 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAccelerating AI Development with Cyber Arenas
Sep 10, 2025
AI development requires high fidelity testing environments to effectively transition from the laboratory to operations. The flexibility offered by cyber arenas presents a novel opportunity to test new artificial intelligence (AI) capabilities with users. Cyber arenas are designed to expose end-users to real-world situations and must rapidly incorporate evolving capabilities to meet their core objectives. To explore this concept the MIT/IEEE/Amazon Graph Challenge Anonymized Network Sensor was deployed in a cyber arena during a National Guard exercise.
Sustainable Supercomputing for AI: GPU Power Capping at HPC Scale
Feb 25, 2024



As research and deployment of AI grows, the computational burden to support and sustain its progress inevitably does too. To train or fine-tune state-of-the-art models in NLP, computer vision, etc., some form of AI hardware acceleration is virtually a requirement. Recent large language models require considerable resources to train and deploy, resulting in significant energy usage, potential carbon emissions, and massive demand for GPUs and other hardware accelerators. However, this surge carries large implications for energy sustainability at the HPC/datacenter level. In this paper, we study the aggregate effect of power-capping GPUs on GPU temperature and power draw at a research supercomputing center. With the right amount of power-capping, we show significant decreases in both temperature and power draw, reducing power consumption and potentially improving hardware life-span with minimal impact on job performance. While power-capping reduces power draw by design, the aggregate system-wide effect on overall energy consumption is less clear; for instance, if users notice job performance degradation from GPU power-caps, they may request additional GPU-jobs to compensate, negating any energy savings or even worsening energy consumption. To our knowledge, our work is the first to conduct and make available a detailed analysis of the effects of GPU power-capping at the supercomputing scale. We hope our work will inspire HPCs/datacenters to further explore, evaluate, and communicate the impact of power-capping AI hardware accelerators for more sustainable AI.
Lincoln AI Computing Survey (LAICS) Update
Oct 13, 2023


This paper is an update of the survey of AI accelerators and processors from past four years, which is now called the Lincoln AI Computing Survey - LAICS (pronounced "lace"). As in past years, this paper collects and summarizes the current commercial accelerators that have been publicly announced with peak performance and peak power consumption numbers. The performance and power values are plotted on a scatter graph, and a number of dimensions and observations from the trends on this plot are again discussed and analyzed. Market segments are highlighted on the scatter plot, and zoomed plots of each segment are also included. Finally, a brief description of each of the new accelerators that have been added in the survey this year is included.
From Words to Watts: Benchmarking the Energy Costs of Large Language Model Inference
Oct 04, 2023



Large language models (LLMs) have exploded in popularity due to their new generative capabilities that go far beyond prior state-of-the-art. These technologies are increasingly being leveraged in various domains such as law, finance, and medicine. However, these models carry significant computational challenges, especially the compute and energy costs required for inference. Inference energy costs already receive less attention than the energy costs of training LLMs -- despite how often these large models are called on to conduct inference in reality (e.g., ChatGPT). As these state-of-the-art LLMs see increasing usage and deployment in various domains, a better understanding of their resource utilization is crucial for cost-savings, scaling performance, efficient hardware usage, and optimal inference strategies. In this paper, we describe experiments conducted to study the computational and energy utilization of inference with LLMs. We benchmark and conduct a preliminary analysis of the inference performance and inference energy costs of different sizes of LLaMA -- a recent state-of-the-art LLM -- developed by Meta AI on two generations of popular GPUs (NVIDIA V100 \& A100) and two datasets (Alpaca and GSM8K) to reflect the diverse set of tasks/benchmarks for LLMs in research and practice. We present the results of multi-node, multi-GPU inference using model sharding across up to 32 GPUs. To our knowledge, our work is the one of the first to study LLM inference performance from the perspective of computational and energy resources at this scale.
Tensor Factorization for Leveraging Cross-Modal Knowledge in Data-Constrained Infrared Object Detection
Sep 28, 2023The primary bottleneck towards obtaining good recognition performance in IR images is the lack of sufficient labeled training data, owing to the cost of acquiring such data. Realizing that object detection methods for the RGB modality are quite robust (at least for some commonplace classes, like person, car, etc.), thanks to the giant training sets that exist, in this work we seek to leverage cues from the RGB modality to scale object detectors to the IR modality, while preserving model performance in the RGB modality. At the core of our method, is a novel tensor decomposition method called TensorFact which splits the convolution kernels of a layer of a Convolutional Neural Network (CNN) into low-rank factor matrices, with fewer parameters than the original CNN. We first pretrain these factor matrices on the RGB modality, for which plenty of training data are assumed to exist and then augment only a few trainable parameters for training on the IR modality to avoid over-fitting, while encouraging them to capture complementary cues from those trained only on the RGB modality. We validate our approach empirically by first assessing how well our TensorFact decomposed network performs at the task of detecting objects in RGB images vis-a-vis the original network and then look at how well it adapts to IR images of the FLIR ADAS v1 dataset. For the latter, we train models under scenarios that pose challenges stemming from data paucity. From the experiments, we observe that: (i) TensorFact shows performance gains on RGB images; (ii) further, this pre-trained model, when fine-tuned, outperforms a standard state-of-the-art object detector on the FLIR ADAS v1 dataset by about 4% in terms of mAP 50 score.
Pixel-Grounded Prototypical Part Networks
Sep 25, 2023



Prototypical part neural networks (ProtoPartNNs), namely PROTOPNET and its derivatives, are an intrinsically interpretable approach to machine learning. Their prototype learning scheme enables intuitive explanations of the form, this (prototype) looks like that (testing image patch). But, does this actually look like that? In this work, we delve into why object part localization and associated heat maps in past work are misleading. Rather than localizing to object parts, existing ProtoPartNNs localize to the entire image, contrary to generated explanatory visualizations. We argue that detraction from these underlying issues is due to the alluring nature of visualizations and an over-reliance on intuition. To alleviate these issues, we devise new receptive field-based architectural constraints for meaningful localization and a principled pixel space mapping for ProtoPartNNs. To improve interpretability, we propose additional architectural improvements, including a simplified classification head. We also make additional corrections to PROTOPNET and its derivatives, such as the use of a validation set, rather than a test set, to evaluate generalization during training. Our approach, PIXPNET (Pixel-grounded Prototypical part Network), is the only ProtoPartNN that truly learns and localizes to prototypical object parts. We demonstrate that PIXPNET achieves quantifiably improved interpretability without sacrificing accuracy.
A Green(er) World for A.I
Jan 27, 2023



As research and practice in artificial intelligence (A.I.) grow in leaps and bounds, the resources necessary to sustain and support their operations also grow at an increasing pace. While innovations and applications from A.I. have brought significant advances, from applications to vision and natural language to improvements to fields like medical imaging and materials engineering, their costs should not be neglected. As we embrace a world with ever-increasing amounts of data as well as research and development of A.I. applications, we are sure to face an ever-mounting energy footprint to sustain these computational budgets, data storage needs, and more. But, is this sustainable and, more importantly, what kind of setting is best positioned to nurture such sustainable A.I. in both research and practice? In this paper, we outline our outlook for Green A.I. -- a more sustainable, energy-efficient and energy-aware ecosystem for developing A.I. across the research, computing, and practitioner communities alike -- and the steps required to arrive there. We present a bird's eye view of various areas for potential changes and improvements from the ground floor of AI's operational and hardware optimizations for datacenters/HPCs to the current incentive structures in the world of A.I. research and practice, and more. We hope these points will spur further discussion, and action, on some of these issues and their potential solutions.
* 8 pages, published in 2022 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW)
An Evaluation of Low Overhead Time Series Preprocessing Techniques for Downstream Machine Learning
Sep 12, 2022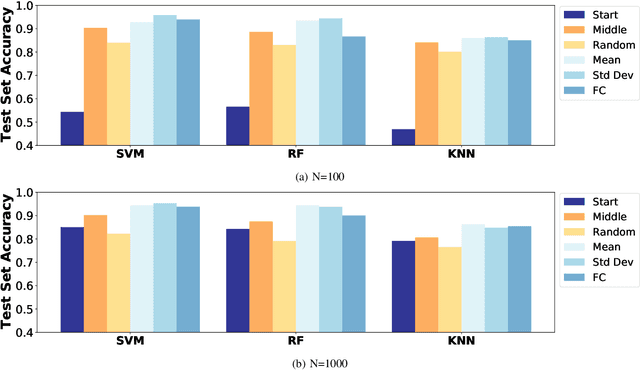
In this paper we address the application of pre-processing techniques to multi-channel time series data with varying lengths, which we refer to as the alignment problem, for downstream machine learning. The misalignment of multi-channel time series data may occur for a variety of reasons, such as missing data, varying sampling rates, or inconsistent collection times. We consider multi-channel time series data collected from the MIT SuperCloud High Performance Computing (HPC) center, where different job start times and varying run times of HPC jobs result in misaligned data. This misalignment makes it challenging to build AI/ML approaches for tasks such as compute workload classification. Building on previous supervised classification work with the MIT SuperCloud Dataset, we address the alignment problem via three broad, low overhead approaches: sampling a fixed subset from a full time series, performing summary statistics on a full time series, and sampling a subset of coefficients from time series mapped to the frequency domain. Our best performing models achieve a classification accuracy greater than 95%, outperforming previous approaches to multi-channel time series classification with the MIT SuperCloud Dataset by 5%. These results indicate our low overhead approaches to solving the alignment problem, in conjunction with standard machine learning techniques, are able to achieve high levels of classification accuracy, and serve as a baseline for future approaches to addressing the alignment problem, such as kernel methods.
The MIT Supercloud Workload Classification Challenge
Apr 13, 2022

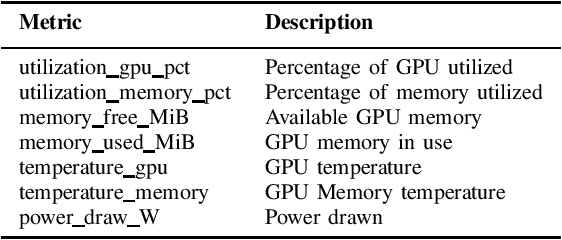
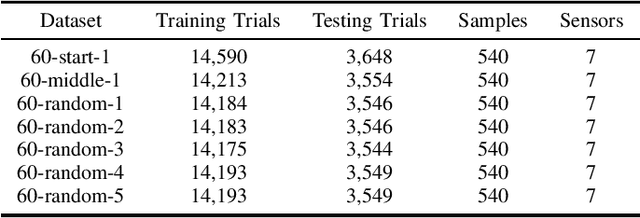
High-Performance Computing (HPC) centers and cloud providers support an increasingly diverse set of applications on heterogenous hardware. As Artificial Intelligence (AI) and Machine Learning (ML) workloads have become an increasingly larger share of the compute workloads, new approaches to optimized resource usage, allocation, and deployment of new AI frameworks are needed. By identifying compute workloads and their utilization characteristics, HPC systems may be able to better match available resources with the application demand. By leveraging datacenter instrumentation, it may be possible to develop AI-based approaches that can identify workloads and provide feedback to researchers and datacenter operators for improving operational efficiency. To enable this research, we released the MIT Supercloud Dataset, which provides detailed monitoring logs from the MIT Supercloud cluster. This dataset includes CPU and GPU usage by jobs, memory usage, and file system logs. In this paper, we present a workload classification challenge based on this dataset. We introduce a labelled dataset that can be used to develop new approaches to workload classification and present initial results based on existing approaches. The goal of this challenge is to foster algorithmic innovations in the analysis of compute workloads that can achieve higher accuracy than existing methods. Data and code will be made publicly available via the Datacenter Challenge website : https://dcc.mit.edu.
Converse: A Tree-Based Modular Task-Oriented Dialogue System
Mar 30, 2022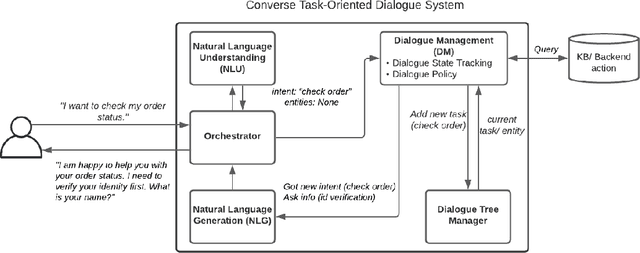

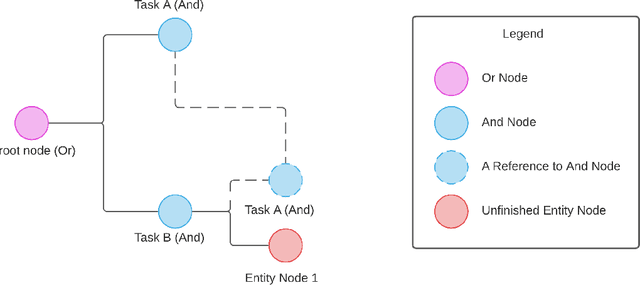
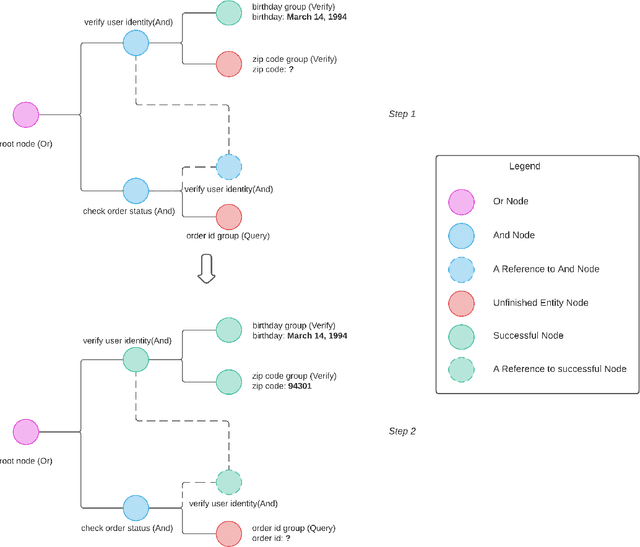
Creating a system that can have meaningful conversations with humans to help accomplish tasks is one of the ultimate goals of Artificial Intelligence (AI). It has defined the meaning of AI since the beginning. A lot has been accomplished in this area recently, with voice assistant products entering our daily lives and chat bot systems becoming commonplace in customer service. At first glance there seems to be no shortage of options for dialogue systems. However, the frequently deployed dialogue systems today seem to all struggle with a critical weakness - they are hard to build and harder to maintain. At the core of the struggle is the need to script every single turn of interactions between the bot and the human user. This makes the dialogue systems more difficult to maintain as the tasks become more complex and more tasks are added to the system. In this paper, we propose Converse, a flexible tree-based modular task-oriented dialogue system. Converse uses an and-or tree structure to represent tasks and offers powerful multi-task dialogue management. Converse supports task dependency and task switching, which are unique features compared to other open-source dialogue frameworks. At the same time, Converse aims to make the bot building process easy and simple, for both professional and non-professional software developers. The code is available at https://github.com/salesforce/Converse.