 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoRet: Improved Retriever for Code Editing
May 30, 2025



In this paper, we introduce CoRet, a dense retrieval model designed for code-editing tasks that integrates code semantics, repository structure, and call graph dependencies. The model focuses on retrieving relevant portions of a code repository based on natural language queries such as requests to implement new features or fix bugs. These retrieved code chunks can then be presented to a user or to a second code-editing model or agent. To train CoRet, we propose a loss function explicitly designed for repository-level retrieval. On SWE-bench and Long Code Arena's bug localisation datasets, we show that our model substantially improves retrieval recall by at least 15 percentage points over existing models, and ablate the design choices to show their importance in achieving these results.
Hyperband-based Bayesian Optimization for Black-box Prompt Selection
Dec 10, 2024



Optimal prompt selection is crucial for maximizing large language model (LLM) performance on downstream tasks. As the most powerful models are proprietary and can only be invoked via an API, users often manually refine prompts in a black-box setting by adjusting instructions and few-shot examples until they achieve good performance as measured on a validation set. Recent methods addressing static black-box prompt selection face significant limitations: They often fail to leverage the inherent structure of prompts, treating instructions and few-shot exemplars as a single block of text. Moreover, they often lack query-efficiency by evaluating prompts on all validation instances, or risk sub-optimal selection of a prompt by using random subsets of validation instances. We introduce HbBoPs, a novel Hyperband-based Bayesian optimization method for black-box prompt selection addressing these key limitations. Our approach combines a structural-aware deep kernel Gaussian Process to model prompt performance with Hyperband as a multi-fidelity scheduler to select the number of validation instances for prompt evaluations. The structural-aware modeling approach utilizes separate embeddings for instructions and few-shot exemplars, enhancing the surrogate model's ability to capture prompt performance and predict which prompt to evaluate next in a sample-efficient manner. Together with Hyperband as a multi-fidelity scheduler we further enable query-efficiency by adaptively allocating resources across different fidelity levels, keeping the total number of validation instances prompts are evaluated on low. Extensive evaluation across ten benchmarks and three LLMs demonstrate that HbBoPs outperforms state-of-the-art methods.
Cost-Effective Hallucination Detection for LLMs
Jul 31, 2024



Large language models (LLMs) can be prone to hallucinations - generating unreliable outputs that are unfaithful to their inputs, external facts or internally inconsistent. In this work, we address several challenges for post-hoc hallucination detection in production settings. Our pipeline for hallucination detection entails: first, producing a confidence score representing the likelihood that a generated answer is a hallucination; second, calibrating the score conditional on attributes of the inputs and candidate response; finally, performing detection by thresholding the calibrated score. We benchmark a variety of state-of-the-art scoring methods on different datasets, encompassing question answering, fact checking, and summarization tasks. We employ diverse LLMs to ensure a comprehensive assessment of performance. We show that calibrating individual scoring methods is critical for ensuring risk-aware downstream decision making. Based on findings that no individual score performs best in all situations, we propose a multi-scoring framework, which combines different scores and achieves top performance across all datasets. We further introduce cost-effective multi-scoring, which can match or even outperform more expensive detection methods, while significantly reducing computational overhead.
Choice of PEFT Technique in Continual Learning: Prompt Tuning is Not All You Need
Jun 05, 2024



Recent Continual Learning (CL) methods have combined pretrained Transformers with prompt tuning, a parameter-efficient fine-tuning (PEFT) technique. We argue that the choice of prompt tuning in prior works was an undefended and unablated decision, which has been uncritically adopted by subsequent research, but warrants further research to understand its implications. In this paper, we conduct this research and find that the choice of prompt tuning as a PEFT method hurts the overall performance of the CL system. To illustrate this, we replace prompt tuning with LoRA in two state-of-the-art continual learning methods: Learning to Prompt and S-Prompts. These variants consistently achieve higher accuracy across a wide range of domain-incremental and class-incremental benchmarks, while being competitive in inference speed. Our work highlights a crucial argument: unexamined choices can hinder progress in the field, and rigorous ablations, such as the PEFT method, are required to drive meaningful adoption of CL techniques in real-world applications.
A Negative Result on Gradient Matching for Selective Backprop
Dec 08, 2023



With increasing scale in model and dataset size, the training of deep neural networks becomes a massive computational burden. One approach to speed up the training process is Selective Backprop. For this approach, we perform a forward pass to obtain a loss value for each data point in a minibatch. The backward pass is then restricted to a subset of that minibatch, prioritizing high-loss examples. We build on this approach, but seek to improve the subset selection mechanism by choosing the (weighted) subset which best matches the mean gradient over the entire minibatch. We use the gradients w.r.t. the model's last layer as a cheap proxy, resulting in virtually no overhead in addition to the forward pass. At the same time, for our experiments we add a simple random selection baseline which has been absent from prior work. Surprisingly, we find that both the loss-based as well as the gradient-matching strategy fail to consistently outperform the random baseline.
Continual Learning with Low Rank Adaptation
Nov 29, 2023



Recent work using pretrained transformers has shown impressive performance when fine-tuned with data from the downstream problem of interest. However, they struggle to retain that performance when the data characteristics changes. In this paper, we focus on continual learning, where a pre-trained transformer is updated to perform well on new data, while retaining its performance on data it was previously trained on. Earlier works have tackled this primarily through methods inspired from prompt tuning. We question this choice, and investigate the applicability of Low Rank Adaptation (LoRA) to continual learning. On a range of domain-incremental learning benchmarks, our LoRA-based solution, CoLoR, yields state-of-the-art performance, while still being as parameter efficient as the prompt tuning based methods.
Renate: A Library for Real-World Continual Learning
Apr 24, 2023


Continual learning enables the incremental training of machine learning models on non-stationary data streams.While academic interest in the topic is high, there is little indication of the use of state-of-the-art continual learning algorithms in practical machine learning deployment. This paper presents Renate, a continual learning library designed to build real-world updating pipelines for PyTorch models. We discuss requirements for the use of continual learning algorithms in practice, from which we derive design principles for Renate. We give a high-level description of the library components and interfaces. Finally, we showcase the strengths of the library by presenting experimental results. Renate may be found at https://github.com/awslabs/renate.
PASHA: Efficient HPO with Progressive Resource Allocation
Jul 14, 2022
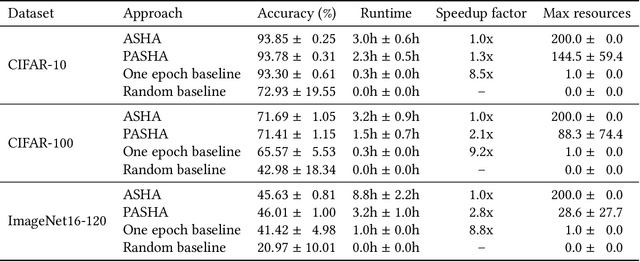
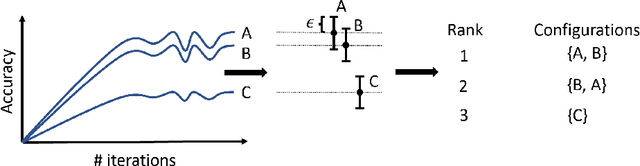
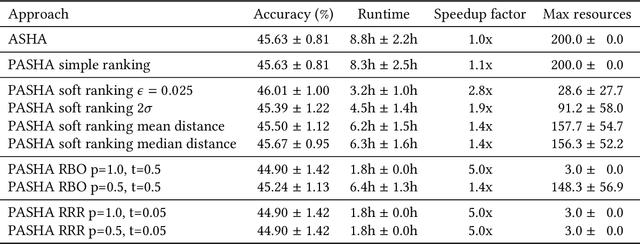
Hyperparameter optimization (HPO) and neural architecture search (NAS) are methods of choice to obtain the best-in-class machine learning models, but in practice they can be costly to run. When models are trained on large datasets, tuning them with HPO or NAS rapidly becomes prohibitively expensive for practitioners, even when efficient multi-fidelity methods are employed. We propose an approach to tackle the challenge of tuning machine learning models trained on large datasets with limited computational resources. Our approach, named PASHA, is able to dynamically allocate maximum resources for the tuning procedure depending on the need. The experimental comparison shows that PASHA identifies well-performing hyperparameter configurations and architectures while consuming significantly fewer computational resources than solutions like ASHA.
Continual Learning with Transformers for Image Classification
Jun 28, 2022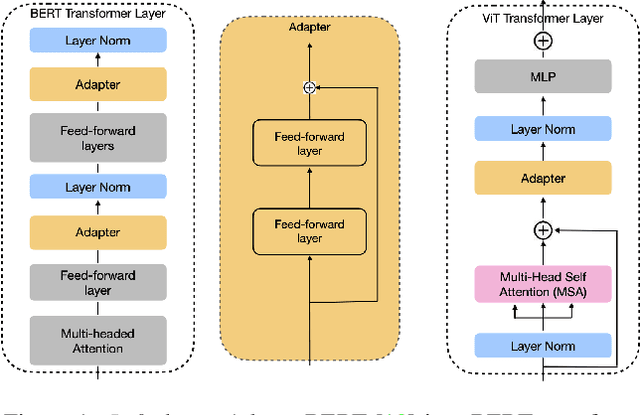
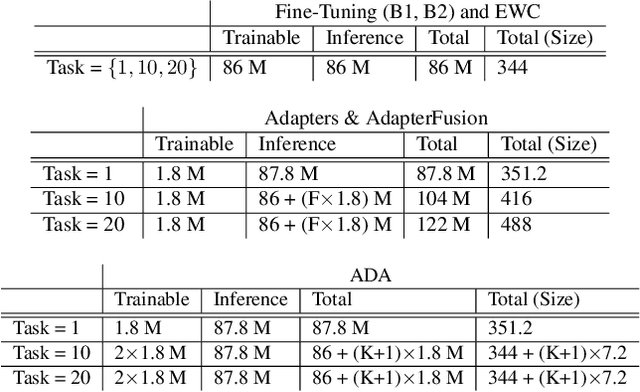
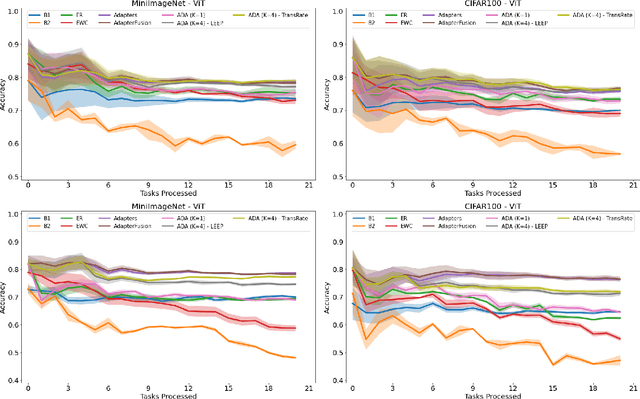
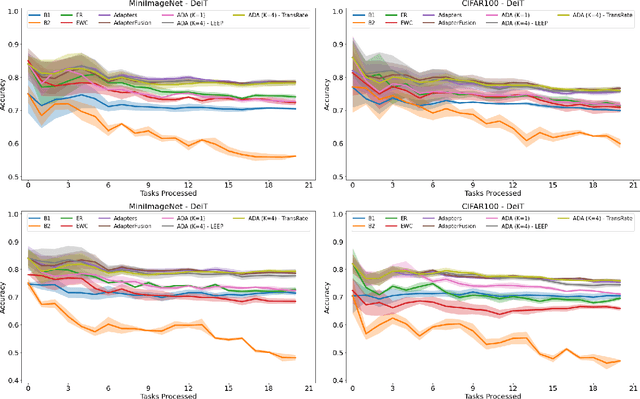
In many real-world scenarios, data to train machine learning models become available over time. However, neural network models struggle to continually learn new concepts without forgetting what has been learnt in the past. This phenomenon is known as catastrophic forgetting and it is often difficult to prevent due to practical constraints, such as the amount of data that can be stored or the limited computation sources that can be used. Moreover, training large neural networks, such as Transformers, from scratch is very costly and requires a vast amount of training data, which might not be available in the application domain of interest. A recent trend indicates that dynamic architectures based on an expansion of the parameters can reduce catastrophic forgetting efficiently in continual learning, but this needs complex tuning to balance the growing number of parameters and barely share any information across tasks. As a result, they struggle to scale to a large number of tasks without significant overhead. In this paper, we validate in the computer vision domain a recent solution called Adaptive Distillation of Adapters (ADA), which is developed to perform continual learning using pre-trained Transformers and Adapters on text classification tasks. We empirically demonstrate on different classification tasks that this method maintains a good predictive performance without retraining the model or increasing the number of model parameters over the time. Besides it is significantly faster at inference time compared to the state-of-the-art methods.
Gradient-Matching Coresets for Rehearsal-Based Continual Learning
Mar 28, 2022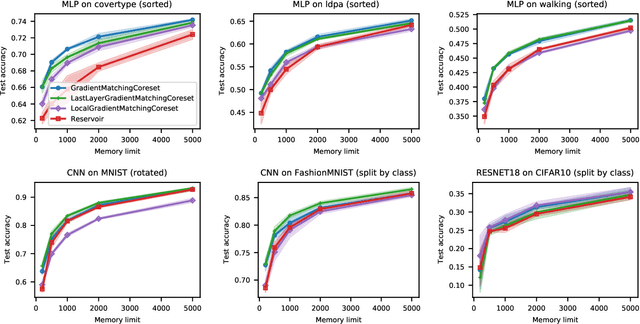
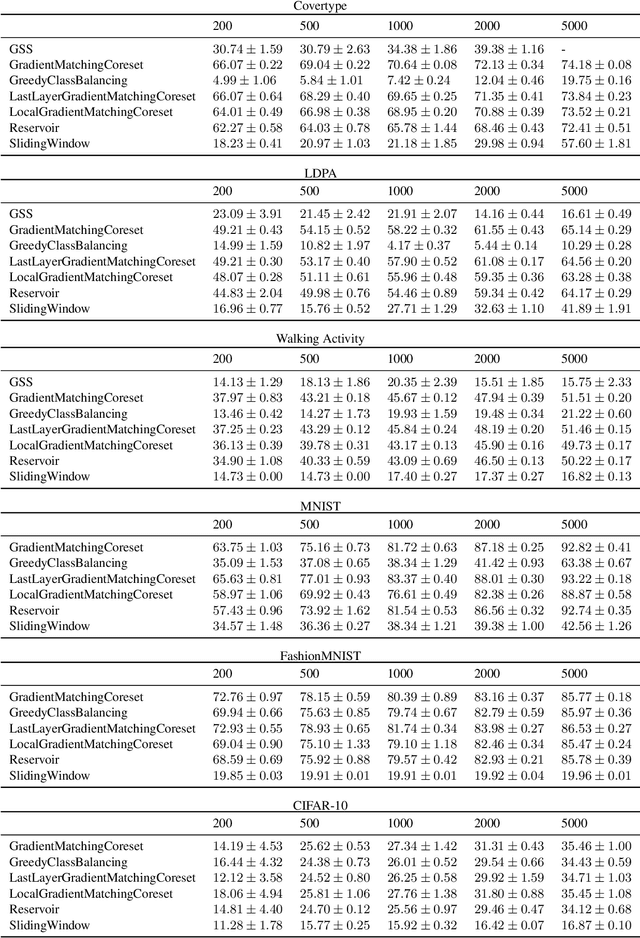
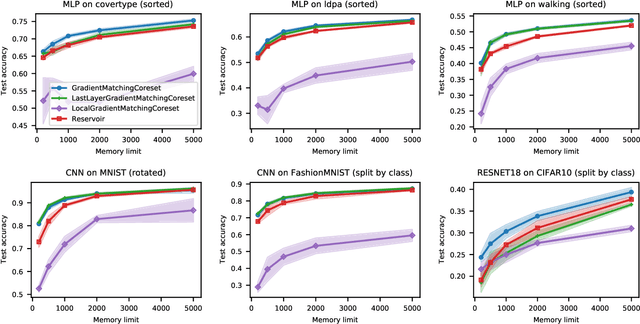
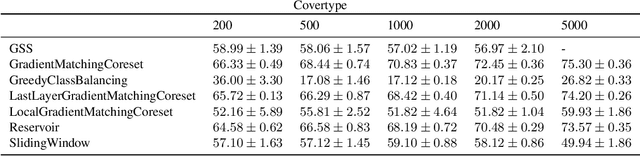
The goal of continual learning (CL) is to efficiently update a machine learning model with new data without forgetting previously-learned knowledge. Most widely-used CL methods rely on a rehearsal memory of data points to be reused while training on new data. Curating such a rehearsal memory to maintain a small, informative subset of all the data seen so far is crucial to the success of these methods. We devise a coreset selection method for rehearsal-based continual learning. Our method is based on the idea of gradient matching: The gradients induced by the coreset should match, as closely as possible, those induced by the original training dataset. Inspired by the neural tangent kernel theory, we perform this gradient matching across the model's initialization distribution, allowing us to extract a coreset without having to train the model first. We evaluate the method on a wide range of continual learning scenarios and demonstrate that it improves the performance of rehearsal-based CL methods compared to competing memory management strategies such as reservoir sampling.