 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploiting temporal parallelism for LSTM Autoencoder acceleration on FPGA
Mar 14, 2026Recurrent Neural Networks (RNNs) are vital for sequential data processing. Long Short-Term Memory Autoencoders (LSTM-AEs) are particularly effective for unsupervised anomaly detection in time-series data. However, inherent sequential dependencies limit parallel computation. While previous work has explored FPGA-based acceleration for LSTM networks, efforts have typically focused on optimizing a single LSTM layer at a time. We introduce a novel FPGA-based accelerator using a dataflow architecture that exploits temporal parallelism for concurrent multi-layer processing of different timesteps within sequences. Experimental evaluations on four representative LSTM-AE models with varying widths and depths, implemented on a Zynq UltraScale+ MPSoC FPGA, demonstrate significant advantages over CPU (Intel Xeon Gold 5218R) and GPU (NVIDIA V100) implementations. Our accelerator achieves latency speedups up to 79.6x vs. CPU and 18.2x vs. GPU, alongside energy-per-timestep reductions of up to 1722x vs. CPU and 59.3x vs. GPU. These results, including superior network depth scalability, highlight our approach's potential for high-performance, real-time, power-efficient LSTM-AE-based anomaly detection on FPGAs.
Hybrid unary-binary design for multiplier-less printed Machine Learning classifiers
Sep 18, 2025Printed Electronics (PE) provide a flexible, cost-efficient alternative to silicon for implementing machine learning (ML) circuits, but their large feature sizes limit classifier complexity. Leveraging PE's low fabrication and NRE costs, designers can tailor hardware to specific ML models, simplifying circuit design. This work explores alternative arithmetic and proposes a hybrid unary-binary architecture that removes costly encoders and enables efficient, multiplier-less execution of MLP classifiers. We also introduce architecture-aware training to further improve area and power efficiency. Evaluation on six datasets shows average reductions of 46% in area and 39% in power, with minimal accuracy loss, surpassing other state-of-the-art MLP designs.
MaRVIn: A Cross-Layer Mixed-Precision RISC-V Framework for DNN Inference, from ISA Extension to Hardware Acceleration
Sep 18, 2025The evolution of quantization and mixed-precision techniques has unlocked new possibilities for enhancing the speed and energy efficiency of NNs. Several recent studies indicate that adapting precision levels across different parameters can maintain accuracy comparable to full-precision models while significantly reducing computational demands. However, existing embedded microprocessors lack sufficient architectural support for efficiently executing mixed-precision NNs, both in terms of ISA extensions and hardware design, resulting in inefficiencies such as excessive data packing/unpacking and underutilized arithmetic units. In this work, we propose novel ISA extensions and a micro-architecture implementation specifically designed to optimize mixed-precision execution, enabling energy-efficient deep learning inference on RISC-V architectures. We introduce MaRVIn, a cross-layer hardware-software co-design framework that enhances power efficiency and performance through a combination of hardware improvements, mixed-precision quantization, ISA-level optimizations, and cycle-accurate emulation. At the hardware level, we enhance the ALU with configurable mixed-precision arithmetic (2, 4, 8 bits) for weights/activations and employ multi-pumping to reduce execution latency while implementing soft SIMD for efficient 2-bit ops. At the software level, we integrate a pruning-aware fine-tuning method to optimize model compression and a greedy-based DSE approach to efficiently search for Pareto-optimal mixed-quantized models. Additionally, we incorporate voltage scaling to boost the power efficiency of our system. Our experimental evaluation over widely used DNNs and datasets, such as CIFAR10 and ImageNet, demonstrates that our framework can achieve, on average, 17.6x speedup for less than 1% accuracy loss and outperforms the ISA-agnostic state-of-the-art RISC-V cores, delivering up to 1.8 TOPs/W.
MAx-DNN: Multi-Level Arithmetic Approximation for Energy-Efficient DNN Hardware Accelerators
Jun 26, 2025Nowadays, the rapid growth of Deep Neural Network (DNN) architectures has established them as the defacto approach for providing advanced Machine Learning tasks with excellent accuracy. Targeting low-power DNN computing, this paper examines the interplay of fine-grained error resilience of DNN workloads in collaboration with hardware approximation techniques, to achieve higher levels of energy efficiency. Utilizing the state-of-the-art ROUP approximate multipliers, we systematically explore their fine-grained distribution across the network according to our layer-, filter-, and kernel-level approaches, and examine their impact on accuracy and energy. We use the ResNet-8 model on the CIFAR-10 dataset to evaluate our approximations. The proposed solution delivers up to 54% energy gains in exchange for up to 4% accuracy loss, compared to the baseline quantized model, while it provides 2x energy gains with better accuracy versus the state-of-the-art DNN approximations.
* Presented at the 13th IEEE LASCAS Conference
Futureproof Static Memory Planning
Apr 07, 2025



The NP-complete combinatorial optimization task of assigning offsets to a set of buffers with known sizes and lifetimes so as to minimize total memory usage is called dynamic storage allocation (DSA). Existing DSA implementations bypass the theoretical state-of-the-art algorithms in favor of either fast but wasteful heuristics, or memory-efficient approaches that do not scale beyond one thousand buffers. The "AI memory wall", combined with deep neural networks' static architecture, has reignited interest in DSA. We present idealloc, a low-fragmentation, high-performance DSA implementation designed for million-buffer instances. Evaluated on a novel suite of particularly hard benchmarks from several domains, idealloc ranks first against four production implementations in terms of a joint effectiveness/robustness criterion.
Accelerating TinyML Inference on Microcontrollers through Approximate Kernels
Sep 25, 2024



The rapid growth of microcontroller-based IoT devices has opened up numerous applications, from smart manufacturing to personalized healthcare. Despite the widespread adoption of energy-efficient microcontroller units (MCUs) in the Tiny Machine Learning (TinyML) domain, they still face significant limitations in terms of performance and memory (RAM, Flash). In this work, we combine approximate computing and software kernel design to accelerate the inference of approximate CNN models on MCUs. Our kernel-based approximation framework firstly unpacks the operands of each convolution layer and then conducts an offline calculation to determine the significance of each operand. Subsequently, through a design space exploration, it employs a computation skipping approximation strategy based on the calculated significance. Our evaluation on an STM32-Nucleo board and 2 popular CNNs trained on the CIFAR-10 dataset shows that, compared to state-of-the-art exact inference, our Pareto optimal solutions can feature on average 21% latency reduction with no degradation in Top-1 classification accuracy, while for lower accuracy requirements, the corresponding reduction becomes even more pronounced.
SLO-aware GPU Frequency Scaling for Energy Efficient LLM Inference Serving
Aug 05, 2024



As Large Language Models (LLMs) gain traction, their reliance on power-hungry GPUs places ever-increasing energy demands, raising environmental and monetary concerns. Inference dominates LLM workloads, presenting a critical challenge for providers: minimizing energy costs under Service-Level Objectives (SLOs) that ensure optimal user experience. In this paper, we present \textit{throttLL'eM}, a framework that reduces energy consumption while meeting SLOs through the use of instance and GPU frequency scaling. \textit{throttLL'eM} features mechanisms that project future KV cache usage and batch size. Leveraging a Machine-Learning (ML) model that receives these projections as inputs, \textit{throttLL'eM} manages performance at the iteration level to satisfy SLOs with reduced frequencies and instance sizes. We show that the proposed ML model achieves $R^2$ scores greater than 0.97 and miss-predicts performance by less than 1 iteration per second on average. Experimental results on LLM inference traces show that \textit{throttLL'eM} achieves up to 43.8\% lower energy consumption and an energy efficiency improvement of at least $1.71\times$ under SLOs, when compared to NVIDIA's Triton server.
Mixed-precision Neural Networks on RISC-V Cores: ISA extensions for Multi-Pumped Soft SIMD Operations
Jul 19, 2024



Recent advancements in quantization and mixed-precision approaches offers substantial opportunities to improve the speed and energy efficiency of Neural Networks (NN). Research has shown that individual parameters with varying low precision, can attain accuracies comparable to full-precision counterparts. However, modern embedded microprocessors provide very limited support for mixed-precision NNs regarding both Instruction Set Architecture (ISA) extensions and their hardware design for efficient execution of mixed-precision operations, i.e., introducing several performance bottlenecks due to numerous instructions for data packing and unpacking, arithmetic unit under-utilizations etc. In this work, we bring together, for the first time, ISA extensions tailored to mixed-precision hardware optimizations, targeting energy-efficient DNN inference on leading RISC-V CPU architectures. To this end, we introduce a hardware-software co-design framework that enables cooperative hardware design, mixed-precision quantization, ISA extensions and inference in cycle-accurate emulations. At hardware level, we firstly expand the ALU unit within our proof-of-concept micro-architecture to support configurable fine grained mixed-precision arithmetic operations. Subsequently, we implement multi-pumping to minimize execution latency, with an additional soft SIMD optimization applied for 2-bit operations. At the ISA level, three distinct MAC instructions are encoded extending the RISC-V ISA, and exposed up to the compiler level, each corresponding to a different mixed-precision operational mode. Our extensive experimental evaluation over widely used DNNs and datasets, such as CIFAR10 and ImageNet, demonstrates that our framework can achieve, on average, 15x energy reduction for less than 1% accuracy loss and outperforms the ISA-agnostic state-of-the-art RISC-V cores.
Evaluation of Resource-Efficient Crater Detectors on Embedded Systems
May 27, 2024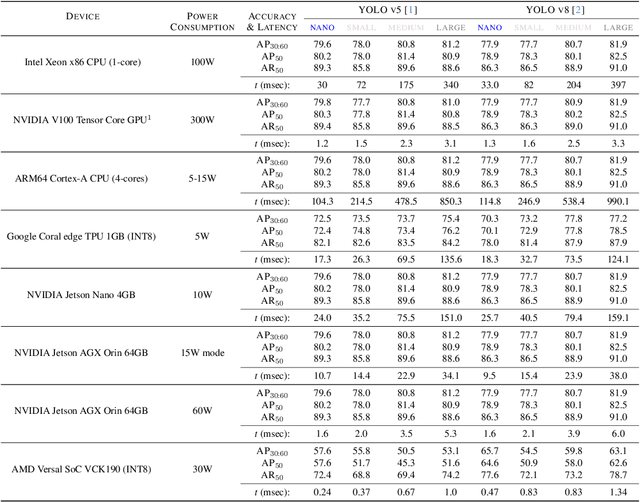
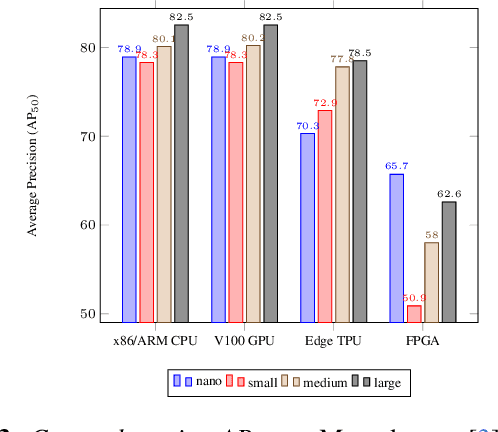
Real-time analysis of Martian craters is crucial for mission-critical operations, including safe landings and geological exploration. This work leverages the latest breakthroughs for on-the-edge crater detection aboard spacecraft. We rigorously benchmark several YOLO networks using a Mars craters dataset, analyzing their performance on embedded systems with a focus on optimization for low-power devices. We optimize this process for a new wave of cost-effective, commercial-off-the-shelf-based smaller satellites. Implementations on diverse platforms, including Google Coral Edge TPU, AMD Versal SoC VCK190, Nvidia Jetson Nano and Jetson AGX Orin, undergo a detailed trade-off analysis. Our findings identify optimal network-device pairings, enhancing the feasibility of crater detection on resource-constrained hardware and setting a new precedent for efficient and resilient extraterrestrial imaging. Code at: https://github.com/billpsomas/mars_crater_detection.
TF2AIF: Facilitating development and deployment of accelerated AI models on the cloud-edge continuum
Apr 21, 2024The B5G/6G evolution relies on connect-compute technologies and highly heterogeneous clusters with HW accelerators, which require specialized coding to be efficiently utilized. The current paper proposes a custom tool for generating multiple SW versions of a certain AI function input in high-level language, e.g., Python TensorFlow, while targeting multiple diverse HW+SW platforms. TF2AIF builds upon disparate tool-flows to create a plethora of relative containers and enable the system orchestrator to deploy the requested function on any peculiar node in the cloud-edge continuum, i.e., to leverage the performance/energy benefits of the underlying HW upon any circumstances. TF2AIF fills an identified gap in today's ecosystem and facilitates research on resource management or automated operations, by demanding minimal time or expertise from users.