 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Counteracting Dark Web Text-Based CAPTCHA with Generative Adversarial Learning for Proactive Cyber Threat Intelligence
Jan 08, 2022
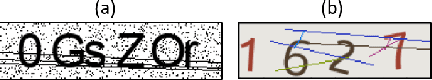
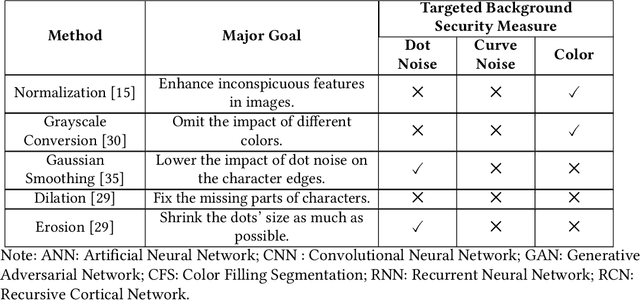
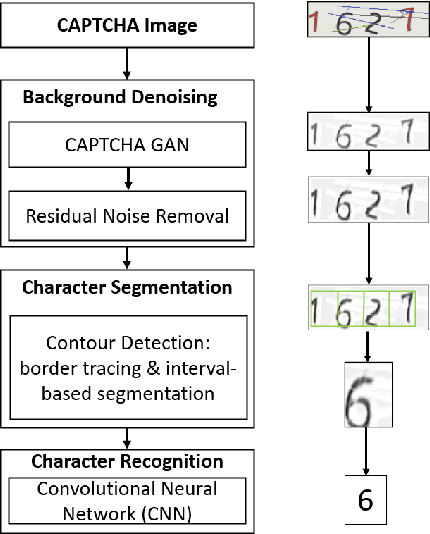
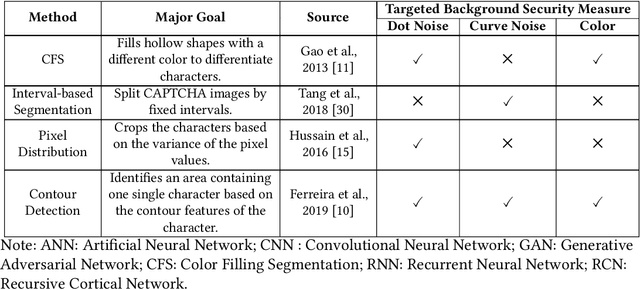
Automated monitoring of dark web (DW) platforms on a large scale is the first step toward developing proactive Cyber Threat Intelligence (CTI). While there are efficient methods for collecting data from the surface web, large-scale dark web data collection is often hindered by anti-crawling measures. In particular, text-based CAPTCHA serves as the most prevalent and prohibiting type of these measures in the dark web. Text-based CAPTCHA identifies and blocks automated crawlers by forcing the user to enter a combination of hard-to-recognize alphanumeric characters. In the dark web, CAPTCHA images are meticulously designed with additional background noise and variable character length to prevent automated CAPTCHA breaking. Existing automated CAPTCHA breaking methods have difficulties in overcoming these dark web challenges. As such, solving dark web text-based CAPTCHA has been relying heavily on human involvement, which is labor-intensive and time-consuming. In this study, we propose a novel framework for automated breaking of dark web CAPTCHA to facilitate dark web data collection. This framework encompasses a novel generative method to recognize dark web text-based CAPTCHA with noisy background and variable character length. To eliminate the need for human involvement, the proposed framework utilizes Generative Adversarial Network (GAN) to counteract dark web background noise and leverages an enhanced character segmentation algorithm to handle CAPTCHA images with variable character length. Our proposed framework, DW-GAN, was systematically evaluated on multiple dark web CAPTCHA testbeds. DW-GAN significantly outperformed the state-of-the-art benchmark methods on all datasets, achieving over 94.4% success rate on a carefully collected real-world dark web dataset...
Real-Time Panoptic Segmentation from Dense Detections
Dec 03, 2019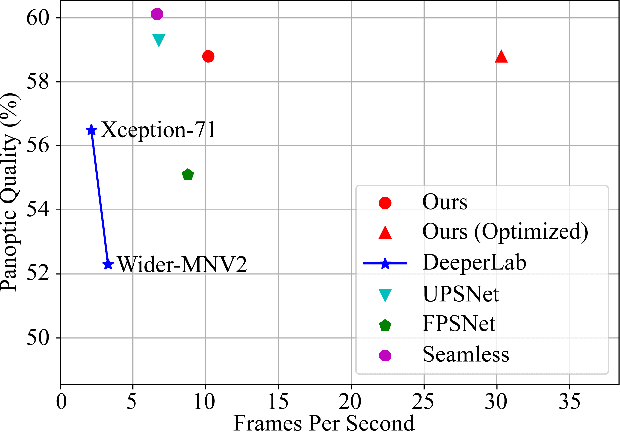
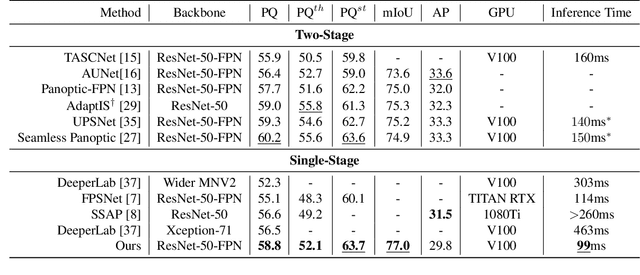
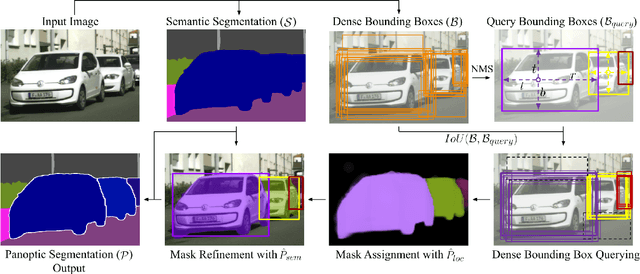
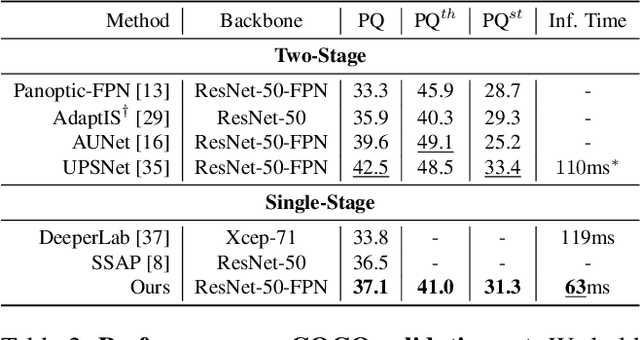
Panoptic segmentation is a complex full scene parsing task requiring simultaneous instance and semantic segmentation at high resolution. Current state-of-the-art approaches cannot run in real-time, and simplifying these architectures to improve efficiency severely degrades their accuracy. In this paper, we propose a new single-shot panoptic segmentation network that leverages dense detections and a global self-attention mechanism to operate in real-time with performance approaching the state of the art. We introduce a novel parameter-free mask construction method that substantially reduces computational complexity by efficiently reusing information from the object detection and semantic segmentation sub-tasks. The resulting network has a simple data flow that does not require feature map re-sampling or clustering post-processing, enabling significant hardware acceleration. Our experiments on the Cityscapes and COCO benchmarks show that our network works at 30 FPS on 1024x2048 resolution, trading a 3% relative performance degradation from the current state of the art for up to 440% faster inference.
Learning Temporally Causal Latent Processes from General Temporal Data
Oct 11, 2021
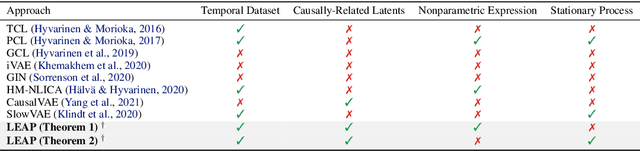
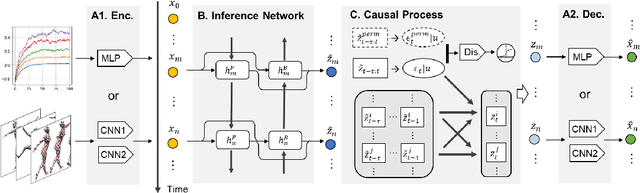
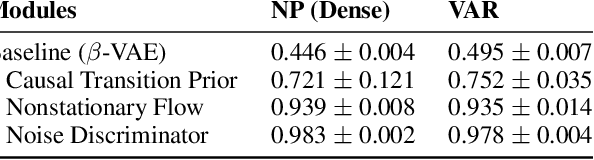
Our goal is to recover time-delayed latent causal variables and identify their relations from measured temporal data. Estimating causally-related latent variables from observations is particularly challenging as the latent variables are not uniquely recoverable in the most general case. In this work, we consider both a nonparametric, nonstationary setting and a parametric setting for the latent processes and propose two provable conditions under which temporally causal latent processes can be identified from their nonlinear mixtures. We propose LEAP, a theoretically-grounded architecture that extends Variational Autoencoders (VAEs) by enforcing our conditions through proper constraints in causal process prior. Experimental results on various data sets demonstrate that temporally causal latent processes are reliably identified from observed variables under different dependency structures and that our approach considerably outperforms baselines that do not leverage history or nonstationarity information. This is one of the first works that successfully recover time-delayed latent processes from nonlinear mixtures without using sparsity or minimality assumptions.
Smart Director: An Event-Driven Directing System for Live Broadcasting
Jan 11, 2022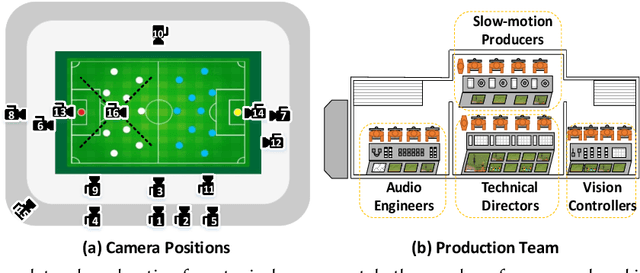
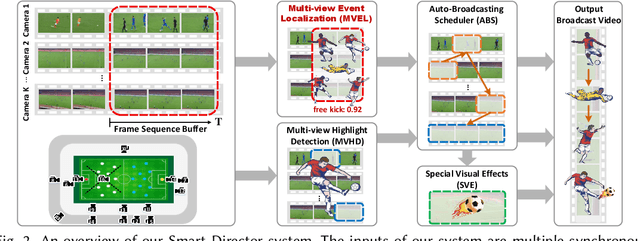
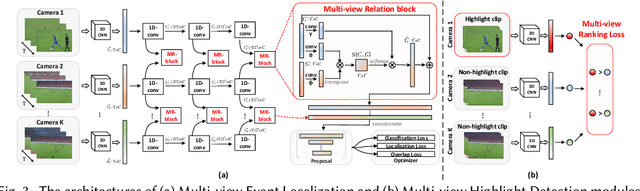
Live video broadcasting normally requires a multitude of skills and expertise with domain knowledge to enable multi-camera productions. As the number of cameras keep increasing, directing a live sports broadcast has now become more complicated and challenging than ever before. The broadcast directors need to be much more concentrated, responsive, and knowledgeable, during the production. To relieve the directors from their intensive efforts, we develop an innovative automated sports broadcast directing system, called Smart Director, which aims at mimicking the typical human-in-the-loop broadcasting process to automatically create near-professional broadcasting programs in real-time by using a set of advanced multi-view video analysis algorithms. Inspired by the so-called "three-event" construction of sports broadcast, we build our system with an event-driven pipeline consisting of three consecutive novel components: 1) the Multi-view Event Localization to detect events by modeling multi-view correlations, 2) the Multi-view Highlight Detection to rank camera views by the visual importance for view selection, 3) the Auto-Broadcasting Scheduler to control the production of broadcasting videos. To our best knowledge, our system is the first end-to-end automated directing system for multi-camera sports broadcasting, completely driven by the semantic understanding of sports events. It is also the first system to solve the novel problem of multi-view joint event detection by cross-view relation modeling. We conduct both objective and subjective evaluations on a real-world multi-camera soccer dataset, which demonstrate the quality of our auto-generated videos is comparable to that of the human-directed. Thanks to its faster response, our system is able to capture more fast-passing and short-duration events which are usually missed by human directors.
Aware Adoption of Artificial Intelligence and Big Data: a Value Framework for Reusable Knowledge
Nov 11, 2021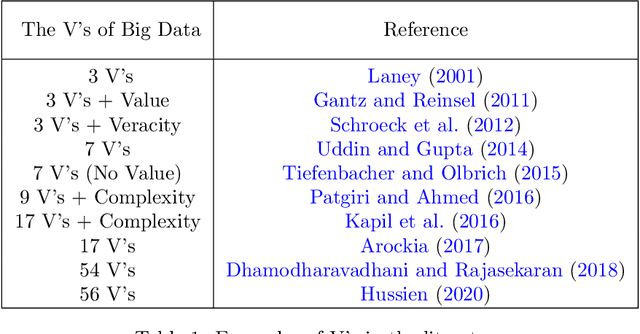
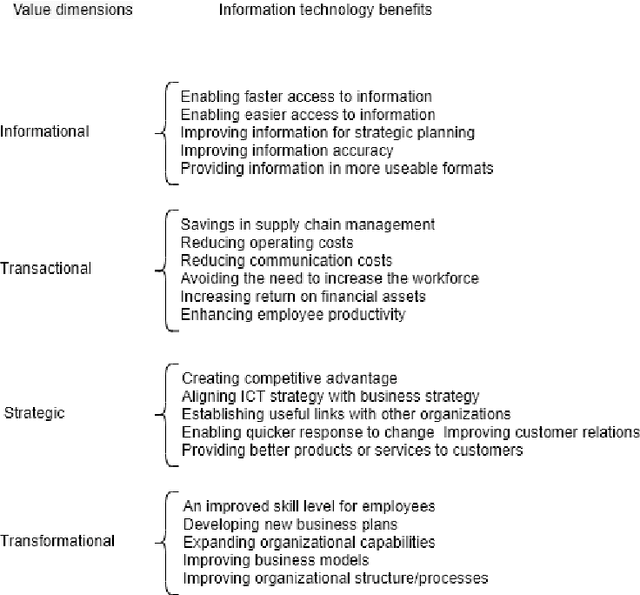
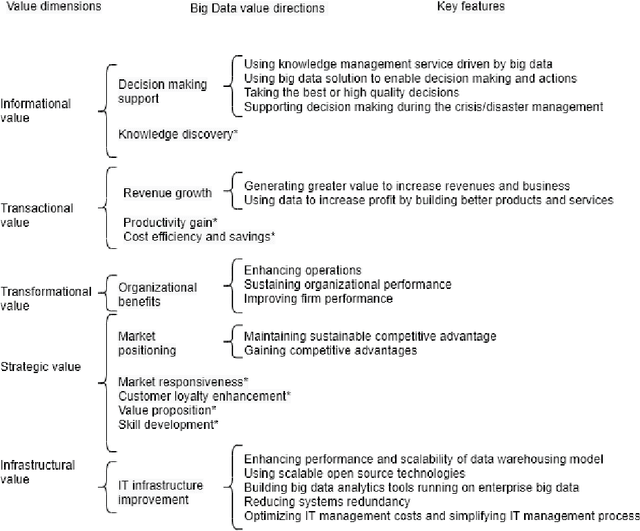
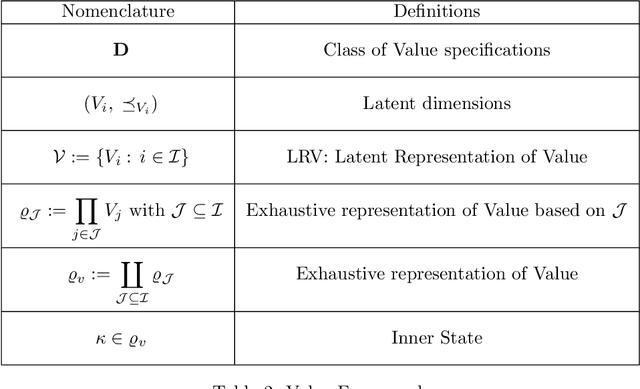
Artificial Intelligence (AI) provides practical advantages in different applied domains. This is changing the way decision-makers reason about complex systems. Indeed, broader visibility on greater information (re)sources, e.g. Big Data (BD), is now available to intelligent agents. On the other hand, such decisions are not always based on reusable, multi-purpose, and explainable knowledge. Therefore, it is necessary to define new models to describe and manage this new (re)source of uncertainty. This contribution aims to introduce a formal framework to deal with the notion of Value in the AI-BD context, embracing both the multiplicity of Value dimensions and the uncertainty in their visibility as the foundations for a dynamic, relational representation of Value. The framework design is based on abstract and highly scalable definitions to represent Value, even considering the interaction of different agents through comparison, combination, and update of states of knowledge. In such a model, both Big Data and different types of intelligence are considered as resources. The information extracted from data becomes a renewable resource if it can be transformed into knowledge, which is reusable beyond a specific scenario and, dynamically, over time. The focus on reusable knowledge is exploited in the relation between Human and Artificial intelligences, which is characterised by a "non-classical" form of uncertainty related to data observability. Finally, we identify applicative domains for future investigation, in order to address the impact of the dynamic behaviour of Value dimensions on strategies and decision-making, enhancing the adaptability and, hence, the sustainability of AI-BD initiatives over time.
Extracting knowledge from features with multilevel abstraction
Dec 04, 2021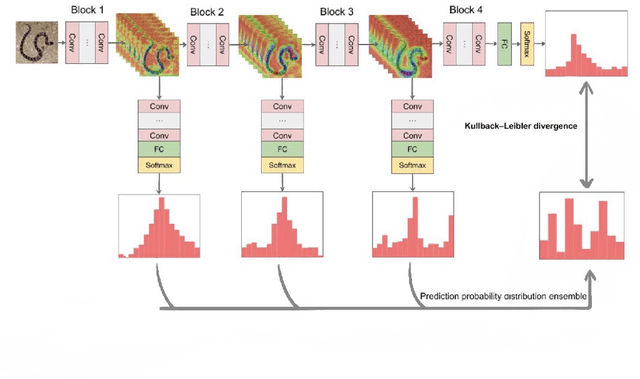
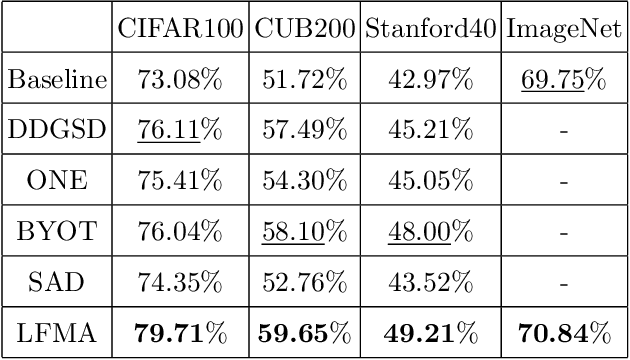

Knowledge distillation aims at transferring the knowledge from a large teacher model to a small student model with great improvements of the performance of the student model. Therefore, the student network can replace the teacher network to deploy on low-resource devices since the higher performance, lower number of parameters and shorter inference time. Self-knowledge distillation (SKD) attracts a great attention recently that a student model itself is a teacher model distilling knowledge from. To the best of our knowledge, self knowledge distillation can be divided into two main streams: data augmentation and refined knowledge auxiliary. In this paper, we purpose a novel SKD method in a different way from the main stream methods. Our method distills knowledge from multilevel abstraction features. Experiments and ablation studies show its great effectiveness and generalization on various kinds of tasks with various kinds of model structures. Our codes have been released on GitHub.
On the Detection of Markov Decision Processes
Dec 23, 2021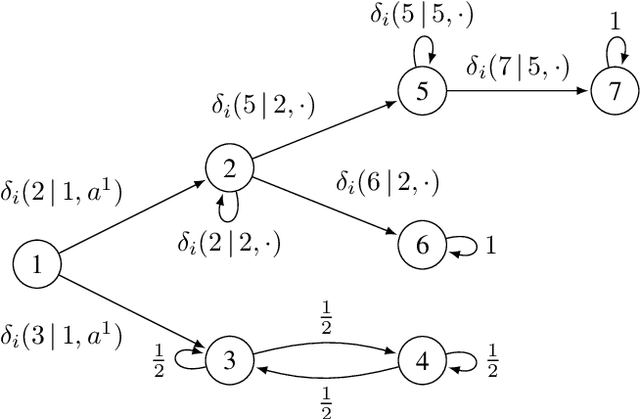
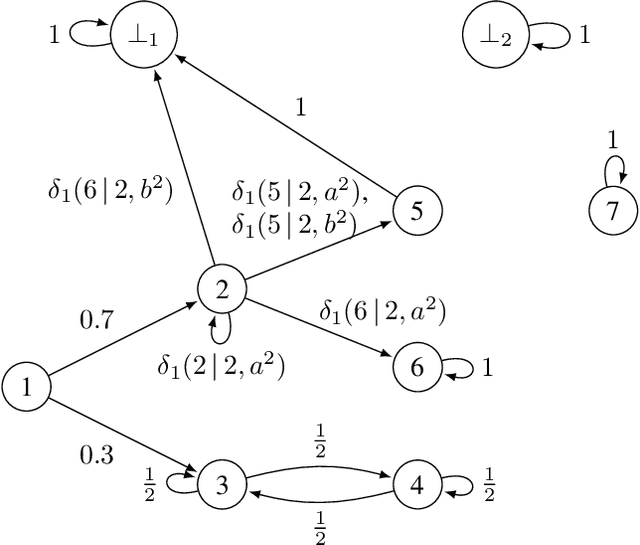
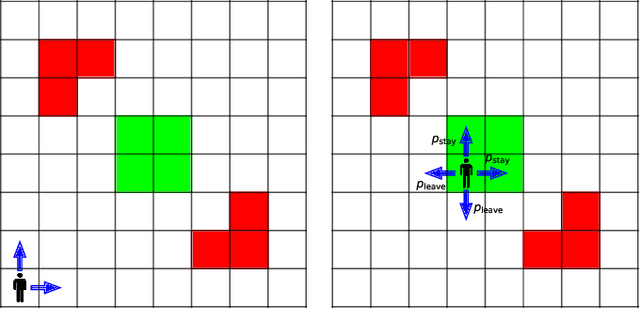
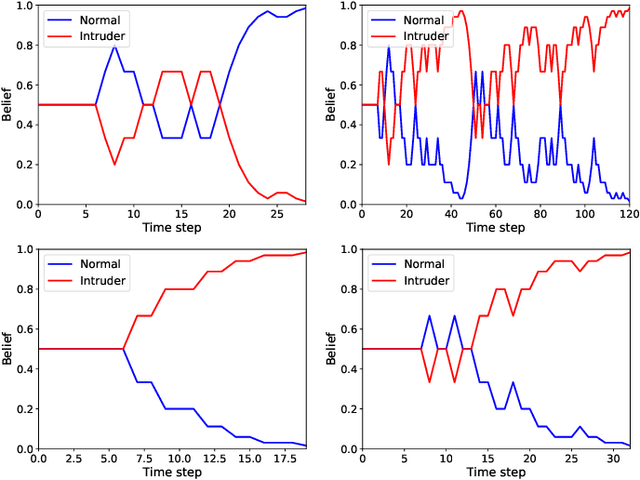
We study the detection problem for a finite set of Markov decision processes (MDPs) where the MDPs have the same state and action spaces but possibly different probabilistic transition functions. Any one of these MDPs could be the model for some underlying controlled stochastic process, but it is unknown a priori which MDP is the ground truth. We investigate whether it is possible to asymptotically detect the ground truth MDP model perfectly based on a single observed history (state-action sequence). Since the generation of histories depends on the policy adopted to control the MDPs, we discuss the existence and synthesis of policies that allow for perfect detection. We start with the case of two MDPs and establish a necessary and sufficient condition for the existence of policies that lead to perfect detection. Based on this condition, we then develop an algorithm that efficiently (in time polynomial in the size of the MDPs) determines the existence of policies and synthesizes one when they exist. We further extend the results to the more general case where there are more than two MDPs in the candidate set, and we develop a policy synthesis algorithm based on the breadth-first search and recursion. We demonstrate the effectiveness of our algorithms through numerical examples.
Machine Learning-Based Soft Sensors for Vacuum Distillation Unit
Nov 19, 2021
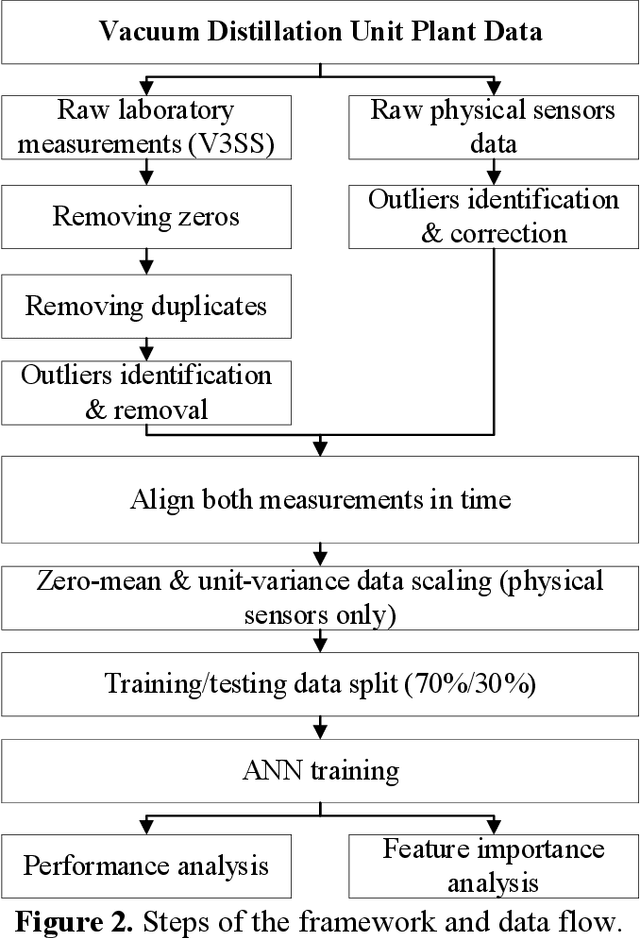
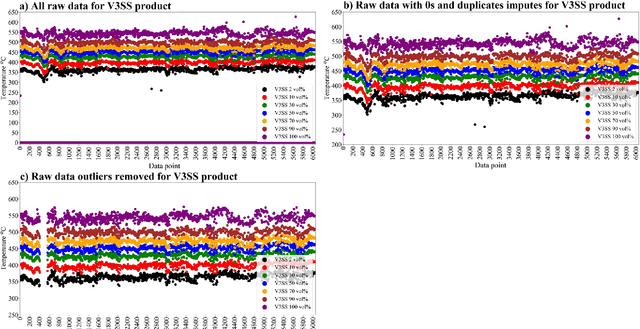
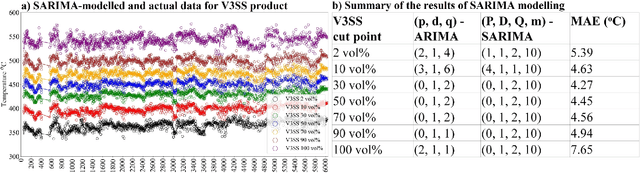
Product quality assessment in the petroleum processing industry can be difficult and time-consuming, e.g. due to a manual collection of liquid samples from the plant and subsequent chemical laboratory analysis of the samples. The product quality is an important property that informs whether the products of the process are within the specifications. In particular, the delays caused by sample processing (collection, laboratory measurements, results analysis, reporting) can lead to detrimental economic effects. One of the strategies to deal with this problem is soft sensors. Soft sensors are a collection of models that can be used to predict and forecast some infrequently measured properties (such as laboratory measurements of petroleum products) based on more frequent measurements of quantities like temperature, pressure and flow rate provided by physical sensors. Soft sensors short-cut the pathway to obtain relevant information about the product quality, often providing measurements as frequently as every minute. One of the applications of soft sensors is for the real-time optimization of a chemical process by a targeted adaptation of operating parameters. Models used for soft sensors can have various forms, however, among the most common are those based on artificial neural networks (ANNs). While soft sensors can deal with some of the issues in the refinery processes, their development and deployment can pose other challenges that are addressed in this paper. Firstly, it is important to enhance the quality of both sets of data (laboratory measurements and physical sensors) in a data pre-processing stage (as described in Methodology section). Secondly, once the data sets are pre-processed, different models need to be tested against prediction error and the model's interpretability. In this work, we present a framework for soft sensor development from raw data to ready-to-use models.
Combining Data-driven Supervision with Human-in-the-loop Feedback for Entity Resolution
Nov 20, 2021

The distribution gap between training datasets and data encountered in production is well acknowledged. Training datasets are often constructed over a fixed period of time and by carefully curating the data to be labeled. Thus, training datasets may not contain all possible variations of data that could be encountered in real-world production environments. Tasked with building an entity resolution system - a model that identifies and consolidates data points that represent the same person - our first model exhibited a clear training-production performance gap. In this case study, we discuss our human-in-the-loop enabled, data-centric solution to closing the training-production performance divergence. We conclude with takeaways that apply to data-centric learning at large.
Fast Image-Anomaly Mitigation for Autonomous Mobile Robots
Sep 04, 2021
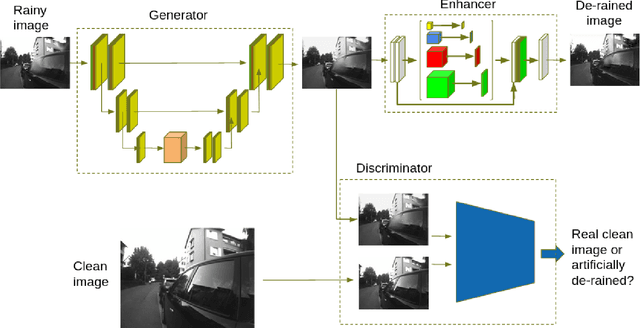
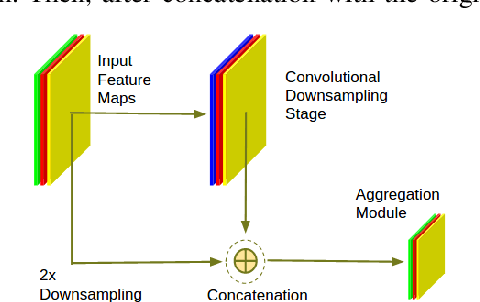

Camera anomalies like rain or dust can severelydegrade image quality and its related tasks, such as localizationand segmentation. In this work we address this importantissue by implementing a pre-processing step that can effectivelymitigate such artifacts in a real-time fashion, thus supportingthe deployment of autonomous systems with limited computecapabilities. We propose a shallow generator with aggregation,trained in an adversarial setting to solve the ill-posed problemof reconstructing the occluded regions. We add an enhancer tofurther preserve high-frequency details and image colorization.We also produce one of the largest publicly available datasets1to train our architecture and use realistic synthetic raindrops toobtain an improved initialization of the model. We benchmarkour framework on existing datasets and on our own imagesobtaining state-of-the-art results while enabling real-time per-formance, with up to 40x faster inference time than existingapproaches.