 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategy Coopetition Explains the Emergence and Transience of In-Context Learning
Mar 07, 2025In-context learning (ICL) is a powerful ability that emerges in transformer models, enabling them to learn from context without weight updates. Recent work has established emergent ICL as a transient phenomenon that can sometimes disappear after long training times. In this work, we sought a mechanistic understanding of these transient dynamics. Firstly, we find that, after the disappearance of ICL, the asymptotic strategy is a remarkable hybrid between in-weights and in-context learning, which we term "context-constrained in-weights learning" (CIWL). CIWL is in competition with ICL, and eventually replaces it as the dominant strategy of the model (thus leading to ICL transience). However, we also find that the two competing strategies actually share sub-circuits, which gives rise to cooperative dynamics as well. For example, in our setup, ICL is unable to emerge quickly on its own, and can only be enabled through the simultaneous slow development of asymptotic CIWL. CIWL thus both cooperates and competes with ICL, a phenomenon we term "strategy coopetition." We propose a minimal mathematical model that reproduces these key dynamics and interactions. Informed by this model, we were able to identify a setup where ICL is truly emergent and persistent.
HARP: A challenging human-annotated math reasoning benchmark
Dec 11, 2024



Math reasoning is becoming an ever increasing area of focus as we scale large language models. However, even the previously-toughest evals like MATH are now close to saturated by frontier models (90.0% for o1-mini and 86.5% for Gemini 1.5 Pro). We introduce HARP, Human Annotated Reasoning Problems (for Math), consisting of 5,409 problems from the US national math competitions (A(J)HSME, AMC, AIME, USA(J)MO). Of these, 4,780 have answers that are automatically check-able (with libraries such as SymPy). These problems range six difficulty levels, with frontier models performing relatively poorly on the hardest bracket of 197 problems (average accuracy 41.1% for o1-mini, and 9.6% for Gemini 1.5 Pro). Our dataset also features multiple choices (for 4,110 problems) and an average of two human-written, ground-truth solutions per problem, offering new avenues of research that we explore briefly. We report evaluations for many frontier models and share some interesting analyses, such as demonstrating that frontier models across families intrinsically scale their inference-time compute for more difficult problems. Finally, we open source all code used for dataset construction (including scraping) and all code for evaluation (including answer checking) to enable future research at: https://github.com/aadityasingh/HARP.
What needs to go right for an induction head? A mechanistic study of in-context learning circuits and their formation
Apr 10, 2024



In-context learning is a powerful emergent ability in transformer models. Prior work in mechanistic interpretability has identified a circuit element that may be critical for in-context learning -- the induction head (IH), which performs a match-and-copy operation. During training of large transformers on natural language data, IHs emerge around the same time as a notable phase change in the loss. Despite the robust evidence for IHs and this interesting coincidence with the phase change, relatively little is known about the diversity and emergence dynamics of IHs. Why is there more than one IH, and how are they dependent on each other? Why do IHs appear all of a sudden, and what are the subcircuits that enable them to emerge? We answer these questions by studying IH emergence dynamics in a controlled setting by training on synthetic data. In doing so, we develop and share a novel optogenetics-inspired causal framework for modifying activations throughout training. Using this framework, we delineate the diverse and additive nature of IHs. By clamping subsets of activations throughout training, we then identify three underlying subcircuits that interact to drive IH formation, yielding the phase change. Furthermore, these subcircuits shed light on data-dependent properties of formation, such as phase change timing, already showing the promise of this more in-depth understanding of subcircuits that need to "go right" for an induction head.
The Transient Nature of Emergent In-Context Learning in Transformers
Nov 15, 2023



Transformer neural networks can exhibit a surprising capacity for in-context learning (ICL) despite not being explicitly trained for it. Prior work has provided a deeper understanding of how ICL emerges in transformers, e.g. through the lens of mechanistic interpretability, Bayesian inference, or by examining the distributional properties of training data. However, in each of these cases, ICL is treated largely as a persistent phenomenon; namely, once ICL emerges, it is assumed to persist asymptotically. Here, we show that the emergence of ICL during transformer training is, in fact, often transient. We train transformers on synthetic data designed so that both ICL and in-weights learning (IWL) strategies can lead to correct predictions. We find that ICL first emerges, then disappears and gives way to IWL, all while the training loss decreases, indicating an asymptotic preference for IWL. The transient nature of ICL is observed in transformers across a range of model sizes and datasets, raising the question of how much to "overtrain" transformers when seeking compact, cheaper-to-run models. We find that L2 regularization may offer a path to more persistent ICL that removes the need for early stopping based on ICL-style validation tasks. Finally, we present initial evidence that ICL transience may be caused by competition between ICL and IWL circuits.
Confronting Reward Model Overoptimization with Constrained RLHF
Oct 10, 2023



Large language models are typically aligned with human preferences by optimizing $\textit{reward models}$ (RMs) fitted to human feedback. However, human preferences are multi-faceted, and it is increasingly common to derive reward from a composition of simpler reward models which each capture a different aspect of language quality. This itself presents a challenge, as it is difficult to appropriately weight these component RMs when combining them. Compounding this difficulty, because any RM is only a proxy for human evaluation, this process is vulnerable to $\textit{overoptimization}$, wherein past a certain point, accumulating higher reward is associated with worse human ratings. In this paper, we perform, to our knowledge, the first study on overoptimization in composite RMs, showing that correlation between component RMs has a significant effect on the locations of these points. We then introduce an approach to solve this issue using constrained reinforcement learning as a means of preventing the agent from exceeding each RM's threshold of usefulness. Our method addresses the problem of weighting component RMs by learning dynamic weights, naturally expressed by Lagrange multipliers. As a result, each RM stays within the range at which it is an effective proxy, improving evaluation performance. Finally, we introduce an adaptive method using gradient-free optimization to identify and optimize towards these points during a single run.
A State Representation for Diminishing Rewards
Sep 07, 2023A common setting in multitask reinforcement learning (RL) demands that an agent rapidly adapt to various stationary reward functions randomly sampled from a fixed distribution. In such situations, the successor representation (SR) is a popular framework which supports rapid policy evaluation by decoupling a policy's expected discounted, cumulative state occupancies from a specific reward function. However, in the natural world, sequential tasks are rarely independent, and instead reflect shifting priorities based on the availability and subjective perception of rewarding stimuli. Reflecting this disjunction, in this paper we study the phenomenon of diminishing marginal utility and introduce a novel state representation, the $\lambda$ representation ($\lambda$R) which, surprisingly, is required for policy evaluation in this setting and which generalizes the SR as well as several other state representations from the literature. We establish the $\lambda$R's formal properties and examine its normative advantages in the context of machine learning, as well as its usefulness for studying natural behaviors, particularly foraging.
ReLOAD: Reinforcement Learning with Optimistic Ascent-Descent for Last-Iterate Convergence in Constrained MDPs
Feb 02, 2023



In recent years, Reinforcement Learning (RL) has been applied to real-world problems with increasing success. Such applications often require to put constraints on the agent's behavior. Existing algorithms for constrained RL (CRL) rely on gradient descent-ascent, but this approach comes with a caveat. While these algorithms are guaranteed to converge on average, they do not guarantee last-iterate convergence, i.e., the current policy of the agent may never converge to the optimal solution. In practice, it is often observed that the policy alternates between satisfying the constraints and maximizing the reward, rarely accomplishing both objectives simultaneously. Here, we address this problem by introducing Reinforcement Learning with Optimistic Ascent-Descent (ReLOAD), a principled CRL method with guaranteed last-iterate convergence. We demonstrate its empirical effectiveness on a wide variety of CRL problems including discrete MDPs and continuous control. In the process we establish a benchmark of challenging CRL problems.
Transfer RL via the Undo Maps Formalism
Nov 26, 2022Transferring knowledge across domains is one of the most fundamental problems in machine learning, but doing so effectively in the context of reinforcement learning remains largely an open problem. Current methods make strong assumptions on the specifics of the task, often lack principled objectives, and -- crucially -- modify individual policies, which might be sub-optimal when the domains differ due to a drift in the state space, i.e., it is intrinsic to the environment and therefore affects every agent interacting with it. To address these drawbacks, we propose TvD: transfer via distribution matching, a framework to transfer knowledge across interactive domains. We approach the problem from a data-centric perspective, characterizing the discrepancy in environments by means of (potentially complex) transformation between their state spaces, and thus posing the problem of transfer as learning to undo this transformation. To accomplish this, we introduce a novel optimization objective based on an optimal transport distance between two distributions over trajectories -- those generated by an already-learned policy in the source domain and a learnable pushforward policy in the target domain. We show this objective leads to a policy update scheme reminiscent of imitation learning, and derive an efficient algorithm to implement it. Our experiments in simple gridworlds show that this method yields successful transfer learning across a wide range of environment transformations.
Minimum Description Length Control
Jul 24, 2022

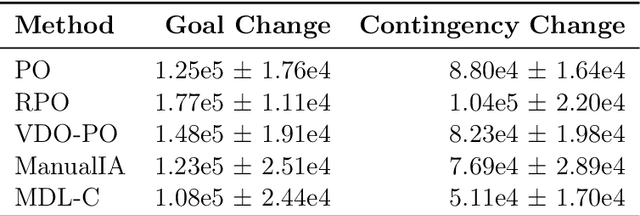

We propose a novel framework for multitask reinforcement learning based on the minimum description length (MDL) principle. In this approach, which we term MDL-control (MDL-C), the agent learns the common structure among the tasks with which it is faced and then distills it into a simpler representation which facilitates faster convergence and generalization to new tasks. In doing so, MDL-C naturally balances adaptation to each task with epistemic uncertainty about the task distribution. We motivate MDL-C via formal connections between the MDL principle and Bayesian inference, derive theoretical performance guarantees, and demonstrate MDL-C's empirical effectiveness on both discrete and high-dimensional continuous control tasks.
Towards an Understanding of Default Policies in Multitask Policy Optimization
Nov 06, 2021


Much of the recent success of deep reinforcement learning has been driven by regularized policy optimization (RPO) algorithms, with strong performance across multiple domains. In this family of methods, agents are trained to maximize cumulative reward while penalizing deviation in behavior from some reference, or default policy. In addition to empirical success, there is a strong theoretical foundation for understanding RPO methods applied to single tasks, with connections to natural gradient, trust region, and variational approaches. However, there is limited formal understanding of desirable properties for default policies in the multitask setting, an increasingly important domain as the field shifts towards training more generally capable agents. Here, we take a first step towards filling this gap by formally linking the quality of the default policy to its effect on optimization. Using these results, we then derive a principled RPO algorithm for multitask learning with strong performance guarantees.