 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDesign Rules for Extreme-Edge Scientific Computing on AI Engines
Apr 21, 2026Extreme-edge scientific applications use machine learning models to analyze sensor data and make real-time decisions. Their stringent latency and throughput requirements demand small batch sizes and require that model weights remain fully on-chip. Spatial dataflow implementations are common for extreme-edge applications. Spatial dataflow works well for small networks, but it fails to scale to larger models due to inherent resource scaling limitations. AI Engines on modern FPGA SoCs offer a promising alternative with high compute density and additional on-chip memory. However, the architecture, programming model, and performance-scaling behavior of AI Engines differ fundamentally from those of the programmable logic, making direct comparison non-trivial and the benefits of using AI Engines unclear. This work addresses how and when extreme-edge scientific neural networks should be implemented on AI Engines versus programmable logic. We provide systematic architectural characterization and micro-benchmarking and introduce a latency-adjusted resource equivalence (LARE) metric that identifies when AI Engine implementations outperform programmable logic designs. We further propose spatial and API-level dataflow optimizations tailored to low-latency scientific inference. Finally, we demonstrate the successful deployment of end-to-end neural networks on AI Engines that cannot fit on programmable logic when using the hlsml toolchain.
Taming the Exponential: A Fast Softmax Surrogate for Integer-Native Edge Inference
Apr 02, 2026Softmax can become a computational bottleneck in the Transformer model's Multi-Head Attention (MHA) block, particularly in small models under low-precision inference, where exponentiation and normalization incur significant overhead. As such, we suggest using Head-Calibrated Clipped-Linear Softmax (HCCS), a bounded, monotone surrogate to the exponential softmax function, which uses a clipped linear mapping of the max centered attention logits. This approximation produces a stable probability distribution, maintains the ordering of the original logits and has non-negative values. HCCS differs from previous softmax surrogates as it includes a set of lightweight calibration parameters that are optimized offline based on a representative dataset and calibrated for each individual attention head to preserve the statistical properties of the individual heads. We describe a hardware-motivated implementation of HCCS for high-throughput scenarios targeting the AMD Versal AI Engines. The current reference implementations from AMD for this platform rely upon either bfloat16 arithmetic or LUTs to perform the exponential operation, which might limit the throughput of the platform and fail to utilize the high-throughput integer vector processing units of the AI Engine. In contrast, HCCS provides a natural mapping to the AI Engines' int8 multiply accumulate (MAC) units. To the best of our knowledge, this is the first int8 optimized softmax surrogate for AMD AI engines that significantly exceeds the speed performance of other reference implementations while maintaining competitive task accuracy on small or heavily quantized MHA workloads after quantization-aware retraining.
PQuantML: A Tool for End-to-End Hardware-aware Model Compression
Mar 27, 2026PQuantML is a new open-source, hardware-aware neural network model compression library tailored to end-to-end workflows. Motivated by the need to deploy performant models to environments with strict latency constraints, PQuantML simplifies training of compressed models by providing a unified interface to apply pruning and quantization, either jointly or individually. The library implements multiple pruning methods with different granularities, as well as fixed-point quantization with support for High-Granularity Quantization. We evaluate PQuantML on representative tasks such as the jet substructure classification, so-called jet tagging, an on-edge problem related to real-time LHC data processing. Using various pruning methods with fixed-point quantization, PQuantML achieves substantial parameter and bit-width reductions while maintaining accuracy. The resulting compression is further compared against existing tools, such as QKeras and HGQ.
AIE4ML: An End-to-End Framework for Compiling Neural Networks for the Next Generation of AMD AI Engines
Dec 17, 2025



Efficient AI inference on AMD's Versal AI Engine (AIE) is challenging due to tightly coupled VLIW execution, explicit datapaths, and local memory management. Prior work focused on first-generation AIE kernel optimizations, without tackling full neural network execution across the 2D array. In this work, we present AIE4ML, the first comprehensive framework for converting AI models automatically into optimized firmware targeting the AIE-ML generation devices, also with forward compatibility for the newer AIE-MLv2 architecture. At the single-kernel level, we attain performance close to the architectural peak. At the graph and system levels, we provide a structured parallelization method that can scale across the 2D AIE-ML fabric and exploit its dedicated memory tiles to stay entirely on-chip throughout the model execution. As a demonstration, we designed a generalized and highly efficient linear-layer implementation with intrinsic support for fused bias addition and ReLU activation. Also, as our framework necessitates the generation of multi-layer implementations, our approach systematically derives deterministic, compact, and topology-optimized placements tailored to the physical 2D grid of the device through a novel graph placement and search algorithm. Finally, the framework seamlessly accepts quantized models imported from high-level tools such as hls4ml or PyTorch while preserving bit-exactness. In layer scaling benchmarks, we achieve up to 98.6% efficiency relative to the single-kernel baseline, utilizing 296 of 304 AIE tiles (97.4%) of the device with entirely on-chip data movement. With evaluations across real-world model topologies, we demonstrate that AIE4ML delivers GPU-class throughput under microsecond latency constraints, making it a practical companion for ultra-low-latency environments such as trigger systems in particle physics experiments.
Evaluation of Resource-Efficient Crater Detectors on Embedded Systems
May 27, 2024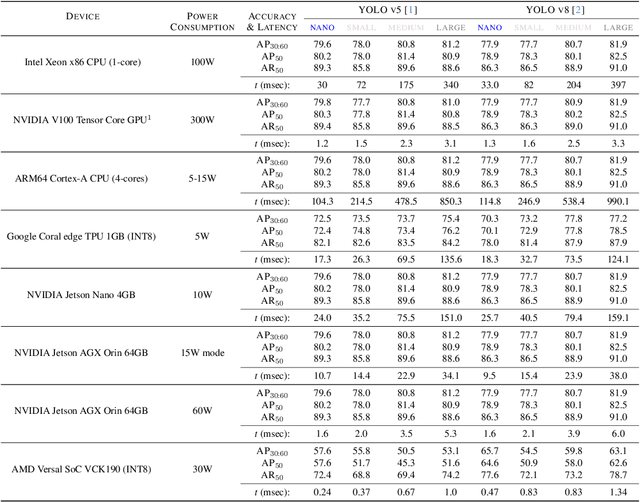
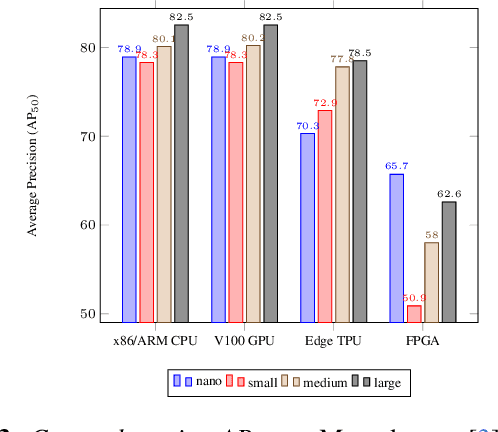
Real-time analysis of Martian craters is crucial for mission-critical operations, including safe landings and geological exploration. This work leverages the latest breakthroughs for on-the-edge crater detection aboard spacecraft. We rigorously benchmark several YOLO networks using a Mars craters dataset, analyzing their performance on embedded systems with a focus on optimization for low-power devices. We optimize this process for a new wave of cost-effective, commercial-off-the-shelf-based smaller satellites. Implementations on diverse platforms, including Google Coral Edge TPU, AMD Versal SoC VCK190, Nvidia Jetson Nano and Jetson AGX Orin, undergo a detailed trade-off analysis. Our findings identify optimal network-device pairings, enhancing the feasibility of crater detection on resource-constrained hardware and setting a new precedent for efficient and resilient extraterrestrial imaging. Code at: https://github.com/billpsomas/mars_crater_detection.
TransAxx: Efficient Transformers with Approximate Computing
Feb 12, 2024Vision Transformer (ViT) models which were recently introduced by the transformer architecture have shown to be very competitive and often become a popular alternative to Convolutional Neural Networks (CNNs). However, the high computational requirements of these models limit their practical applicability especially on low-power devices. Current state-of-the-art employs approximate multipliers to address the highly increased compute demands of DNN accelerators but no prior research has explored their use on ViT models. In this work we propose TransAxx, a framework based on the popular PyTorch library that enables fast inherent support for approximate arithmetic to seamlessly evaluate the impact of approximate computing on DNNs such as ViT models. Using TransAxx we analyze the sensitivity of transformer models on the ImageNet dataset to approximate multiplications and perform approximate-aware finetuning to regain accuracy. Furthermore, we propose a methodology to generate approximate accelerators for ViT models. Our approach uses a Monte Carlo Tree Search (MCTS) algorithm to efficiently search the space of possible configurations using a hardware-driven hand-crafted policy. Our evaluation demonstrates the efficacy of our methodology in achieving significant trade-offs between accuracy and power, resulting in substantial gains without compromising on performance.
AdaPT: Fast Emulation of Approximate DNN Accelerators in PyTorch
Mar 08, 2022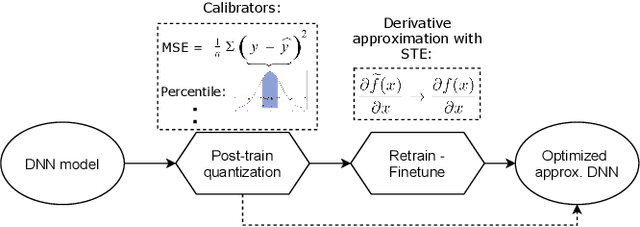
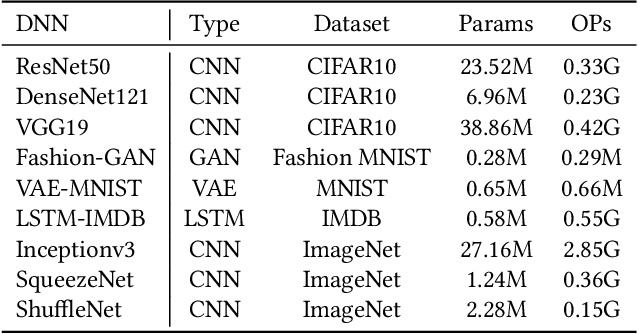
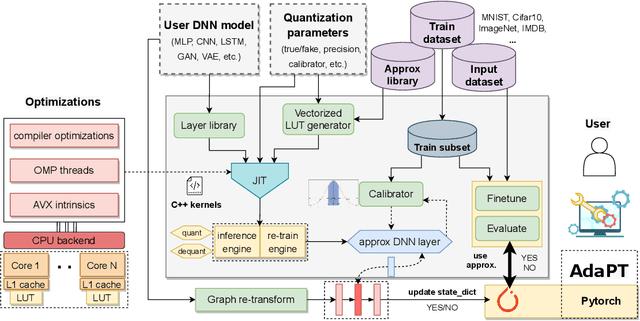
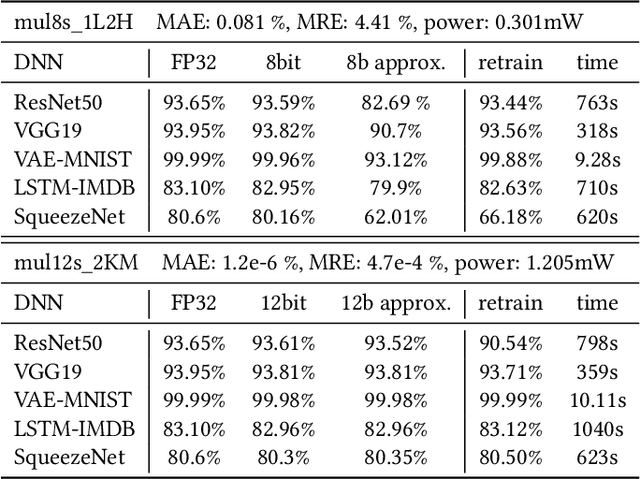
Current state-of-the-art employs approximate multipliers to address the highly increased power demands of DNN accelerators. However, evaluating the accuracy of approximate DNNs is cumbersome due to the lack of adequate support for approximate arithmetic in DNN frameworks. We address this inefficiency by presenting AdaPT, a fast emulation framework that extends PyTorch to support approximate inference as well as approximation-aware retraining. AdaPT can be seamlessly deployed and is compatible with the most DNNs. We evaluate the framework on several DNN models and application fields including CNNs, LSTMs, and GANs for a number of approximate multipliers with distinct bitwidth values. The results show substantial error recovery from approximate re-training and reduced inference time up to 53.9x with respect to the baseline approximate implementation.