 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Quality-aware News Recommendation
Feb 28, 2022

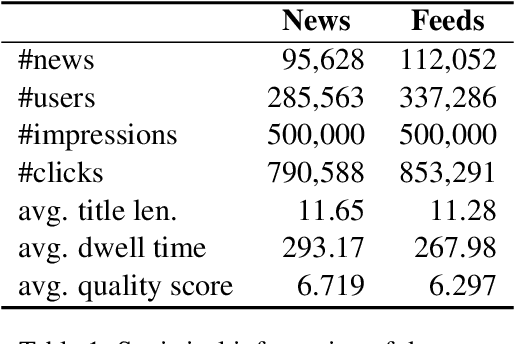
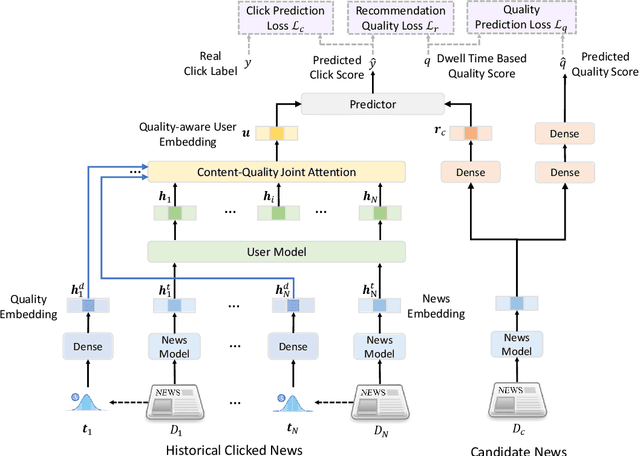
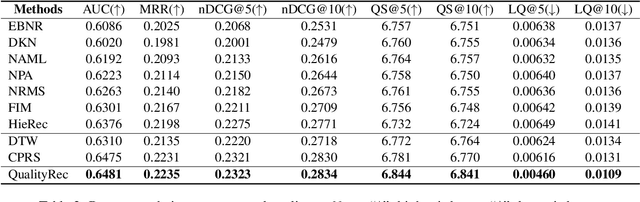
News recommendation is a core technique used by many online news platforms. Recommending high-quality news to users is important for keeping good user experiences and news platforms' reputations. However, existing news recommendation methods mainly aim to optimize news clicks while ignoring the quality of news they recommended, which may lead to recommending news with uninformative content or even clickbaits. In this paper, we propose a quality-aware news recommendation method named QualityRec that can effectively improve the quality of recommended news. In our approach, we first propose an effective news quality evaluation method based on the distributions of users' reading dwell time on news. Next, we propose to incorporate news quality information into user interest modeling by designing a content-quality attention network to select clicked news based on both news semantics and qualities. We further train the recommendation model with an auxiliary news quality prediction task to learn quality-aware recommendation model, and we add a recommendation quality regularization loss to encourage the model to recommend higher-quality news. Extensive experiments on two real-world datasets show that QualityRec can effectively improve the overall quality of recommended news and reduce the recommendation of low-quality news, with even slightly better recommendation accuracy.
Distillation of Human-Object Interaction Contexts for Action Recognition
Dec 17, 2021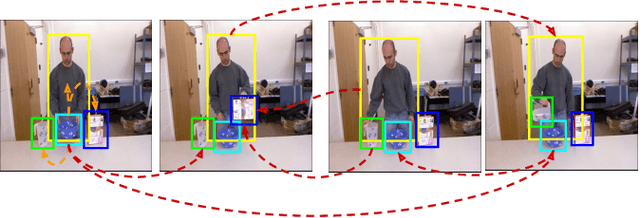

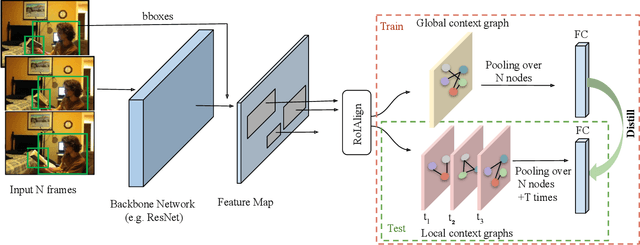
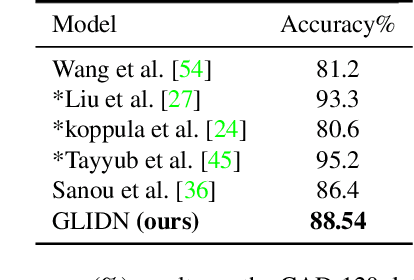
Modeling spatial-temporal relations is imperative for recognizing human actions, especially when a human is interacting with objects, while multiple objects appear around the human differently over time. Most existing action recognition models focus on learning overall visual cues of a scene but disregard informative fine-grained features, which can be captured by learning human-object relationships and interactions. In this paper, we learn human-object relationships by exploiting the interaction of their local and global contexts. We hence propose the Global-Local Interaction Distillation Network (GLIDN), learning human and object interactions through space and time via knowledge distillation for fine-grained scene understanding. GLIDN encodes humans and objects into graph nodes and learns local and global relations via graph attention network. The local context graphs learn the relation between humans and objects at a frame level by capturing their co-occurrence at a specific time step. The global relation graph is constructed based on the video-level of human and object interactions, identifying their long-term relations throughout a video sequence. More importantly, we investigate how knowledge from these graphs can be distilled to their counterparts for improving human-object interaction (HOI) recognition. We evaluate our model by conducting comprehensive experiments on two datasets including Charades and CAD-120 datasets. We have achieved better results than the baselines and counterpart approaches.
A Unified Transformer Framework for Group-based Segmentation: Co-Segmentation, Co-Saliency Detection and Video Salient Object Detection
Mar 11, 2022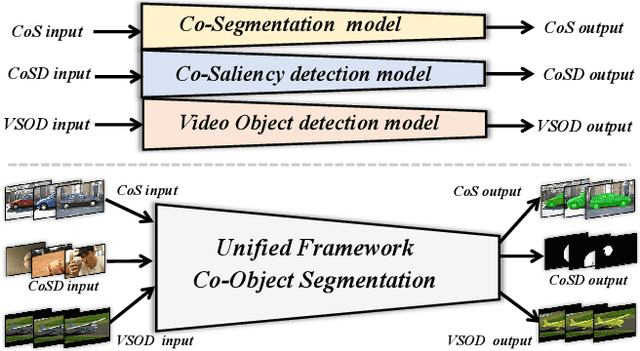
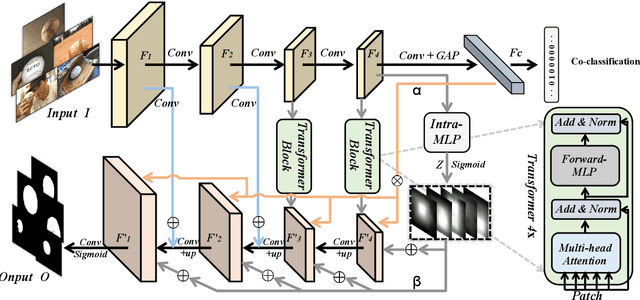
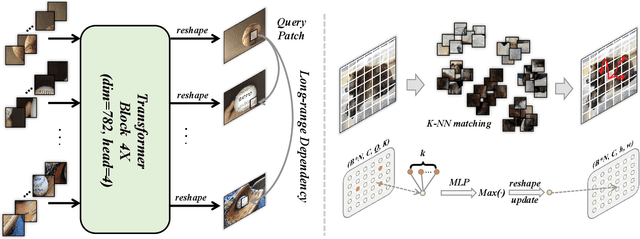
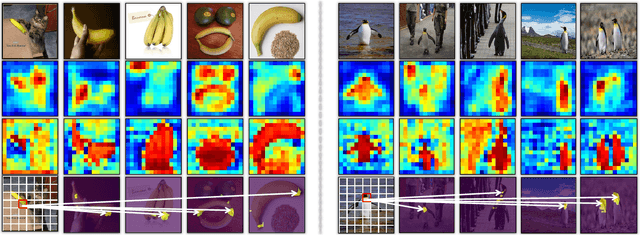
Humans tend to mine objects by learning from a group of images or several frames of video since we live in a dynamic world. In the computer vision area, many researches focus on co-segmentation (CoS), co-saliency detection (CoSD) and video salient object detection (VSOD) to discover the co-occurrent objects. However, previous approaches design different networks on these similar tasks separately, and they are difficult to apply to each other, which lowers the upper bound of the transferability of deep learning frameworks. Besides, they fail to take full advantage of the cues among inter- and intra-feature within a group of images. In this paper, we introduce a unified framework to tackle these issues, term as UFO (Unified Framework for Co-Object Segmentation). Specifically, we first introduce a transformer block, which views the image feature as a patch token and then captures their long-range dependencies through the self-attention mechanism. This can help the network to excavate the patch structured similarities among the relevant objects. Furthermore, we propose an intra-MLP learning module to produce self-mask to enhance the network to avoid partial activation. Extensive experiments on four CoS benchmarks (PASCAL, iCoseg, Internet and MSRC), three CoSD benchmarks (Cosal2015, CoSOD3k, and CocA) and four VSOD benchmarks (DAVIS16, FBMS, ViSal and SegV2) show that our method outperforms other state-of-the-arts on three different tasks in both accuracy and speed by using the same network architecture , which can reach 140 FPS in real-time.
Worsening Perception: Real-time Degradation of Autonomous Vehicle Perception Performance for Simulation of Adverse Weather Conditions
Mar 05, 2021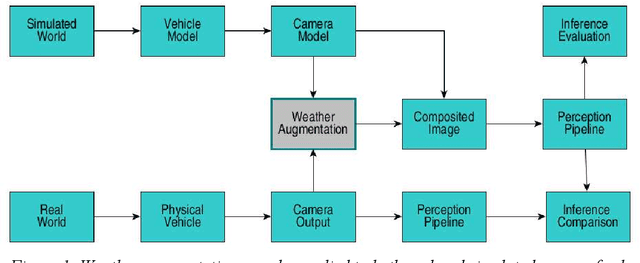


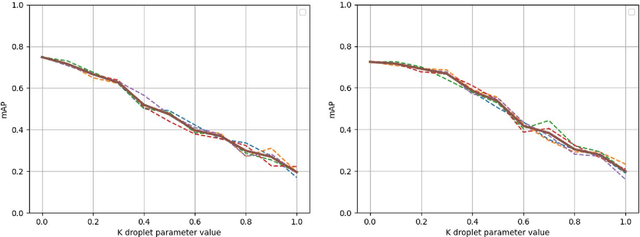
Autonomous vehicles rely heavily upon their perception subsystems to see the environment in which they operate. Unfortunately, the effect of varying weather conditions presents a significant challenge to object detection algorithms, and thus it is imperative to test the vehicle extensively in all conditions which it may experience. However, unpredictable weather can make real-world testing in adverse conditions an expensive and time consuming task requiring access to specialist facilities, and weatherproofing of sensitive electronics. Simulation provides an alternative to real world testing, with some studies developing increasingly visually realistic representations of the real world on powerful compute hardware. Given that subsequent subsystems in the autonomous vehicle pipeline are unaware of the visual realism of the simulation, when developing modules downstream of perception the appearance is of little consequence - rather it is how the perception system performs in the prevailing weather condition that is important. This study explores the potential of using a simple, lightweight image augmentation system in an autonomous racing vehicle - focusing not on visual accuracy, but rather the effect upon perception system performance. With minimal adjustment, the prototype system developed in this study can replicate the effects of both water droplets on the camera lens, and fading light conditions. The system introduces a latency of less than 8 ms using compute hardware that is well suited to being carried in the vehicle - rendering it ideally suited to real-time implementation that can be run during experiments in simulation, and augmented reality testing in the real world.
Analytic Learning of Convolutional Neural Network For Pattern Recognition
Feb 14, 2022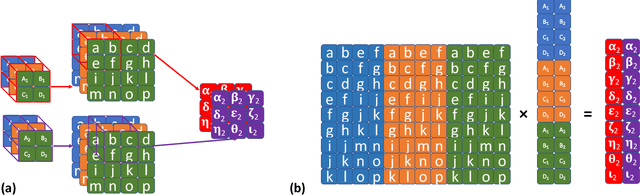

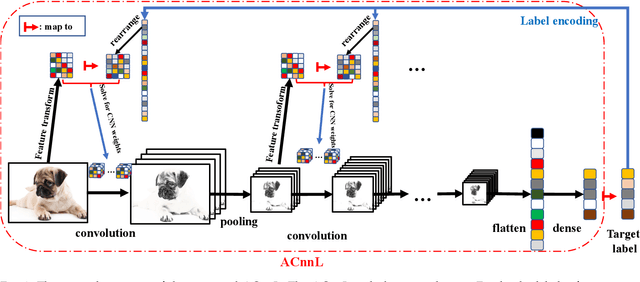
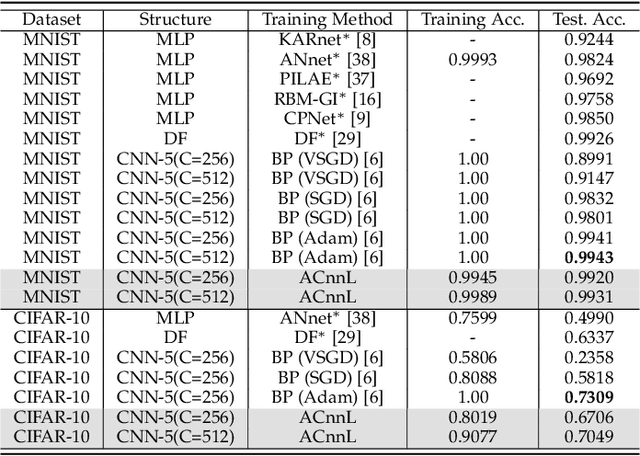
Training convolutional neural networks (CNNs) with back-propagation (BP) is time-consuming and resource-intensive particularly in view of the need to visit the dataset multiple times. In contrast, analytic learning attempts to obtain the weights in one epoch. However, existing attempts to analytic learning considered only the multilayer perceptron (MLP). In this article, we propose an analytic convolutional neural network learning (ACnnL). Theoretically we show that ACnnL builds a closed-form solution similar to its MLP counterpart, but differs in their regularization constraints. Consequently, we are able to answer to a certain extent why CNNs usually generalize better than MLPs from the implicit regularization point of view. The ACnnL is validated by conducting classification tasks on several benchmark datasets. It is encouraging that the ACnnL trains CNNs in a significantly fast manner with reasonably close prediction accuracies to those using BP. Moreover, our experiments disclose a unique advantage of ACnnL under the small-sample scenario when training data are scarce or expensive.
Filter-enhanced MLP is All You Need for Sequential Recommendation
Feb 28, 2022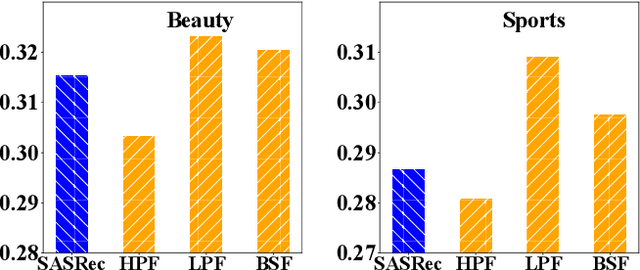
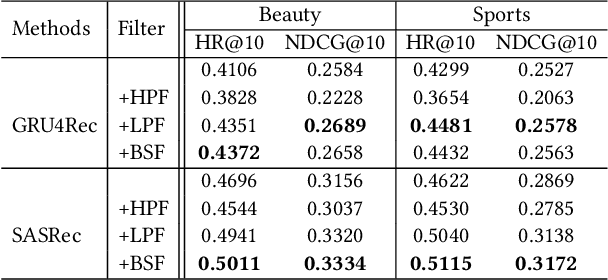
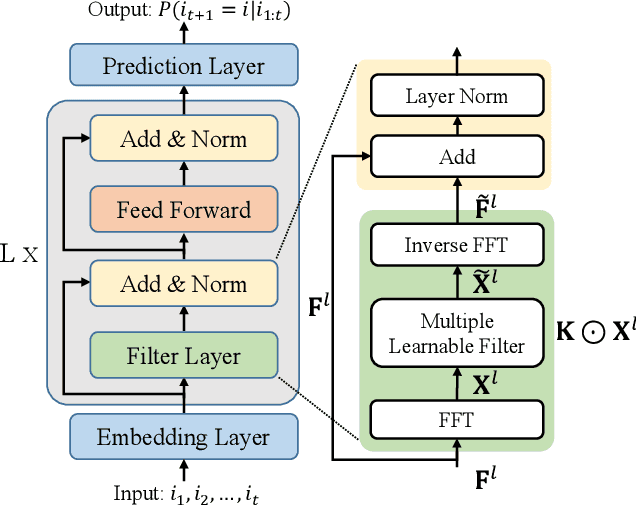
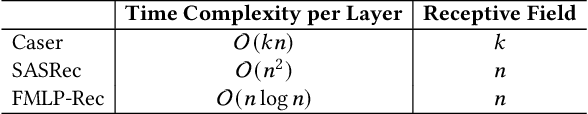
Recently, deep neural networks such as RNN, CNN and Transformer have been applied in the task of sequential recommendation, which aims to capture the dynamic preference characteristics from logged user behavior data for accurate recommendation. However, in online platforms, logged user behavior data is inevitable to contain noise, and deep recommendation models are easy to overfit on these logged data. To tackle this problem, we borrow the idea of filtering algorithms from signal processing that attenuates the noise in the frequency domain. In our empirical experiments, we find that filtering algorithms can substantially improve representative sequential recommendation models, and integrating simple filtering algorithms (eg Band-Stop Filter) with an all-MLP architecture can even outperform competitive Transformer-based models. Motivated by it, we propose \textbf{FMLP-Rec}, an all-MLP model with learnable filters for sequential recommendation task. The all-MLP architecture endows our model with lower time complexity, and the learnable filters can adaptively attenuate the noise information in the frequency domain. Extensive experiments conducted on eight real-world datasets demonstrate the superiority of our proposed method over competitive RNN, CNN, GNN and Transformer-based methods. Our code and data are publicly available at the link: \textcolor{blue}{\url{https://github.com/RUCAIBox/FMLP-Rec}}.
Predicting emotion from music videos: exploring the relative contribution of visual and auditory information to affective responses
Feb 19, 2022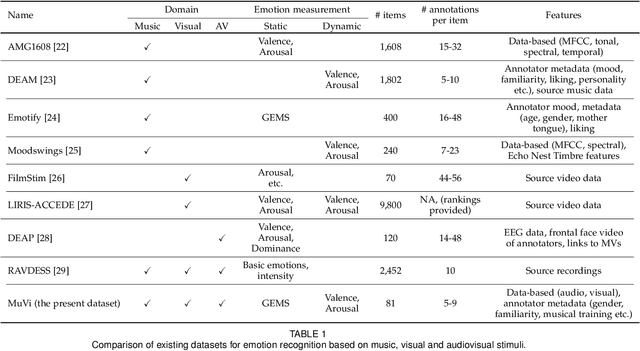

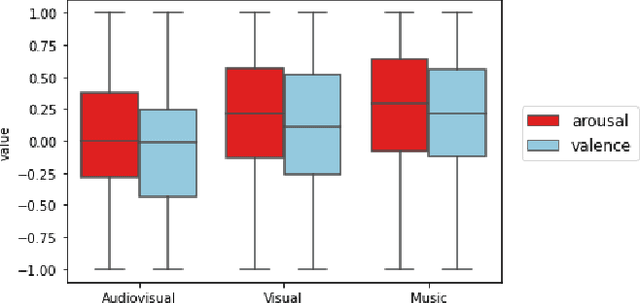
Although media content is increasingly produced, distributed, and consumed in multiple combinations of modalities, how individual modalities contribute to the perceived emotion of a media item remains poorly understood. In this paper we present MusicVideos (MuVi), a novel dataset for affective multimedia content analysis to study how the auditory and visual modalities contribute to the perceived emotion of media. The data were collected by presenting music videos to participants in three conditions: music, visual, and audiovisual. Participants annotated the music videos for valence and arousal over time, as well as the overall emotion conveyed. We present detailed descriptive statistics for key measures in the dataset and the results of feature importance analyses for each condition. Finally, we propose a novel transfer learning architecture to train Predictive models Augmented with Isolated modality Ratings (PAIR) and demonstrate the potential of isolated modality ratings for enhancing multimodal emotion recognition. Our results suggest that perceptions of arousal are influenced primarily by auditory information, while perceptions of valence are more subjective and can be influenced by both visual and auditory information. The dataset is made publicly available.
Real-Time Segmentation of Non-Rigid Surgical Tools based on Deep Learning and Tracking
Sep 07, 2020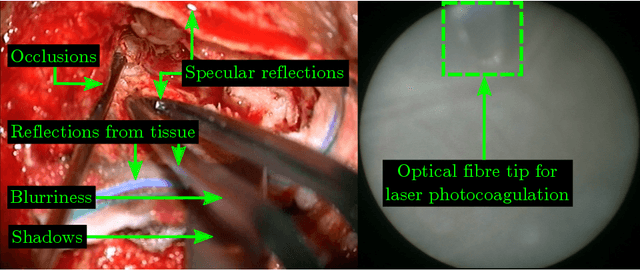

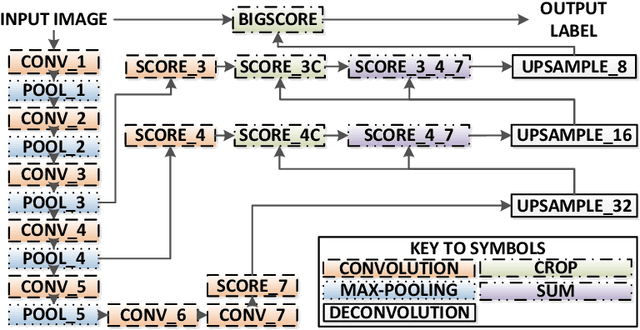
Real-time tool segmentation is an essential component in computer-assisted surgical systems. We propose a novel real-time automatic method based on Fully Convolutional Networks (FCN) and optical flow tracking. Our method exploits the ability of deep neural networks to produce accurate segmentations of highly deformable parts along with the high speed of optical flow. Furthermore, the pre-trained FCN can be fine-tuned on a small amount of medical images without the need to hand-craft features. We validated our method using existing and new benchmark datasets, covering both ex vivo and in vivo real clinical cases where different surgical instruments are employed. Two versions of the method are presented, non-real-time and real-time. The former, using only deep learning, achieves a balanced accuracy of 89.6% on a real clinical dataset, outperforming the (non-real-time) state of the art by 3.8% points. The latter, a combination of deep learning with optical flow tracking, yields an average balanced accuracy of 78.2% across all the validated datasets.
Deep Dose Plugin Towards Real-time Monte Carlo Dose Calculation Through a Deep Learning based Denoising Algorithm
Nov 30, 2020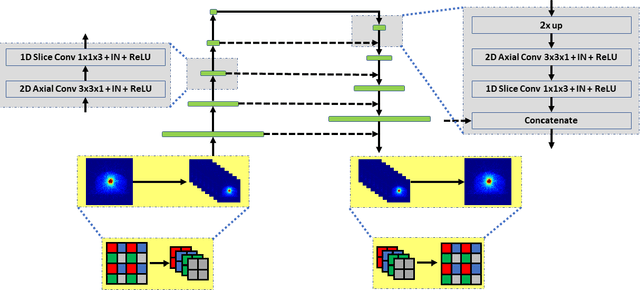

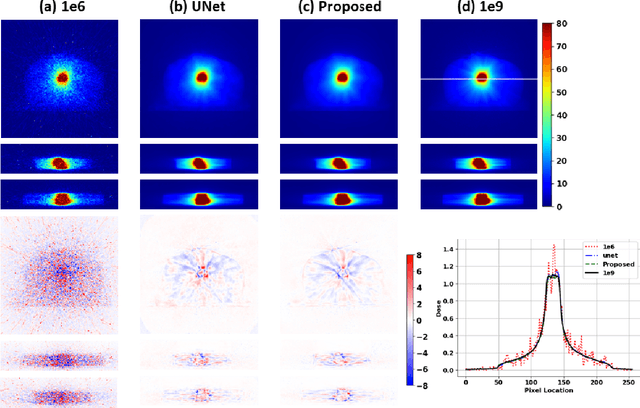
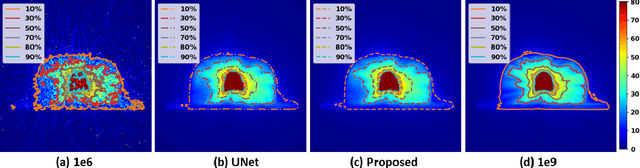
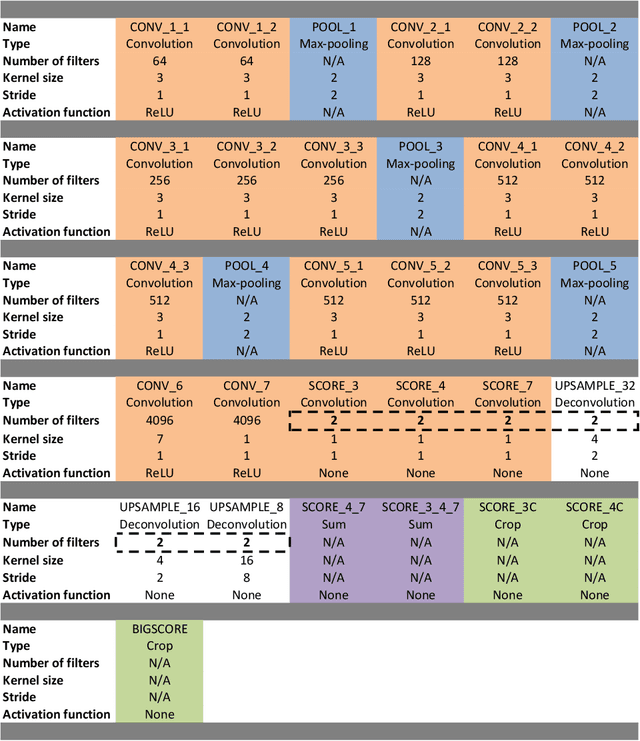
Monte Carlo (MC) simulation is considered the gold standard method for radiotherapy dose calculation. However, achieving high precision requires a large number of simulation histories, which is time consuming. The use of computer graphics processing units (GPUs) has greatly accelerated MC simulation and allows dose calculation within a few minutes for a typical radiotherapy treatment plan. However, some clinical applications demand real time efficiency for MC dose calculation. To tackle this problem, we have developed a real time, deep learning based dose denoiser that can be plugged into a current GPU based MC dose engine to enable real time MC dose calculation. We used two different acceleration strategies to achieve this goal: 1) we applied voxel unshuffle and voxel shuffle operators to decrease the input and output sizes without any information loss, and 2) we decoupled the 3D volumetric convolution into a 2D axial convolution and a 1D slice convolution. In addition, we used a weakly supervised learning framework to train the network, which greatly reduces the size of the required training dataset and thus enables fast fine tuning based adaptation of the trained model to different radiation beams. Experimental results show that the proposed denoiser can run in as little as 39 ms, which is around 11.6 times faster than the baseline model. As a result, the whole MC dose calculation pipeline can be finished within 0.15 seconds, including both GPU MC dose calculation and deep learning based denoising, achieving the real time efficiency needed for some radiotherapy applications, such as online adaptive radiotherapy.
Parallel Fourier Ptychography reconstruction
Mar 04, 2022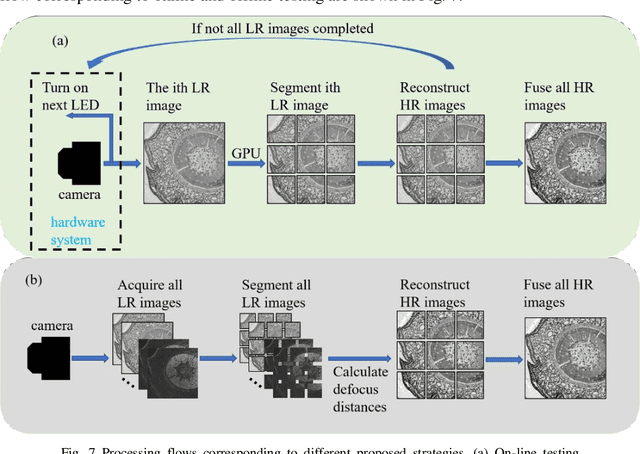


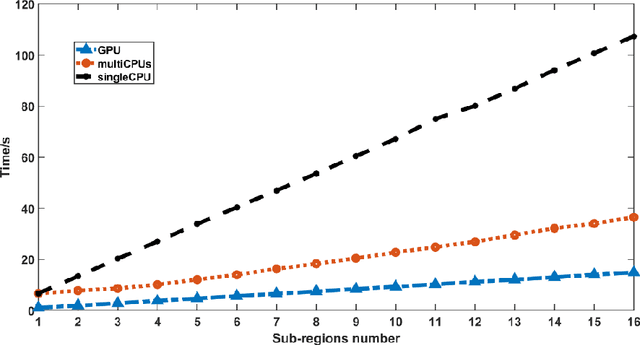
Fourier ptychography has attracted a wide range of focus for its ability of large space-bandwidth-produce, and quantative phase measurement. It is a typical computational imaging technique which refers to optimizing both the imaging hardware and reconstruction algorithms simultaneously. The data redundancy and inverse problem algorithms are the sources of FPM's excellent performance. But at the same time, this large amount of data processing and complex algorithms also greatly reduce the imaging speed. In this article, we propose a parallel Fourier ptychography reconstruction framework consisting of three levels of parallel computing parts and implemented it with both central processing unit (CPU) and compute unified device architecture (CUDA) platform. In the conventional FPM reconstruction framework, the sample image is divided into multiple sub-regions for separately processing because the illumination angles for different subregions are varied for the same LED and different subregions contain different defocus distances due to the non-planar distribution or non-ideal posture of biological sample. We first build a parallel computing sub-framework in spatial domain based on the above-mentioned characteristics. And then, by utilizing the sequential characteristics of different spectrum regions to update, a parallel computing sub-framework in the spectrum domain is carried out in our scheme. The feasibility of the proposed parallel FPM reconstruction framework is verified with different experimental results acquired with the system we built.