 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Brain-inspired Multilayer Perceptron with Spiking Neurons
Mar 28, 2022
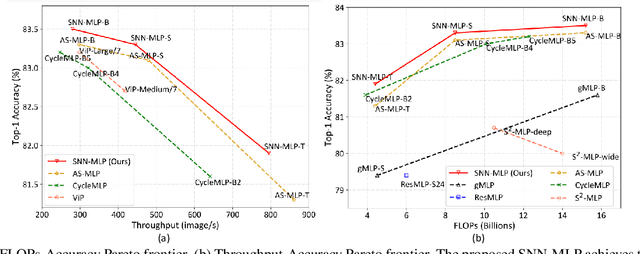
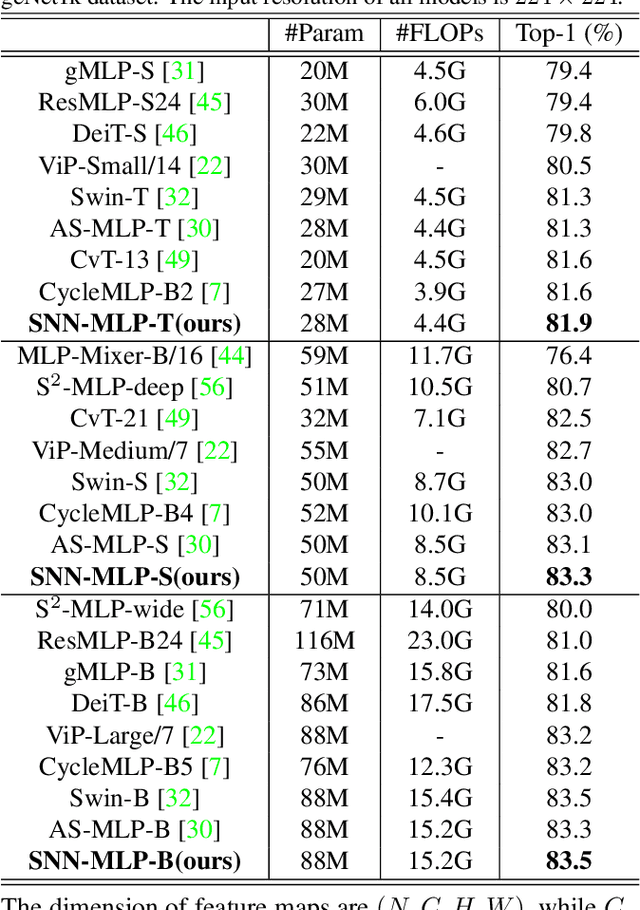
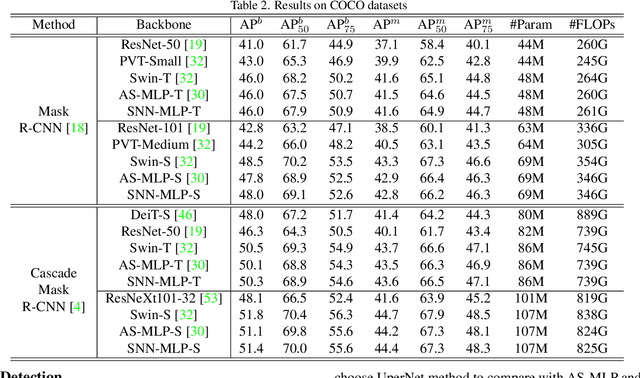
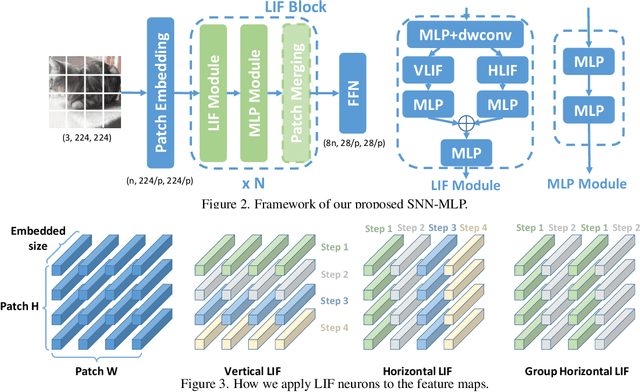
Recently, Multilayer Perceptron (MLP) becomes the hotspot in the field of computer vision tasks. Without inductive bias, MLPs perform well on feature extraction and achieve amazing results. However, due to the simplicity of their structures, the performance highly depends on the local features communication machenism. To further improve the performance of MLP, we introduce information communication mechanisms from brain-inspired neural networks. Spiking Neural Network (SNN) is the most famous brain-inspired neural network, and achieve great success on dealing with sparse data. Leaky Integrate and Fire (LIF) neurons in SNNs are used to communicate between different time steps. In this paper, we incorporate the machanism of LIF neurons into the MLP models, to achieve better accuracy without extra FLOPs. We propose a full-precision LIF operation to communicate between patches, including horizontal LIF and vertical LIF in different directions. We also propose to use group LIF to extract better local features. With LIF modules, our SNN-MLP model achieves 81.9%, 83.3% and 83.5% top-1 accuracy on ImageNet dataset with only 4.4G, 8.5G and 15.2G FLOPs, respectively, which are state-of-the-art results as far as we know.
A deep residual learning implementation of Metamorphosis
Feb 01, 2022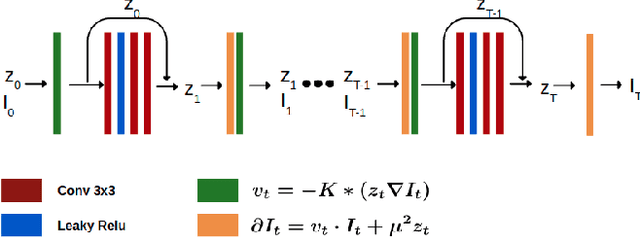
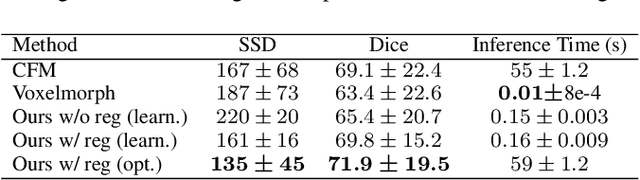
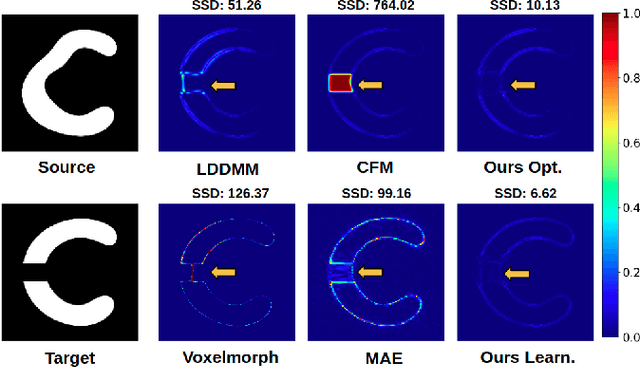
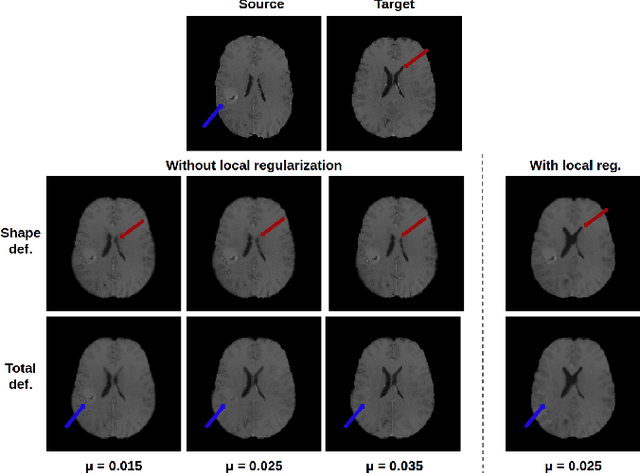
In medical imaging, most of the image registration methods implicitly assume a one-to-one correspondence between the source and target images (i.e., diffeomorphism). However, this is not necessarily the case when dealing with pathological medical images (e.g., presence of a tumor, lesion, etc.). To cope with this issue, the Metamorphosis model has been proposed. It modifies both the shape and the appearance of an image to deal with the geometrical and topological differences. However, the high computational time and load have hampered its applications so far. Here, we propose a deep residual learning implementation of Metamorphosis that drastically reduces the computational time at inference. Furthermore, we also show that the proposed framework can easily integrate prior knowledge of the localization of topological changes (e.g., segmentation masks) that can act as spatial regularization to correctly disentangle appearance and shape changes. We test our method on the BraTS 2021 dataset, showing that it outperforms current state-of-the-art methods in the alignment of images with brain tumors.
Towards Online Domain Adaptive Object Detection
Apr 11, 2022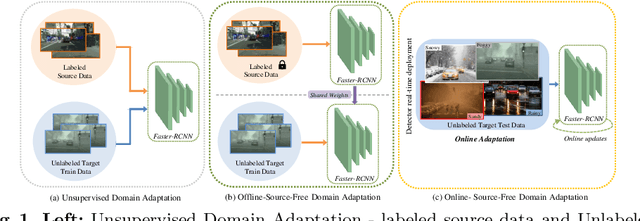
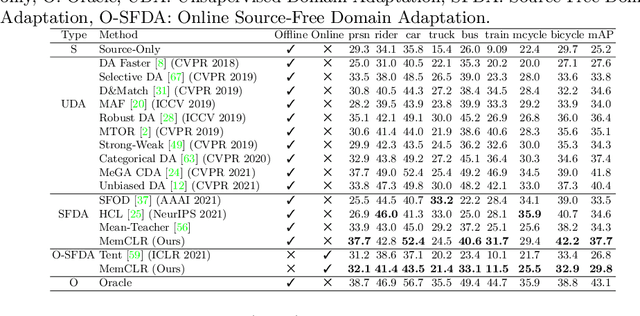
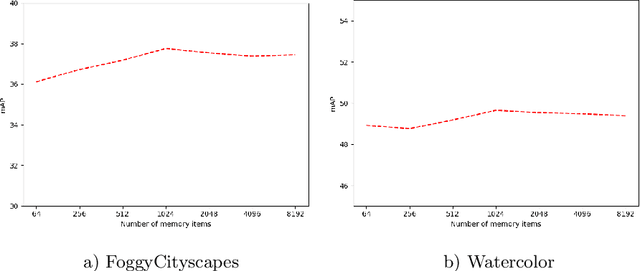
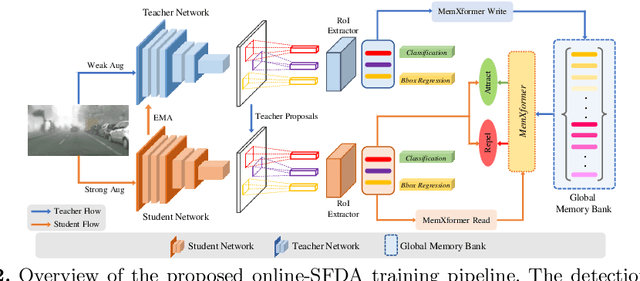
Existing object detection models assume both the training and test data are sampled from the same source domain. This assumption does not hold true when these detectors are deployed in real-world applications, where they encounter new visual domain. Unsupervised Domain Adaptation (UDA) methods are generally employed to mitigate the adverse effects caused by domain shift. Existing UDA methods operate in an offline manner where the model is first adapted towards the target domain and then deployed in real-world applications. However, this offline adaptation strategy is not suitable for real-world applications as the model frequently encounters new domain shifts. Hence, it becomes critical to develop a feasible UDA method that generalizes to these domain shifts encountered during deployment time in a continuous online manner. To this end, we propose a novel unified adaptation framework that adapts and improves generalization on the target domain in online settings. In particular, we introduce MemXformer - a cross-attention transformer-based memory module where items in the memory take advantage of domain shifts and record prototypical patterns of the target distribution. Further, MemXformer produces strong positive and negative pairs to guide a novel contrastive loss, which enhances target specific representation learning. Experiments on diverse detection benchmarks show that the proposed strategy can produce state-of-the-art performance in both online and offline settings. To the best of our knowledge, this is the first work to address online and offline adaptation settings for object detection. Code at https://github.com/Vibashan/online-od
AdaPT: Fast Emulation of Approximate DNN Accelerators in PyTorch
Mar 08, 2022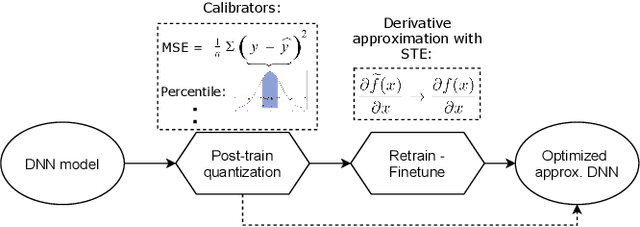
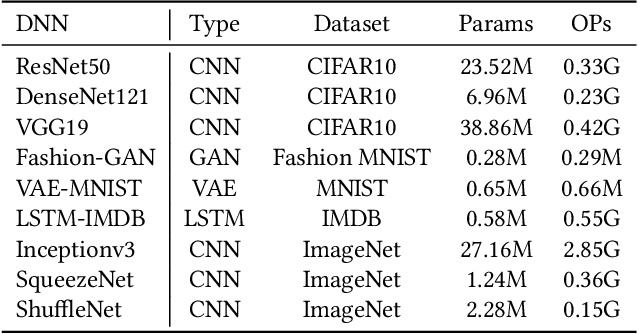
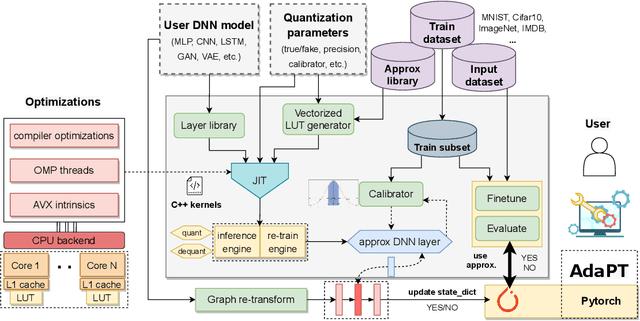
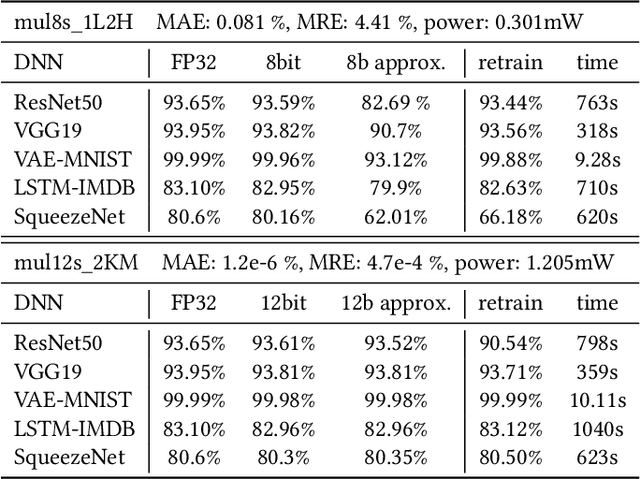
Current state-of-the-art employs approximate multipliers to address the highly increased power demands of DNN accelerators. However, evaluating the accuracy of approximate DNNs is cumbersome due to the lack of adequate support for approximate arithmetic in DNN frameworks. We address this inefficiency by presenting AdaPT, a fast emulation framework that extends PyTorch to support approximate inference as well as approximation-aware retraining. AdaPT can be seamlessly deployed and is compatible with the most DNNs. We evaluate the framework on several DNN models and application fields including CNNs, LSTMs, and GANs for a number of approximate multipliers with distinct bitwidth values. The results show substantial error recovery from approximate re-training and reduced inference time up to 53.9x with respect to the baseline approximate implementation.
Machine Learning-Based Automated Thermal Comfort Prediction: Integration of Low-Cost Thermal and Visual Cameras for Higher Accuracy
Apr 14, 2022

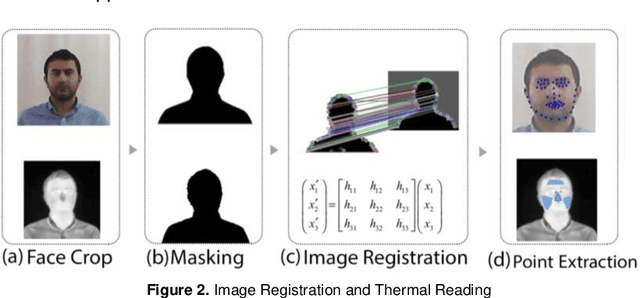
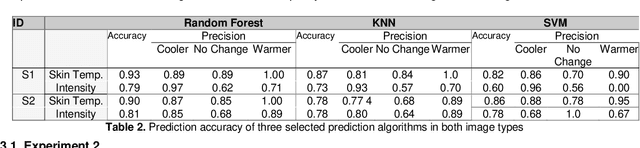
Recent research is trying to leverage occupants' demand in the building's control loop to consider individuals' well-being and the buildings' energy savings. To that end, a real-time feedback system is needed to provide data about occupants' comfort conditions that can be used to control the building's heating, cooling, and air conditioning (HVAC) system. The emergence of thermal imaging techniques provides an excellent opportunity for contactless data gathering with no interruption in occupant conditions and activities. There is increasing attention to infrared thermal camera usage in public buildings because of their non-invasive quality in reading the human skin temperature. However, the state-of-the-art methods need additional modifications to become more reliable. To capitalize potentials and address some existing limitations, new solutions are required to bring a more holistic view toward non-intrusive thermal scanning by leveraging the benefit of machine learning and image processing. This research implements an automated approach to collect and register simultaneous thermal and visual images and read the facial temperature in different regions. This paper also presents two additional investigations. First, through utilizing IButton wearable thermal sensors on the forehead area, we investigate the reliability of an in-expensive thermal camera (FLIR Lepton) in reading the skin temperature. Second, by studying the false-color version of thermal images, we look into the possibility of non-radiometric thermal images for predicting personalized thermal comfort. The results shows the strong performance of Random Forest and K-Nearest Neighbor prediction algorithms in predicting personalized thermal comfort. In addition, we have found that non-radiometric images can also indicate thermal comfort when the algorithm is trained with larger amounts of data.
Any Way You Look At It: Semantic Crossview Localization and Mapping with LiDAR
Mar 16, 2022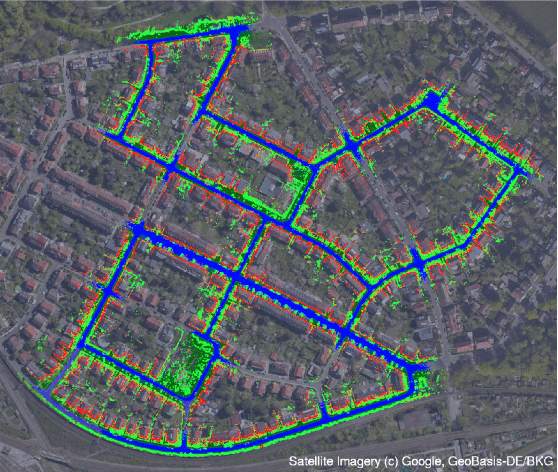
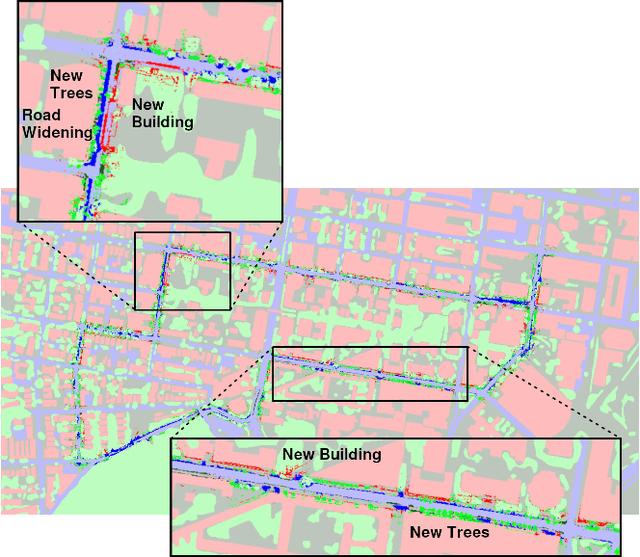
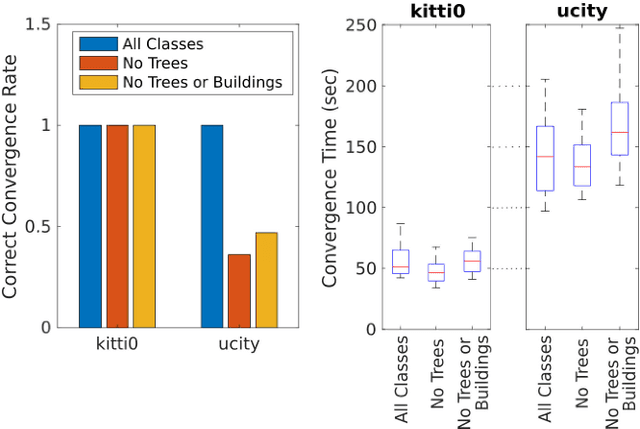
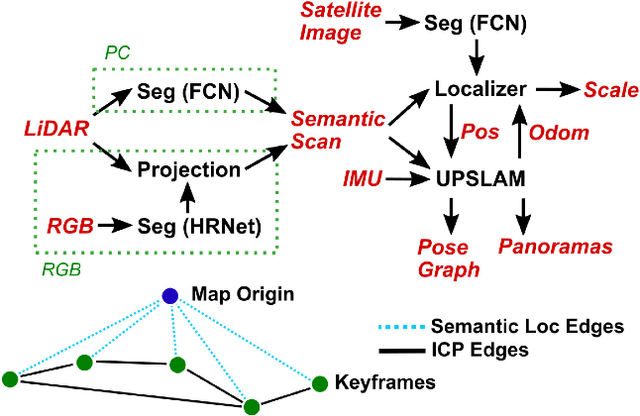
Currently, GPS is by far the most popular global localization method. However, it is not always reliable or accurate in all environments. SLAM methods enable local state estimation but provide no means of registering the local map to a global one, which can be important for inter-robot collaboration or human interaction. In this work, we present a real-time method for utilizing semantics to globally localize a robot using only egocentric 3D semantically labelled LiDAR and IMU as well as top-down RGB images obtained from satellites or aerial robots. Additionally, as it runs, our method builds a globally registered, semantic map of the environment. We validate our method on KITTI as well as our own challenging datasets, and show better than 10 meter accuracy, a high degree of robustness, and the ability to estimate the scale of a top-down map on the fly if it is initially unknown.
* Published in the IEEE Robotics and Automation Letters and presented at the IEEE 2021 International Conference on Robotics and Automation. See https://www.youtube.com/watch?v=_qwAoYK9iGU for accompanying video
DIAS: A Domain-Independent Alife-Based Problem-Solving System
Mar 14, 2022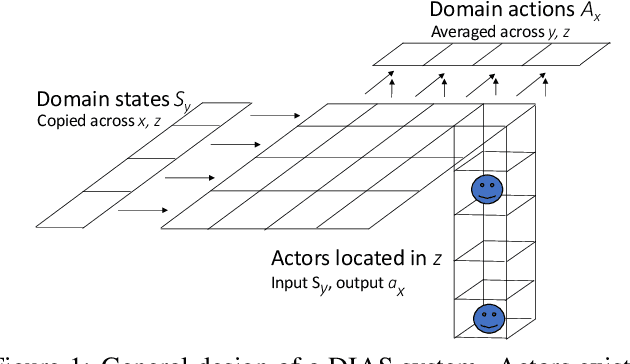
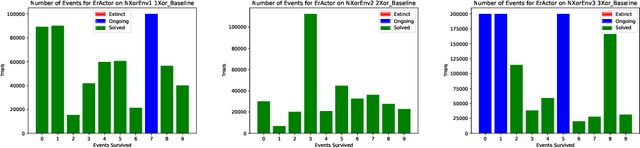


A domain-independent problem-solving system based on principles of Artificial Life is introduced. In this system, DIAS, the input and output dimensions of the domain are laid out in a spatial medium. A population of actors, each seeing only part of this medium, solves problems collectively in it. The process is independent of the domain and can be implemented through different kinds of actors. Through a set of experiments on various problem domains, DIAS is shown able to solve problems with different dimensionality and complexity, to require no hyperparameter tuning for new problems, and to exhibit lifelong learning, i.e. adapt rapidly to run-time changes in the problem domain, and do it better than a standard non-collective approach. DIAS therefore demonstrates a role for Alife in building scalable, general, and adaptive problem-solving systems.
Attacker Attribution of Audio Deepfakes
Mar 28, 2022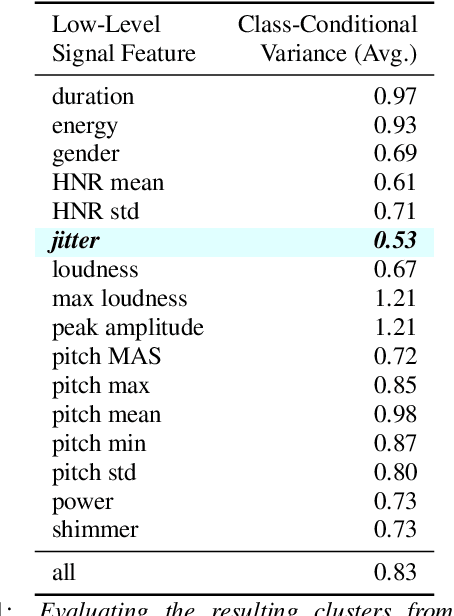
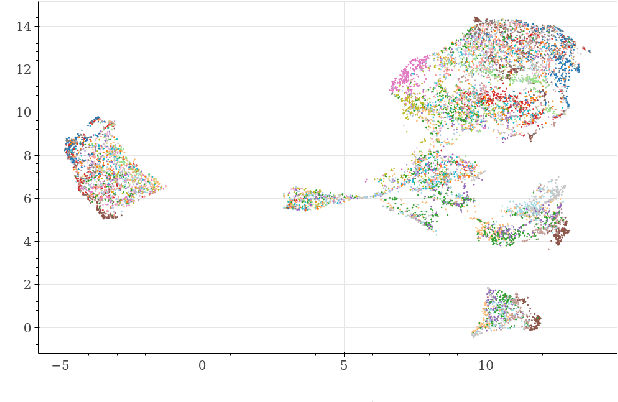
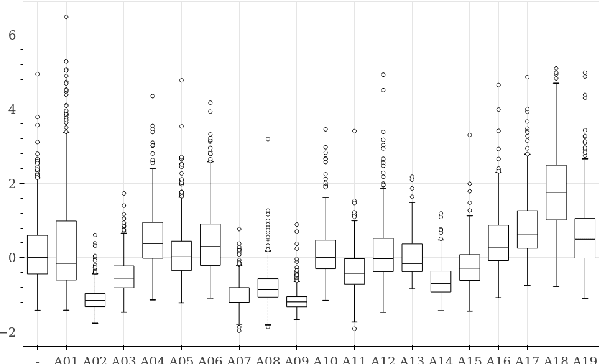
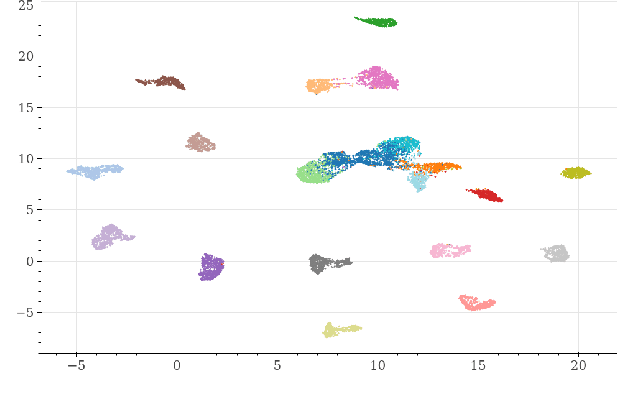
Deepfakes are synthetically generated media often devised with malicious intent. They have become increasingly more convincing with large training datasets advanced neural networks. These fakes are readily being misused for slander, misinformation and fraud. For this reason, intensive research for developing countermeasures is also expanding. However, recent work is almost exclusively limited to deepfake detection - predicting if audio is real or fake. This is despite the fact that attribution (who created which fake?) is an essential building block of a larger defense strategy, as practiced in the field of cybersecurity for a long time. This paper considers the problem of deepfake attacker attribution in the domain of audio. We present several methods for creating attacker signatures using low-level acoustic descriptors and machine learning embeddings. We show that speech signal features are inadequate for characterizing attacker signatures. However, we also demonstrate that embeddings from a recurrent neural network can successfully characterize attacks from both known and unknown attackers. Our attack signature embeddings result in distinct clusters, both for seen and unseen audio deepfakes. We show that these embeddings can be used in downstream-tasks to high-effect, scoring 97.10% accuracy in attacker-id classification.
Online No-regret Model-Based Meta RL for Personalized Navigation
Apr 05, 2022
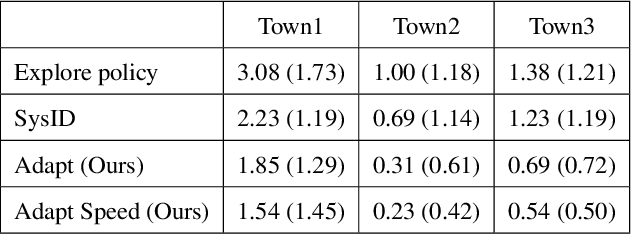
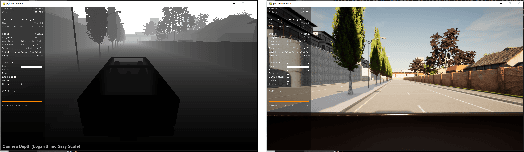
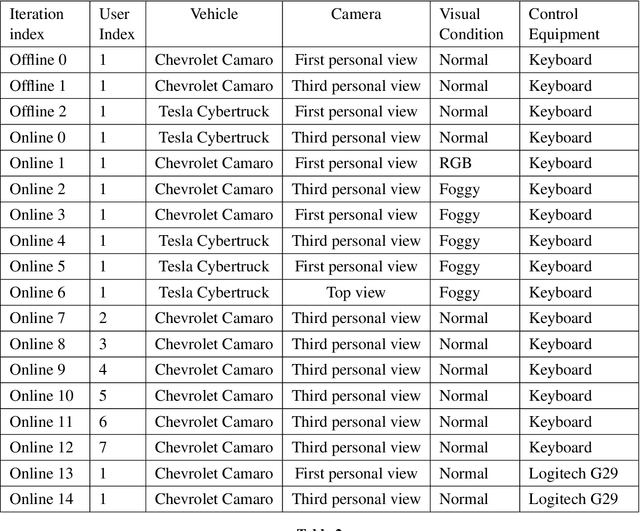
The interaction between a vehicle navigation system and the driver of the vehicle can be formulated as a model-based reinforcement learning problem, where the navigation systems (agent) must quickly adapt to the characteristics of the driver (environmental dynamics) to provide the best sequence of turn-by-turn driving instructions. Most modern day navigation systems (e.g, Google maps, Waze, Garmin) are not designed to personalize their low-level interactions for individual users across a wide range of driving styles (e.g., vehicle type, reaction time, level of expertise). Towards the development of personalized navigation systems that adapt to a variety of driving styles, we propose an online no-regret model-based RL method that quickly conforms to the dynamics of the current user. As the user interacts with it, the navigation system quickly builds a user-specific model, from which navigation commands are optimized using model predictive control. By personalizing the policy in this way, our method is able to give well-timed driving instructions that match the user's dynamics. Our theoretical analysis shows that our method is a no-regret algorithm and we provide the convergence rate in the agnostic setting. Our empirical analysis with 60+ hours of real-world user data using a driving simulator shows that our method can reduce the number of collisions by more than 60%.
3D-SiamRPN: An End-to-End Learning Method for Real-Time 3D Single Object Tracking Using Raw Point Cloud
Aug 12, 2021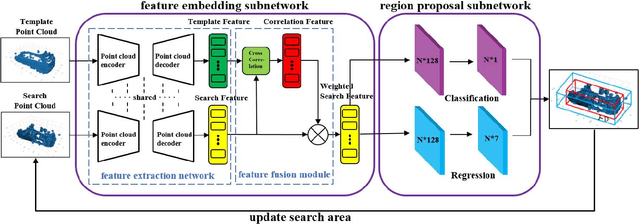


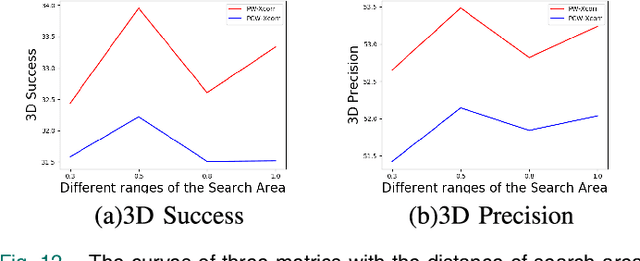
3D single object tracking is a key issue for autonomous following robot, where the robot should robustly track and accurately localize the target for efficient following. In this paper, we propose a 3D tracking method called 3D-SiamRPN Network to track a single target object by using raw 3D point cloud data. The proposed network consists of two subnetworks. The first subnetwork is feature embedding subnetwork which is used for point cloud feature extraction and fusion. In this subnetwork, we first use PointNet++ to extract features of point cloud from template and search branches. Then, to fuse the information of features in the two branches and obtain their similarity, we propose two cross correlation modules, named Pointcloud-wise and Point-wise respectively. The second subnetwork is region proposal network(RPN), which is used to get the final 3D bounding box of the target object based on the fusion feature from cross correlation modules. In this subnetwork, we utilize the regression and classification branches of a region proposal subnetwork to obtain proposals and scores, thus get the final 3D bounding box of the target object. Experimental results on KITTI dataset show that our method has a competitive performance in both Success and Precision compared to the state-of-the-art methods, and could run in real-time at 20.8 FPS. Additionally, experimental results on H3D dataset demonstrate that our method also has good generalization ability and could achieve good tracking performance in a new scene without re-training.