 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning Instance-Specific Adaptation for Cross-Domain Segmentation
Mar 30, 2022

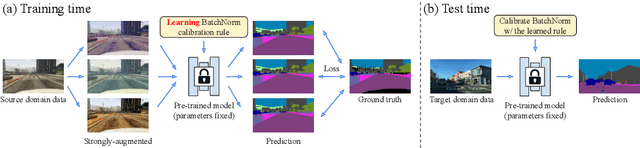
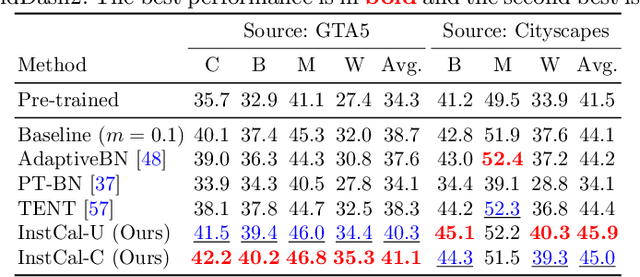

We propose a test-time adaptation method for cross-domain image segmentation. Our method is simple: Given a new unseen instance at test time, we adapt a pre-trained model by conducting instance-specific BatchNorm (statistics) calibration. Our approach has two core components. First, we replace the manually designed BatchNorm calibration rule with a learnable module. Second, we leverage strong data augmentation to simulate random domain shifts for learning the calibration rule. In contrast to existing domain adaptation methods, our method does not require accessing the target domain data at training time or conducting computationally expensive test-time model training/optimization. Equipping our method with models trained by standard recipes achieves significant improvement, comparing favorably with several state-of-the-art domain generalization and one-shot unsupervised domain adaptation approaches. Combining our method with the domain generalization methods further improves performance, reaching a new state of the art.
Classification of multivariate weakly-labelled time-series with attention
Feb 16, 2021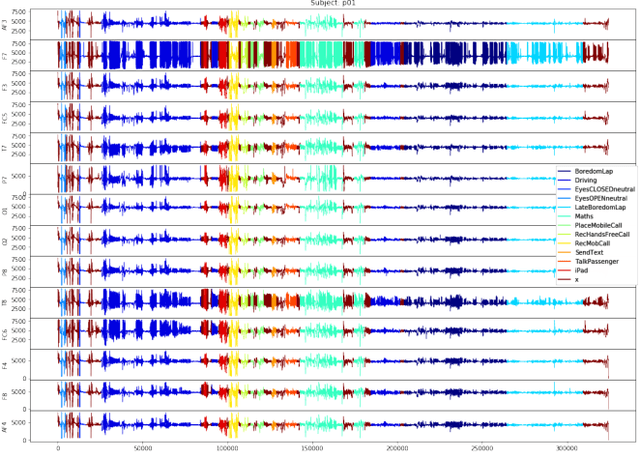
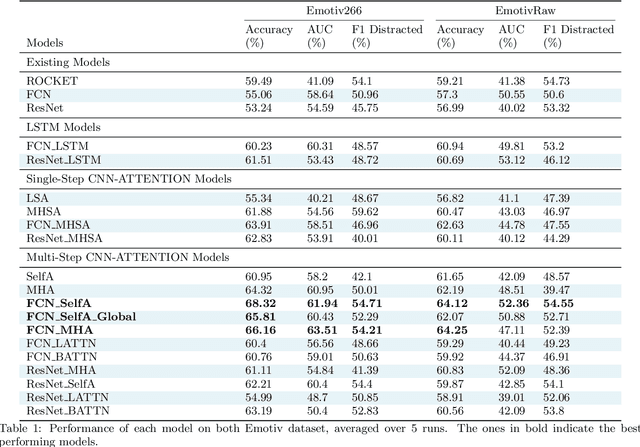
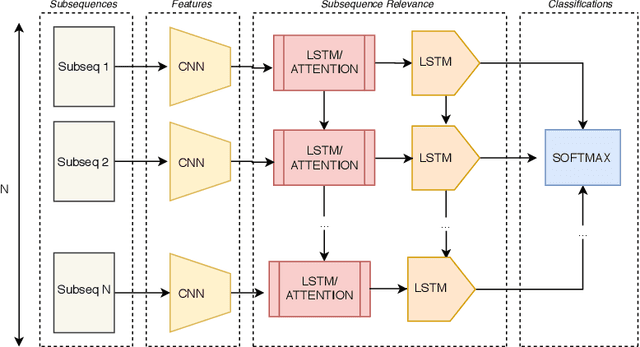
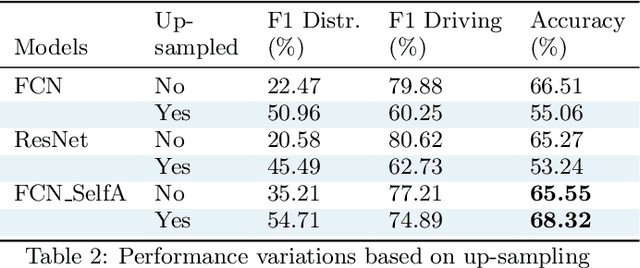
This research identifies a gap in weakly-labelled multivariate time-series classification (TSC), where state-of-the-art TSC models do not per-form well. Weakly labelled time-series are time-series containing noise and significant redundancies. In response to this gap, this paper proposes an approach of exploiting context relevance of subsequences from previous subsequences to improve classification accuracy. To achieve this, state-of-the-art Attention algorithms are experimented in combination with the top CNN models for TSC (FCN and ResNet), in an CNN-LSTM architecture. Attention is a popular strategy for context extraction with exceptional performance in modern sequence-to-sequence tasks. This paper shows how attention algorithms can be used for improved weakly labelledTSC by evaluating models on a multivariate EEG time-series dataset obtained using a commercial Emotiv headsets from participants performing various activities while driving. These time-series are segmented into sub-sequences and labelled to allow supervised TSC.
Curious Exploration via Structured World Models Yields Zero-Shot Object Manipulation
Jun 22, 2022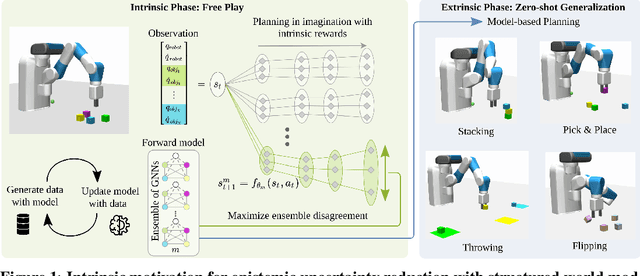

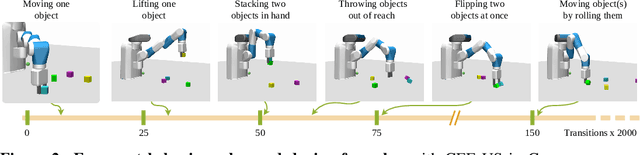
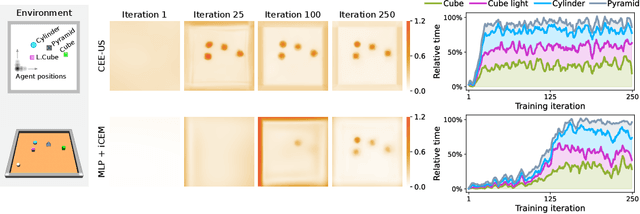
It has been a long-standing dream to design artificial agents that explore their environment efficiently via intrinsic motivation, similar to how children perform curious free play. Despite recent advances in intrinsically motivated reinforcement learning (RL), sample-efficient exploration in object manipulation scenarios remains a significant challenge as most of the relevant information lies in the sparse agent-object and object-object interactions. In this paper, we propose to use structured world models to incorporate relational inductive biases in the control loop to achieve sample-efficient and interaction-rich exploration in compositional multi-object environments. By planning for future novelty inside structured world models, our method generates free-play behavior that starts to interact with objects early on and develops more complex behavior over time. Instead of using models only to compute intrinsic rewards, as commonly done, our method showcases that the self-reinforcing cycle between good models and good exploration also opens up another avenue: zero-shot generalization to downstream tasks via model-based planning. After the entirely intrinsic task-agnostic exploration phase, our method solves challenging downstream tasks such as stacking, flipping, pick & place, and throwing that generalizes to unseen numbers and arrangements of objects without any additional training.
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time
Mar 10, 2022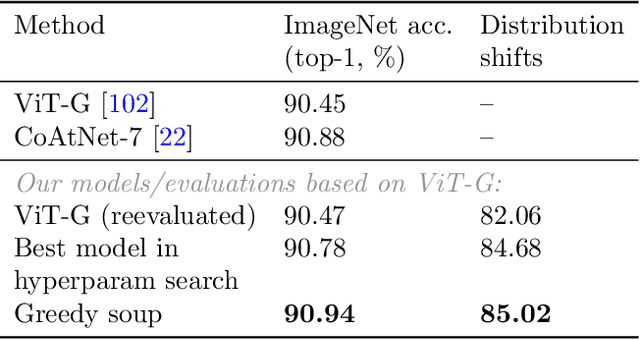
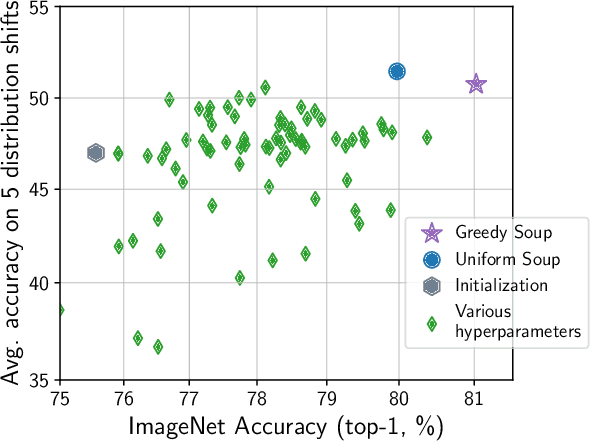

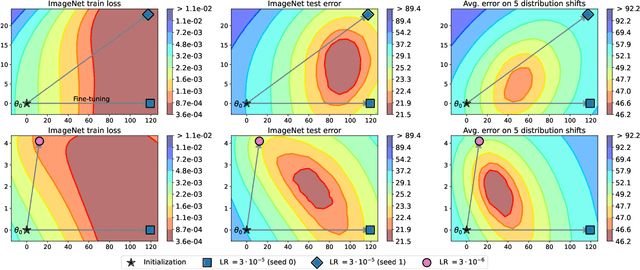
The conventional recipe for maximizing model accuracy is to (1) train multiple models with various hyperparameters and (2) pick the individual model which performs best on a held-out validation set, discarding the remainder. In this paper, we revisit the second step of this procedure in the context of fine-tuning large pre-trained models, where fine-tuned models often appear to lie in a single low error basin. We show that averaging the weights of multiple models fine-tuned with different hyperparameter configurations often improves accuracy and robustness. Unlike a conventional ensemble, we may average many models without incurring any additional inference or memory costs -- we call the results "model soups." When fine-tuning large pre-trained models such as CLIP, ALIGN, and a ViT-G pre-trained on JFT, our soup recipe provides significant improvements over the best model in a hyperparameter sweep on ImageNet. As a highlight, the resulting ViT-G model attains 90.94% top-1 accuracy on ImageNet, a new state of the art. Furthermore, we show that the model soup approach extends to multiple image classification and natural language processing tasks, improves out-of-distribution performance, and improves zero-shot performance on new downstream tasks. Finally, we analytically relate the performance similarity of weight-averaging and logit-ensembling to flatness of the loss and confidence of the predictions, and validate this relation empirically.
Mean Embeddings with Test-Time Data Augmentation for Ensembling of Representations
Jun 15, 2021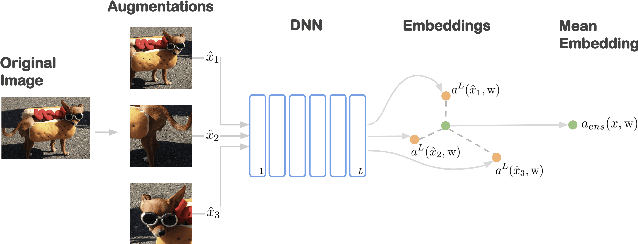
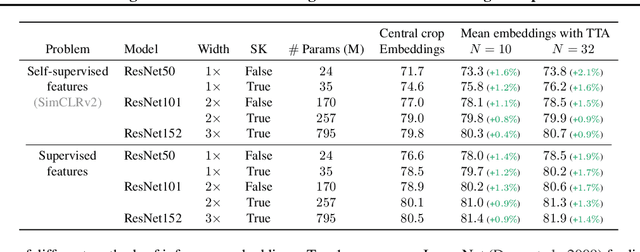
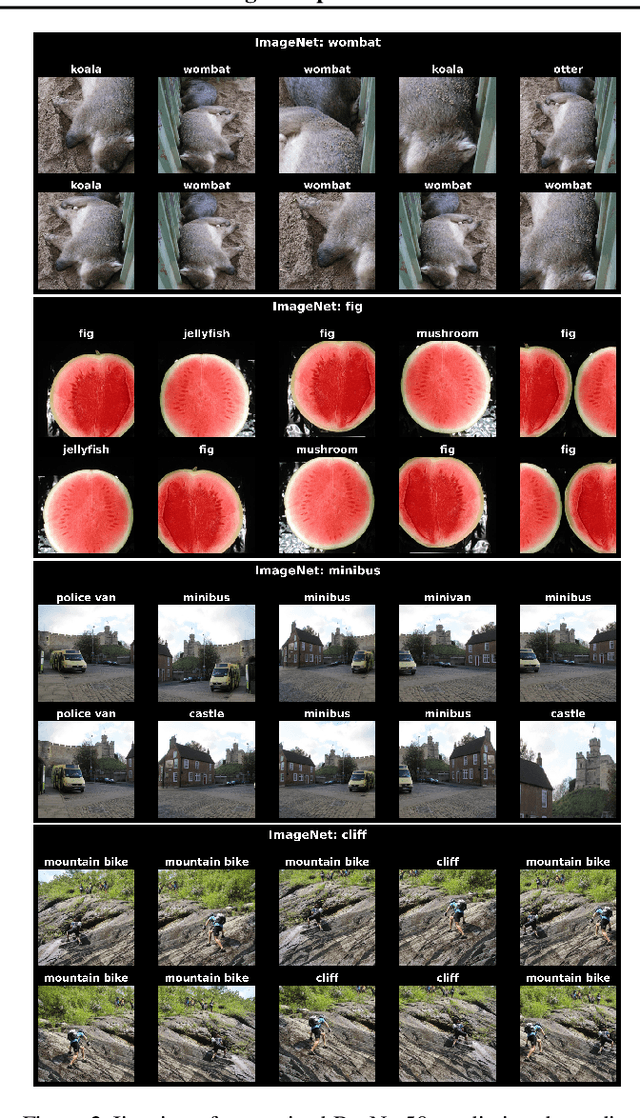
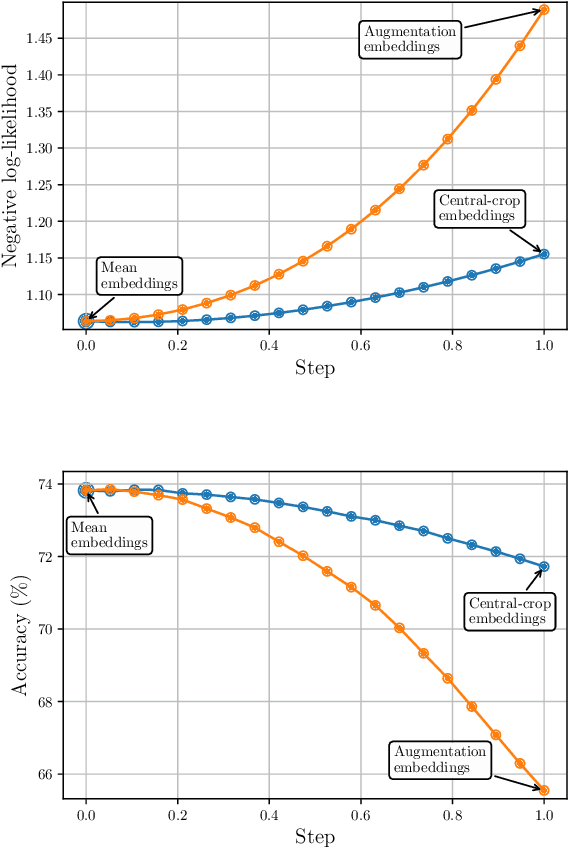
Averaging predictions over a set of models -- an ensemble -- is widely used to improve predictive performance and uncertainty estimation of deep learning models. At the same time, many machine learning systems, such as search, matching, and recommendation systems, heavily rely on embeddings. Unfortunately, due to misalignment of features of independently trained models, embeddings, cannot be improved with a naive deep ensemble like approach. In this work, we look at the ensembling of representations and propose mean embeddings with test-time augmentation (MeTTA) simple yet well-performing recipe for ensembling representations. Empirically we demonstrate that MeTTA significantly boosts the quality of linear evaluation on ImageNet for both supervised and self-supervised models. Even more exciting, we draw connections between MeTTA, image retrieval, and transformation invariant models. We believe that spreading the success of ensembles to inference higher-quality representations is the important step that will open many new applications of ensembling.
Learning in Observable POMDPs, without Computationally Intractable Oracles
Jun 07, 2022Much of reinforcement learning theory is built on top of oracles that are computationally hard to implement. Specifically for learning near-optimal policies in Partially Observable Markov Decision Processes (POMDPs), existing algorithms either need to make strong assumptions about the model dynamics (e.g. deterministic transitions) or assume access to an oracle for solving a hard optimistic planning or estimation problem as a subroutine. In this work we develop the first oracle-free learning algorithm for POMDPs under reasonable assumptions. Specifically, we give a quasipolynomial-time end-to-end algorithm for learning in "observable" POMDPs, where observability is the assumption that well-separated distributions over states induce well-separated distributions over observations. Our techniques circumvent the more traditional approach of using the principle of optimism under uncertainty to promote exploration, and instead give a novel application of barycentric spanners to constructing policy covers.
Real-time Face Mask Detection in Video Data
May 05, 2021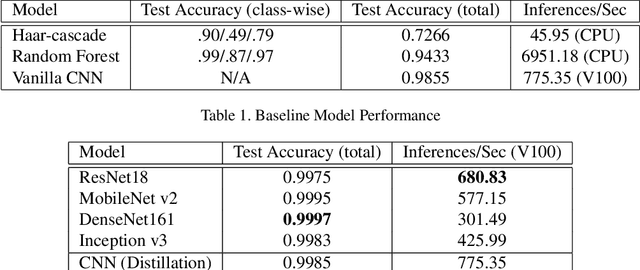
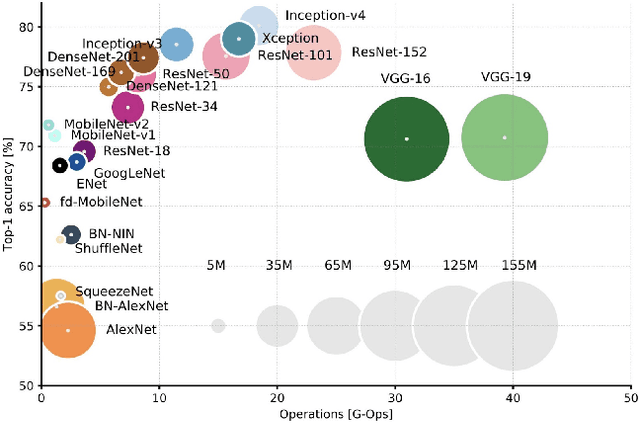
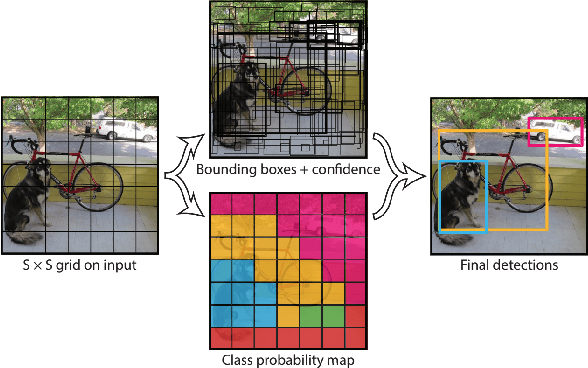
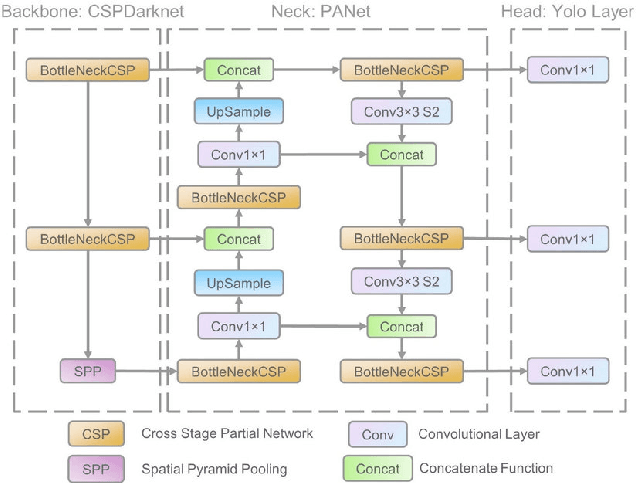
In response to the ongoing COVID-19 pandemic, we present a robust deep learning pipeline that is capable of identifying correct and incorrect mask-wearing from real-time video streams. To accomplish this goal, we devised two separate approaches and evaluated their performance and run-time efficiency. The first approach leverages a pre-trained face detector in combination with a mask-wearing image classifier trained on a large-scale synthetic dataset. The second approach utilizes a state-of-the-art object detection network to perform localization and classification of faces in one shot, fine-tuned on a small set of labeled real-world images. The first pipeline achieved a test accuracy of 99.97% on the synthetic dataset and maintained 6 FPS running on video data. The second pipeline achieved a mAP(0.5) of 89% on real-world images while sustaining 52 FPS on video data. We have concluded that if a larger dataset with bounding-box labels can be curated, this task is best suited using object detection architectures such as YOLO and SSD due to their superior inference speed and satisfactory performance on key evaluation metrics.
PredictionNet: Real-Time Joint Probabilistic Traffic Prediction for Planning, Control, and Simulation
Sep 23, 2021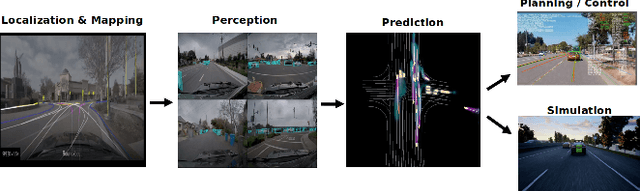
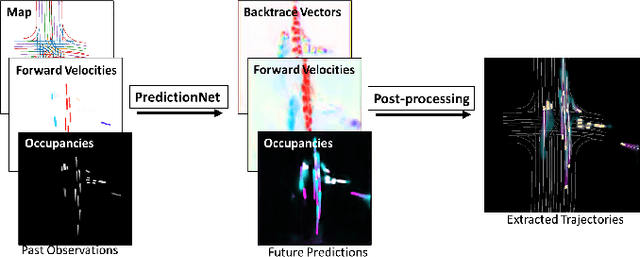
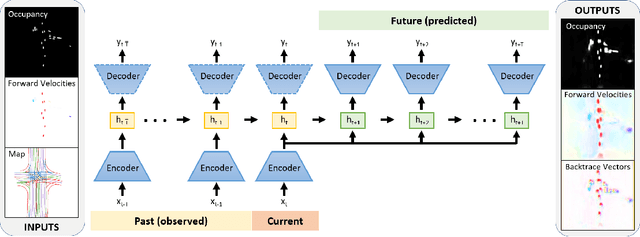

Predicting the future motion of traffic agents is crucial for safe and efficient autonomous driving. To this end, we present PredictionNet, a deep neural network (DNN) that predicts the motion of all surrounding traffic agents together with the ego-vehicle's motion. All predictions are probabilistic and are represented in a simple top-down rasterization that allows an arbitrary number of agents. Conditioned on a multilayer map with lane information, the network outputs future positions, velocities, and backtrace vectors jointly for all agents including the ego-vehicle in a single pass. Trajectories are then extracted from the output. The network can be used to simulate realistic traffic, and it produces competitive results on popular benchmarks. More importantly, it has been used to successfully control a real-world vehicle for hundreds of kilometers, by combining it with a motion planning/control subsystem. The network runs faster than real-time on an embedded GPU, and the system shows good generalization (across sensory modalities and locations) due to the choice of input representation. Furthermore, we demonstrate that by extending the DNN with reinforcement learning (RL), it can better handle rare or unsafe events like aggressive maneuvers and crashes.
Analysis and modeling to forecast in time series: a systematic review
Mar 31, 2021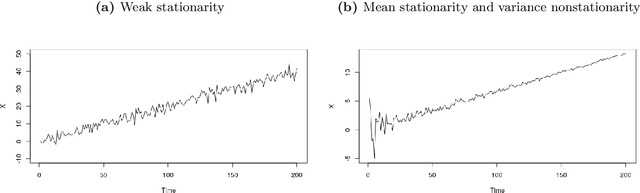

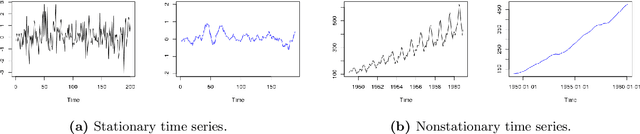
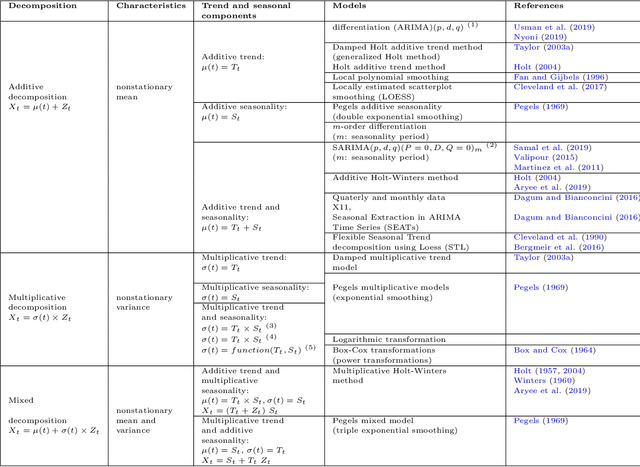
This paper surveys state-of-the-art methods and models dedicated to time series analysis and modeling, with the final aim of prediction. This review aims to offer a structured and comprehensive view of the full process flow, and encompasses time series decomposition, stationary tests, modeling and forecasting. Besides, to meet didactic purposes, a unified presentation has been adopted throughout this survey, to present decomposition frameworks on the one hand and linear and nonlinear time series models on the other hand. First, we decrypt the relationships between stationarity and linearity, and further examine the main classes of methods used to test for weak stationarity. Next, the main frameworks for time series decomposition are presented in a unified way: depending on the time series, a more or less complex decomposition scheme seeks to obtain nonstationary effects (the deterministic components) and a remaining stochastic component. An appropriate modeling of the latter is a critical step to guarantee prediction accuracy. We then present three popular linear models, together with two more flexible variants of the latter. A step further in model complexity, and still in a unified way, we present five major nonlinear models used for time series. Amongst nonlinear models, artificial neural networks hold a place apart as deep learning has recently gained considerable attention. A whole section is therefore dedicated to time series forecasting relying on deep learning approaches. A final section provides a list of R and Python implementations for the methods, models and tests presented throughout this review. In this document, our intention is to bring sufficient in-depth knowledge, while covering a broad range of models and forecasting methods: this compilation spans from well-established conventional approaches to more recent adaptations of deep learning to time series forecasting.
DeeprETA: An ETA Post-processing System at Scale
Jun 05, 2022
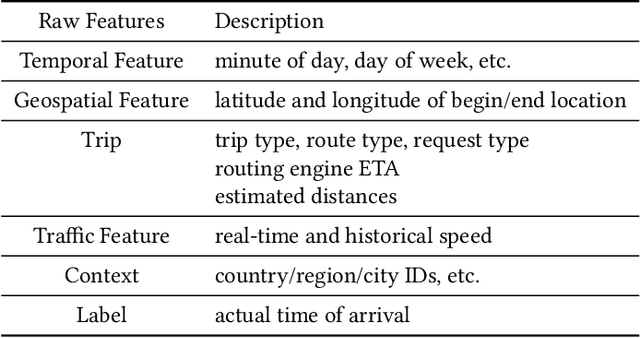
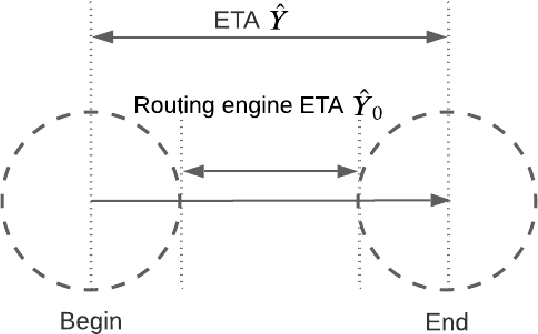
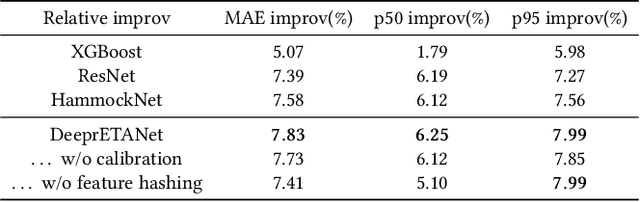
Estimated Time of Arrival (ETA) plays an important role in delivery and ride-hailing platforms. For example, Uber uses ETAs to calculate fares, estimate pickup times, match riders to drivers, plan deliveries, and more. Commonly used route planning algorithms predict an ETA conditioned on the best available route, but such ETA estimates can be unreliable when the actual route taken is not known in advance. In this paper, we describe an ETA post-processing system in which a deep residual ETA network (DeeprETA) refines naive ETAs produced by a route planning algorithm. Offline experiments and online tests demonstrate that post-processing by DeeprETA significantly improves upon the accuracy of naive ETAs as measured by mean and median absolute error. We further show that post-processing by DeeprETA attains lower error than competitive baseline regression models.