 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edgemimic-video: Video-Action Models for Generalizable Robot Control Beyond VLAs
Dec 19, 2025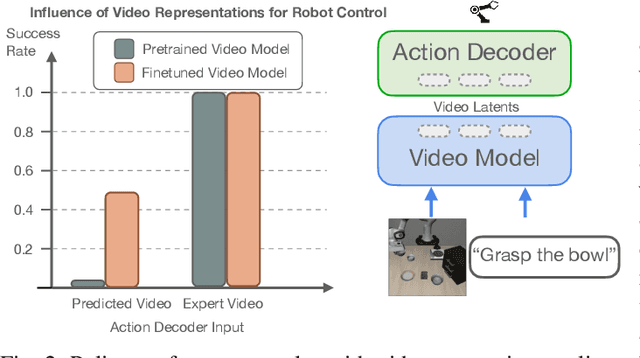
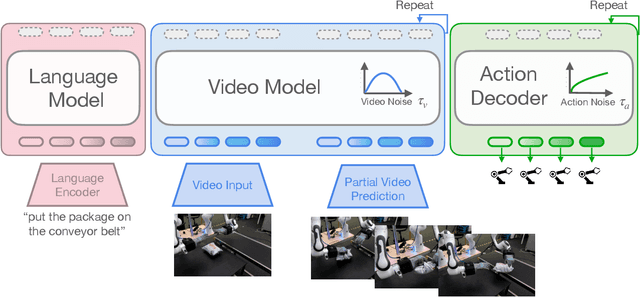

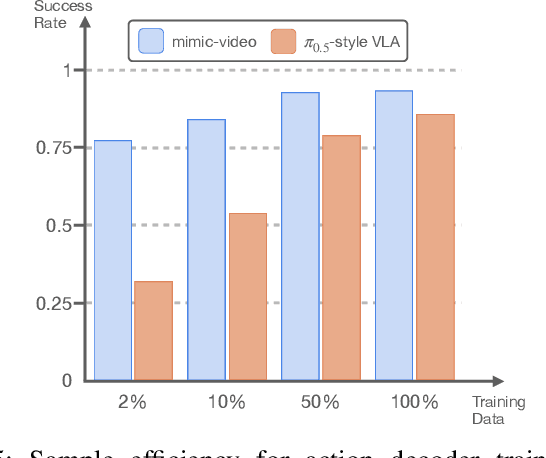
Prevailing Vision-Language-Action Models (VLAs) for robotic manipulation are built upon vision-language backbones pretrained on large-scale, but disconnected static web data. As a result, despite improved semantic generalization, the policy must implicitly infer complex physical dynamics and temporal dependencies solely from robot trajectories. This reliance creates an unsustainable data burden, necessitating continuous, large-scale expert data collection to compensate for the lack of innate physical understanding. We contend that while vision-language pretraining effectively captures semantic priors, it remains blind to physical causality. A more effective paradigm leverages video to jointly capture semantics and visual dynamics during pretraining, thereby isolating the remaining task of low-level control. To this end, we introduce mimic-video, a novel Video-Action Model (VAM) that pairs a pretrained Internet-scale video model with a flow matching-based action decoder conditioned on its latent representations. The decoder serves as an Inverse Dynamics Model (IDM), generating low-level robot actions from the latent representation of video-space action plans. Our extensive evaluation shows that our approach achieves state-of-the-art performance on simulated and real-world robotic manipulation tasks, improving sample efficiency by 10x and convergence speed by 2x compared to traditional VLA architectures.
Latent Action Diffusion for Cross-Embodiment Manipulation
Jun 17, 2025End-to-end learning approaches offer great potential for robotic manipulation, but their impact is constrained by data scarcity and heterogeneity across different embodiments. In particular, diverse action spaces across different end-effectors create barriers for cross-embodiment learning and skill transfer. We address this challenge through diffusion policies learned in a latent action space that unifies diverse end-effector actions. We first show that we can learn a semantically aligned latent action space for anthropomorphic robotic hands, a human hand, and a parallel jaw gripper using encoders trained with a contrastive loss. Second, we show that by using our proposed latent action space for co-training on manipulation data from different end-effectors, we can utilize a single policy for multi-robot control and obtain up to 13% improved manipulation success rates, indicating successful skill transfer despite a significant embodiment gap. Our approach using latent cross-embodiment policies presents a new method to unify different action spaces across embodiments, enabling efficient multi-robot control and data sharing across robot setups. This unified representation significantly reduces the need for extensive data collection for each new robot morphology, accelerates generalization across embodiments, and ultimately facilitates more scalable and efficient robotic learning.
mimic-one: a Scalable Model Recipe for General Purpose Robot Dexterity
Jun 13, 2025



We present a diffusion-based model recipe for real-world control of a highly dexterous humanoid robotic hand, designed for sample-efficient learning and smooth fine-motor action inference. Our system features a newly designed 16-DoF tendon-driven hand, equipped with wide angle wrist cameras and mounted on a Franka Emika Panda arm. We develop a versatile teleoperation pipeline and data collection protocol using both glove-based and VR interfaces, enabling high-quality data collection across diverse tasks such as pick and place, item sorting and assembly insertion. Leveraging high-frequency generative control, we train end-to-end policies from raw sensory inputs, enabling smooth, self-correcting motions in complex manipulation scenarios. Real-world evaluations demonstrate up to 93.3% out of distribution success rates, with up to a +33.3% performance boost due to emergent self-correcting behaviors, while also revealing scaling trends in policy performance. Our results advance the state-of-the-art in dexterous robotic manipulation through a fully integrated, practical approach to hardware, learning, and real-world deployment.
Vision-Language Models are Zero-Shot Reward Models for Reinforcement Learning
Oct 19, 2023



Reinforcement learning (RL) requires either manually specifying a reward function, which is often infeasible, or learning a reward model from a large amount of human feedback, which is often very expensive. We study a more sample-efficient alternative: using pretrained vision-language models (VLMs) as zero-shot reward models (RMs) to specify tasks via natural language. We propose a natural and general approach to using VLMs as reward models, which we call VLM-RMs. We use VLM-RMs based on CLIP to train a MuJoCo humanoid to learn complex tasks without a manually specified reward function, such as kneeling, doing the splits, and sitting in a lotus position. For each of these tasks, we only provide a single sentence text prompt describing the desired task with minimal prompt engineering. We provide videos of the trained agents at: https://sites.google.com/view/vlm-rm. We can improve performance by providing a second ``baseline'' prompt and projecting out parts of the CLIP embedding space irrelevant to distinguish between goal and baseline. Further, we find a strong scaling effect for VLM-RMs: larger VLMs trained with more compute and data are better reward models. The failure modes of VLM-RMs we encountered are all related to known capability limitations of current VLMs, such as limited spatial reasoning ability or visually unrealistic environments that are far off-distribution for the VLM. We find that VLM-RMs are remarkably robust as long as the VLM is large enough. This suggests that future VLMs will become more and more useful reward models for a wide range of RL applications.
Meta-Learning via Classifier(-free) Guidance
Oct 17, 2022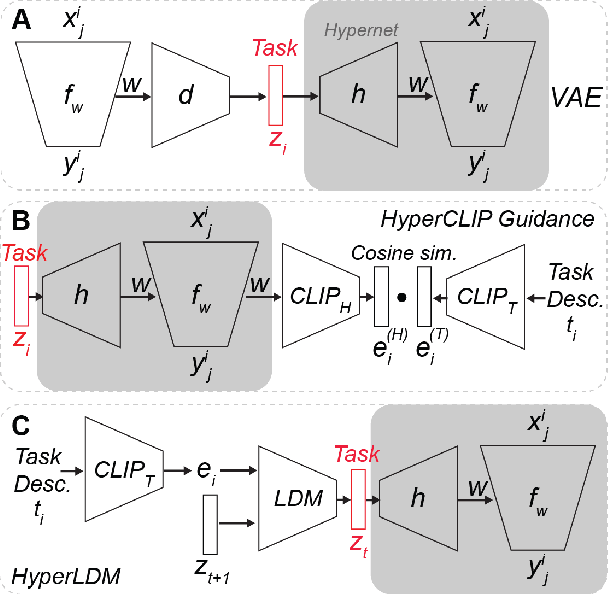
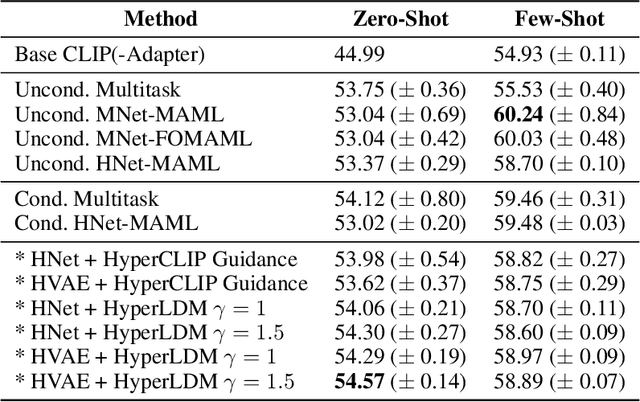


State-of-the-art meta-learning techniques do not optimize for zero-shot adaptation to unseen tasks, a setting in which humans excel. On the contrary, meta-learning algorithms learn hyperparameters and weight initializations that explicitly optimize for few-shot learning performance. In this work, we take inspiration from recent advances in generative modeling and language-conditioned image synthesis to propose meta-learning techniques that use natural language guidance to achieve higher zero-shot performance compared to the state-of-the-art. We do so by recasting the meta-learning problem as a multi-modal generative modeling problem: given a task, we consider its adapted neural network weights and its natural language description as equivalent multi-modal task representations. We first train an unconditional generative hypernetwork model to produce neural network weights; then we train a second "guidance" model that, given a natural language task description, traverses the hypernetwork latent space to find high-performance task-adapted weights in a zero-shot manner. We explore two alternative approaches for latent space guidance: "HyperCLIP"-based classifier guidance and a conditional Hypernetwork Latent Diffusion Model ("HyperLDM"), which we show to benefit from the classifier-free guidance technique common in image generation. Finally, we demonstrate that our approaches outperform existing meta-learning methods with zero-shot learning experiments on our Meta-VQA dataset, which we specifically constructed to reflect the multi-modal meta-learning setting.
Diversified Sampling for Batched Bayesian Optimization with Determinantal Point Processes
Oct 22, 2021
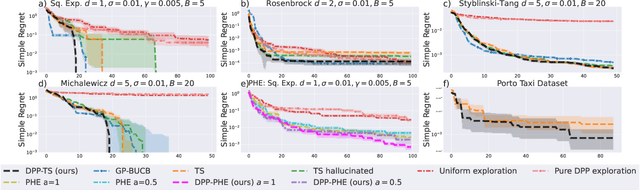
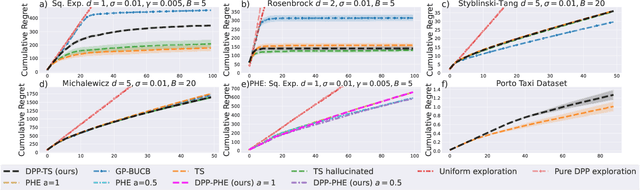
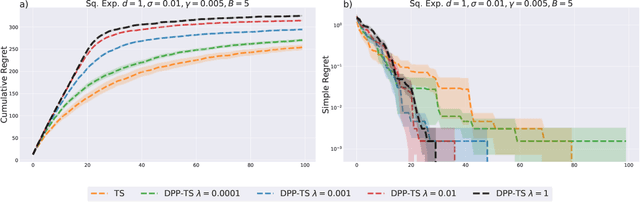
In Bayesian Optimization (BO) we study black-box function optimization with noisy point evaluations and Bayesian priors. Convergence of BO can be greatly sped up by batching, where multiple evaluations of the black-box function are performed in a single round. The main difficulty in this setting is to propose at the same time diverse and informative batches of evaluation points. In this work, we introduce DPP-Batch Bayesian Optimization (DPP-BBO), a universal framework for inducing batch diversity in sampling based BO by leveraging the repulsive properties of Determinantal Point Processes (DPP) to naturally diversify the batch sampling procedure. We illustrate this framework by formulating DPP-Thompson Sampling (DPP-TS) as a variant of the popular Thompson Sampling (TS) algorithm and introducing a Markov Chain Monte Carlo procedure to sample from it. We then prove novel Bayesian simple regret bounds for both classical batched TS as well as our counterpart DPP-TS, with the latter bound being tighter. Our real-world, as well as synthetic, experiments demonstrate improved performance of DPP-BBO over classical batching methods with Gaussian process and Cox process models.
Learning Material Parameters and Hydrodynamics of Soft Robotic Fish via Differentiable Simulation
Sep 30, 2021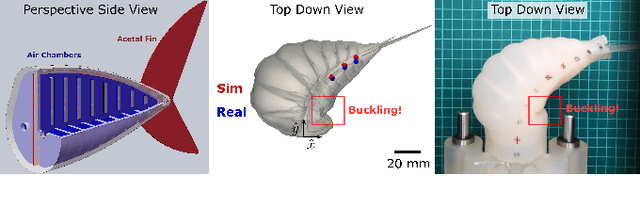
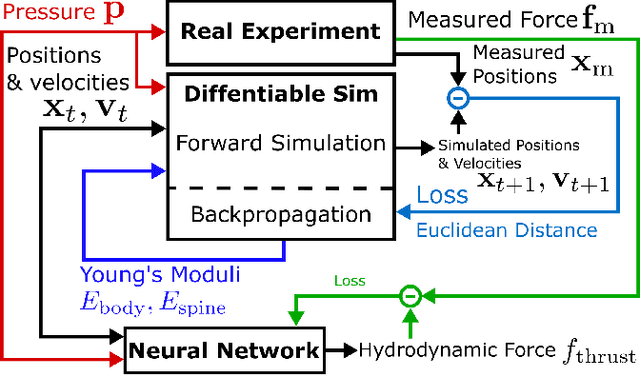

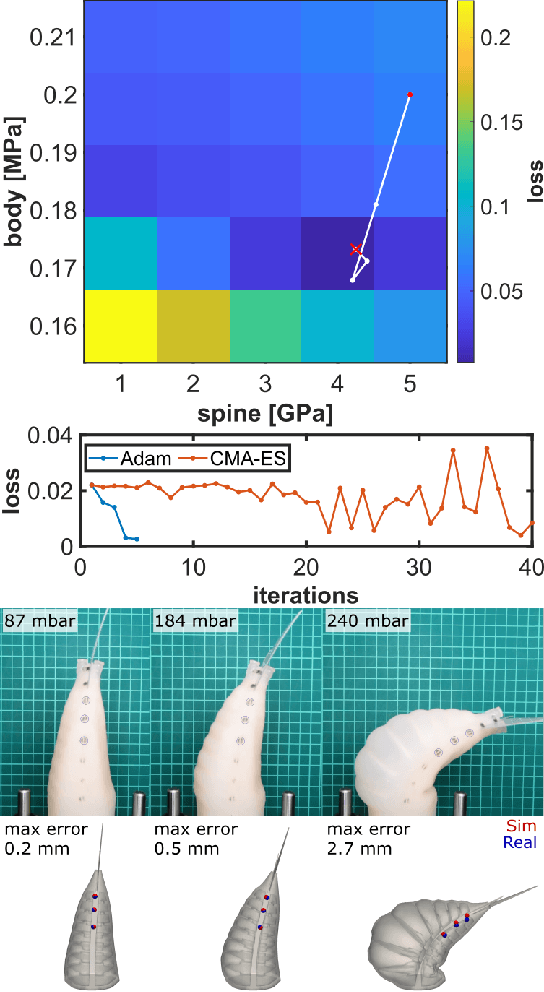
The high dimensionality of soft mechanisms and the complex physics of fluid-structure interactions render the sim2real gap for soft robots particularly challenging. Our framework allows high fidelity prediction of dynamic behavior for composite bi-morph bending structures in real hardware to accuracy near measurement uncertainty. We address this gap with our differentiable simulation tool by learning the material parameters and hydrodynamics of our robots. We demonstrate an experimentally-verified, fast optimization pipeline for learning the material parameters and hydrodynamics from quasi-static and dynamic data via differentiable simulation. Our method identifies physically plausible Young's moduli for various soft silicone elastomers and stiff acetal copolymers used in creation of our three different fish robot designs. For these robots we provide a differentiable and more robust estimate of the thrust force than analytical models and we successfully predict deformation to millimeter accuracy in dynamic experiments under various actuation signals. Although we focus on a specific application for underwater soft robots, our framework is applicable to any pneumatically actuated soft mechanism. This work presents a prototypical hardware and simulation problem solved using our framework that can be extended straightforwardly to higher dimensional parameter inference, learning control policies, and computational design enabled by its differentiability.