 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Entroformer: A Transformer-based Entropy Model for Learned Image Compression
Feb 11, 2022


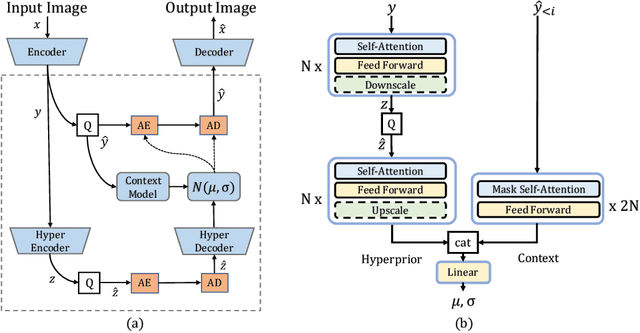

One critical component in lossy deep image compression is the entropy model, which predicts the probability distribution of the quantized latent representation in the encoding and decoding modules. Previous works build entropy models upon convolutional neural networks which are inefficient in capturing global dependencies. In this work, we propose a novel transformer-based entropy model, termed Entroformer, to capture long-range dependencies in probability distribution estimation effectively and efficiently. Different from vision transformers in image classification, the Entroformer is highly optimized for image compression, including a top-k self-attention and a diamond relative position encoding. Meanwhile, we further expand this architecture with a parallel bidirectional context model to speed up the decoding process. The experiments show that the Entroformer achieves state-of-the-art performance on image compression while being time-efficient.
Memory Efficient Continual Learning for Neural Text Classification
Mar 09, 2022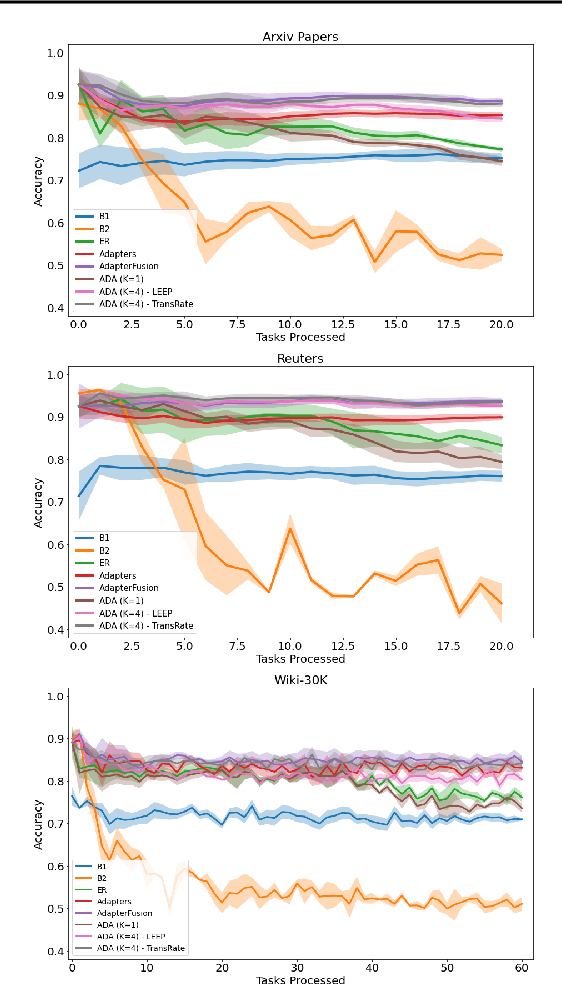
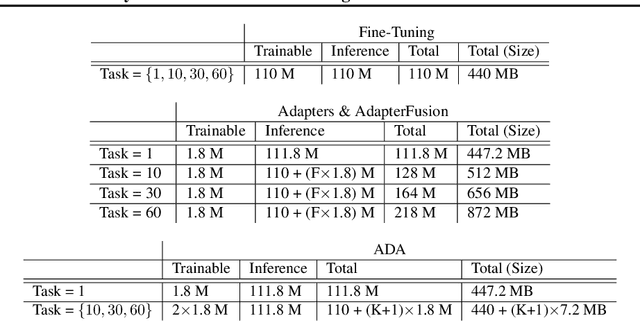
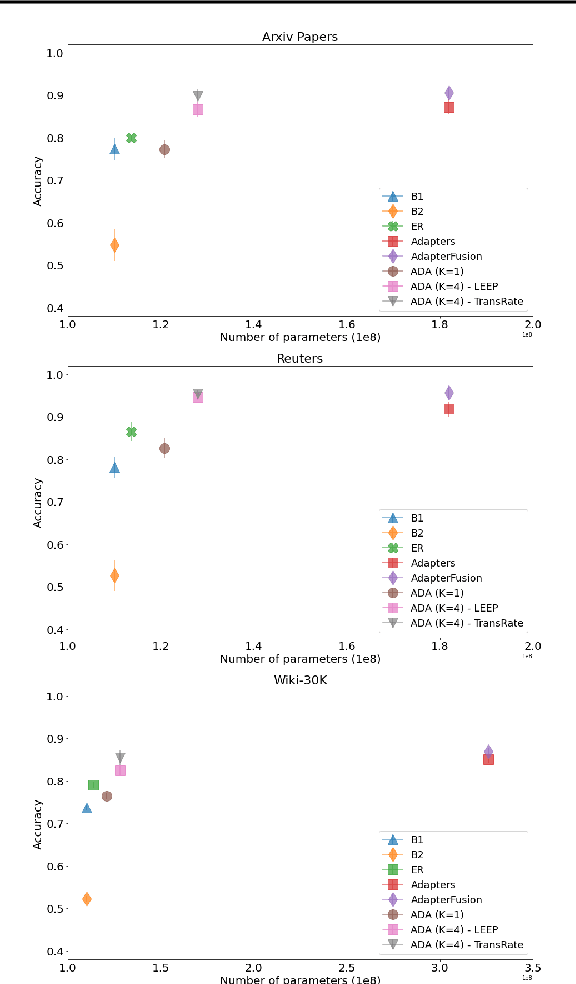
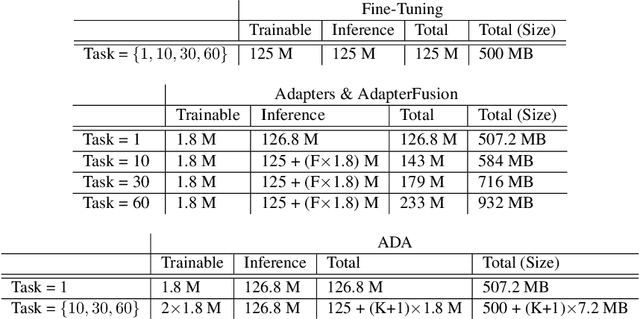
Learning text classifiers based on pre-trained language models has become the standard practice in natural language processing applications. Unfortunately, training large neural language models, such as transformers, from scratch is very costly and requires a vast amount of training data, which might not be available in the application domain of interest. Moreover, in many real-world scenarios, classes are uncovered as more data is seen, calling for class-incremental modelling approaches. In this work we devise a method to perform text classification using pre-trained models on a sequence of classification tasks provided in sequence. We formalize the problem as a continual learning problem where the algorithm learns new tasks without performance degradation on the previous ones and without re-training the model from scratch. We empirically demonstrate that our method requires significantly less model parameters compared to other state of the art methods and that it is significantly faster at inference time. The tight control on the number of model parameters, and so the memory, is not only improving efficiency. It is making possible the usage of the algorithm in real-world applications where deploying a solution with a constantly increasing memory consumption is just unrealistic. While our method suffers little forgetting, it retains a predictive performance on-par with state of the art but less memory efficient methods.
Spirit Distillation: Precise Real-time Semantic Segmentation of Road Scenes with Insufficient Data
Apr 17, 2021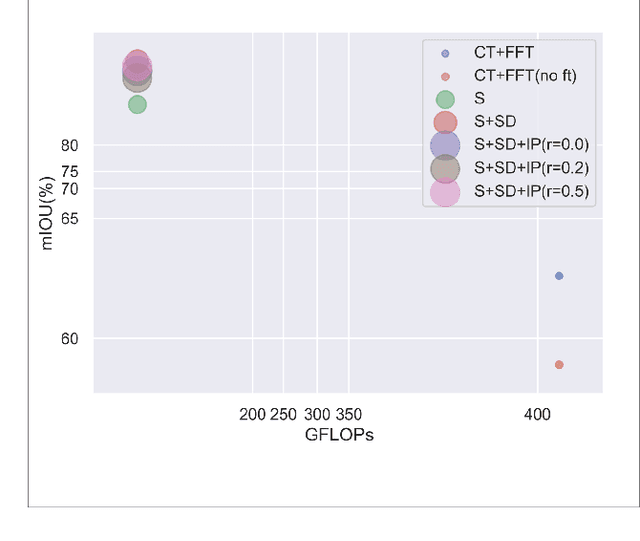
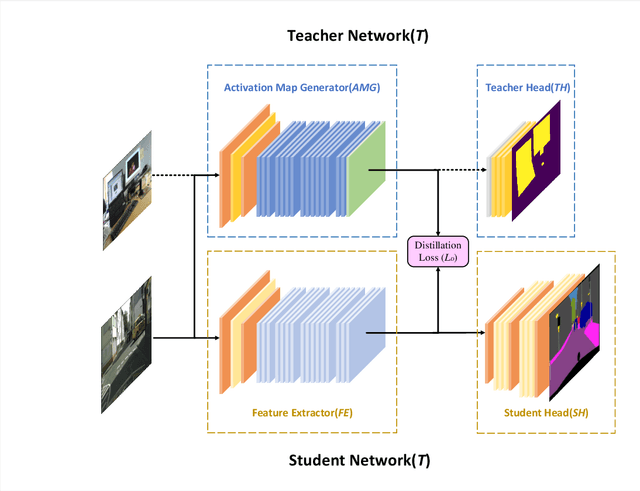
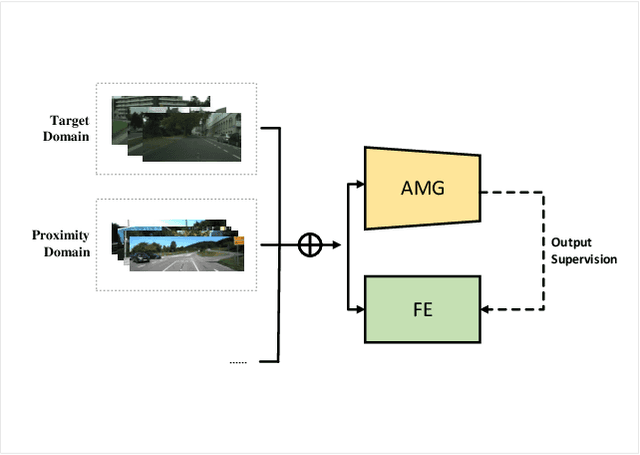
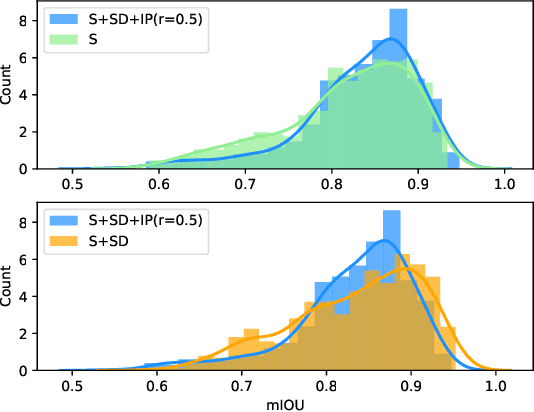
Semantic segmentation of road scenes is one of the key technologies for realizing autonomous driving scene perception, and the effectiveness of deep Convolutional Neural Networks(CNNs) for this task has been demonstrated. State-of-art CNNs for semantic segmentation suffer from excessive computations as well as large-scale training data requirement. Inspired by the ideas of Fine-tuning-based Transfer Learning (FTT) and feature-based knowledge distillation, we propose a new knowledge distillation method for cross-domain knowledge transference and efficient data-insufficient network training, named Spirit Distillation(SD), which allow the student network to mimic the teacher network to extract general features, so that a compact and accurate student network can be trained for real-time semantic segmentation of road scenes. Then, in order to further alleviate the trouble of insufficient data and improve the robustness of the student, an Enhanced Spirit Distillation (ESD) method is proposed, which commits to exploit a more comprehensive general features extraction capability by considering images from both the target and the proximity domains as input. To our knowledge, this paper is a pioneering work on the application of knowledge distillation to few-shot learning. Persuasive experiments conducted on Cityscapes semantic segmentation with the prior knowledge transferred from COCO2017 and KITTI demonstrate that our methods can train a better student network (mIOU and high-precision accuracy boost by 1.4% and 8.2% respectively, with 78.2% segmentation variance) with only 41.8% FLOPs (see Fig. 1).
ABCNet v2: Adaptive Bezier-Curve Network for Real-time End-to-end Text Spotting
May 08, 2021
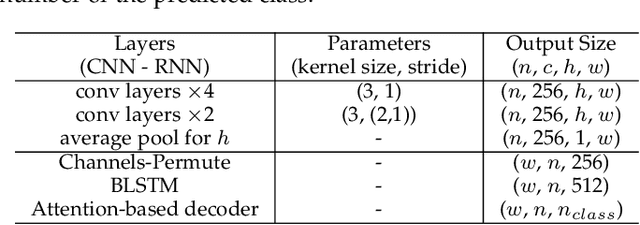


End-to-end text-spotting, which aims to integrate detection and recognition in a unified framework, has attracted increasing attention due to its simplicity of the two complimentary tasks. It remains an open problem especially when processing arbitrarily-shaped text instances. Previous methods can be roughly categorized into two groups: character-based and segmentation-based, which often require character-level annotations and/or complex post-processing due to the unstructured output. Here, we tackle end-to-end text spotting by presenting Adaptive Bezier Curve Network v2 (ABCNet v2). Our main contributions are four-fold: 1) For the first time, we adaptively fit arbitrarily-shaped text by a parameterized Bezier curve, which, compared with segmentation-based methods, can not only provide structured output but also controllable representation. 2) We design a novel BezierAlign layer for extracting accurate convolution features of a text instance of arbitrary shapes, significantly improving the precision of recognition over previous methods. 3) Different from previous methods, which often suffer from complex post-processing and sensitive hyper-parameters, our ABCNet v2 maintains a simple pipeline with the only post-processing non-maximum suppression (NMS). 4) As the performance of text recognition closely depends on feature alignment, ABCNet v2 further adopts a simple yet effective coordinate convolution to encode the position of the convolutional filters, which leads to a considerable improvement with negligible computation overhead. Comprehensive experiments conducted on various bilingual (English and Chinese) benchmark datasets demonstrate that ABCNet v2 can achieve state-of-the-art performance while maintaining very high efficiency.
Towards Robust Stacked Capsule Autoencoder with Hybrid Adversarial Training
Mar 01, 2022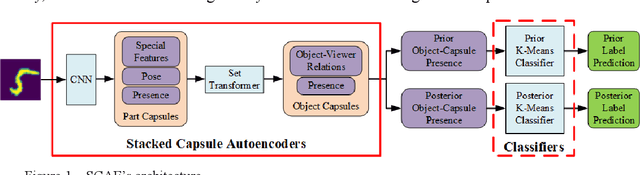
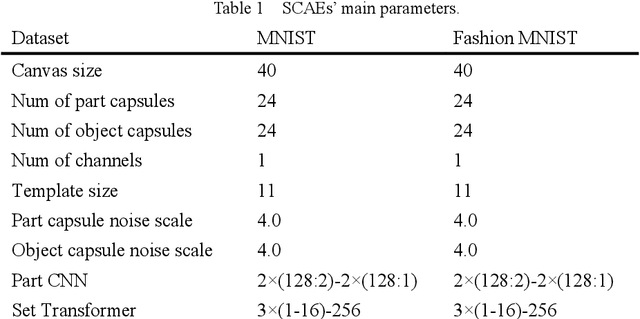
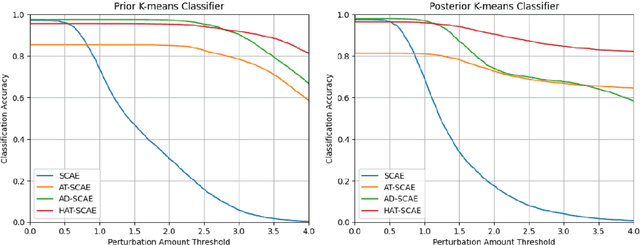
Capsule networks (CapsNets) are new neural networks that classify images based on the spatial relationships of features. By analyzing the pose of features and their relative positions, it is more capable to recognize images after affine transformation. The stacked capsule autoencoder (SCAE) is a state-of-the-art CapsNet, and achieved unsupervised classification of CapsNets for the first time. However, the security vulnerabilities and the robustness of the SCAE has rarely been explored. In this paper, we propose an evasion attack against SCAE, where the attacker can generate adversarial perturbations based on reducing the contribution of the object capsules in SCAE related to the original category of the image. The adversarial perturbations are then applied to the original images, and the perturbed images will be misclassified. Furthermore, we propose a defense method called Hybrid Adversarial Training (HAT) against such evasion attacks. HAT makes use of adversarial training and adversarial distillation to achieve better robustness and stability. We evaluate the defense method and the experimental results show that the refined SCAE model can achieve 82.14% classification accuracy under evasion attack. The source code is available at https://github.com/FrostbiteXSW/SCAE_Defense.
Large-scale Stochastic Optimization of NDCG Surrogates for Deep Learning with Provable Convergence
Feb 24, 2022

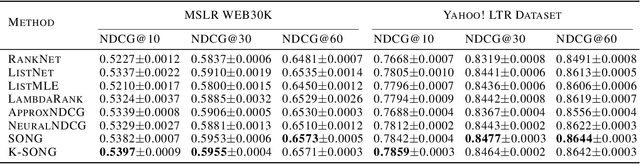

NDCG, namely Normalized Discounted Cumulative Gain, is a widely used ranking metric in information retrieval and machine learning. However, efficient and provable stochastic methods for maximizing NDCG are still lacking, especially for deep models. In this paper, we propose a principled approach to optimize NDCG and its top-$K$ variant. First, we formulate a novel compositional optimization problem for optimizing the NDCG surrogate, and a novel bilevel compositional optimization problem for optimizing the top-$K$ NDCG surrogate. Then, we develop efficient stochastic algorithms with provable convergence guarantees for the non-convex objectives. Different from existing NDCG optimization methods, the per-iteration complexity of our algorithms scales with the mini-batch size instead of the number of total items. To improve the effectiveness for deep learning, we further propose practical strategies by using initial warm-up and stop gradient operator. Experimental results on multiple datasets demonstrate that our methods outperform prior ranking approaches in terms of NDCG. To the best of our knowledge, this is the first time that stochastic algorithms are proposed to optimize NDCG with a provable convergence guarantee.
FreeSOLO: Learning to Segment Objects without Annotations
Feb 24, 2022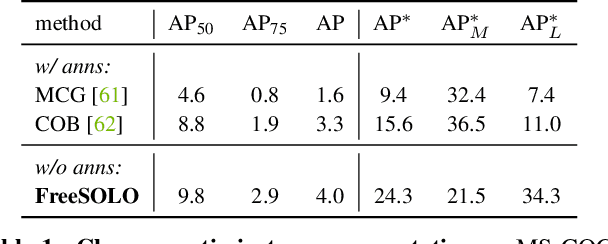

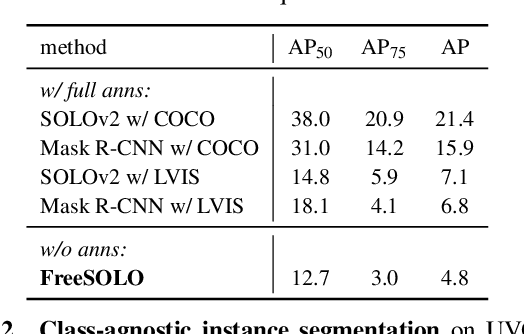
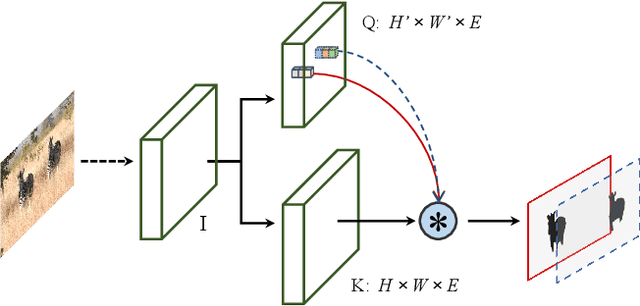
Instance segmentation is a fundamental vision task that aims to recognize and segment each object in an image. However, it requires costly annotations such as bounding boxes and segmentation masks for learning. In this work, we propose a fully unsupervised learning method that learns class-agnostic instance segmentation without any annotations. We present FreeSOLO, a self-supervised instance segmentation framework built on top of the simple instance segmentation method SOLO. Our method also presents a novel localization-aware pre-training framework, where objects can be discovered from complicated scenes in an unsupervised manner. FreeSOLO achieves 9.8% AP_{50} on the challenging COCO dataset, which even outperforms several segmentation proposal methods that use manual annotations. For the first time, we demonstrate unsupervised class-agnostic instance segmentation successfully. FreeSOLO's box localization significantly outperforms state-of-the-art unsupervised object detection/discovery methods, with about 100% relative improvements in COCO AP. FreeSOLO further demonstrates superiority as a strong pre-training method, outperforming state-of-the-art self-supervised pre-training methods by +9.8% AP when fine-tuning instance segmentation with only 5% COCO masks.
Practical Mission Planning for Optimized UAV-Sensor Wireless Recharging
Mar 09, 2022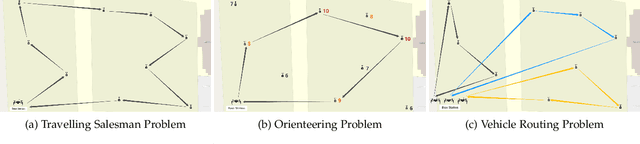
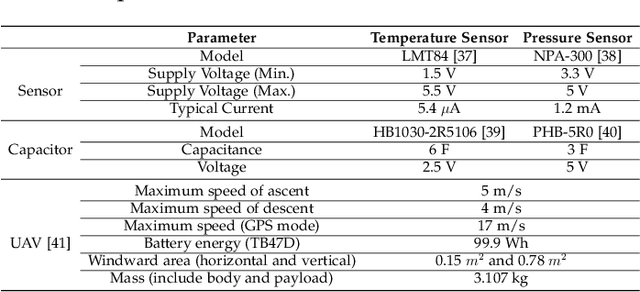
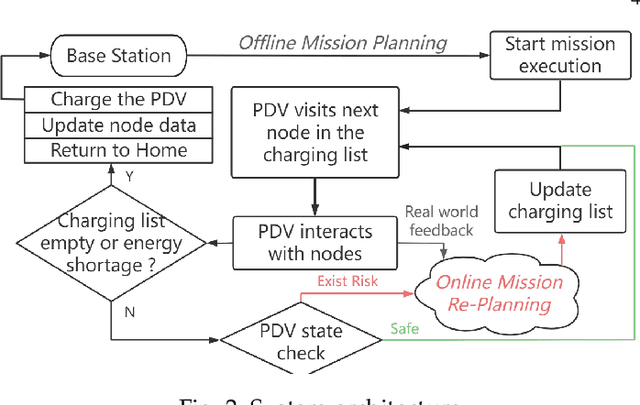
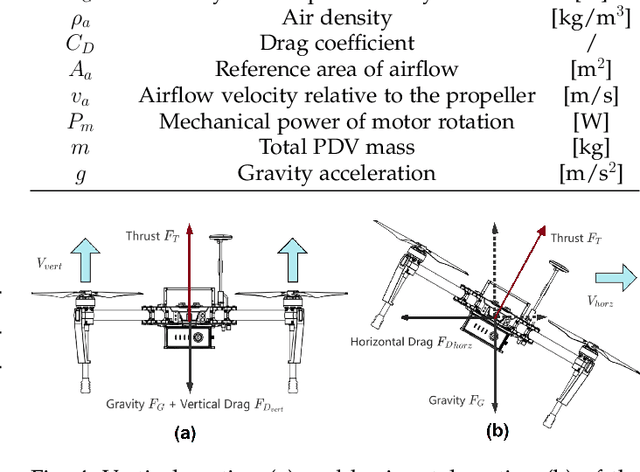
Recharging Internet of Things devices using autonomous robots is an attractive maintenance solution. Ensuring efficient and reliable performance of autonomous power delivery vehicles is very challenging in dynamic environments. Our work considers a hybrid Travelling Salesman Problem and Orienteering Problem scenario where the optimization objective is to jointly minimize discharged energy of the power delivery vehicle and maximize recharged energy of devices. This is decomposed as an NP-hard nonconvex optimization and nonlinear integer programming problem. Many studies have demonstrated satisfactory performance of heuristic algorithms' ability to solve specific routing problems, however very few studies explore online updating (i.e., mission re-planning `on the fly') for such hybrid scenarios. In this paper, we present a novel lightweight and reliable mission planner that solves the problem by combining offline search and online reevaluation. We propose Rapid Online Metaheuristic-based Planner, ROMP, a multi-objective offline and online mission planner that can incorporate real-time state information from the power delivery vehicle and its local environment to deliver reliable, up-to-date and near-optimal mission planning. We supplement Guided Local Search (via Google OR-Tools) with a Black Hole-inspired algorithm. Our results show that the proposed solver improves the solution quality offered by Guided Local Search in most of the cases tested. We also demonstrate latency performance improvements by applying a parallelization strategy.
Improving the quality control of seismic data through active learning
Jan 20, 2022
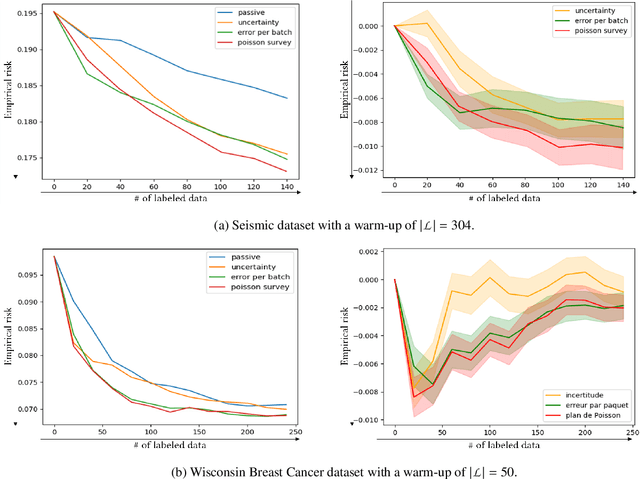
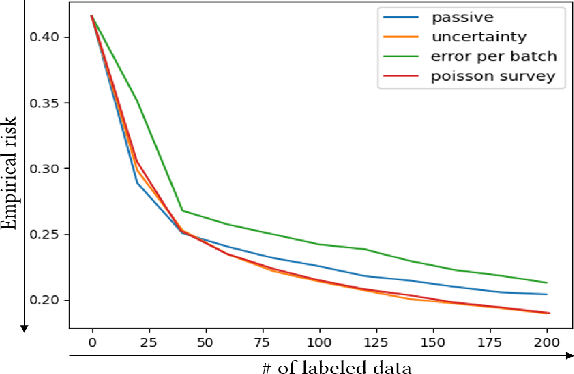
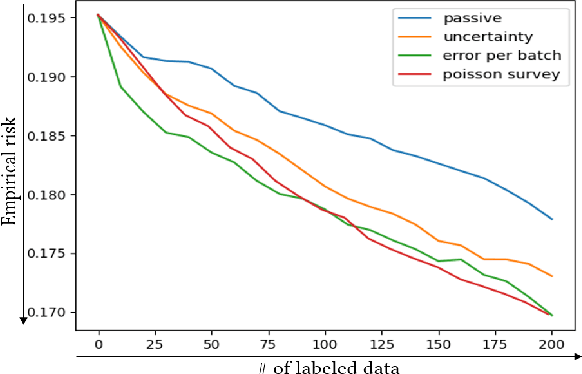
In image denoising problems, the increasing density of available images makes an exhaustive visual inspection impossible and therefore automated methods based on machine-learning must be deployed for this purpose. This is particulary the case in seismic signal processing. Engineers/geophysicists have to deal with millions of seismic time series. Finding the sub-surface properties useful for the oil industry may take up to a year and is very costly in terms of computing/human resources. In particular, the data must go through different steps of noise attenuation. Each denoise step is then ideally followed by a quality control (QC) stage performed by means of human expertise. To learn a quality control classifier in a supervised manner, labeled training data must be available, but collecting the labels from human experts is extremely time-consuming. We therefore propose a novel active learning methodology to sequentially select the most relevant data, which are then given back to a human expert for labeling. Beyond the application in geophysics, the technique we promote in this paper, based on estimates of the local error and its uncertainty, is generic. Its performance is supported by strong empirical evidence, as illustrated by the numerical experiments presented in this article, where it is compared to alternative active learning strategies both on synthetic and real seismic datasets.
6D Pose Estimation with Combined Deep Learning and 3D Vision Techniques for a Fast and Accurate Object Grasping
Nov 11, 2021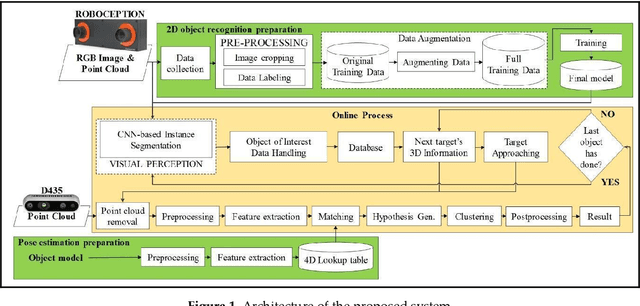
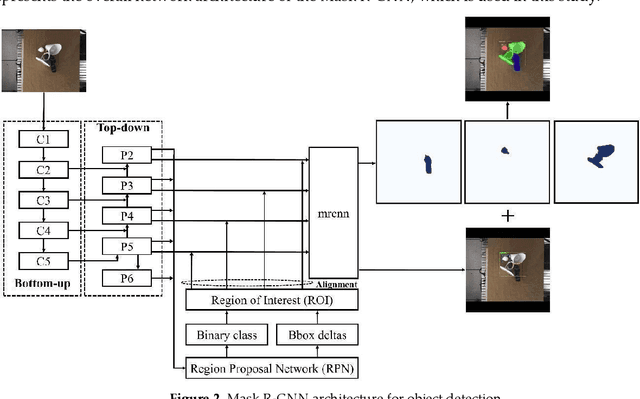
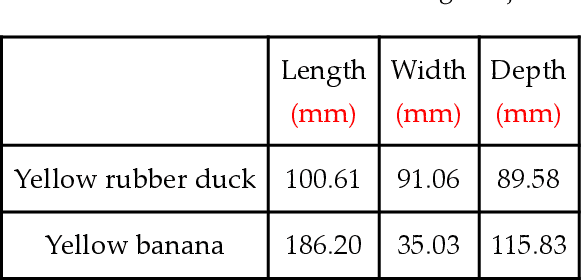
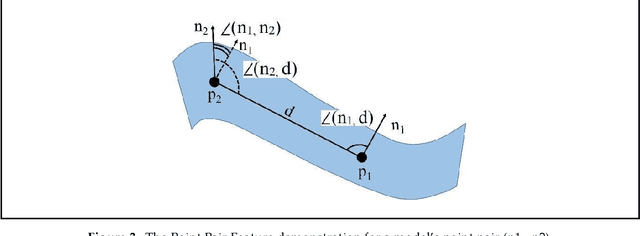
Real-time robotic grasping, supporting a subsequent precise object-in-hand operation task, is a priority target towards highly advanced autonomous systems. However, such an algorithm which can perform sufficiently-accurate grasping with time efficiency is yet to be found. This paper proposes a novel method with a 2-stage approach that combines a fast 2D object recognition using a deep neural network and a subsequent accurate and fast 6D pose estimation based on Point Pair Feature framework to form a real-time 3D object recognition and grasping solution capable of multi-object class scenes. The proposed solution has a potential to perform robustly on real-time applications, requiring both efficiency and accuracy. In order to validate our method, we conducted extensive and thorough experiments involving laborious preparation of our own dataset. The experiment results show that the proposed method scores 97.37% accuracy in 5cm5deg metric and 99.37% in Average Distance metric. Experiment results have shown an overall 62% relative improvement (5cm5deg metric) and 52.48% (Average Distance metric) by using the proposed method. Moreover, the pose estimation execution also showed an average improvement of 47.6% in running time. Finally, to illustrate the overall efficiency of the system in real-time operations, a pick-and-place robotic experiment is conducted and has shown a convincing success rate with 90% of accuracy. This experiment video is available at https://sites.google.com/view/dl-ppf6dpose/.