 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Cardiac Intervention Assistance: Hardware-aware Neural Architecture Exploration for Real-Time 3D Cardiac Cine MRI Segmentation
Aug 17, 2020
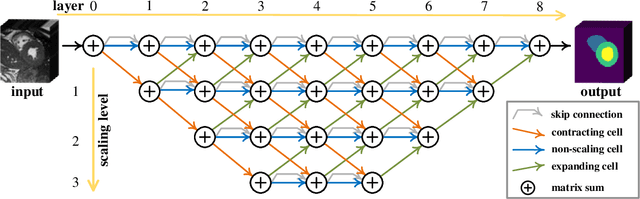
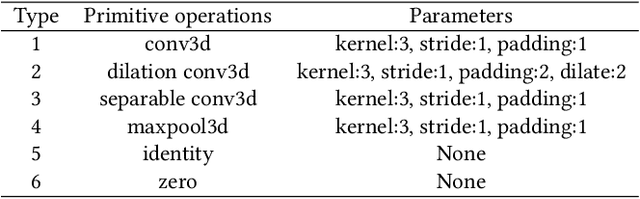
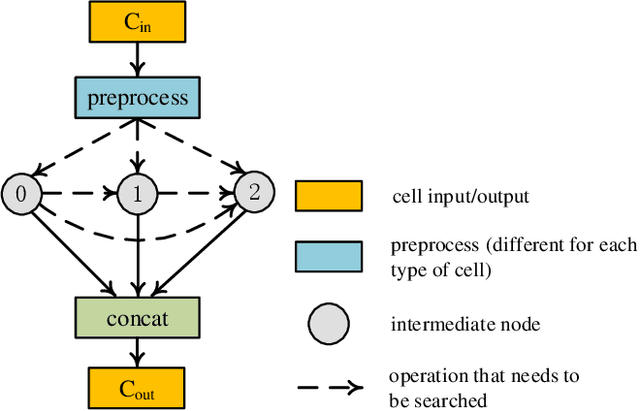
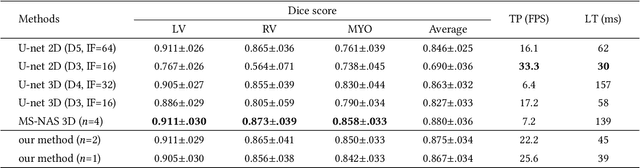
Real-time cardiac magnetic resonance imaging (MRI) plays an increasingly important role in guiding various cardiac interventions. In order to provide better visual assistance, the cine MRI frames need to be segmented on-the-fly to avoid noticeable visual lag. In addition, considering reliability and patient data privacy, the computation is preferably done on local hardware. State-of-the-art MRI segmentation methods mostly focus on accuracy only, and can hardly be adopted for real-time application or on local hardware. In this work, we present the first hardware-aware multi-scale neural architecture search (NAS) framework for real-time 3D cardiac cine MRI segmentation. The proposed framework incorporates a latency regularization term into the loss function to handle real-time constraints, with the consideration of underlying hardware. In addition, the formulation is fully differentiable with respect to the architecture parameters, so that stochastic gradient descent (SGD) can be used for optimization to reduce the computation cost while maintaining optimization quality. Experimental results on ACDC MICCAI 2017 dataset demonstrate that our hardware-aware multi-scale NAS framework can reduce the latency by up to 3.5 times and satisfy the real-time constraints, while still achieving competitive segmentation accuracy, compared with the state-of-the-art NAS segmentation framework.
Bayesian Learning via Neural Schrödinger-Föllmer Flows
Nov 23, 2021
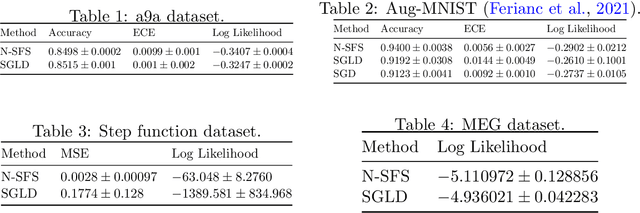
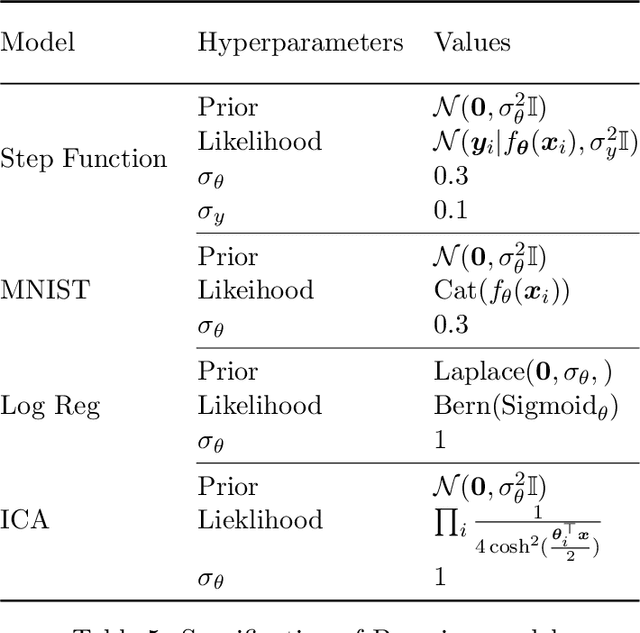
In this work we explore a new framework for approximate Bayesian inference in large datasets based on stochastic control. We advocate stochastic control as a finite time alternative to popular steady-state methods such as stochastic gradient Langevin dynamics (SGLD). Furthermore, we discuss and adapt the existing theoretical guarantees of this framework and establish connections to already existing VI routines in SDE-based models.
Hybrid Reinforcement Learning-Based Eco-Driving Strategy for Connected and Automated Vehicles at Signalized Intersections
Jan 28, 2022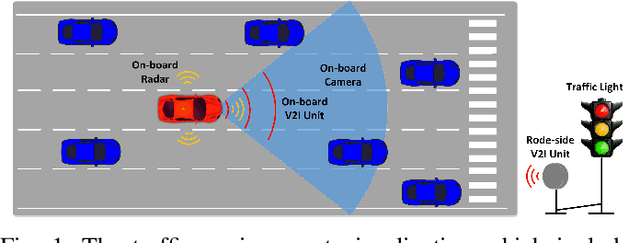
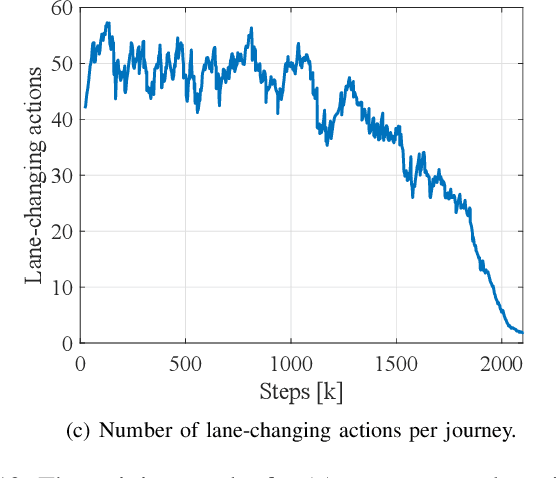
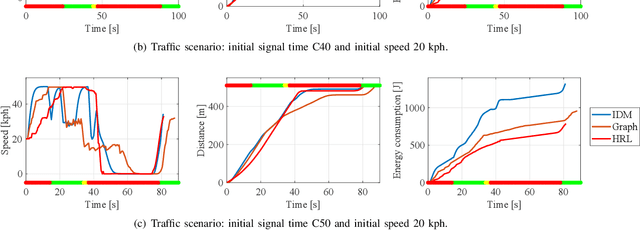
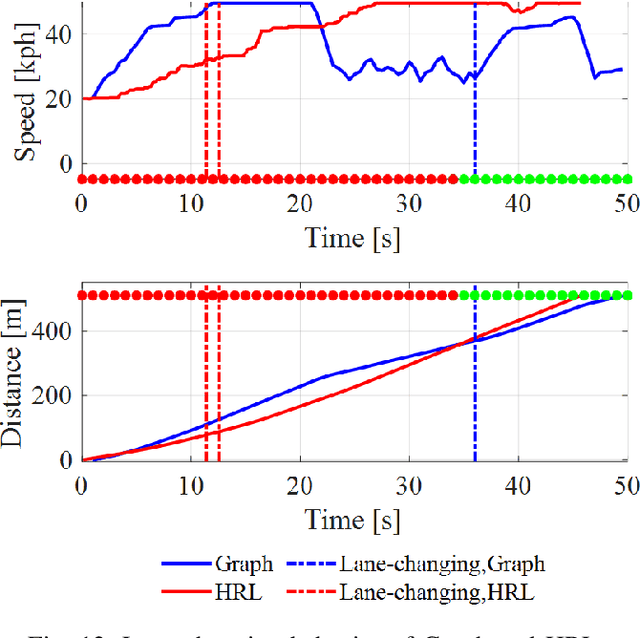
Taking advantage of both vehicle-to-everything (V2X) communication and automated driving technology, connected and automated vehicles are quickly becoming one of the transformative solutions to many transportation problems. However, in a mixed traffic environment at signalized intersections, it is still a challenging task to improve overall throughput and energy efficiency considering the complexity and uncertainty in the traffic system. In this study, we proposed a hybrid reinforcement learning (HRL) framework which combines the rule-based strategy and the deep reinforcement learning (deep RL) to support connected eco-driving at signalized intersections in mixed traffic. Vision-perceptive methods are integrated with vehicle-to-infrastructure (V2I) communications to achieve higher mobility and energy efficiency in mixed connected traffic. The HRL framework has three components: a rule-based driving manager that operates the collaboration between the rule-based policies and the RL policy; a multi-stream neural network that extracts the hidden features of vision and V2I information; and a deep RL-based policy network that generate both longitudinal and lateral eco-driving actions. In order to evaluate our approach, we developed a Unity-based simulator and designed a mixed-traffic intersection scenario. Moreover, several baselines were implemented to compare with our new design, and numerical experiments were conducted to test the performance of the HRL model. The experiments show that our HRL method can reduce energy consumption by 12.70% and save 11.75% travel time when compared with a state-of-the-art model-based Eco-Driving approach.
Adaptive Group Lasso Neural Network Models for Functions of Few Variables and Time-Dependent Data
Aug 24, 2021
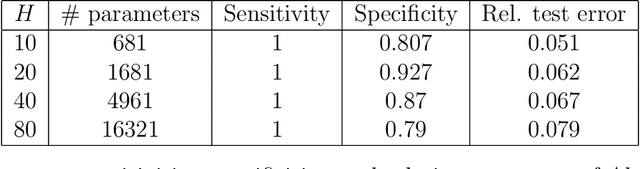
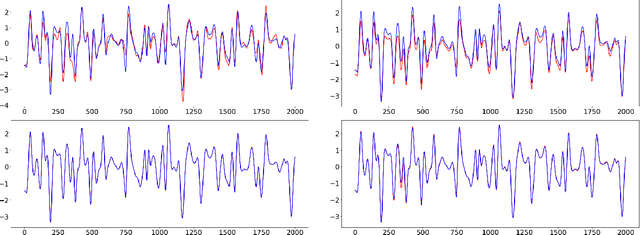

In this paper, we propose an adaptive group Lasso deep neural network for high-dimensional function approximation where input data are generated from a dynamical system and the target function depends on few active variables or few linear combinations of variables. We approximate the target function by a deep neural network and enforce an adaptive group Lasso constraint to the weights of a suitable hidden layer in order to represent the constraint on the target function. Our empirical studies show that the proposed method outperforms recent state-of-the-art methods including the sparse dictionary matrix method, neural networks with or without group Lasso penalty.
Video Summarization Based on Video-text Modelling
Jan 10, 2022
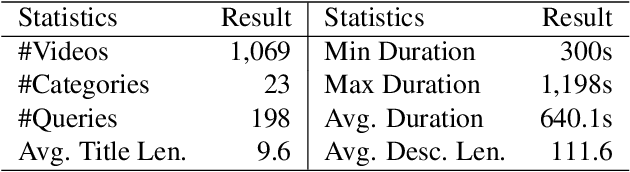
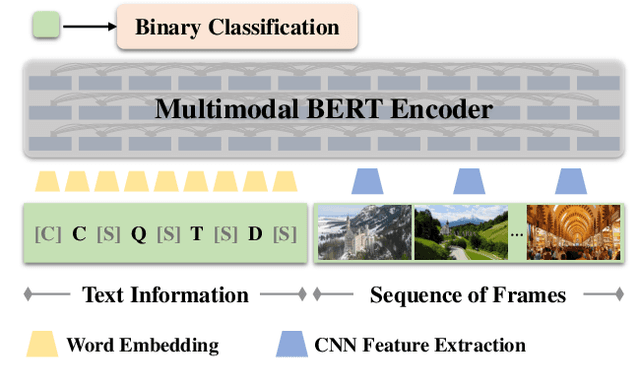
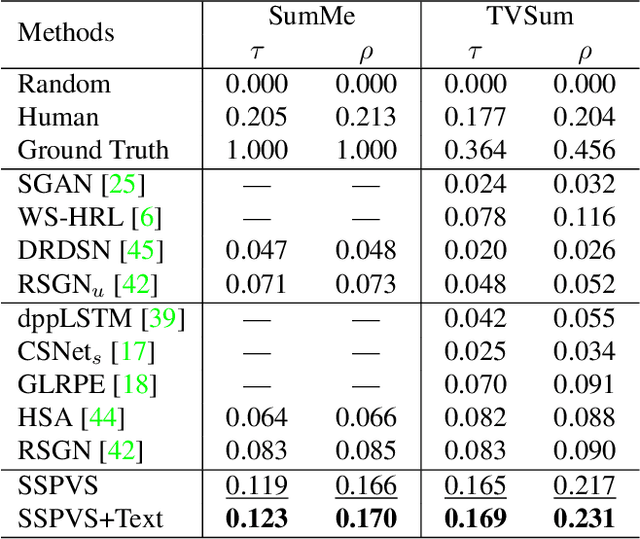
Modern video summarization methods are based on deep neural networks which require a large amount of annotated data for training. However, existing datasets for video summarization are small-scale, easily leading to over-fitting of the deep models. Considering that the annotation of large-scale datasets is time-consuming, we propose a multimodal self-supervised learning framework to obtain semantic representations of videos, which benefits the video summarization task. Specifically, we explore the semantic consistency between the visual information and text information of videos, for the self-supervised pretraining of a multimodal encoder on a newly-collected dataset of video-text pairs. Additionally, we introduce a progressive video summarization method, where the important content in a video is pinpointed progressively to generate better summaries. Finally, an objective evaluation framework is proposed to measure the quality of video summaries based on video classification. Extensive experiments have proved the effectiveness and superiority of our method in rank correlation coefficients, F-score, and the proposed objective evaluation compared to the state of the art.
A Machine Learning Approach for Material Type Logging and Chemical Assaying from Autonomous Measure-While-Drilling (MWD) Data
Feb 07, 2022

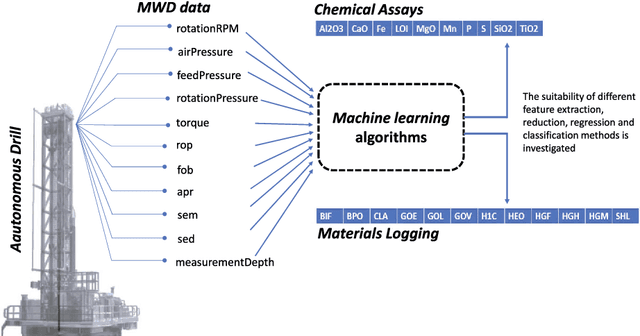
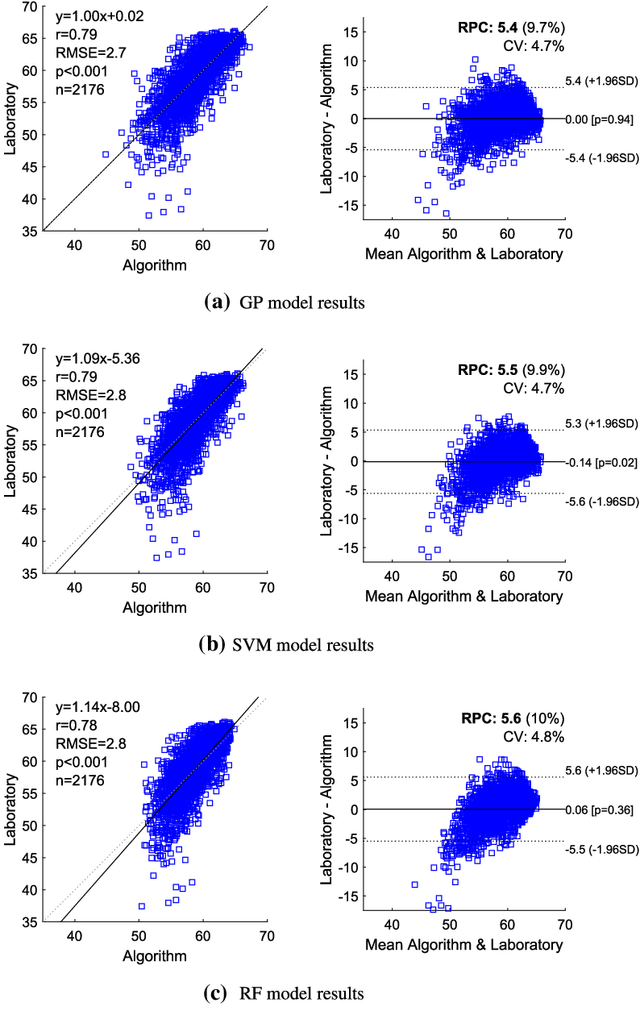
Understanding the structure and mineralogical composition of a region is an essential step in mining, both during exploration (before mining) and in the mining process. During exploration, sparse but high-quality data are gathered to assess the overall orebody. During the mining process, boundary positions and material properties are refined as the mine progresses. This refinement is facilitated through drilling, material logging, and chemical assaying. Material type logging suffers from a high degree of variability due to factors such as the diversity in mineralization and geology, the subjective nature of human measurement even by experts, and human error in manually recording results. While laboratory-based chemical assaying is much more precise, it is time-consuming and costly and does not always capture or correlate boundary positions between all material types. This leads to significant challenges and financial implications for the industry, as the accuracy of production blasthole logging and assaying processes is essential for resource evaluation, planning, and execution of mine plans. To overcome these challenges, this work reports on a pilot study to automate the process of material logging and chemical assaying. A machine learning approach has been trained on features extracted from measurement-while-drilling (MWD) data, logged from autonomous drilling systems (ADS). MWD data facilitate the construction of profiles of physical drilling parameters as a function of hole depth. A hypothesis is formed to link these drilling parameters to the underlying mineral composition. The results of the pilot study discussed in this paper demonstrate the feasibility of this process, with correlation coefficients of up to 0.92 for chemical assays and 93% accuracy for material detection, depending on the material or assay type and their generalization across the different spatial regions.
* 29 pages, 19 figures, mathematical geosciences, Rio Tinto Centre for Mine Automation
Dynamic Time Warping as a New Evaluation for Dst Forecast with Machine Learning
Jun 08, 2020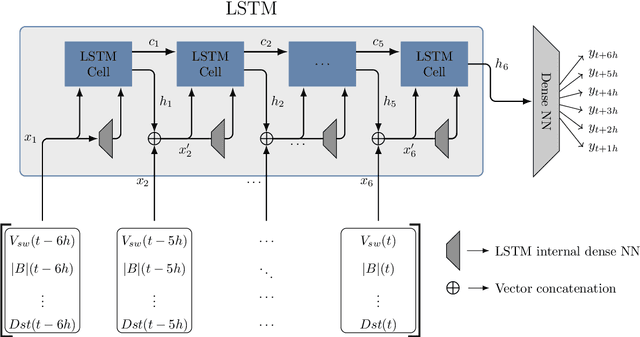
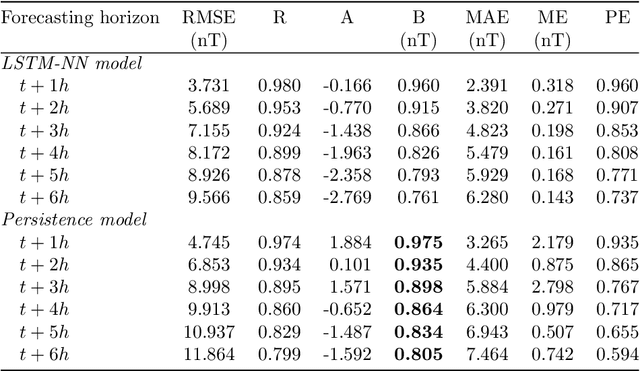
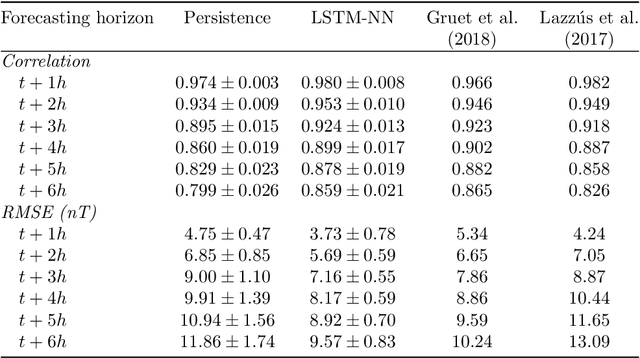
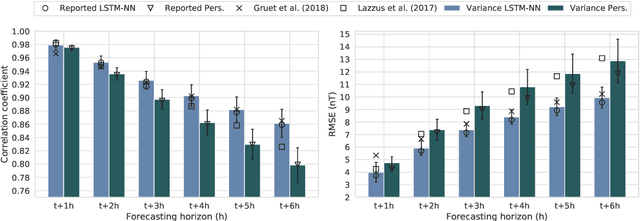
Models based on neural networks and machine learning are seeing a rise in popularity in space physics. In particular, the forecasting of geomagnetic indices with neural network models is becoming a popular field of study. These models are evaluated with metrics such as the root-mean-square error (RMSE) and Pearson correlation coefficient. However, these classical metrics sometimes fail to capture crucial behavior. To show where the classical metrics are lacking, we trained a neural network, using a long short-term memory network, to make a forecast of the disturbance storm time index at origin time $t$ with a forecasting horizon of 1 up to 6 hours, trained on OMNIWeb data. Inspection of the model's results with the correlation coefficient and RMSE indicated a performance comparable to the latest publications. However, visual inspection showed that the predictions made by the neural network were behaving similarly to the persistence model. In this work, a new method is proposed to measure whether two time series are shifted in time with respect to each other, such as the persistence model output versus the observation. The new measure, based on Dynamical Time Warping, is capable of identifying results made by the persistence model and shows promising results in confirming the visual observations of the neural network's output. Finally, different methodologies for training the neural network are explored in order to remove the persistence behavior from the results.
Sketch2PQ: Freeform Planar Quadrilateral Mesh Design via a Single Sketch
Jan 23, 2022
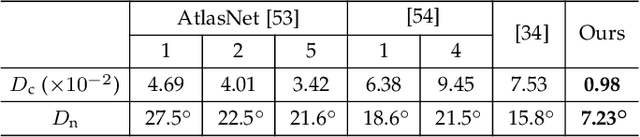
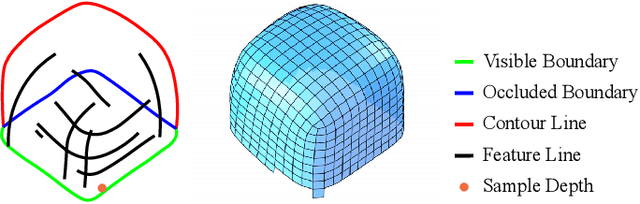
The freeform architectural modeling process often involves two important stages: concept design and digital modeling. In the first stage, architects usually sketch the overall 3D shape and the panel layout on a physical or digital paper briefly. In the second stage, a digital 3D model is created using the sketching as the reference. The digital model needs to incorporate geometric requirements for its components, such as planarity of panels due to consideration of construction costs, which can make the modeling process more challenging. In this work, we present a novel sketch-based system to bridge the concept design and digital modeling of freeform roof-like shapes represented as planar quadrilateral (PQ) meshes. Our system allows the user to sketch the surface boundary and contour lines under axonometric projection and supports the sketching of occluded regions. In addition, the user can sketch feature lines to provide directional guidance to the PQ mesh layout. Given the 2D sketch input, we propose a deep neural network to infer in real-time the underlying surface shape along with a dense conjugate direction field, both of which are used to extract the final PQ mesh. To train and validate our network, we generate a large synthetic dataset that mimics architect sketching of freeform quadrilateral patches. The effectiveness and usability of our system are demonstrated with quantitative and qualitative evaluation as well as user studies.
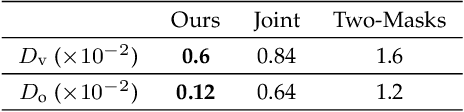
Learning Fine-Grained Motion Embedding for Landscape Animation
Sep 13, 2021

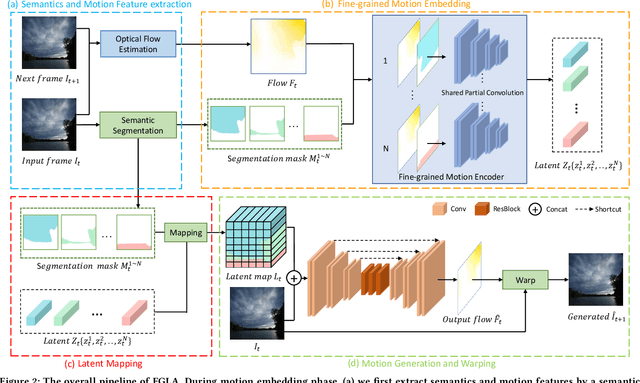
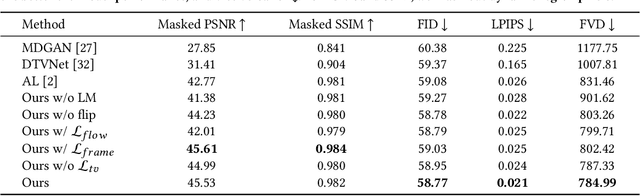
In this paper we focus on landscape animation, which aims to generate time-lapse videos from a single landscape image. Motion is crucial for landscape animation as it determines how objects move in videos. Existing methods are able to generate appealing videos by learning motion from real time-lapse videos. However, current methods suffer from inaccurate motion generation, which leads to unrealistic video results. To tackle this problem, we propose a model named FGLA to generate high-quality and realistic videos by learning Fine-Grained motion embedding for Landscape Animation. Our model consists of two parts: (1) a motion encoder which embeds time-lapse motion in a fine-grained way. (2) a motion generator which generates realistic motion to animate input images. To train and evaluate on diverse time-lapse videos, we build the largest high-resolution Time-lapse video dataset with Diverse scenes, namely Time-lapse-D, which includes 16,874 video clips with over 10 million frames. Quantitative and qualitative experimental results demonstrate the superiority of our method. In particular, our method achieves relative improvements by 19% on LIPIS and 5.6% on FVD compared with state-of-the-art methods on our dataset. A user study carried out with 700 human subjects shows that our approach visually outperforms existing methods by a large margin.
Ice hockey player identification via transformers
Nov 22, 2021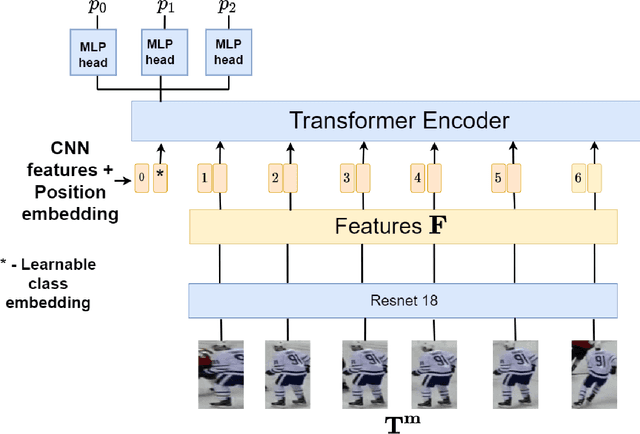
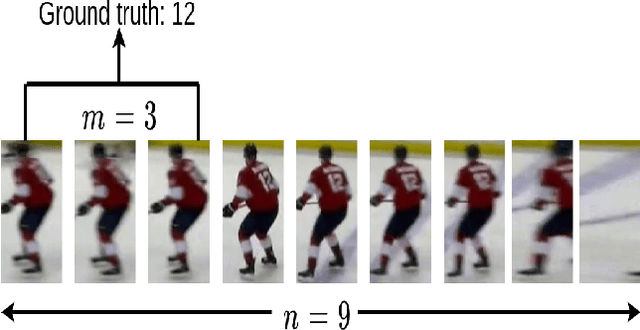
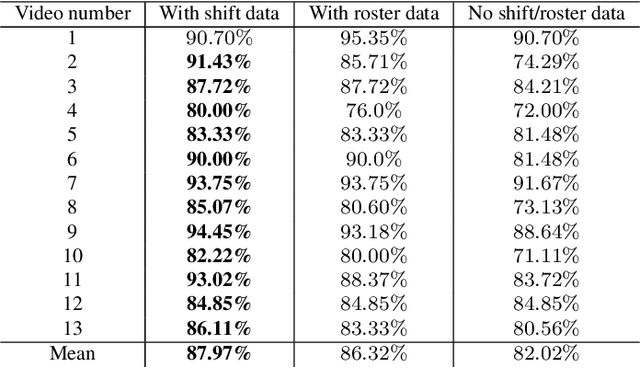
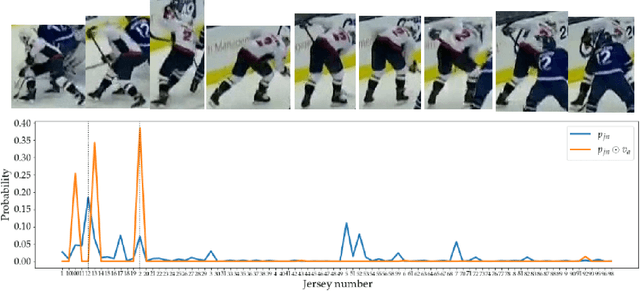
Identifying players in video is a foundational step in computer vision-based sports analytics. Obtaining player identities is essential for analyzing the game and is used in downstream tasks such as game event recognition. Transformers are the existing standard in Natural Language Processing (NLP) and are swiftly gaining traction in computer vision. Motivated by the increasing success of transformers in computer vision, in this paper, we introduce a transformer network for recognizing players through their jersey numbers in broadcast National Hockey League (NHL) videos. The transformer takes temporal sequences of player frames (also called player tracklets) as input and outputs the probabilities of jersey numbers present in the frames. The proposed network performs better than the previous benchmark on the dataset used. We implement a weakly-supervised training approach by generating approximate frame-level labels for jersey number presence and use the frame-level labels for faster training. We also utilize player shifts available in the NHL play-by-play data by reading the game time using optical character recognition (OCR) to get the players on the ice rink at a certain game time. Using player shifts improved the player identification accuracy by 6%.