 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Web-Based File Clustering and Indexing for Mindoro State University
Feb 13, 2022
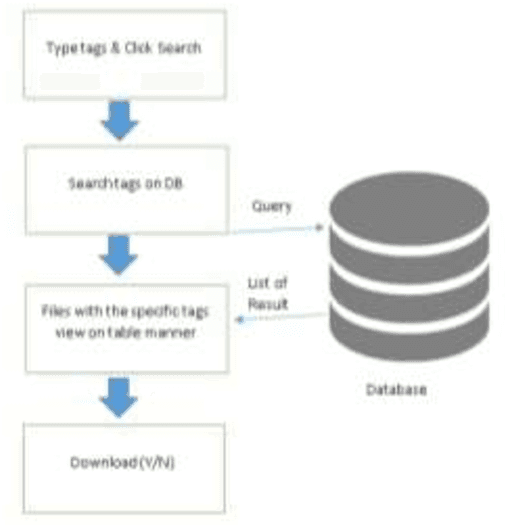

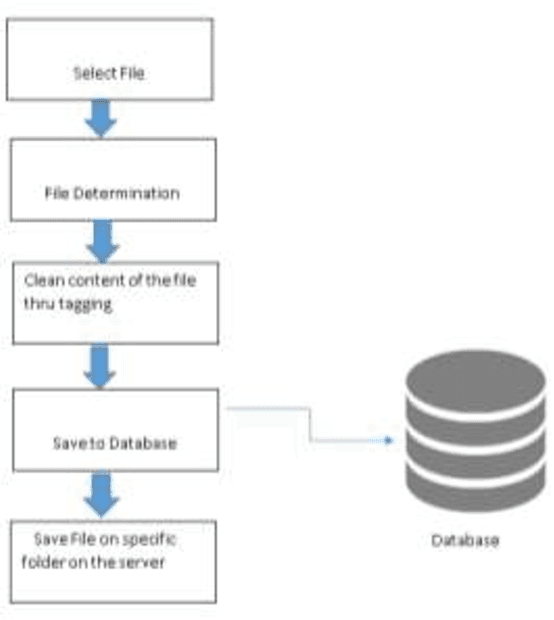
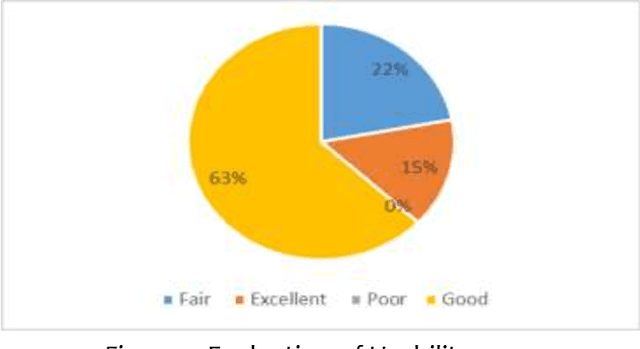
The Web Based File Clustering and Indexing for Mindoro State University aim to organize data circulated over the Web into groups or collections to facilitate data availability and access and at the same time meet user preferences. The main benefits include increasing Web information accessibility, understanding users navigation behavior, improving information retrieval and content delivery on the Web. Web based file clustering could help in reaching the required documents that the user is searching for. In this paper a novel approach has been introduced for search results clustering that is based on the semantics of the retrieved documents rather than the syntax of the terms in those documents. Data clustering was used to improve the information retrieval from the collection of documents. Data were processed and analyzed using SPSS where the instrument was evaluated to test the reliability and validity of the measures used. Evaluation was based on a Likert scale of Excellent, Good, Fair, and Poor as described for the selected quality characteristics.
* 11 pages, 9 figures, 1 table
MFA: TDNN with Multi-scale Frequency-channel Attention for Text-independent Speaker Verification with Short Utterances
Feb 04, 2022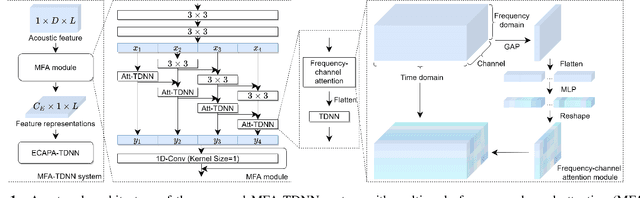
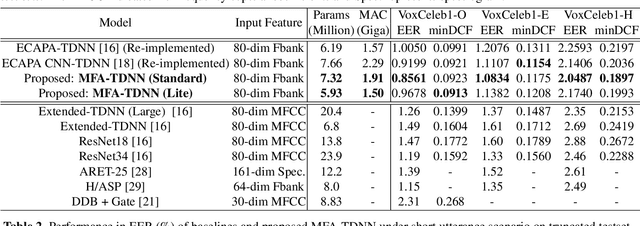
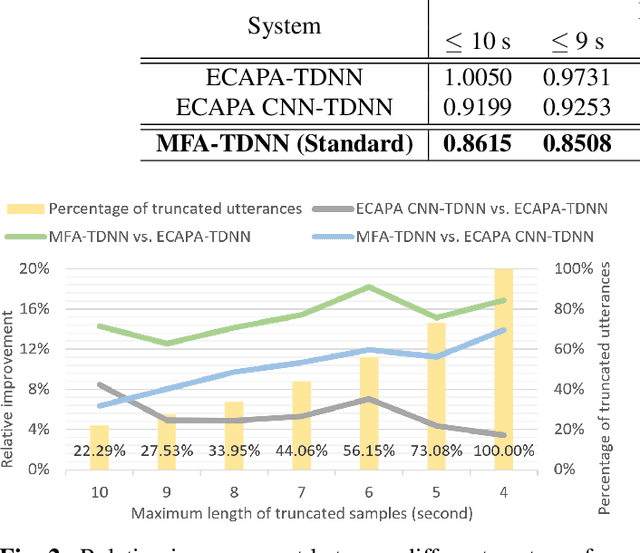
The time delay neural network (TDNN) represents one of the state-of-the-art of neural solutions to text-independent speaker verification. However, they require a large number of filters to capture the speaker characteristics at any local frequency region. In addition, the performance of such systems may degrade under short utterance scenarios. To address these issues, we propose a multi-scale frequency-channel attention (MFA), where we characterize speakers at different scales through a novel dual-path design which consists of a convolutional neural network and TDNN. We evaluate the proposed MFA on the VoxCeleb database and observe that the proposed framework with MFA can achieve state-of-the-art performance while reducing parameters and computation complexity. Further, the MFA mechanism is found to be effective for speaker verification with short test utterances.
Targeted Data Poisoning Attack on News Recommendation System by Content Perturbation
Mar 10, 2022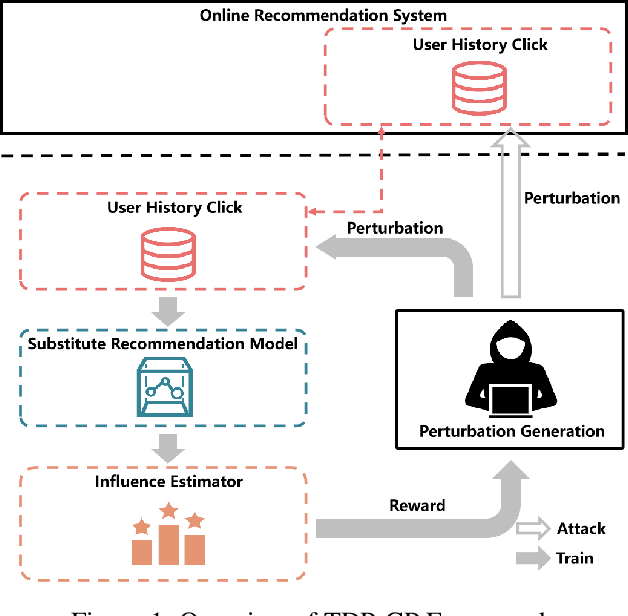
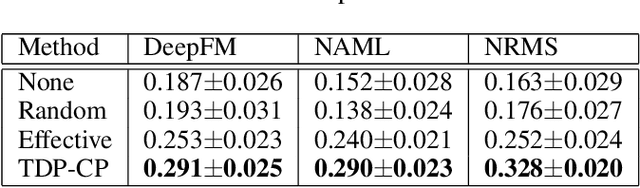
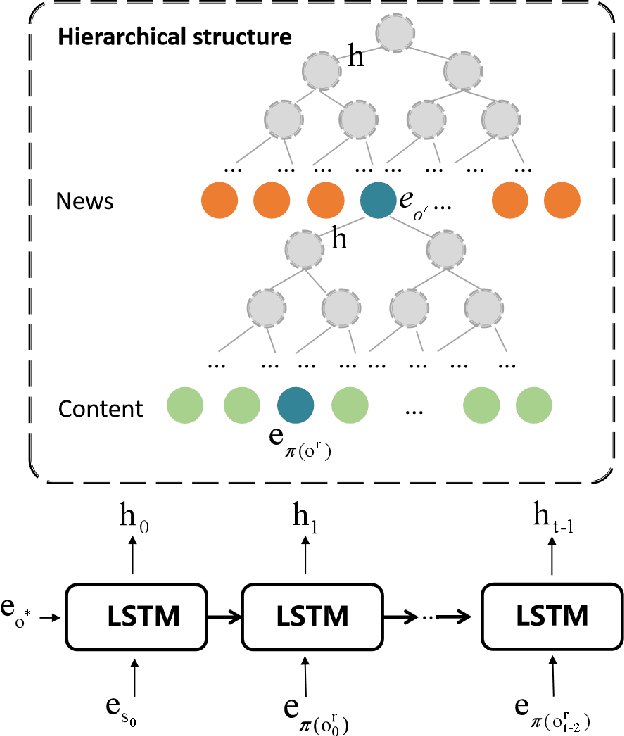
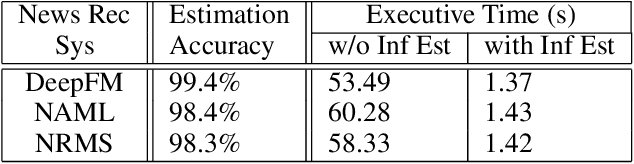
News Recommendation System(NRS) has become a fundamental technology to many online news services. Meanwhile, several studies show that recommendation systems(RS) are vulnerable to data poisoning attacks, and the attackers have the ability to mislead the system to perform as their desires. A widely studied attack approach, injecting fake users, can be applied on the NRS when the NRS is treated the same as the other systems whose items are fixed. However, in the NRS, as each item (i.e. news) is more informative, we propose a novel approach to poison the NRS, which is to perturb contents of some browsed news that results in the manipulation of the rank of the target news. Intuitively, an attack is useless if it is highly likely to be caught, i.e., exposed. To address this, we introduce a notion of the exposure risk and propose a novel problem of attacking a history news dataset by means of perturbations where the goal is to maximize the manipulation of the target news rank while keeping the risk of exposure under a given budget. We design a reinforcement learning framework, called TDP-CP, which contains a two-stage hierarchical model to reduce the searching space. Meanwhile, influence estimation is also applied to save the time on retraining the NRS for rewards. We test the performance of TDP-CP under three NRSs and on different target news. Our experiments show that TDP-CP can increase the rank of the target news successfully with a limited exposure budget.
SEED: Sound Event Early Detection via Evidential Uncertainty
Feb 13, 2022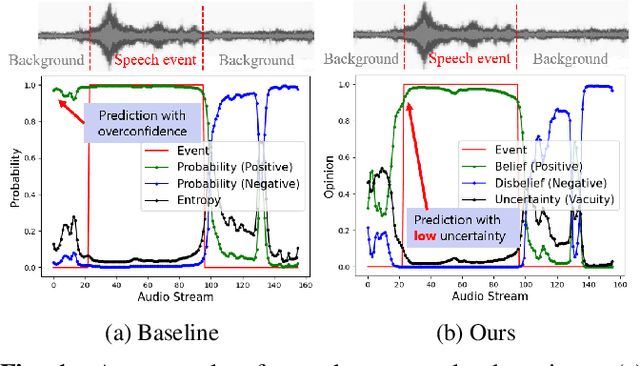

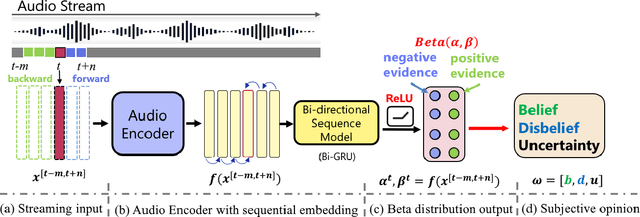
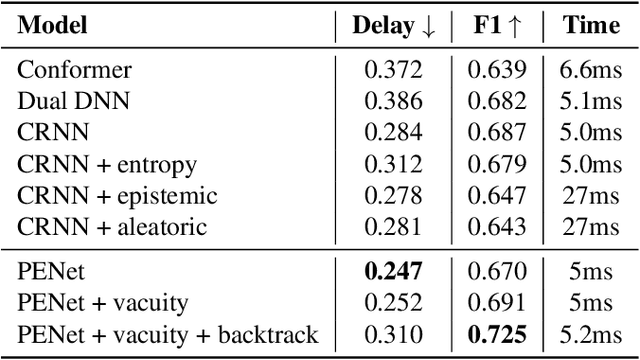
Sound Event Early Detection (SEED) is an essential task in recognizing the acoustic environments and soundscapes. However, most of the existing methods focus on the offline sound event detection, which suffers from the over-confidence issue of early-stage event detection and usually yield unreliable results. To solve the problem, we propose a novel Polyphonic Evidential Neural Network (PENet) to model the evidential uncertainty of the class probability with Beta distribution. Specifically, we use a Beta distribution to model the distribution of class probabilities, and the evidential uncertainty enriches uncertainty representation with evidence information, which plays a central role in reliable prediction. To further improve the event detection performance, we design the backtrack inference method that utilizes both the forward and backward audio features of an ongoing event. Experiments on the DESED database show that the proposed method can simultaneously improve 13.0\% and 3.8\% in time delay and detection F1 score compared to the state-of-the-art methods.
Worsening Perception: Real-time Degradation of Autonomous Vehicle Perception Performance for Simulation of Adverse Weather Conditions
Mar 03, 2021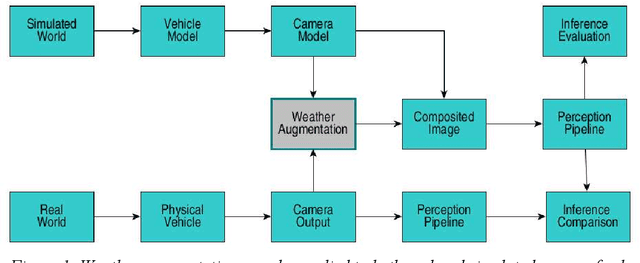


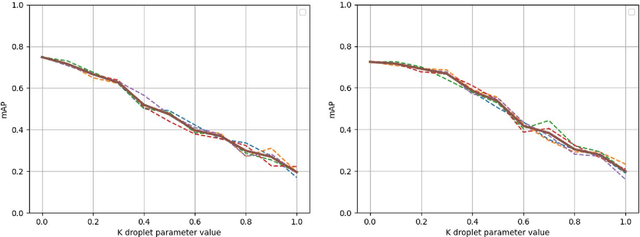
Autonomous vehicles rely heavily upon their perception subsystems to see the environment in which they operate. Unfortunately, the effect of varying weather conditions presents a significant challenge to object detection algorithms, and thus it is imperative to test the vehicle extensively in all conditions which it may experience. However, unpredictable weather can make real-world testing in adverse conditions an expensive and time consuming task requiring access to specialist facilities, and weatherproofing of sensitive electronics. Simulation provides an alternative to real world testing, with some studies developing increasingly visually realistic representations of the real world on powerful compute hardware. Given that subsequent subsystems in the autonomous vehicle pipeline are unaware of the visual realism of the simulation, when developing modules downstream of perception the appearance is of little consequence - rather it is how the perception system performs in the prevailing weather condition that is important. This study explores the potential of using a simple, lightweight image augmentation system in an autonomous racing vehicle - focusing not on visual accuracy, but rather the effect upon perception system performance. With minimal adjustment, the prototype system developed in this study can replicate the effects of both water droplets on the camera lens, and fading light conditions. The system introduces a latency of less than 8 ms using compute hardware that is well suited to being carried in the vehicle - rendering it ideally suited to real-time implementation that can be run during experiments in simulation, and augmented reality testing in the real world.
Improving performance of aircraft detection in satellite imagery while limiting the labelling effort: Hybrid active learning
Feb 10, 2022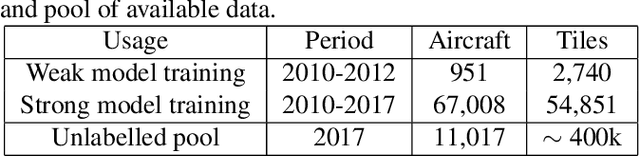
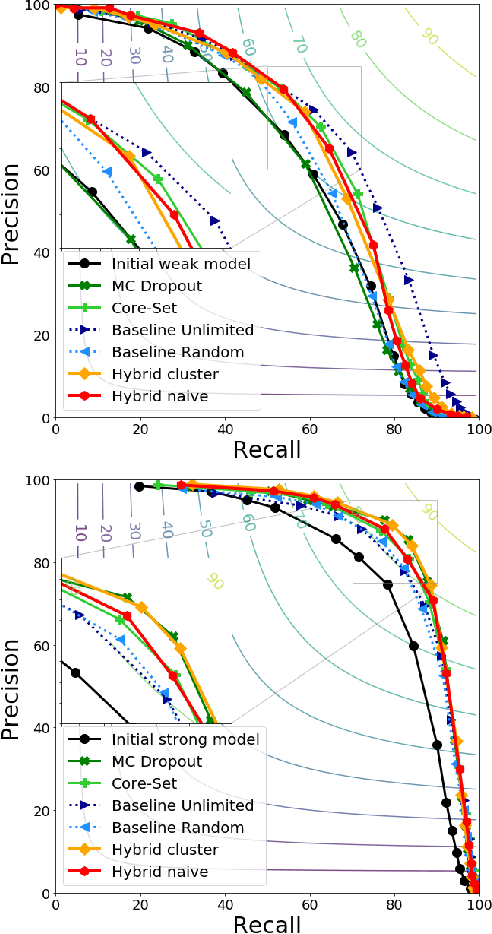
The earth observation industry provides satellite imagery with high spatial resolution and short revisit time. To allow efficient operational employment of these images, automating certain tasks has become necessary. In the defense domain, aircraft detection on satellite imagery is a valuable tool for analysts. Obtaining high performance detectors on such a task can only be achieved by leveraging deep learning and thus us-ing a large amount of labeled data. To obtain labels of a high enough quality, the knowledge of military experts is needed.We propose a hybrid clustering active learning method to select the most relevant data to label, thus limiting the amount of data required and further improving the performances. It combines diversity- and uncertainty-based active learning selection methods. For aircraft detection by segmentation, we show that this method can provide better or competitive results compared to other active learning methods.
Real-time Human Action Recognition Using Locally Aggregated Kinematic-Guided Skeletonlet and Supervised Hashing-by-Analysis Model
May 24, 2021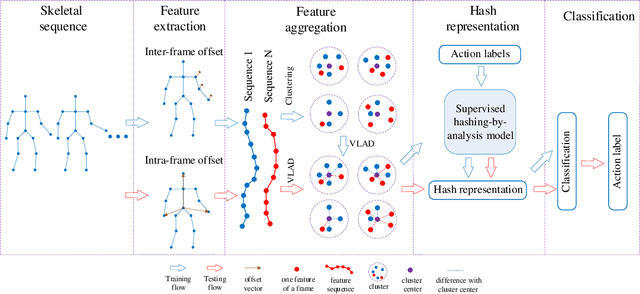
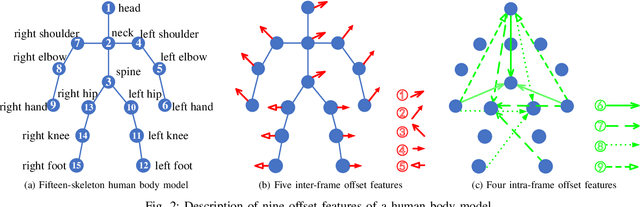
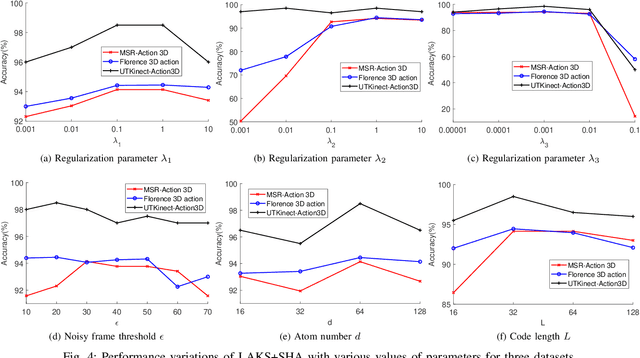
3D action recognition is referred to as the classification of action sequences which consist of 3D skeleton joints. While many research work are devoted to 3D action recognition, it mainly suffers from three problems: highly complicated articulation, a great amount of noise, and a low implementation efficiency. To tackle all these problems, we propose a real-time 3D action recognition framework by integrating the locally aggregated kinematic-guided skeletonlet (LAKS) with a supervised hashing-by-analysis (SHA) model. We first define the skeletonlet as a few combinations of joint offsets grouped in terms of kinematic principle, and then represent an action sequence using LAKS, which consists of a denoising phase and a locally aggregating phase. The denoising phase detects the noisy action data and adjust it by replacing all the features within it with the features of the corresponding previous frame, while the locally aggregating phase sums the difference between an offset feature of the skeletonlet and its cluster center together over all the offset features of the sequence. Finally, the SHA model which combines sparse representation with a hashing model, aiming at promoting the recognition accuracy while maintaining a high efficiency. Experimental results on MSRAction3D, UTKinectAction3D and Florence3DAction datasets demonstrate that the proposed method outperforms state-of-the-art methods in both recognition accuracy and implementation efficiency.
Wastewater Pipe Rating Model Using Natural Language Processing
Feb 22, 2022
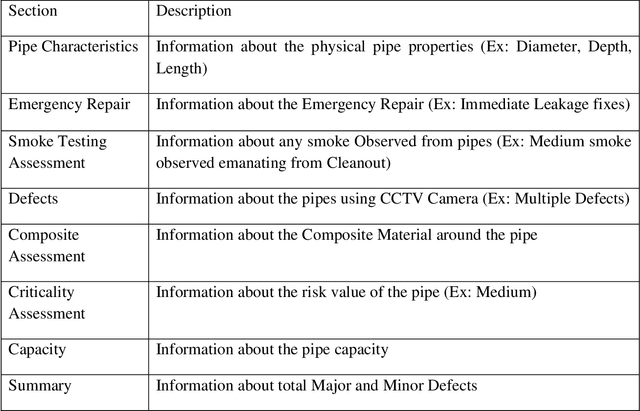
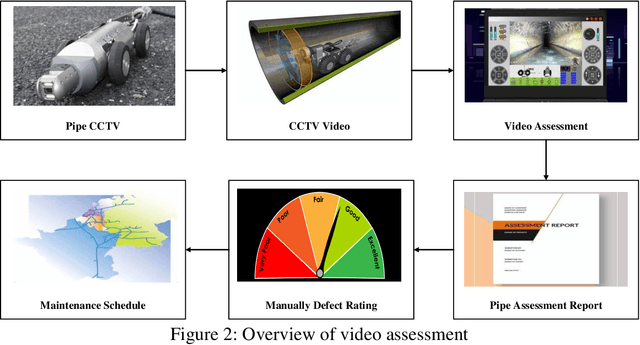

Closed-circuit video (CCTV) inspection has been the most popular technique for visually evaluating the interior status of pipelines in recent decades. Certified inspectors prepare the pipe repair document based on the CCTV inspection. The traditional manual method of assessing sewage structural conditions from pipe repair documents takes a long time and is prone to human mistakes. The automatic identification of necessary texts has received little attention. By building an automated framework employing Natural Language Processing (NLP), this study presents an effective technique to automate the identification of the pipe defect rating of the pipe repair documents. NLP technologies are employed to break down textual material into grammatical units in this research. Further analysis entails using words to discover pipe defect symptoms and their frequency and then combining that information into a single score. Our model achieves 95.0% accuracy,94.9% sensitivity, 94.4% specificity, 95.9% precision score, and 95.7% F1 score, showing the potential of the proposed model to be used in large-scale pipe repair documents for accurate and efficient pipeline failure detection to improve the quality of the pipeline. Keywords: Sewer pipe inspection, Defect detection, Natural language processing, Text recognition
A Constraint Programming Approach to Weighted Isomorphic Mapping of Fragment-based Shape Signatures
Jan 04, 2022
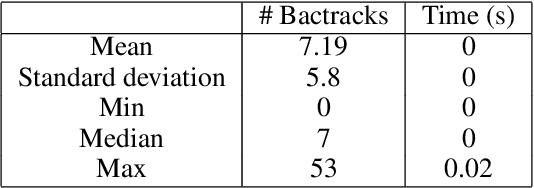
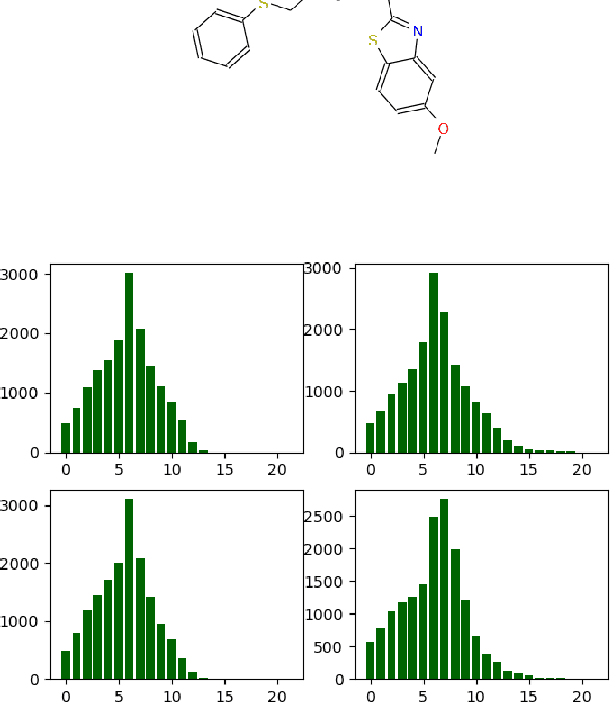
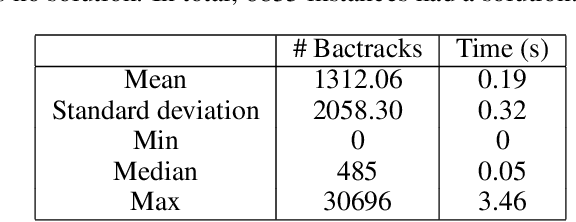
Fragment-based shape signature techniques have proven to be powerful tools for computer-aided drug design. They allow scientists to search for target molecules with some similarity to a known active compound. They do not require reference to the full underlying chemical structure, which is essential to deal with chemical databases containing millions of compounds. However, finding the optimal match of a part of the fragmented compound can be time-consuming. In this paper, we use constraint programming to solve this specific problem. It involves finding a weighted assignment of fragments subject to connectivity constraints. Our experiments demonstrate the practical relevance of our approach and open new perspectives, including generating multiple, diverse solutions. Our approach constitutes an original use of a constraint solver in a real time setting, where propagation allows to avoid an enumeration of weighted paths. The model must remain robust to the addition of constraints making some instances not tractable. This particular context requires the use of unusual criteria for the choice of the model: lightweight, standard propagation algorithms, data structures without prohibitive constant cost. The objective is not to design new, complex algorithms to solve difficult instances.
HDL: Hybrid Deep Learning for the Synthesis of Myocardial Velocity Maps in Digital Twins for Cardiac Analysis
Mar 09, 2022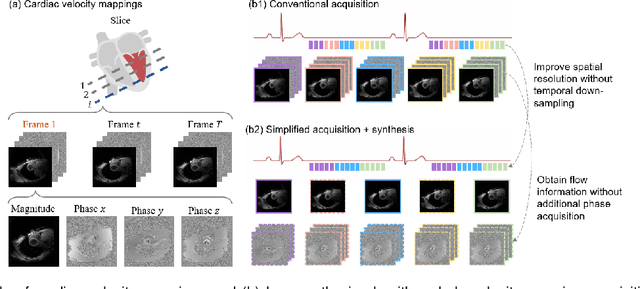
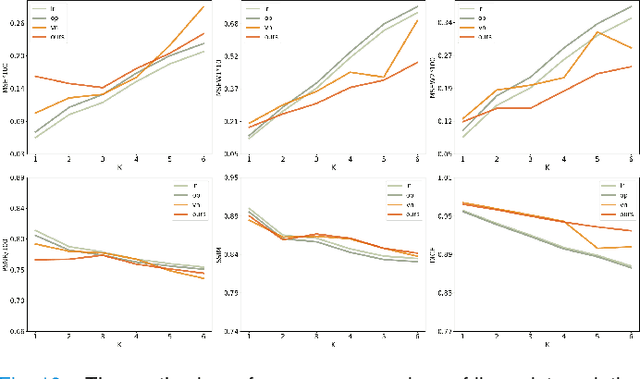

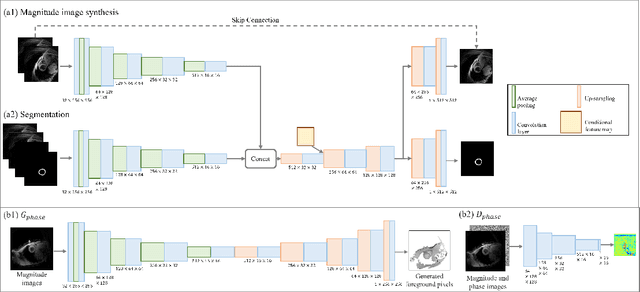
Synthetic digital twins based on medical data accelerate the acquisition, labelling and decision making procedure in digital healthcare. A core part of digital healthcare twins is model-based data synthesis, which permits the generation of realistic medical signals without requiring to cope with the modelling complexity of anatomical and biochemical phenomena producing them in reality. Unfortunately, algorithms for cardiac data synthesis have been so far scarcely studied in the literature. An important imaging modality in the cardiac examination is three-directional CINE multi-slice myocardial velocity mapping (3Dir MVM), which provides a quantitative assessment of cardiac motion in three orthogonal directions of the left ventricle. The long acquisition time and complex acquisition produce make it more urgent to produce synthetic digital twins of this imaging modality. In this study, we propose a hybrid deep learning (HDL) network, especially for synthetic 3Dir MVM data. Our algorithm is featured by a hybrid UNet and a Generative Adversarial Network with a foreground-background generation scheme. The experimental results show that from temporally down-sampled magnitude CINE images (six times), our proposed algorithm can still successfully synthesise high temporal resolution 3Dir MVM CMR data (PSNR=42.32) with precise left ventricle segmentation (DICE=0.92). These performance scores indicate that our proposed HDL algorithm can be implemented in real-world digital twins for myocardial velocity mapping data simulation. To the best of our knowledge, this work is the first one in the literature investigating digital twins of the 3Dir MVM CMR, which has shown great potential for improving the efficiency of clinical studies via synthesised cardiac data.