 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Belief Reinforcement Learning for Efficient Coordinated Spatial Exploration
Mar 04, 2026Coordinating multiple autonomous agents to explore and serve spatially heterogeneous demand requires jointly learning unknown spatial patterns and planning trajectories that maximize task performance. Pure model-based approaches provide structured uncertainty estimates but lack adaptive policy learning, while deep reinforcement learning often suffers from poor sample efficiency when spatial priors are absent. This paper presents a hybrid belief-reinforcement learning (HBRL) framework to address this gap. In the first phase, agents construct spatial beliefs using a Log-Gaussian Cox Process (LGCP) and execute information-driven trajectories guided by a Pathwise Mutual Information (PathMI) planner with multi-step lookahead. In the second phase, trajectory control is transferred to a Soft Actor-Critic (SAC) agent, warm-started through dual-channel knowledge transfer: belief state initialization supplies spatial uncertainty, and replay buffer seeding provides demonstration trajectories generated during LGCP exploration. A variance-normalized overlap penalty enables coordinated coverage through shared belief state, permitting cooperative sensing in high-uncertainty regions while discouraging redundant coverage in well-explored areas. The framework is evaluated on a multi-UAV wireless service provisioning task. Results show 10.8% higher cumulative reward and 38% faster convergence over baselines, with ablation studies confirming that dual-channel transfer outperforms either channel alone.
Induced Modularity and Community Detection for Functionally Interpretable Reinforcement Learning
Jan 28, 2025



Interpretability in reinforcement learning is crucial for ensuring AI systems align with human values and fulfill the diverse related requirements including safety, robustness and fairness. Building on recent approaches to encouraging sparsity and locality in neural networks, we demonstrate how the penalisation of non-local weights leads to the emergence of functionally independent modules in the policy network of a reinforcement learning agent. To illustrate this, we demonstrate the emergence of two parallel modules for assessment of movement along the X and Y axes in a stochastic Minigrid environment. Through the novel application of community detection algorithms, we show how these modules can be automatically identified and their functional roles verified through direct intervention on the network weights prior to inference. This establishes a scalable framework for reinforcement learning interpretability through functional modularity, addressing challenges regarding the trade-off between completeness and cognitive tractability of reinforcement learning explanations.
Adaptive Probabilistic Planning for the Uncertain and Dynamic Orienteering Problem
Sep 09, 2024



The Orienteering Problem (OP) is a well-studied routing problem that has been extended to incorporate uncertainties, reflecting stochastic or dynamic travel costs, prize-collection costs, and prizes. Existing approaches may, however, be inefficient in real-world applications due to insufficient modeling knowledge and initially unknowable parameters in online scenarios. Thus, we propose the Uncertain and Dynamic Orienteering Problem (UDOP), modeling travel costs as distributions with unknown and time-variant parameters. UDOP also associates uncertain travel costs with dynamic prizes and prize-collection costs for its objective and budget constraints. To address UDOP, we develop an ADaptive Approach for Probabilistic paThs - ADAPT, that iteratively performs 'execution' and 'online planning' based on an initial 'offline' solution. The execution phase updates system status and records online cost observations. The online planner employs a Bayesian approach to adaptively estimate power consumption and optimize path sequence based on safety beliefs. We evaluate ADAPT in a practical Unmanned Aerial Vehicle (UAV) charging scheduling problem for Wireless Rechargeable Sensor Networks. The UAV must optimize its path to recharge sensor nodes efficiently while managing its energy under uncertain conditions. ADAPT maintains comparable solution quality and computation time while offering superior robustness. Extensive simulations show that ADAPT achieves a 100% Mission Success Rate (MSR) across all tested scenarios, outperforming comparable heuristic-based and frequentist approaches that fail up to 70% (under challenging conditions) and averaging 67% MSR, respectively. This work advances the field of OP with uncertainties, offering a reliable and efficient approach for real-world applications in uncertain and dynamic environments.
Is That Rain? Understanding Effects on Visual Odometry Performance for Autonomous UAVs and Efficient DNN-based Rain Classification at the Edge
Jul 17, 2024



The development of safe and reliable autonomous unmanned aerial vehicles relies on the ability of the system to recognise and adapt to changes in the local environment based on sensor inputs. State-of-the-art local tracking and trajectory planning are typically performed using camera sensor input to the flight control algorithm, but the extent to which environmental disturbances like rain affect the performance of these systems is largely unknown. In this paper, we first describe the development of an open dataset comprising ~335k images to examine these effects for seven different classes of precipitation conditions and show that a worst-case average tracking error of 1.5 m is possible for a state-of-the-art visual odometry system (VINS-Fusion). We then use the dataset to train a set of deep neural network models suited to mobile and constrained deployment scenarios to determine the extent to which it may be possible to efficiently and accurately classify these `rainy' conditions. The most lightweight of these models (MobileNetV3 small) can achieve an accuracy of 90% with a memory footprint of just 1.28 MB and a frame rate of 93 FPS, which is suitable for deployment in resource-constrained and latency-sensitive systems. We demonstrate a classification latency in the order of milliseconds using typical flight computer hardware. Accordingly, such a model can feed into the disturbance estimation component of an autonomous flight controller. In addition, data from unmanned aerial vehicles with the ability to accurately determine environmental conditions in real time may contribute to developing more granular timely localised weather forecasting.
On Solving Close Enough Orienteering Problem with Overlapped Neighborhoods
Oct 06, 2023The Close Enough Traveling Salesman Problem (CETSP) is a well-known variant of the classic Traveling Salesman Problem whereby the agent may complete its mission at any point within a target neighborhood. Heuristics based on overlapped neighborhoods, known as Steiner Zones (SZ), have gained attention in addressing CETSPs. While SZs offer effective approximations to the original graph, their inherent overlap imposes constraints on the search space, potentially conflicting with global optimization objectives. Here we present the Close Enough Orienteering Problem with Non-uniform Neighborhoods (CEOP-N), which extends CETSP by introducing variable prize attributes and non-uniform cost considerations for prize collection. To tackle CEOP-N, we develop a new approach featuring a Randomized Steiner Zone Discretization (RSZD) scheme coupled with a hybrid algorithm based on Particle Swarm Optimization (PSO) and Ant Colony System (ACS) - CRaSZe-AntS. The RSZD scheme identifies sub-regions for PSO exploration, and ACS determines the discrete visiting sequence. We evaluate the RSZD's discretization performance on CEOP instances derived from established CETSP instances, and compare CRaSZe-AntS against the most relevant state-of-the-art heuristic focused on single-neighborhood optimization for CEOP. We also compare the performance of the interior search within SZs and the boundary search on individual neighborhoods in the context of CEOP-N. Our results show CRaSZe-AntS can yield comparable solution quality with significantly reduced computation time compared to the single-neighborhood strategy, where we observe an averaged 140.44% increase in prize collection and 55.18% reduction of execution time. CRaSZe-AntS is thus highly effective in solving emerging CEOP-N, examples of which include truck-and-drone delivery scenarios.
Safe Reinforcement Learning as Wasserstein Variational Inference: Formal Methods for Interpretability
Jul 13, 2023Reinforcement Learning or optimal control can provide effective reasoning for sequential decision-making problems with variable dynamics. Such reasoning in practical implementation, however, poses a persistent challenge in interpreting the reward function and corresponding optimal policy. Consequently, formalizing the sequential decision-making problems as inference has a considerable value, as probabilistic inference in principle offers diverse and powerful mathematical tools to infer the stochastic dynamics whilst suggesting a probabilistic interpretation of the reward design and policy convergence. In this study, we propose a novel Adaptive Wasserstein Variational Optimization (AWaVO) to tackle these challenges in sequential decision-making. Our approach utilizes formal methods to provide interpretations of reward design, transparency of training convergence, and probabilistic interpretation of sequential decisions. To demonstrate practicality, we show convergent training with guaranteed global convergence rates not only in simulation but also in real robot tasks, and empirically verify a reasonable tradeoff between high performance and conservative interpretability.
Multi-Agent Reinforcement Learning with Action Masking for UAV-enabled Mobile Communications
Mar 29, 2023



Unmanned Aerial Vehicles (UAVs) are increasingly used as aerial base stations to provide ad hoc communications infrastructure. Building upon prior research efforts which consider either static nodes, 2D trajectories or single UAV systems, this paper focuses on the use of multiple UAVs for providing wireless communication to mobile users in the absence of terrestrial communications infrastructure. In particular, we jointly optimize UAV 3D trajectory and NOMA power allocation to maximize system throughput. Firstly, a weighted K-means-based clustering algorithm establishes UAV-user associations at regular intervals. The efficacy of training a novel Shared Deep Q-Network (SDQN) with action masking is then explored. Unlike training each UAV separately using DQN, the SDQN reduces training time by using the experiences of multiple UAVs instead of a single agent. We also show that SDQN can be used to train a multi-agent system with differing action spaces. Simulation results confirm that: 1) training a shared DQN outperforms a conventional DQN in terms of maximum system throughput (+20%) and training time (-10%); 2) it can converge for agents with different action spaces, yielding a 9% increase in throughput compared to mutual learning algorithms; and 3) combining NOMA with an SDQN architecture enables the network to achieve a better sum rate compared with existing baseline schemes.
Trustworthy Reinforcement Learning for Quadrotor UAV Tracking Control Systems
Feb 22, 2023Simultaneously accurate and reliable tracking control for quadrotors in complex dynamic environments is challenging. As aerodynamics derived from drag forces and moment variations are chaotic and difficult to precisely identify, most current quadrotor tracking systems treat them as simple `disturbances' in conventional control approaches. We propose a novel, interpretable trajectory tracker integrating a Distributional Reinforcement Learning disturbance estimator for unknown aerodynamic effects with a Stochastic Model Predictive Controller (SMPC). The proposed estimator `Constrained Distributional Reinforced disturbance estimator' (ConsDRED) accurately identifies uncertainties between true and estimated values of aerodynamic effects. Simplified Affine Disturbance Feedback is used for control parameterization to guarantee convexity, which we then integrate with a SMPC. We theoretically guarantee that ConsDRED achieves at least an optimal global convergence rate and a certain sublinear rate if constraints are violated with an error decreases as the width and the layer of neural network increase. To demonstrate practicality, we show convergent training in simulation and real-world experiments, and empirically verify that ConsDRED is less sensitive to hyperparameter settings compared with canonical constrained RL approaches. We demonstrate our system improves accumulative tracking errors by at least 62% compared with the recent art. Importantly, the proposed framework, ConsDRED-SMPC, balances the tradeoff between pursuing high performance and obeying conservative constraints for practical implementations
QuaDUE-CCM: Interpretable Distributional Reinforcement Learning using Uncertain Contraction Metrics for Precise Quadrotor Trajectory Tracking
Jul 15, 2022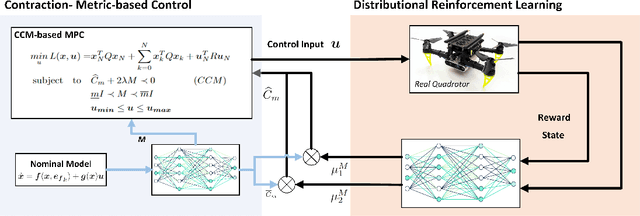

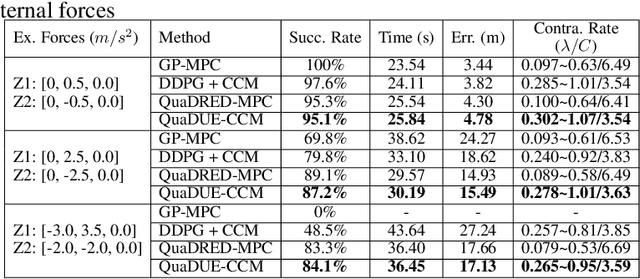
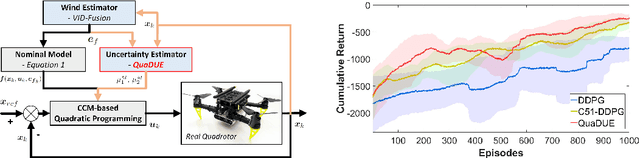
Accuracy and stability are common requirements for Quadrotor trajectory tracking systems. Designing an accurate and stable tracking controller remains challenging, particularly in unknown and dynamic environments with complex aerodynamic disturbances. We propose a Quantile-approximation-based Distributional-reinforced Uncertainty Estimator (QuaDUE) to accurately identify the effects of aerodynamic disturbances, i.e., the uncertainties between the true and estimated Control Contraction Metrics (CCMs). Taking inspiration from contraction theory and integrating the QuaDUE for uncertainties, our novel CCM-based trajectory tracking framework tracks any feasible reference trajectory precisely whilst guaranteeing exponential convergence. More importantly, the convergence and training acceleration of the distributional RL are guaranteed and analyzed, respectively, from theoretical perspectives. We also demonstrate our system under unknown and diverse aerodynamic forces. Under large aerodynamic forces (>2m/s^2), compared with the classic data-driven approach, our QuaDUE-CCM achieves at least a 56.6% improvement in tracking error. Compared with QuaDRED-MPC, a distributional RL-based approach, QuaDUE-CCM achieves at least a 3 times improvement in contraction rate.
Interpretable Stochastic Model Predictive Control using Distributional Reinforced Estimation for Quadrotor Tracking Systems
May 14, 2022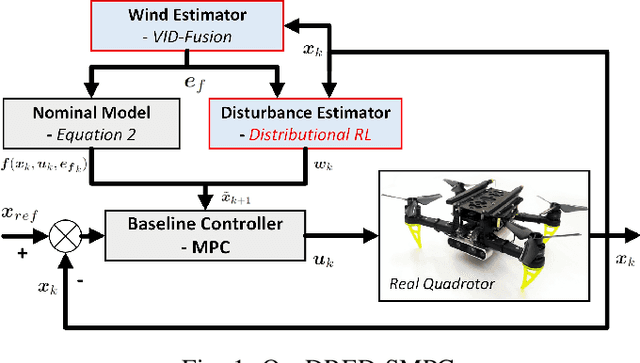
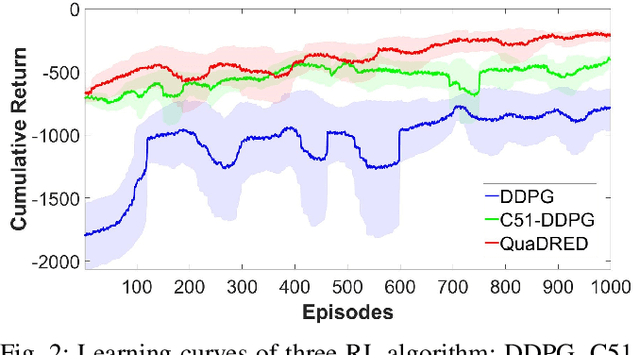
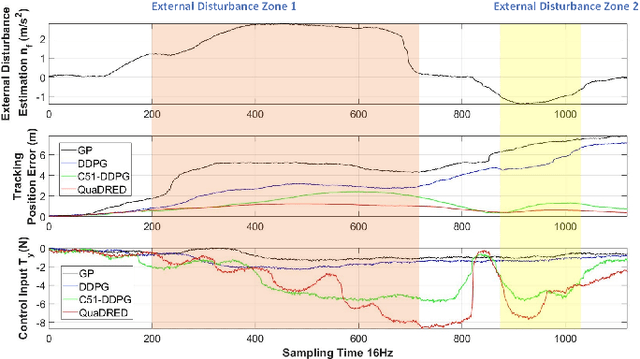
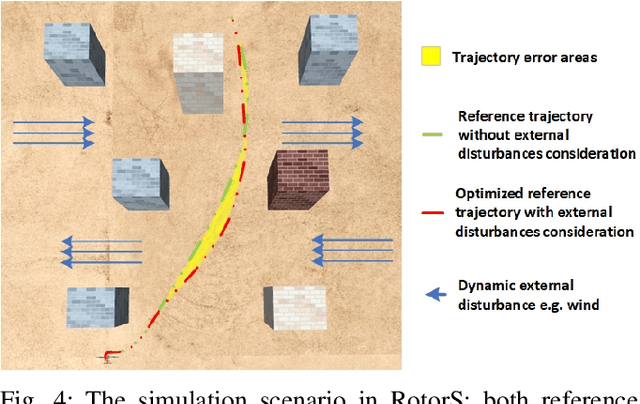
This paper presents a novel trajectory tracker for autonomous quadrotor navigation in dynamic and complex environments. The proposed framework integrates a distributional Reinforcement Learning (RL) estimator for unknown aerodynamic effects into a Stochastic Model Predictive Controller (SMPC) for trajectory tracking. Aerodynamic effects derived from drag forces and moment variations are difficult to model directly and accurately. Most current quadrotor tracking systems therefore treat them as simple `disturbances' in conventional control approaches. We propose Quantile-approximation-based Distributional Reinforced-disturbance-estimator, an aerodynamic disturbance estimator, to accurately identify disturbances, i.e., uncertainties between the true and estimated values of aerodynamic effects. Simplified Affine Disturbance Feedback is employed for control parameterization to guarantee convexity, which we then integrate with a SMPC to achieve sufficient and non-conservative control signals. We demonstrate our system to improve the cumulative tracking errors by at least 66% with unknown and diverse aerodynamic forces compared with recent state-of-the-art. Concerning traditional Reinforcement Learning's non-interpretability, we provide convergence and stability guarantees of Distributional RL and SMPC, respectively, with non-zero mean disturbances.