 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Not All Experts are Equal: Efficient Expert Pruning and Skipping for Mixture-of-Experts Large Language Models
Feb 22, 2024
A pivotal advancement in the progress of large language models (LLMs) is the emergence of the Mixture-of-Experts (MoE) LLMs. Compared to traditional LLMs, MoE LLMs can achieve higher performance with fewer parameters, but it is still hard to deploy them due to their immense parameter sizes. Different from previous weight pruning methods that rely on specifically designed hardware, this paper mainly aims to enhance the deployment efficiency of MoE LLMs by introducing plug-and-play expert-level sparsification techniques. Specifically, we propose, for the first time to our best knowledge, post-training approaches for task-agnostic and task-specific expert pruning and skipping of MoE LLMs, tailored to improve deployment efficiency while maintaining model performance across a wide range of tasks. Extensive experiments show that our proposed methods can simultaneously reduce model sizes and increase the inference speed, while maintaining satisfactory performance. Data and code will be available at https://github.com/Lucky-Lance/Expert_Sparsity.
Fast and Efficient Sequential Radar Parameter Estimation in MIMO-OTFS Systems
Feb 22, 2024We consider the estimation of three-dimensional (3D) radar parameters, namely, bearing or angle-of-arrival (AoA), delay or range, and Doppler shift velocity, under a mono-static multiple-input multiple-output (MIMO) joint communications and radar (JCR) system based on Orthogonal Time Frequency Space (OTFS) signals. In particular, we propose a novel two-step algorithm to estimate the three radar parameters sequentially, where the AoA is obtained first, followed by the estimation of range and velocity via a reduced two-dimensional (2D) grid maximum likelihood (ML) search in the delay-Doppler (DD) domain. Besides the resulting lower complexity, the decoupling of AoA and DD estimation enables the incorporation of an linear minimum mean square error (LMMSE) procedure in the ML estimation of range and velocity, which are found to significantly outperform State-of-the-Art (SotA) alternatives and approach the fundamental limits of the Cram`er-Rao lower bound (CRLB) and search grid resolution.
Data Augmentation is Dead, Long Live Data Augmentation
Feb 22, 2024Textual data augmentation (DA) is a prolific field of study where novel techniques to create artificial data are regularly proposed, and that has demonstrated great efficiency on small data settings, at least for text classification tasks. In this paper, we challenge those results, showing that classical data augmentation is simply a way of performing better fine-tuning, and that spending more time fine-tuning before applying data augmentation negates its effect. This is a significant contribution as it answers several questions that were left open in recent years, namely~: which DA technique performs best (all of them as long as they generate data close enough to the training set as to not impair training) and why did DA show positive results (facilitates training of network). We furthermore show that zero and few-shot data generation via conversational agents such as ChatGPT or LLama2 can increase performances, concluding that this form of data augmentation does still work, even if classical methods do not.
A Conversational Brain-Artificial Intelligence Interface
Feb 22, 2024We introduce Brain-Artificial Intelligence Interfaces (BAIs) as a new class of Brain-Computer Interfaces (BCIs). Unlike conventional BCIs, which rely on intact cognitive capabilities, BAIs leverage the power of artificial intelligence to replace parts of the neuro-cognitive processing pipeline. BAIs allow users to accomplish complex tasks by providing high-level intentions, while a pre-trained AI agent determines low-level details. This approach enlarges the target audience of BCIs to individuals with cognitive impairments, a population often excluded from the benefits of conventional BCIs. We present the general concept of BAIs and illustrate the potential of this new approach with a Conversational BAI based on EEG. In particular, we show in an experiment with simulated phone conversations that the Conversational BAI enables complex communication without the need to generate language. Our work thus demonstrates, for the first time, the ability of a speech neuroprosthesis to enable fluent communication in realistic scenarios with non-invasive technologies.
Efficient and Guaranteed-Safe Non-Convex Trajectory Optimization with Constrained Diffusion Model
Feb 22, 2024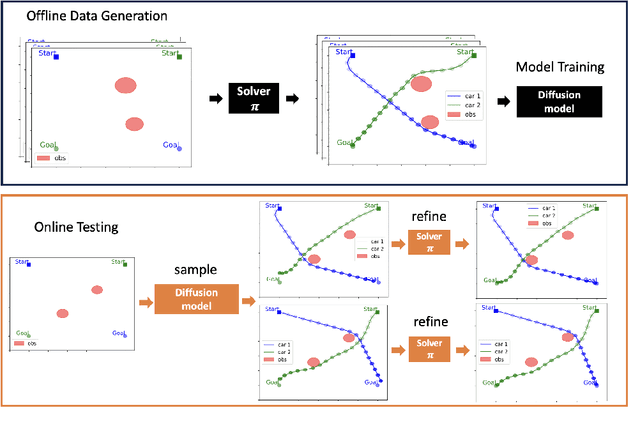
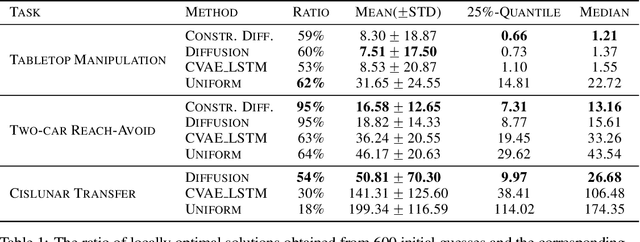
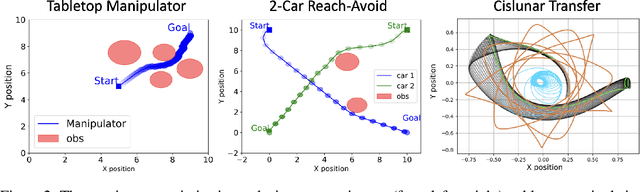

Trajectory optimization in robotics poses a challenging non-convex problem due to complex dynamics and environmental settings. Traditional numerical optimization methods are time-consuming in finding feasible solutions, whereas data-driven approaches lack safety guarantees for the output trajectories. In this paper, we introduce a general and fully parallelizable framework that combines diffusion models and numerical solvers for non-convex trajectory optimization, ensuring both computational efficiency and constraint satisfaction. A novel constrained diffusion model is proposed with an additional constraint violation loss for training. It aims to approximate the distribution of locally optimal solutions while minimizing constraint violations during sampling. The samples are then used as initial guesses for a numerical solver to refine and derive final solutions with formal verification of feasibility and optimality. Experimental evaluations on three tasks over different robotics domains verify the improved constraint satisfaction and computational efficiency with 4$\times$ to 22$\times$ acceleration using our proposed method, which generalizes across trajectory optimization problems and scales well with problem complexity.
SoftQE: Learned Representations of Queries Expanded by LLMs
Feb 20, 2024We investigate the integration of Large Language Models (LLMs) into query encoders to improve dense retrieval without increasing latency and cost, by circumventing the dependency on LLMs at inference time. SoftQE incorporates knowledge from LLMs by mapping embeddings of input queries to those of the LLM-expanded queries. While improvements over various strong baselines on in-domain MS-MARCO metrics are marginal, SoftQE improves performance by 2.83 absolute percentage points on average on five out-of-domain BEIR tasks.
Time-modulated arrays with Haar wavelets
Jan 28, 2024Time-modulated arrays (TMAs) can effectively perform beamsteering over the first positive harmonic pattern by applying progressively delayed versions of stair-step approximations of a sine waveform to the antenna excitations. In this letter, we consider synthesizing such stair-step sine approximations by means of Haar wavelets. Haar functions constitute a complete orthonormal set of rectangular waveforms, which have the ability to represent a given function with a high degree of accuracy using few constituent terms. Hence, when they are applied to the TMA synthesis, employing single-pole double-throw switches, such a feature leads to an excellent rejection level of the undesired harmonics as well as a bandwidth greater than that supported by conventional TMAs with on-off switches.
* 5 pages, 4 figures, Published in IEEE Antennas and Wireless Propagation Letters
Misalignment, Learning, and Ranking: Harnessing Users Limited Attention
Feb 21, 2024In digital health and EdTech, recommendation systems face a significant challenge: users often choose impulsively, in ways that conflict with the platform's long-term payoffs. This misalignment makes it difficult to effectively learn to rank items, as it may hinder exploration of items with greater long-term payoffs. Our paper tackles this issue by utilizing users' limited attention spans. We propose a model where a platform presents items with unknown payoffs to the platform in a ranked list to $T$ users over time. Each user selects an item by first considering a prefix window of these ranked items and then picking the highest preferred item in that window (and the platform observes its payoff for this item). We study the design of online bandit algorithms that obtain vanishing regret against hindsight optimal benchmarks. We first consider adversarial window sizes and stochastic iid payoffs. We design an active-elimination-based algorithm that achieves an optimal instance-dependent regret bound of $O(\log(T))$, by showing matching regret upper and lower bounds. The key idea is using the combinatorial structure of the problem to either obtain a large payoff from each item or to explore by getting a sample from that item. This method systematically narrows down the item choices to enhance learning efficiency and payoff. Second, we consider adversarial payoffs and stochastic iid window sizes. We start from the full-information problem of finding the permutation that maximizes the expected payoff. By a novel combinatorial argument, we characterize the polytope of admissible item selection probabilities by a permutation and show it has a polynomial-size representation. Using this representation, we show how standard algorithms for adversarial online linear optimization in the space of admissible probabilities can be used to obtain a polynomial-time algorithm with $O(\sqrt{T})$ regret.
Best of Many in Both Worlds: Online Resource Allocation with Predictions under Unknown Arrival Model
Feb 21, 2024Online decision-makers today can often obtain predictions on future variables, such as arrivals, demands, inventories, and so on. These predictions can be generated from simple forecasting algorithms for univariate time-series, all the way to state-of-the-art machine learning models that leverage multiple time-series and additional feature information. However, the prediction quality is often unknown to decisions-makers a priori, hence blindly following the predictions can be harmful. In this paper, we address this problem by giving algorithms that take predictions as inputs and perform robustly against the unknown prediction quality. We consider the online resource allocation problem, one of the most generic models in revenue management and online decision-making. In this problem, a decision maker has a limited amount of resources, and requests arrive sequentially. For each request, the decision-maker needs to decide on an action, which generates a certain amount of rewards and consumes a certain amount of resources, without knowing the future requests. The decision-maker's objective is to maximize the total rewards subject to resource constraints. We take the shadow price of each resource as prediction, which can be obtained by predictions on future requests. Prediction quality is naturally defined to be the $\ell_1$ distance between the prediction and the actual shadow price. Our main contribution is an algorithm which takes the prediction of unknown quality as an input, and achieves asymptotically optimal performance under both requests arrival models (stochastic and adversarial) without knowing the prediction quality and the requests arrival model beforehand. We show our algorithm's performance matches the best achievable performance of any algorithm had the arrival models and the accuracy of the predictions been known. We empirically validate our algorithm with experiments.
GDTM: An Indoor Geospatial Tracking Dataset with Distributed Multimodal Sensors
Feb 21, 2024Constantly locating moving objects, i.e., geospatial tracking, is essential for autonomous building infrastructure. Accurate and robust geospatial tracking often leverages multimodal sensor fusion algorithms, which require large datasets with time-aligned, synchronized data from various sensor types. However, such datasets are not readily available. Hence, we propose GDTM, a nine-hour dataset for multimodal object tracking with distributed multimodal sensors and reconfigurable sensor node placements. Our dataset enables the exploration of several research problems, such as optimizing architectures for processing multimodal data, and investigating models' robustness to adverse sensing conditions and sensor placement variances. A GitHub repository containing the code, sample data, and checkpoints of this work is available at https://github.com/nesl/GDTM.