 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilingual Reference Need Assessment System for Wikipedia
Mar 17, 2026Wikipedia is a critical source of information for millions of users across the Web. It serves as a key resource for large language models, search engines, question-answering systems, and other Web-based applications. In Wikipedia, content needs to be verifiable, meaning that readers can check that claims are backed by references to reliable sources. This depends on manual verification by editors, an effective but labor-intensive process, especially given the high volume of daily edits. To address this challenge, we introduce a multilingual machine learning system to assist editors in identifying claims requiring citations. Our approach is tested in 10 language editions of Wikipedia, outperforming existing benchmarks for reference need assessment. We not only consider machine learning evaluation metrics but also system requirements, allowing us to explore the trade-offs between model accuracy and computational efficiency under real-world infrastructure constraints. We deploy our system in production and release data and code to support further research.
* Accepted for publication at the Proceedings of the ACM Web Conference 2026 (WWW '26). Author's copy
Customs Fraud Detection in the Presence of Concept Drift
Sep 29, 2021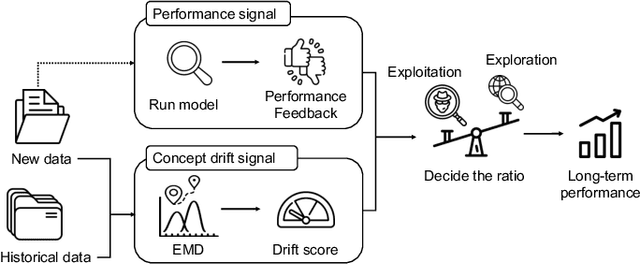
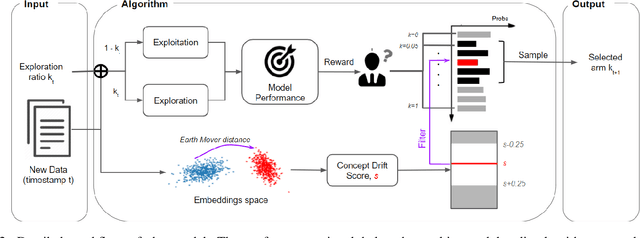
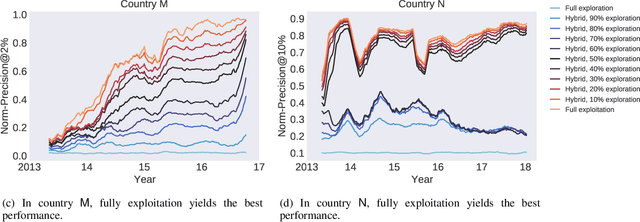
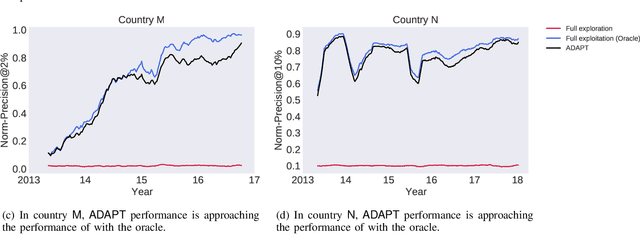
Capturing the changing trade pattern is critical in customs fraud detection. As new goods are imported and novel frauds arise, a drift-aware fraud detection system is needed to detect both known frauds and unknown frauds within a limited budget. The current paper proposes ADAPT, an adaptive selection method that controls the balance between exploitation and exploration strategies used for customs fraud detection. ADAPT makes use of the model performance trends and the amount of concept drift to determine the best exploration ratio at every time. Experiments on data from four countries over several years show that each country requires a different amount of exploration for maintaining its fraud detection system. We find the system with ADAPT can gradually adapt to the dataset and find the appropriate amount of exploration ratio with high performance.