 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealisMotion: Decomposed Human Motion Control and Video Generation in the World Space
Aug 12, 2025Generating human videos with realistic and controllable motions is a challenging task. While existing methods can generate visually compelling videos, they lack separate control over four key video elements: foreground subject, background video, human trajectory and action patterns. In this paper, we propose a decomposed human motion control and video generation framework that explicitly decouples motion from appearance, subject from background, and action from trajectory, enabling flexible mix-and-match composition of these elements. Concretely, we first build a ground-aware 3D world coordinate system and perform motion editing directly in the 3D space. Trajectory control is implemented by unprojecting edited 2D trajectories into 3D with focal-length calibration and coordinate transformation, followed by speed alignment and orientation adjustment; actions are supplied by a motion bank or generated via text-to-motion methods. Then, based on modern text-to-video diffusion transformer models, we inject the subject as tokens for full attention, concatenate the background along the channel dimension, and add motion (trajectory and action) control signals by addition. Such a design opens up the possibility for us to generate realistic videos of anyone doing anything anywhere. Extensive experiments on benchmark datasets and real-world cases demonstrate that our method achieves state-of-the-art performance on both element-wise controllability and overall video quality.
Accelerating the discovery of low-energy structure configurations: a computational approach that integrates first-principles calculations, Monte Carlo sampling, and Machine Learning
Oct 08, 2024



Finding Minimum Energy Configurations (MECs) is essential in fields such as physics, chemistry, and materials science, as they represent the most stable states of the systems. In particular, identifying such MECs in multi-component alloys considered candidate PFMs is key because it determines the most stable arrangement of atoms within the alloy, directly influencing its phase stability, structural integrity, and thermo-mechanical properties. However, since the search space grows exponentially with the number of atoms considered, obtaining such MECs using computationally expensive first-principles DFT calculations often results in a cumbersome task. To escape the above compromise between physical fidelity and computational efficiency, we have developed a novel physics-based data-driven approach that combines Monte Carlo sampling, first-principles DFT calculations, and Machine Learning to accelerate the discovery of MECs in multi-component alloys. More specifically, we have leveraged well-established Cluster Expansion (CE) techniques with Local Outlier Factor models to establish strategies that enhance the reliability of the CE method. In this work, we demonstrated the capabilities of the proposed approach for the particular case of a tungsten-based quaternary high-entropy alloy. However, the method is applicable to other types of alloys and enables a wide range of applications.
UniDM: A Unified Framework for Data Manipulation with Large Language Models
May 10, 2024



Designing effective data manipulation methods is a long standing problem in data lakes. Traditional methods, which rely on rules or machine learning models, require extensive human efforts on training data collection and tuning models. Recent methods apply Large Language Models (LLMs) to resolve multiple data manipulation tasks. They exhibit bright benefits in terms of performance but still require customized designs to fit each specific task. This is very costly and can not catch up with the requirements of big data lake platforms. In this paper, inspired by the cross-task generality of LLMs on NLP tasks, we pave the first step to design an automatic and general solution to tackle with data manipulation tasks. We propose UniDM, a unified framework which establishes a new paradigm to process data manipulation tasks using LLMs. UniDM formalizes a number of data manipulation tasks in a unified form and abstracts three main general steps to solve each task. We develop an automatic context retrieval to allow the LLMs to retrieve data from data lakes, potentially containing evidence and factual information. For each step, we design effective prompts to guide LLMs to produce high quality results. By our comprehensive evaluation on a variety of benchmarks, our UniDM exhibits great generality and state-of-the-art performance on a wide variety of data manipulation tasks.
Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation
Sep 08, 2023



Large language models (LLMs) have emerged as a new paradigm for Text-to-SQL task. However, the absence of a systematical benchmark inhibits the development of designing effective, efficient and economic LLM-based Text-to-SQL solutions. To address this challenge, in this paper, we first conduct a systematical and extensive comparison over existing prompt engineering methods, including question representation, example selection and example organization, and with these experimental results, we elaborate their pros and cons. Based on these findings, we propose a new integrated solution, named DAIL-SQL, which refreshes the Spider leaderboard with 86.6% execution accuracy and sets a new bar. To explore the potential of open-source LLM, we investigate them in various scenarios, and further enhance their performance with supervised fine-tuning. Our explorations highlight open-source LLMs' potential in Text-to-SQL, as well as the advantages and disadvantages of the supervised fine-tuning. Additionally, towards an efficient and economic LLM-based Text-to-SQL solution, we emphasize the token efficiency in prompt engineering and compare the prior studies under this metric. We hope that our work provides a deeper understanding of Text-to-SQL with LLMs, and inspires further investigations and broad applications.
Maximizing Spatio-Temporal Entropy of Deep 3D CNNs for Efficient Video Recognition
Mar 05, 20233D convolution neural networks (CNNs) have been the prevailing option for video recognition. To capture the temporal information, 3D convolutions are computed along the sequences, leading to cubically growing and expensive computations. To reduce the computational cost, previous methods resort to manually designed 3D/2D CNN structures with approximations or automatic search, which sacrifice the modeling ability or make training time-consuming. In this work, we propose to automatically design efficient 3D CNN architectures via a novel training-free neural architecture search approach tailored for 3D CNNs considering the model complexity. To measure the expressiveness of 3D CNNs efficiently, we formulate a 3D CNN as an information system and derive an analytic entropy score, based on the Maximum Entropy Principle. Specifically, we propose a spatio-temporal entropy score (STEntr-Score) with a refinement factor to handle the discrepancy of visual information in spatial and temporal dimensions, through dynamically leveraging the correlation between the feature map size and kernel size depth-wisely. Highly efficient and expressive 3D CNN architectures, \ie entropy-based 3D CNNs (E3D family), can then be efficiently searched by maximizing the STEntr-Score under a given computational budget, via an evolutionary algorithm without training the network parameters. Extensive experiments on Something-Something V1\&V2 and Kinetics400 demonstrate that the E3D family achieves state-of-the-art performance with higher computational efficiency. Code is available at https://github.com/alibaba/lightweight-neural-architecture-search.
Entroformer: A Transformer-based Entropy Model for Learned Image Compression
Feb 11, 2022

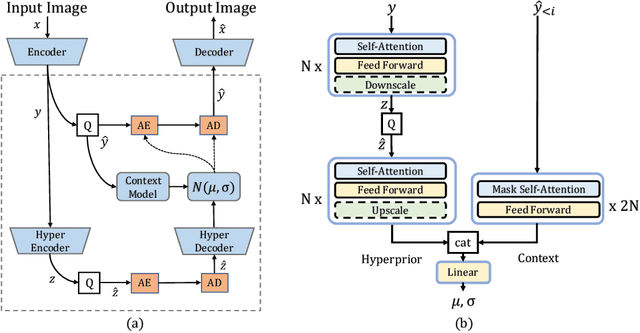

One critical component in lossy deep image compression is the entropy model, which predicts the probability distribution of the quantized latent representation in the encoding and decoding modules. Previous works build entropy models upon convolutional neural networks which are inefficient in capturing global dependencies. In this work, we propose a novel transformer-based entropy model, termed Entroformer, to capture long-range dependencies in probability distribution estimation effectively and efficiently. Different from vision transformers in image classification, the Entroformer is highly optimized for image compression, including a top-k self-attention and a diamond relative position encoding. Meanwhile, we further expand this architecture with a parallel bidirectional context model to speed up the decoding process. The experiments show that the Entroformer achieves state-of-the-art performance on image compression while being time-efficient.
Interpolation variable rate image compression
Sep 20, 2021
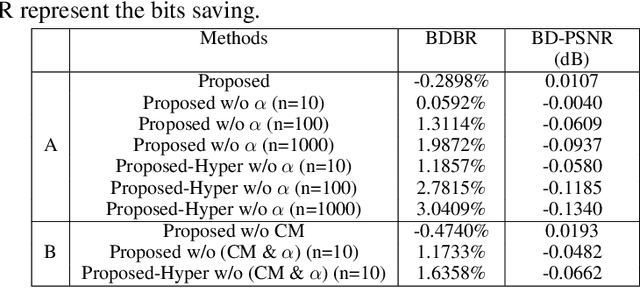
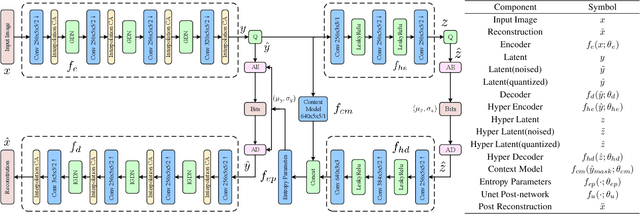
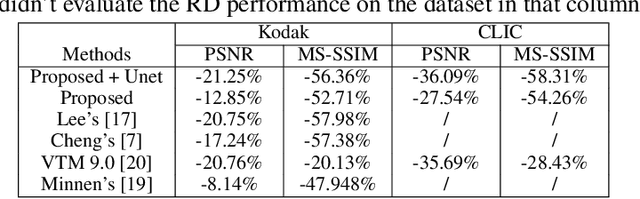
Compression standards have been used to reduce the cost of image storage and transmission for decades. In recent years, learned image compression methods have been proposed and achieved compelling performance to the traditional standards. However, in these methods, a set of different networks are used for various compression rates, resulting in a high cost in model storage and training. Although some variable-rate approaches have been proposed to reduce the cost by using a single network, most of them brought some performance degradation when applying fine rate control. To enable variable-rate control without sacrificing the performance, we propose an efficient Interpolation Variable-Rate (IVR) network, by introducing a handy Interpolation Channel Attention (InterpCA) module in the compression network. With the use of two hyperparameters for rate control and linear interpolation, the InterpCA achieves a fine PSNR interval of 0.001 dB and a fine rate interval of 0.0001 Bits-Per-Pixel (BPP) with 9000 rates in the IVR network. Experimental results demonstrate that the IVR network is the first variable-rate learned method that outperforms VTM 9.0 (intra) in PSNR and Multiscale Structural Similarity (MS-SSIM).
Spatiotemporal Entropy Model is All You Need for Learned Video Compression
Apr 13, 2021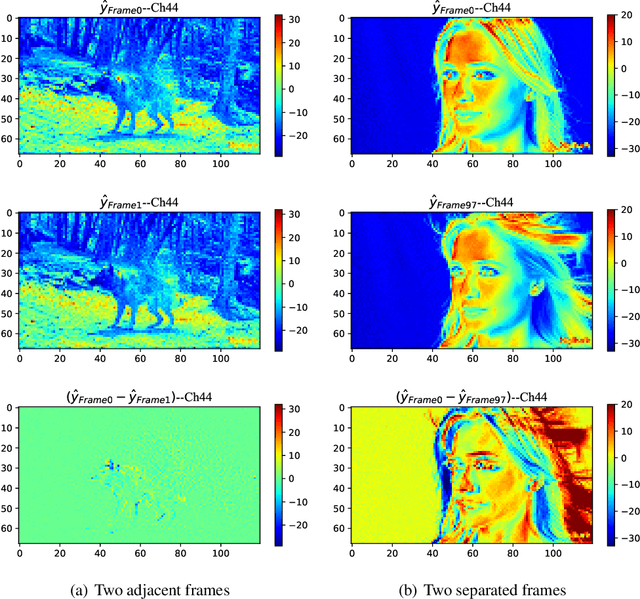

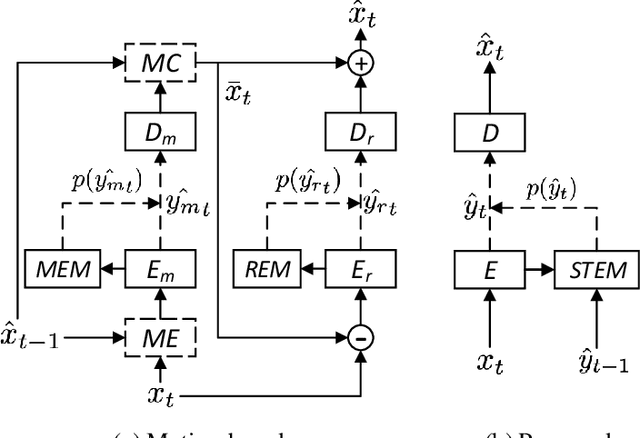
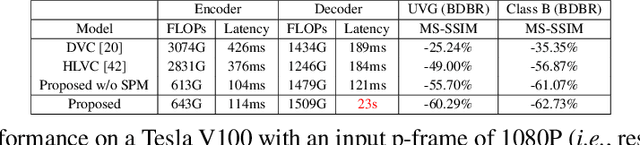
The framework of dominant learned video compression methods is usually composed of motion prediction modules as well as motion vector and residual image compression modules, suffering from its complex structure and error propagation problem. Approaches have been proposed to reduce the complexity by replacing motion prediction modules with implicit flow networks. Error propagation aware training strategy is also proposed to alleviate incremental reconstruction errors from previously decoded frames. Although these methods have brought some improvement, little attention has been paid to the framework itself. Inspired by the success of learned image compression through simplifying the framework with a single deep neural network, it is natural to expect a better performance in video compression via a simple yet appropriate framework. Therefore, we propose a framework to directly compress raw-pixel frames (rather than residual images), where no extra motion prediction module is required. Instead, an entropy model is used to estimate the spatiotemporal redundancy in a latent space rather than pixel level, which significantly reduces the complexity of the framework. Specifically, the whole framework is a compression module, consisting of a unified auto-encoder which produces identically distributed latents for all frames, and a spatiotemporal entropy estimation model to minimize the entropy of these latents. Experiments showed that the proposed method outperforms state-of-the-art (SOTA) performance under the metric of multiscale structural similarity (MS-SSIM) and achieves competitive results under the metric of PSNR.
Learning Accurate Entropy Model with Global Reference for Image Compression
Oct 29, 2020


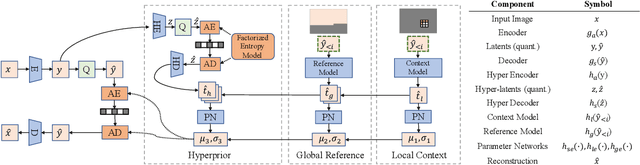
In recent deep image compression neural networks, the entropy model plays a critical role in estimating the prior distribution of deep image encodings. Existing methods combine hyperprior with local context in the entropy estimation function. This greatly limits their performance due to the absence of a global vision. In this work, we propose a novel Global Reference Model for image compression to effectively leverage both the local and the global context information, leading to an enhanced compression rate. The proposed method scans decoded latents and then finds the most relevant latent to assist the distribution estimating of the current latent. A by-product of this work is the innovation of a mean-shifting GDN module that further improves the performance. Experimental results demonstrate that the proposed model outperforms the rate-distortion performance of most of the state-of-the-art methods in the industry.