 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Dys-XAI: Influence-Based Explanations for Dysarthria Severity Assessment
Jun 19, 2026Dysarthria severity assessment is essential for therapy planning and longitudinal monitoring, yet manual perceptual rating is time-consuming and variable across clinicians. Although deep learning models achieve strong performance, their black-box nature limits clinical adoption. Existing speech explainability methods typically provide acoustic feature importance scores that are difficult for end-users to interpret. We propose an influence-based, instance-level explainability framework that explains each decision through supportive and competing training samples. Using gradient-based influence approximations, we compute per-utterance influence scores to identify supportive and competing training samples for each prediction. Controlled deletion experiments from 5 to 20 percent validate the explanations, showing that removing highly influential samples systematically shifts predictions. This approach provides auditable explanations by linking decisions to perceptible reference cases.
LISE : Listenable Interpretable Speaker Embeddings
Jun 19, 2026Deep neural network-based automatic speaker verification (ASV) systems achieve impressive performance but their embedding representations remain opaque, lacking a structured and perceptually verifiable explanation of the vocal characteristics they encode. Existing approaches either require annotation of speaker attributes or introduce alternative representations whose interpretability is unvalidated with listeners. We propose Listenable Interpretable Speaker Embeddings (LISE), a label-free framework that decomposes pretrained speaker embeddings into a small set of components. This decomposition yields a structured representation that supports the analysis of what information has been encoded by speaker embeddings. LISE preserves ASV performance with negligible EER degradation on x-vector and ECAPA-TDNN. Crucially, the interpretability of these components for human listeners is demonstrated through listening experiments, where participants distinguished speakers with 83.9% accuracy.
Disentangling Speaker Traits for Deepfake Source Verification via Chebyshev Polynomial and Riemannian Metric Learning
Mar 23, 2026Speech deepfake source verification systems aims to determine whether two synthetic speech utterances originate from the same source generator, often assuming that the resulting source embeddings are independent of speaker traits. However, this assumption remains unverified. In this paper, we first investigate the impact of speaker factors on source verification. We propose a speaker-disentangled metric learning (SDML) framework incorporating two novel loss functions. The first leverages Chebyshev polynomial to mitigate gradient instability during disentanglement optimization. The second projects source and speaker embeddings into hyperbolic space, leveraging Riemannian metric distances to reduce speaker information and learn more discriminative source features. Experimental results on MLAAD benchmark, evaluated under four newly proposed protocols designed for source-speaker disentanglement scenarios, demonstrate the effectiveness of SDML framework. The code, evaluation protocols and demo website are available at https://github.com/xxuan-acoustics/RiemannSD-Net.
A New Approach to Voice Authenticity
Feb 09, 2024

Voice faking, driven primarily by recent advances in text-to-speech (TTS) synthesis technology, poses significant societal challenges. Currently, the prevailing assumption is that unaltered human speech can be considered genuine, while fake speech comes from TTS synthesis. We argue that this binary distinction is oversimplified. For instance, altered playback speeds can be used for malicious purposes, like in the 'Drunken Nancy Pelosi' incident. Similarly, editing of audio clips can be done ethically, e.g., for brevity or summarization in news reporting or podcasts, but editing can also create misleading narratives. In this paper, we propose a conceptual shift away from the binary paradigm of audio being either 'fake' or 'real'. Instead, our focus is on pinpointing 'voice edits', which encompass traditional modifications like filters and cuts, as well as TTS synthesis and VC systems. We delineate 6 categories and curate a new challenge dataset rooted in the M-AILABS corpus, for which we present baseline detection systems. And most importantly, we argue that merely categorizing audio as fake or real is a dangerous over-simplification that will fail to move the field of speech technology forward.
Exploratory Evaluation of Speech Content Masking
Jan 08, 2024Most recent speech privacy efforts have focused on anonymizing acoustic speaker attributes but there has not been as much research into protecting information from speech content. We introduce a toy problem that explores an emerging type of privacy called "content masking" which conceals selected words and phrases in speech. In our efforts to define this problem space, we evaluate an introductory baseline masking technique based on modifying sequences of discrete phone representations (phone codes) produced from a pre-trained vector-quantized variational autoencoder (VQ-VAE) and re-synthesized using WaveRNN. We investigate three different masking locations and three types of masking strategies: noise substitution, word deletion, and phone sequence reversal. Our work attempts to characterize how masking affects two downstream tasks: automatic speech recognition (ASR) and automatic speaker verification (ASV). We observe how the different masks types and locations impact these downstream tasks and discuss how these issues may influence privacy goals.
Protecting Publicly Available Data With Machine Learning Shortcuts
Oct 30, 2023Machine-learning (ML) shortcuts or spurious correlations are artifacts in datasets that lead to very good training and test performance but severely limit the model's generalization capability. Such shortcuts are insidious because they go unnoticed due to good in-domain test performance. In this paper, we explore the influence of different shortcuts and show that even simple shortcuts are difficult to detect by explainable AI methods. We then exploit this fact and design an approach to defend online databases against crawlers: providers such as dating platforms, clothing manufacturers, or used car dealers have to deal with a professionalized crawling industry that grabs and resells data points on a large scale. We show that a deterrent can be created by deliberately adding ML shortcuts. Such augmented datasets are then unusable for ML use cases, which deters crawlers and the unauthorized use of data from the internet. Using real-world data from three use cases, we show that the proposed approach renders such collected data unusable, while the shortcut is at the same time difficult to notice in human perception. Thus, our proposed approach can serve as a proactive protection against illegitimate data crawling.
New Challenges for Content Privacy in Speech and Audio
Jan 21, 2023Privacy in speech and audio has many facets. A particularly under-developed area of privacy in this domain involves consideration for information related to content and context. Speech content can include words and their meaning or even stylistic markers, pathological speech, intonation patterns, or emotion. More generally, audio captured in-the-wild may contain background speech or reveal contextual information such as markers of location, room characteristics, paralinguistic sounds, or other audible events. Audio recording devices and speech technologies are becoming increasingly commonplace in everyday life. At the same time, commercialised speech and audio technologies do not provide consumers with a range of privacy choices. Even where privacy is regulated or protected by law, technical solutions to privacy assurance and enforcement fall short. This position paper introduces three important and timely research challenges for content privacy in speech and audio. We highlight current gaps and opportunities, and identify focus areas, that could have significant implications for developing ethical and safer speech technologies.
Shortcut Removal for Improved OOD-Generalization
Nov 24, 2022



Machine learning is a data-driven discipline, and learning success is largely dependent on the quality of the underlying data sets. However, it is becoming increasingly clear that even high performance on held-out test data does not necessarily mean that a model generalizes or learns anything meaningful at all. One reason for this is the presence of machine learning shortcuts, i.e., hints in the data that are predictive but accidental and semantically unconnected to the problem. We present a new approach to detect such shortcuts and a technique to automatically remove them from datasets. Using an adversarially trained lens, any small and highly predictive clues in images can be detected and removed. We show that this approach 1) does not cause degradation of model performance in the absence of these shortcuts, and 2) reliably identifies and neutralizes shortcuts from different image datasets. In our experiments, we are able to recover up to 93,8% of model performance in the presence of different shortcuts. Finally, we apply our model to a real-world dataset from the medical domain consisting of chest x-rays and identify and remove several types of shortcuts that are known to hinder real-world applicability. Thus, we hope that our proposed approach fosters real-world applicability of machine learning.
Analysis of Voice Conversion and Code-Switching Synthesis Using VQ-VAE
Mar 28, 2022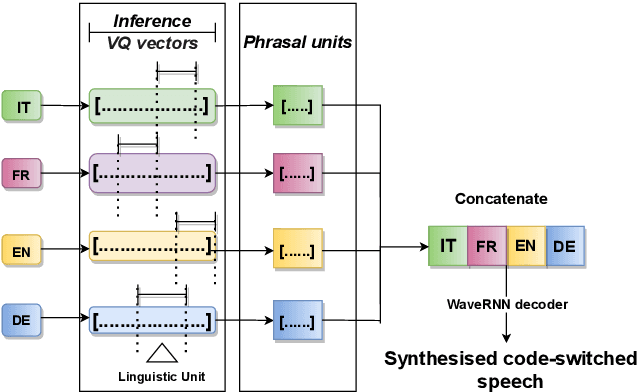
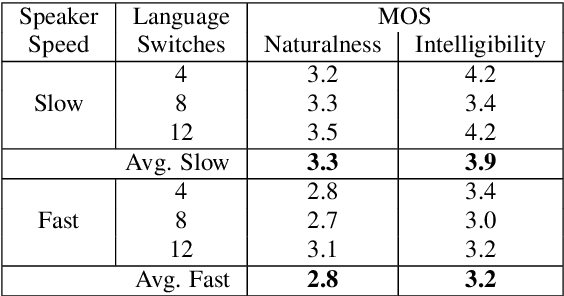
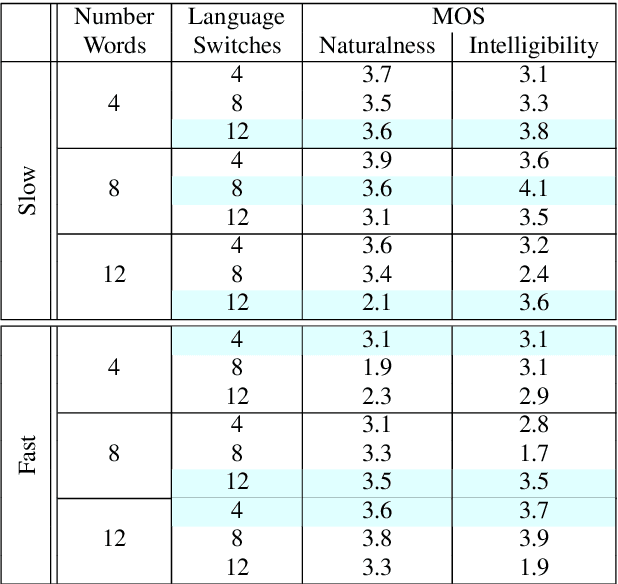
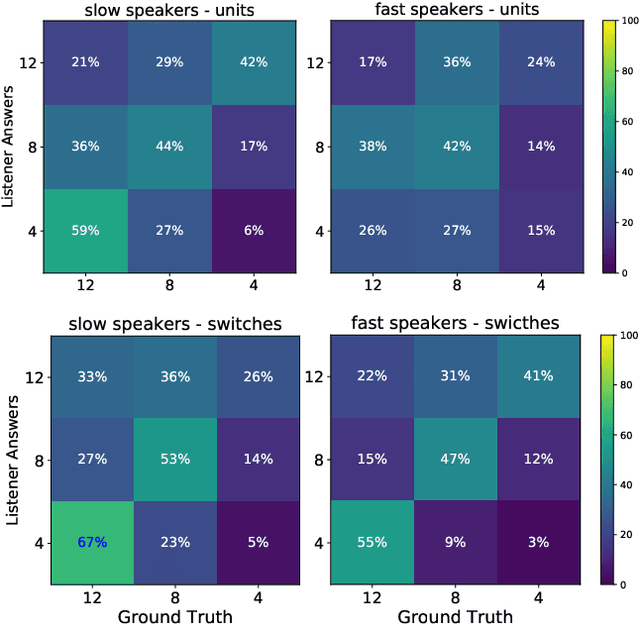
This paper presents an analysis of speech synthesis quality achieved by simultaneously performing voice conversion and language code-switching using multilingual VQ-VAE speech synthesis in German, French, English and Italian. In this paper, we utilize VQ code indices representing phone information from VQ-VAE to perform code-switching and a VQ speaker code to perform voice conversion in a single system with a neural vocoder. Our analysis examines several aspects of code-switching including the number of language switches and the number of words involved in each switch. We found that speech synthesis quality degrades after increasing the number of language switches within an utterance and decreasing the number of words. We also found some evidence of accent transfer when performing voice conversion across languages as observed when a speaker's original language differs from the language of a synthetic target utterance. We present results from our listening tests and discuss the inherent difficulties of assessing accent transfer in speech synthesis. Our work highlights some of the limitations and strengths of using a semi-supervised end-to-end system like VQ-VAE for handling multilingual synthesis. Our work provides insight into why multilingual speech synthesis is challenging and we suggest some directions for expanding work in this area.
Attacker Attribution of Audio Deepfakes
Mar 28, 2022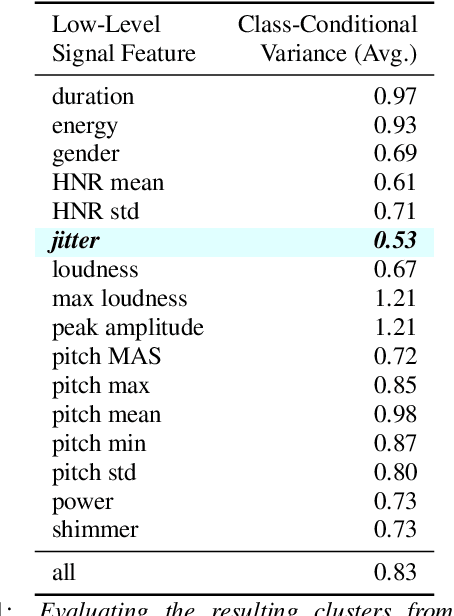
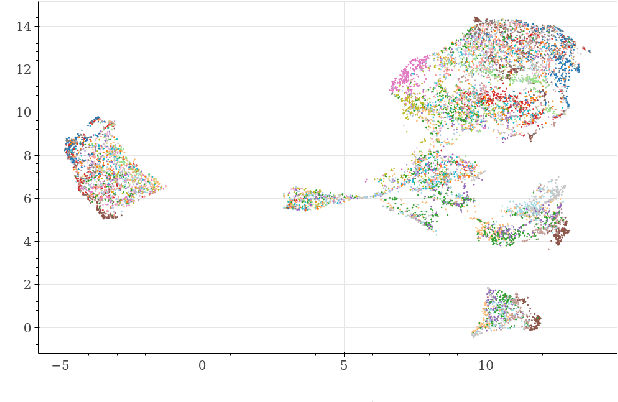
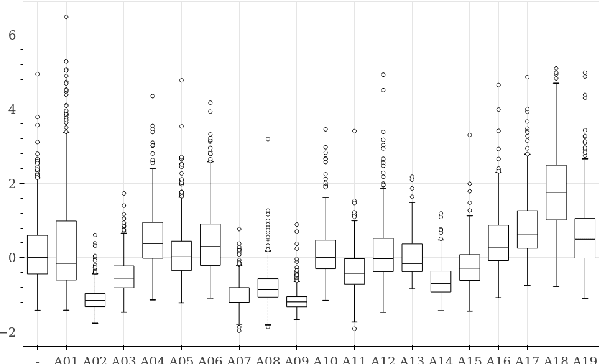
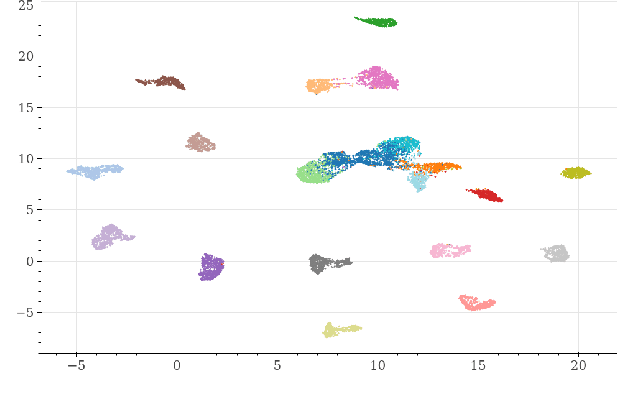
Deepfakes are synthetically generated media often devised with malicious intent. They have become increasingly more convincing with large training datasets advanced neural networks. These fakes are readily being misused for slander, misinformation and fraud. For this reason, intensive research for developing countermeasures is also expanding. However, recent work is almost exclusively limited to deepfake detection - predicting if audio is real or fake. This is despite the fact that attribution (who created which fake?) is an essential building block of a larger defense strategy, as practiced in the field of cybersecurity for a long time. This paper considers the problem of deepfake attacker attribution in the domain of audio. We present several methods for creating attacker signatures using low-level acoustic descriptors and machine learning embeddings. We show that speech signal features are inadequate for characterizing attacker signatures. However, we also demonstrate that embeddings from a recurrent neural network can successfully characterize attacks from both known and unknown attackers. Our attack signature embeddings result in distinct clusters, both for seen and unseen audio deepfakes. We show that these embeddings can be used in downstream-tasks to high-effect, scoring 97.10% accuracy in attacker-id classification.