 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Multinomial Logistic Bandit via Frequent Directions
Jun 10, 2026This paper studies efficient online algorithms for multinomial logistic bandits (MLogB), where the feedback distribution over $K+1$ outcomes follows a multinomial logistic model of $d$-dimensional action vectors. A representative UCB-type algorithm, OFUL-MLogB, achieves a regret bound of $\tilde{\mathcal{O}}(Kd\sqrt{T})$, but still requires $\mathcal{O}(K^3d^3)$ time and $\mathcal{O}(K^2d^2)$ space per round due to parameter estimation and optimistic reward construction, which is prohibitive in high-dimensional settings. To address this limitation, we propose EOFD-MLogB, which integrates frequent directions matrix sketching into OFUL-MLogB. By maintaining a low-rank SVD sketch of the accumulated Hessian, constrained online Newton updates in parameter estimation and $Kd \times K$ spectral-norm computations in the reward bonus are reduced to one-dimensional root-finding tasks and $K \times K$ eigenvalue computations, respectively. This yields dominant per-round time complexity $\mathcal{O}(Kd(m+K)^2)$ and space complexity $\mathcal{O}(Kd(m+K))$, where $m \ll d$ is the sketch size. We further prove a regret bound of $\tilde{\mathcal{O}}(Δ_T(Kd\lnΔ_T+m)\sqrt{T})$, where the sketching error factor $Δ_T$ is controlled by the $m$-truncated spectral tail of the Hessian. Thus, when the Hessian is approximately low-rank, the regret is close to that of OFUL-MLogB. Experiments validate the computational efficiency and competitive performance.
Improved Analysis for Sign-based Methods with Momentum Updates
Jul 16, 2025



In this paper, we present enhanced analysis for sign-based optimization algorithms with momentum updates. Traditional sign-based methods, under the separable smoothness assumption, guarantee a convergence rate of $\mathcal{O}(T^{-1/4})$, but they either require large batch sizes or assume unimodal symmetric stochastic noise. To address these limitations, we demonstrate that signSGD with momentum can achieve the same convergence rate using constant batch sizes without additional assumptions. Our analysis, under the standard $l_2$-smoothness condition, improves upon the result of the prior momentum-based signSGD method by a factor of $\mathcal{O}(d^{1/2})$, where $d$ is the problem dimension. Furthermore, we explore sign-based methods with majority vote in distributed settings and show that the proposed momentum-based method yields convergence rates of $\mathcal{O}\left( d^{1/2}T^{-1/2} + dn^{-1/2} \right)$ and $\mathcal{O}\left( \max \{ d^{1/4}T^{-1/4}, d^{1/10}T^{-1/5} \} \right)$, which outperform the previous results of $\mathcal{O}\left( dT^{-1/4} + dn^{-1/2} \right)$ and $\mathcal{O}\left( d^{3/8}T^{-1/8} \right)$, respectively. Numerical experiments further validate the effectiveness of the proposed methods.
Discounted Online Convex Optimization: Uniform Regret Across a Continuous Interval
May 26, 2025Reflecting the greater significance of recent history over the distant past in non-stationary environments, $\lambda$-discounted regret has been introduced in online convex optimization (OCO) to gracefully forget past data as new information arrives. When the discount factor $\lambda$ is given, online gradient descent with an appropriate step size achieves an $O(1/\sqrt{1-\lambda})$ discounted regret. However, the value of $\lambda$ is often not predetermined in real-world scenarios. This gives rise to a significant open question: is it possible to develop a discounted algorithm that adapts to an unknown discount factor. In this paper, we affirmatively answer this question by providing a novel analysis to demonstrate that smoothed OGD (SOGD) achieves a uniform $O(\sqrt{\log T/1-\lambda})$ discounted regret, holding for all values of $\lambda$ across a continuous interval simultaneously. The basic idea is to maintain multiple OGD instances to handle different discount factors, and aggregate their outputs sequentially by an online prediction algorithm named as Discounted-Normal-Predictor (DNP) (Kapralov and Panigrahy,2010). Our analysis reveals that DNP can combine the decisions of two experts, even when they operate on discounted regret with different discount factors.
Learning without Isolation: Pathway Protection for Continual Learning
May 24, 2025



Deep networks are prone to catastrophic forgetting during sequential task learning, i.e., losing the knowledge about old tasks upon learning new tasks. To this end, continual learning(CL) has emerged, whose existing methods focus mostly on regulating or protecting the parameters associated with the previous tasks. However, parameter protection is often impractical, since the size of parameters for storing the old-task knowledge increases linearly with the number of tasks, otherwise it is hard to preserve the parameters related to the old-task knowledge. In this work, we bring a dual opinion from neuroscience and physics to CL: in the whole networks, the pathways matter more than the parameters when concerning the knowledge acquired from the old tasks. Following this opinion, we propose a novel CL framework, learning without isolation(LwI), where model fusion is formulated as graph matching and the pathways occupied by the old tasks are protected without being isolated. Thanks to the sparsity of activation channels in a deep network, LwI can adaptively allocate available pathways for a new task, realizing pathway protection and addressing catastrophic forgetting in a parameter-efficient manner. Experiments on popular benchmark datasets demonstrate the superiority of the proposed LwI.
Projection-Free Variance Reduction Methods for Stochastic Constrained Multi-Level Compositional Optimization
Jun 06, 2024This paper investigates projection-free algorithms for stochastic constrained multi-level optimization. In this context, the objective function is a nested composition of several smooth functions, and the decision set is closed and convex. Existing projection-free algorithms for solving this problem suffer from two limitations: 1) they solely focus on the gradient mapping criterion and fail to match the optimal sample complexities in unconstrained settings; 2) their analysis is exclusively applicable to non-convex functions, without considering convex and strongly convex objectives. To address these issues, we introduce novel projection-free variance reduction algorithms and analyze their complexities under different criteria. For gradient mapping, our complexities improve existing results and match the optimal rates for unconstrained problems. For the widely-used Frank-Wolfe gap criterion, we provide theoretical guarantees that align with those for single-level problems. Additionally, by using a stage-wise adaptation, we further obtain complexities for convex and strongly convex functions. Finally, numerical experiments on different tasks demonstrate the effectiveness of our methods.
Adaptive Variance Reduction for Stochastic Optimization under Weaker Assumptions
Jun 04, 2024This paper explores adaptive variance reduction methods for stochastic optimization based on the STORM technique. Existing adaptive extensions of STORM rely on strong assumptions like bounded gradients and bounded function values, or suffer an additional $\mathcal{O}(\log T)$ term in the convergence rate. To address these limitations, we introduce a novel adaptive STORM method that achieves an optimal convergence rate of $\mathcal{O}(T^{-1/3})$ for non-convex functions with our newly designed learning rate strategy. Compared with existing approaches, our method requires weaker assumptions and attains the optimal convergence rate without the additional $\mathcal{O}(\log T)$ term. We also extend the proposed technique to stochastic compositional optimization, obtaining the same optimal rate of $\mathcal{O}(T^{-1/3})$. Furthermore, we investigate the non-convex finite-sum problem and develop another innovative adaptive variance reduction method that achieves an optimal convergence rate of $\mathcal{O}(n^{1/4} T^{-1/2} )$, where $n$ represents the number of component functions. Numerical experiments across various tasks validate the effectiveness of our method.
Efficient Sign-Based Optimization: Accelerating Convergence via Variance Reduction
Jun 01, 2024

Sign stochastic gradient descent (signSGD) is a communication-efficient method that transmits only the sign of stochastic gradients for parameter updating. Existing literature has demonstrated that signSGD can achieve a convergence rate of $\mathcal{O}(d^{1/2}T^{-1/4})$, where $d$ represents the dimension and $T$ is the iteration number. In this paper, we improve this convergence rate to $\mathcal{O}(d^{1/2}T^{-1/3})$ by introducing the Sign-based Stochastic Variance Reduction (SSVR) method, which employs variance reduction estimators to track gradients and leverages their signs to update. For finite-sum problems, our method can be further enhanced to achieve a convergence rate of $\mathcal{O}(m^{1/4}d^{1/2}T^{-1/2})$, where $m$ denotes the number of component functions. Furthermore, we investigate the heterogeneous majority vote in distributed settings and introduce two novel algorithms that attain improved convergence rates of $\mathcal{O}(d^{1/2}T^{-1/2} + dn^{-1/2})$ and $\mathcal{O}(d^{1/4}T^{-1/4})$ respectively, outperforming the previous results of $\mathcal{O}(dT^{-1/4} + dn^{-1/2})$ and $\mathcal{O}(d^{3/8}T^{-1/8})$, where $n$ represents the number of nodes. Numerical experiments across different tasks validate the effectiveness of our proposed methods.
Experimental Investigation on the Friction-induced Vibration with Periodic Characteristics in a Running-in Process under Lubrication
Nov 24, 2021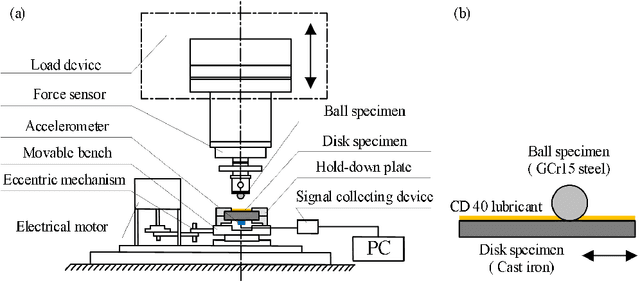
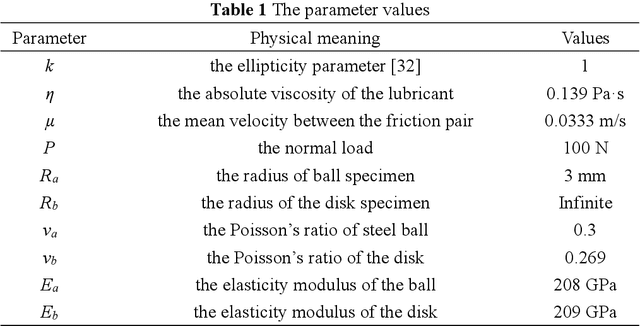
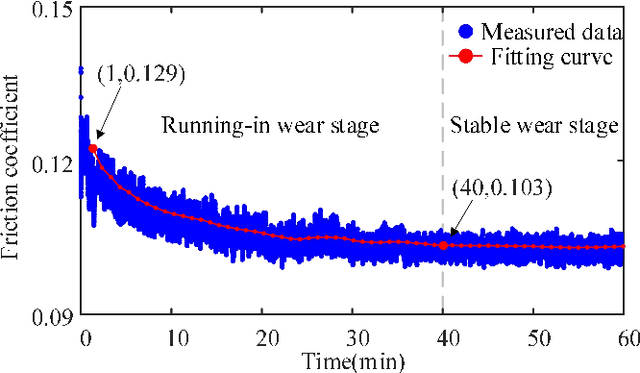
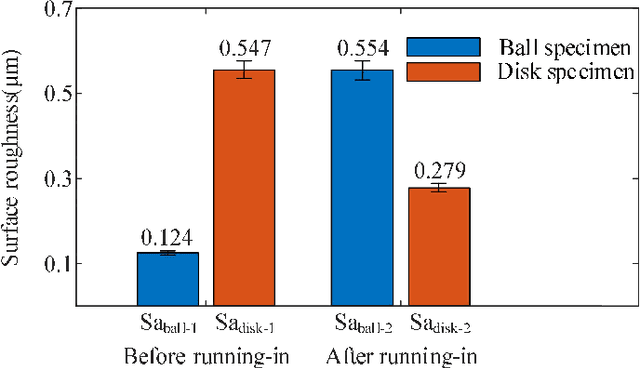
This paper investigated the friction-induced vibration (FIV) behavior under the running-in process with oil lubrication. The FIV signal with periodic characteristics under lubrication was identified with the help of the squeal signal induced in an oil-free wear experiment and then extracted by the harmonic wavelet packet transform (HWPT). The variation of the FIV signal from running-in wear stage to steady wear stage was studied by its root mean square (RMS) values. The result indicates that the time-frequency characteristics of the FIV signals evolve with the wear process and can reflect the wear stages of the friction pairs. The RMS evolvement of the FIV signal is in the same trend to the composite surface roughness and demonstrates that the friction pair goes through the running-in wear stage and the steady wear stage. Therefore, the FIV signal with periodic characteristics can describe the evolvement of the running-in process and distinguish the running-in wear stage and the stable wear stage of the friction pair.