 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Online Continual Learning with Natural Distribution Shifts: An Empirical Study with Visual Data
Aug 20, 2021
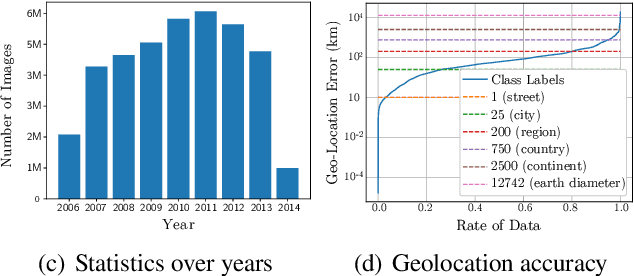
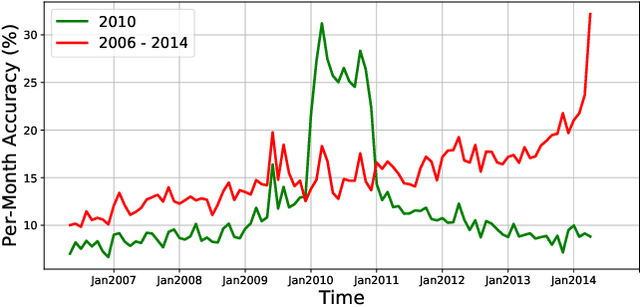
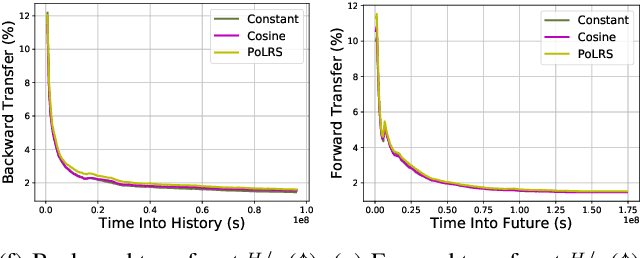
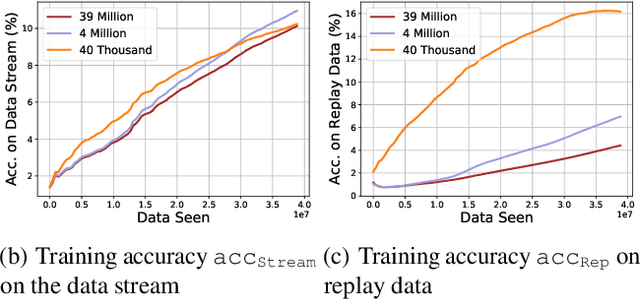
Continual learning is the problem of learning and retaining knowledge through time over multiple tasks and environments. Research has primarily focused on the incremental classification setting, where new tasks/classes are added at discrete time intervals. Such an "offline" setting does not evaluate the ability of agents to learn effectively and efficiently, since an agent can perform multiple learning epochs without any time limitation when a task is added. We argue that "online" continual learning, where data is a single continuous stream without task boundaries, enables evaluating both information retention and online learning efficacy. In online continual learning, each incoming small batch of data is first used for testing and then added to the training set, making the problem truly online. Trained models are later evaluated on historical data to assess information retention. We introduce a new benchmark for online continual visual learning that exhibits large scale and natural distribution shifts. Through a large-scale analysis, we identify critical and previously unobserved phenomena of gradient-based optimization in continual learning, and propose effective strategies for improving gradient-based online continual learning with real data. The source code and dataset are available in: https://github.com/IntelLabs/continuallearning.
Optimised Informed RRTs for Mobile Robot Path Planning
Aug 30, 2021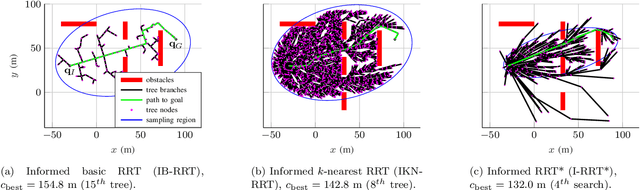
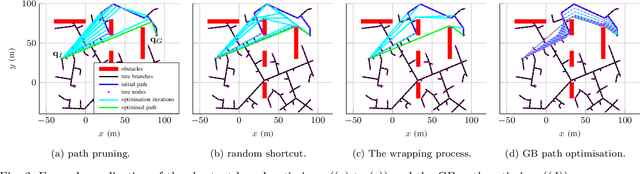
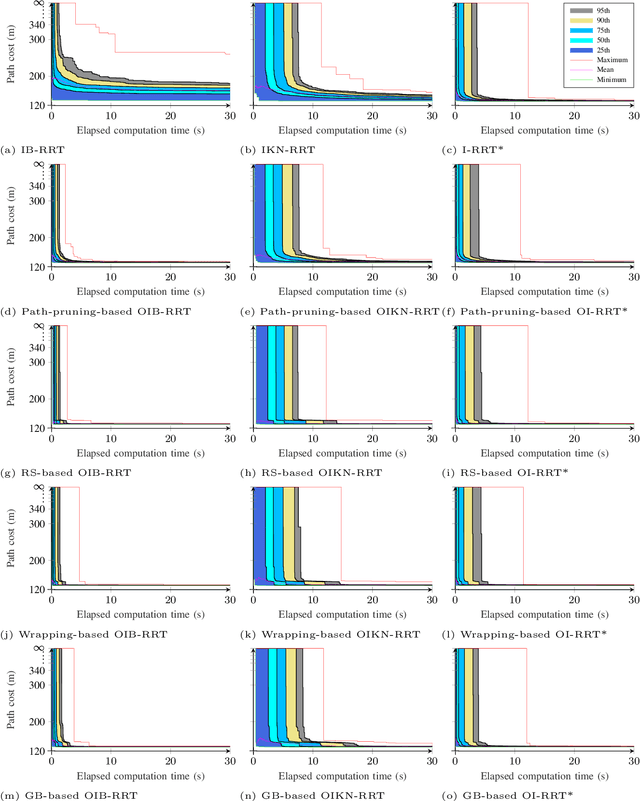
Path planners based on basic rapidly-exploring random trees (RRTs) are quick and efficient, and thus favourable for real-time robot path planning, but are almost-surely suboptimal. In contrast, the optimal RRT (RRT*) converges to the optimal solution, but may be expensive in practice. Recent work has focused on accelerating the RRT*'s convergence rate. The most successful strategies are informed sampling, path optimisation, and a combination thereof. However, informed sampling and its combination with path optimisation have not been applied to the basic RRT. Moreover, while a number of path optimisers can be used to accelerate the convergence rate, a comparison of their effectiveness is lacking. This paper investigates the use of informed sampling and path optimisation to accelerate planners based on both the basic RRT and the RRT*, resulting in a family of algorithms known as optimised informed RRTs. We apply different path optimisers and compare their effectiveness. The goal is to ascertain if applying informed sampling and path optimisation can help the quick, though almost-surely suboptimal, path planners based on the basic RRT attain comparable or better performance than RRT*-based planners. Analyses show that RRT-based optimised informed RRTs do attain better performance than their RRT*-based counterparts, both when planning time is limited and when there is more planning time.
Ensemble Grammar Induction For Detecting Anomalies in Time Series
Jan 29, 2020

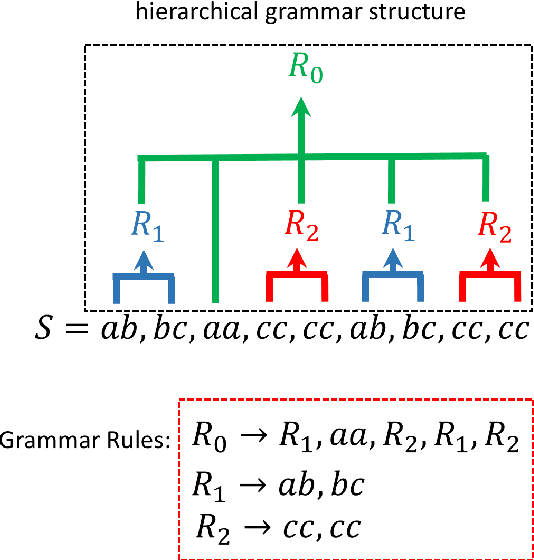
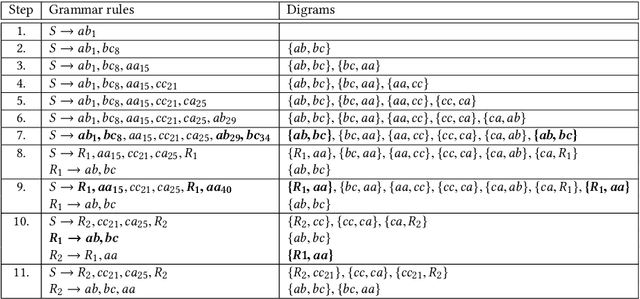
Time series anomaly detection is an important task, with applications in a broad variety of domains. Many approaches have been proposed in recent years, but often they require that the length of the anomalies be known in advance and provided as an input parameter. This limits the practicality of the algorithms, as such information is often unknown in advance, or anomalies with different lengths might co-exist in the data. To address this limitation, previously, a linear time anomaly detection algorithm based on grammar induction has been proposed. While the algorithm can find variable-length patterns, it still requires preselecting values for at least two parameters at the discretization step. How to choose these parameter values properly is still an open problem. In this paper, we introduce a grammar-induction-based anomaly detection method utilizing ensemble learning. Instead of using a particular choice of parameter values for anomaly detection, the method generates the final result based on a set of results obtained using different parameter values. We demonstrate that the proposed ensemble approach can outperform existing grammar-induction-based approaches with different criteria for selection of parameter values. We also show that the proposed approach can achieve performance similar to that of the state-of-the-art distance-based anomaly detection algorithm.
Independent SE(3)-Equivariant Models for End-to-End Rigid Protein Docking
Nov 15, 2021



Protein complex formation is a central problem in biology, being involved in most of the cell's processes, and essential for applications, e.g. drug design or protein engineering. We tackle rigid body protein-protein docking, i.e., computationally predicting the 3D structure of a protein-protein complex from the individual unbound structures, assuming no conformational change within the proteins happens during binding. We design a novel pairwise-independent SE(3)-equivariant graph matching network to predict the rotation and translation to place one of the proteins at the right docked position relative to the second protein. We mathematically guarantee a basic principle: the predicted complex is always identical regardless of the initial locations and orientations of the two structures. Our model, named EquiDock, approximates the binding pockets and predicts the docking poses using keypoint matching and alignment, achieved through optimal transport and a differentiable Kabsch algorithm. Empirically, we achieve significant running time improvements and often outperform existing docking software despite not relying on heavy candidate sampling, structure refinement, or templates.
Sequential Detection and Estimation of Multipath Channel Parameters Using Belief Propagation
Sep 12, 2021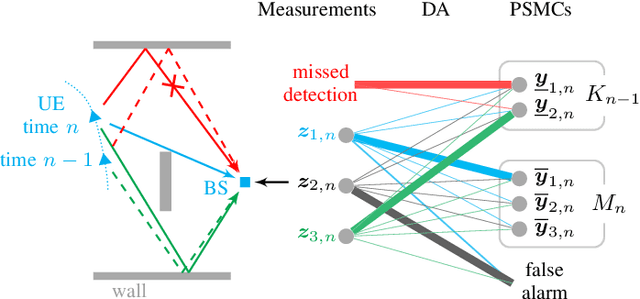
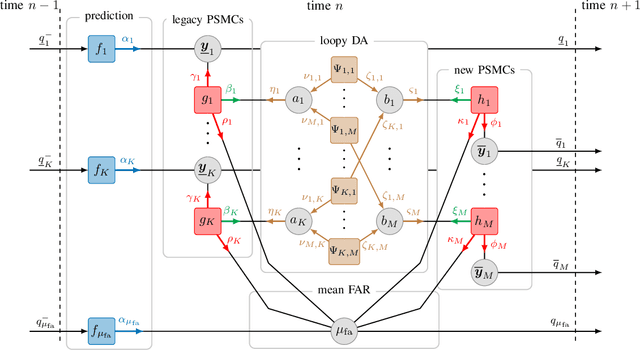
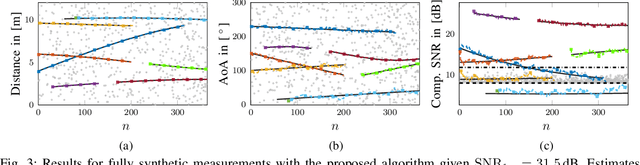
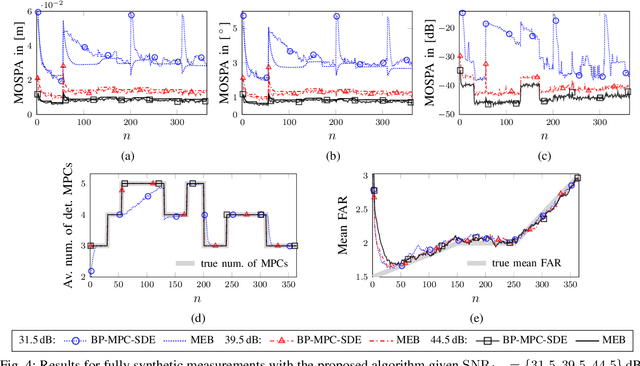
This paper proposes a belief propagation (BP)-based algorithm for sequential detection and estimation of multipath components (MPCs) parameters based on radio signals. Under dynamic channel conditions with moving transmitter and/or receiver, the number of MPCs reflected from visible geometric features, the MPC dispersion parameters (delay, angle, Doppler frequency, etc), and the number of false alarm contributions are unknown and time-varying. We develop a Bayesian model for sequential detection and estimation of MPC dispersion parameters, and represent it by a factor graph enabling the use of BP for efficient computation of the marginal posterior distributions. At each time instance, a snapshot-based channel estimator provides parameter estimates of a set of MPCs which are used as noisy measurements by the proposed BP-based algorithm. It performs joint probabilistic data association, estimation of the time-varying MPC parameters, and the mean number of false alarm measurements by means of the sum-product algorithm rules. The results using synthetic measurements show that the proposed algorithm is able to cope with a high number of false alarm measurements originating from the snapshot-based channel estimator and to sequentially detect and estimate MPCs parameters with very low signal-to-noise ratio (SNR). The performance of the proposed algorithm compares well to existing algorithms for high SNR MPCs, but significantly it outperforms them for medium or low SNR MPCs. In particular, we show that our algorithm outperforms the Kalman enhanced super resolution tracking (KEST) algorithm, a state-of-the-art sequential channel parameters estimation method. Furthermore, results with real radio measurements demonstrate the excellent performance of the algorithm in realistic and challenging scenarios.
Confounder Identification-free Causal Visual Feature Learning
Nov 26, 2021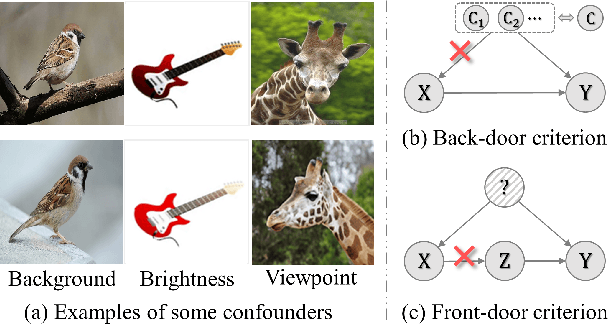
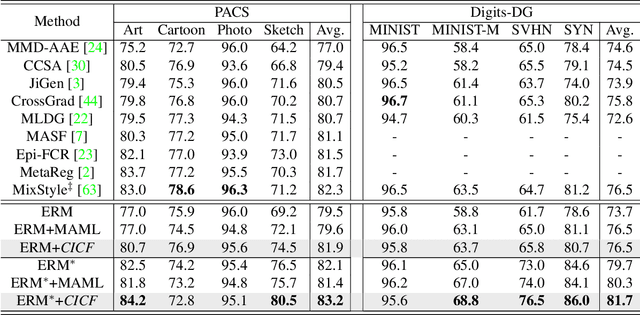
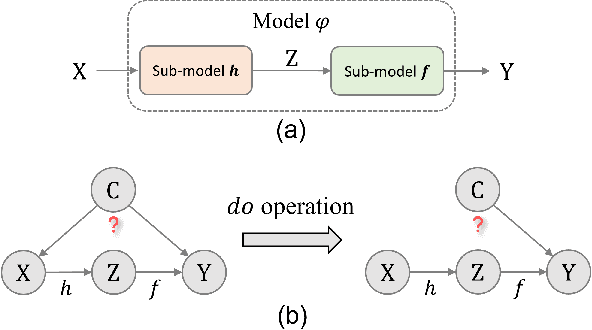
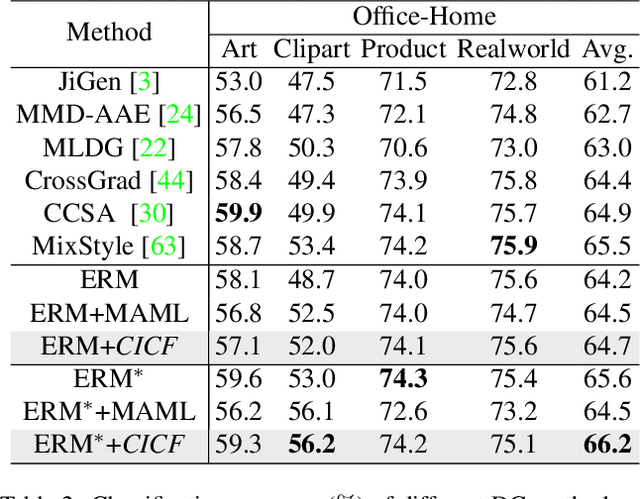
Confounders in deep learning are in general detrimental to model's generalization where they infiltrate feature representations. Therefore, learning causal features that are free of interference from confounders is important. Most previous causal learning based approaches employ back-door criterion to mitigate the adverse effect of certain specific confounder, which require the explicit identification of confounder. However, in real scenarios, confounders are typically diverse and difficult to be identified. In this paper, we propose a novel Confounder Identification-free Causal Visual Feature Learning (CICF) method, which obviates the need for identifying confounders. CICF models the interventions among different samples based on front-door criterion, and then approximates the global-scope intervening effect upon the instance-level interventions from the perspective of optimization. In this way, we aim to find a reliable optimization direction, which avoids the intervening effects of confounders, to learn causal features. Furthermore, we uncover the relation between CICF and the popular meta-learning strategy MAML, and provide an interpretation of why MAML works from the theoretical perspective of causal learning for the first time. Thanks to the effective learning of causal features, our CICF enables models to have superior generalization capability. Extensive experiments on domain generalization benchmark datasets demonstrate the effectiveness of our CICF, which achieves the state-of-the-art performance.
RIS-aided D2D Communication Design for URLLC Packet Delivery
Nov 26, 2021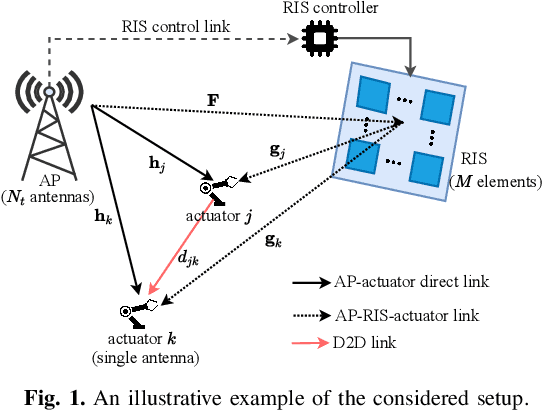
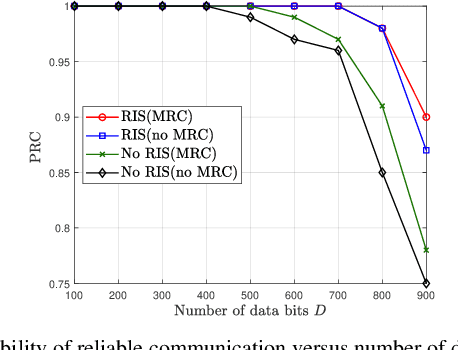
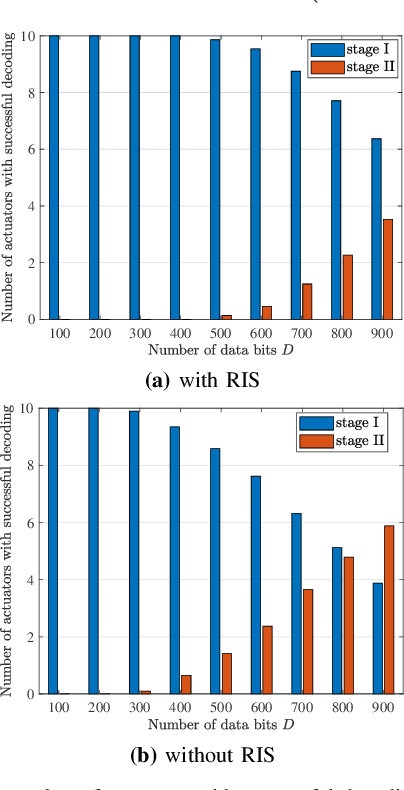
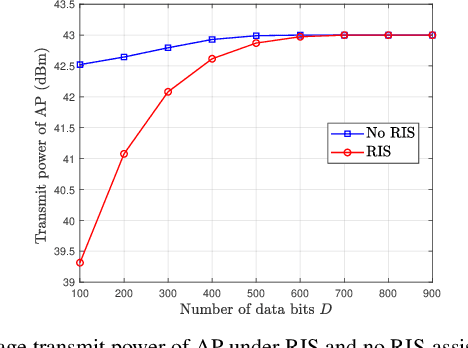
In this paper, we consider a smart factory scenario where a set of actuators receive critical control signals from an access point (AP) with reliability and low latency requirements. We investigate jointly active beamforming at the AP and passive phase shifting at the reconfigurable intelligent surface (RIS) for successfully delivering the control signals from the AP to the actuators within a required time duration. The transmission follows a two-stage design. In the first stage, each actuator can both receive the direct signal from AP and the reflected signal from the RIS. In the second stage, the actuators with successful reception in the first stage, relay the message through the D2D network to the actuators with failed receptions. We formulate a non-convex optimization problem where we first obtain an equivalent but more tractable form by addressing the problem with discrete indicator functions. Then, Frobenius inner product based equality is applied for decoupling the optimization variables. Further, we adopt a penalty-based approach to resolve the rank-one constraints. Finally, we deal with the $\ell_0$-norm by $\ell_1$-norm approximation and add an extra term $\ell_1-\ell_2$ for sparsity. Numerical results reveal that the proposed two-stage RIS-aided D2D communication protocol is effective for enabling reliable communication with latency requirements.
Experimental Investigation on the Friction-induced Vibration with Periodic Characteristics in a Running-in Process under Lubrication
Nov 15, 2021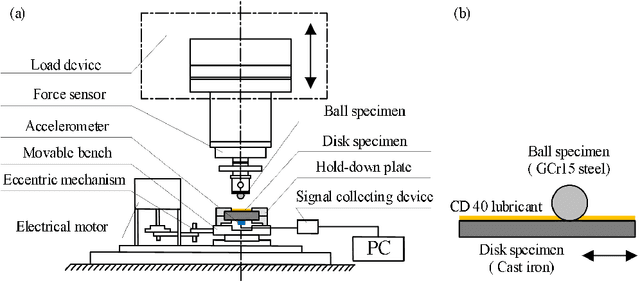
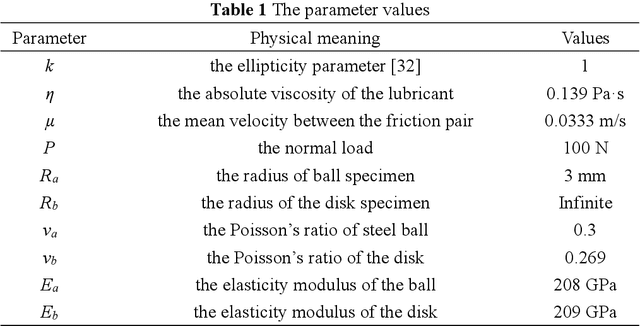
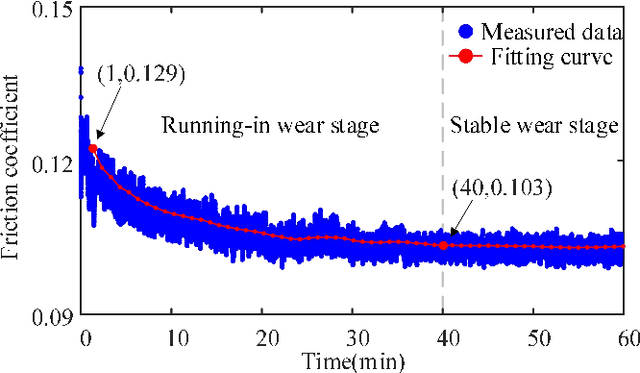
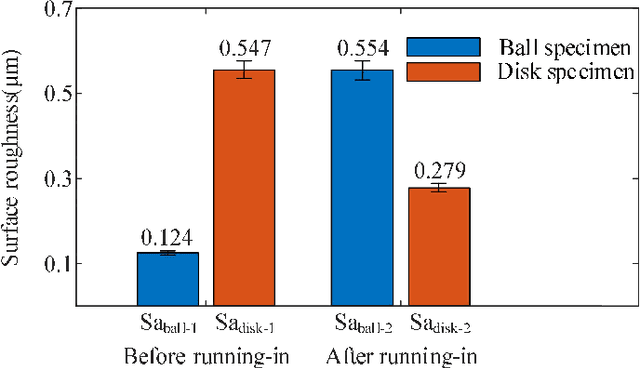
This paper investigated the friction-induced vibration (FIV) behavior under the running-in process with oil lubrication. The FIV signal with periodic characteristics under lubrication was identified with the help of the squeal signal induced in an oil-free wear experiment and then extracted by the harmonic wavelet packet transform (HWPT). The variation of the FIV signal from running-in wear stage to steady wear stage was studied by its root mean square (RMS) values. The result indicates that the time-frequency characteristics of the FIV signals evolve with the wear process and can reflect the wear stages of the friction pairs. The RMS evolvement of the FIV signal is in the same trend to the composite surface roughness and demonstrates that the friction pair goes through the running-in wear stage and the steady wear stage. Therefore, the FIV signal with periodic characteristics can describe the evolvement of the running-in process and distinguish the running-in wear stage and the stable wear stage of the friction pair.
A First-Occupancy Representation for Reinforcement Learning
Sep 28, 2021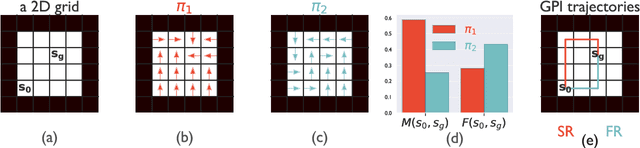
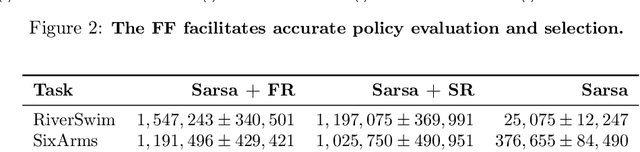
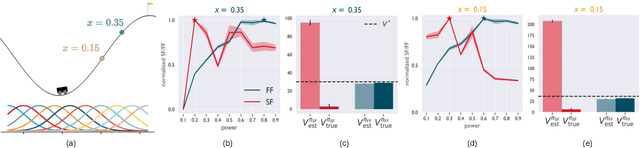
Both animals and artificial agents benefit from state representations that support rapid transfer of learning across tasks and which enable them to efficiently traverse their environments to reach rewarding states. The successor representation (SR), which measures the expected cumulative, discounted state occupancy under a fixed policy, enables efficient transfer to different reward structures in an otherwise constant Markovian environment and has been hypothesized to underlie aspects of biological behavior and neural activity. However, in the real world, rewards may move or only be available for consumption once, may shift location, or agents may simply aim to reach goal states as rapidly as possible without the constraint of artificially imposed task horizons. In such cases, the most behaviorally-relevant representation would carry information about when the agent was likely to first reach states of interest, rather than how often it should expect to visit them over a potentially infinite time span. To reflect such demands, we introduce the first-occupancy representation (FR), which measures the expected temporal discount to the first time a state is accessed. We demonstrate that the FR facilitates the selection of efficient paths to desired states, allows the agent, under certain conditions, to plan provably optimal trajectories defined by a sequence of subgoals, and induces similar behavior to animals avoiding threatening stimuli.
Distributed stochastic proximal algorithm with random reshuffling for non-smooth finite-sum optimization
Nov 06, 2021
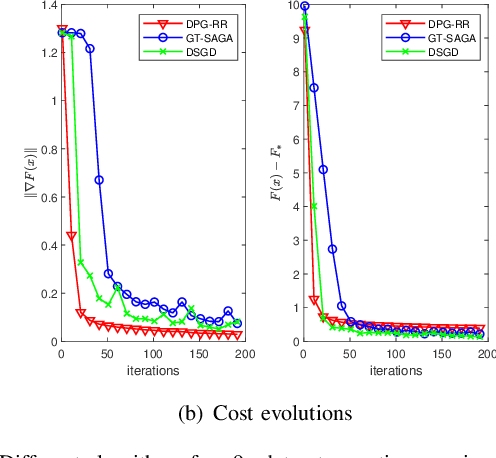
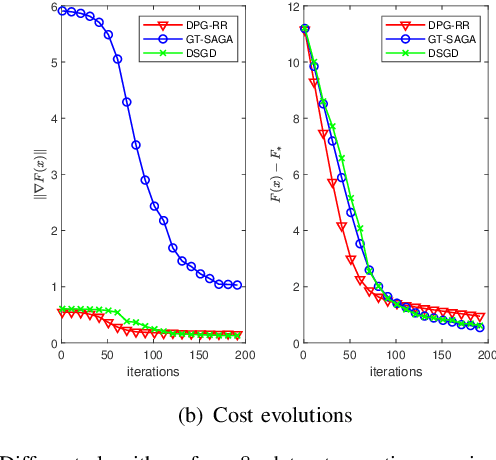
The non-smooth finite-sum minimization is a fundamental problem in machine learning. This paper develops a distributed stochastic proximal-gradient algorithm with random reshuffling to solve the finite-sum minimization over time-varying multi-agent networks. The objective function is a sum of differentiable convex functions and non-smooth regularization. Each agent in the network updates local variables with a constant step-size by local information and cooperates to seek an optimal solution. We prove that local variable estimates generated by the proposed algorithm achieve consensus and are attracted to a neighborhood of the optimal solution in expectation with an $\mathcal{O}(\frac{1}{T}+\frac{1}{\sqrt{T}})$ convergence rate. In addition, this paper shows that the steady-state error of the objective function can be arbitrarily small by choosing small enough step-sizes. Finally, some comparative simulations are provided to verify the convergence performance of the proposed algorithm.