 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTiny but Trusted: Efficient Vision-Language Reasoning for Time-Series Anomaly Detection
May 28, 2026Recent advances in Vision-Language Models (VLMs) have achieved impressive performance across many tasks, yet prior studies report unsatisfactory performance when applying large language or multimodal models to finding abnormal patterns in sequential data. Public anomaly detection benchmarks typically provide interval annotations but not natural-language rationales, making it difficult to fine-tune VLMs to produce grounded, interpretable decisions. To address this gap, we construct VisAnomBench, a curated benchmark built from public time-series datasets and augmented with high-quality anomaly explanations selected from multiple large VLMs using fine-grained, task-specific rewards. Through fine-tuning on this benchmark, we develop VisAnomReasoner, a parameter-efficient VLM for time-series anomaly detection. Experimental results on VisAnomBench show that VisAnomReasoner achieves more accurate anomaly localization and consistently outperforms all baselines, with improvements of at least 21.23 and 23.87 percentage points in precision and F1, respectively. Additional experiments on the TSB-AD-U benchmark demonstrate strong cross-benchmark generalization, with VisAnomReasoner improving precision and F1 by 9.57 and 13.39 percentage points, respectively.
mTSBench: Benchmarking Multivariate Time Series Anomaly Detection and Model Selection at Scale
Jun 26, 2025Multivariate time series anomaly detection (MTS-AD) is critical in domains like healthcare, cybersecurity, and industrial monitoring, yet remains challenging due to complex inter-variable dependencies, temporal dynamics, and sparse anomaly labels. We introduce mTSBench, the largest benchmark to date for MTS-AD and unsupervised model selection, spanning 344 labeled time series across 19 datasets and 12 diverse application domains. mTSBench evaluates 24 anomaly detection methods, including large language model (LLM)-based detectors for multivariate time series, and systematically benchmarks unsupervised model selection techniques under standardized conditions. Consistent with prior findings, our results confirm that no single detector excels across datasets, underscoring the importance of model selection. However, even state-of-the-art selection methods remain far from optimal, revealing critical gaps. mTSBench provides a unified evaluation suite to enable rigorous, reproducible comparisons and catalyze future advances in adaptive anomaly detection and robust model selection.
Ensemble Grammar Induction For Detecting Anomalies in Time Series
Jan 29, 2020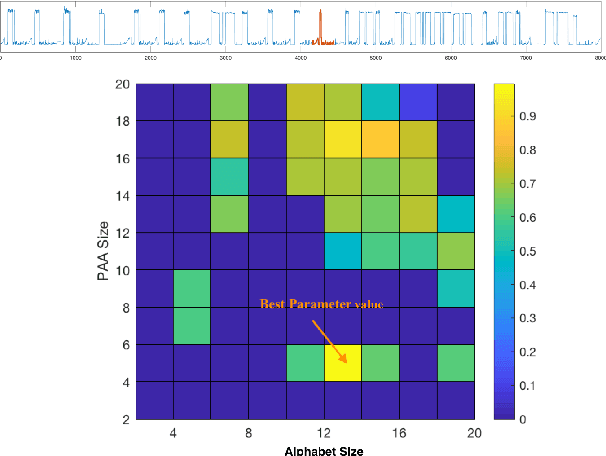

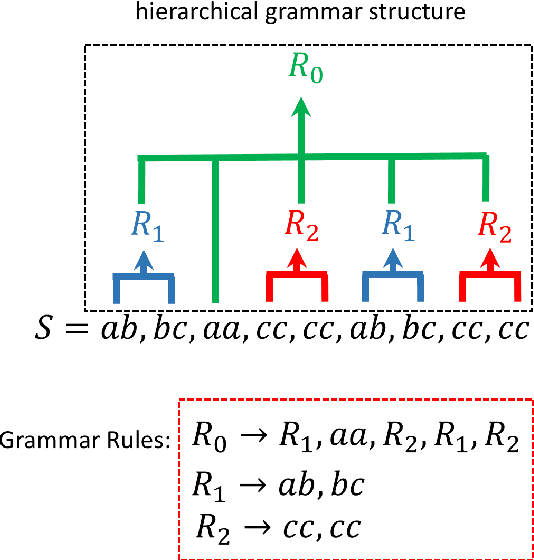
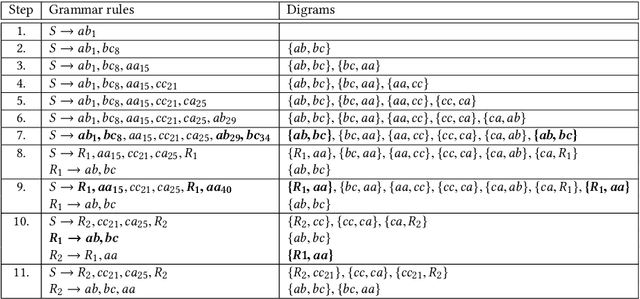
Time series anomaly detection is an important task, with applications in a broad variety of domains. Many approaches have been proposed in recent years, but often they require that the length of the anomalies be known in advance and provided as an input parameter. This limits the practicality of the algorithms, as such information is often unknown in advance, or anomalies with different lengths might co-exist in the data. To address this limitation, previously, a linear time anomaly detection algorithm based on grammar induction has been proposed. While the algorithm can find variable-length patterns, it still requires preselecting values for at least two parameters at the discretization step. How to choose these parameter values properly is still an open problem. In this paper, we introduce a grammar-induction-based anomaly detection method utilizing ensemble learning. Instead of using a particular choice of parameter values for anomaly detection, the method generates the final result based on a set of results obtained using different parameter values. We demonstrate that the proposed ensemble approach can outperform existing grammar-induction-based approaches with different criteria for selection of parameter values. We also show that the proposed approach can achieve performance similar to that of the state-of-the-art distance-based anomaly detection algorithm.