 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
A Comprehensive Study of Exploitable Patterns in Smart Contracts: From Vulnerability to Defense
Apr 30, 2025With the rapid advancement of blockchain technology, smart contracts have enabled the implementation of increasingly complex functionalities. However, ensuring the security of smart contracts remains a persistent challenge across the stages of development, compilation, and execution. Vulnerabilities within smart contracts not only undermine the security of individual applications but also pose significant risks to the broader blockchain ecosystem, as demonstrated by the growing frequency of attacks since 2016, resulting in substantial financial losses. This paper provides a comprehensive analysis of key security risks in Ethereum smart contracts, specifically those written in Solidity and executed on the Ethereum Virtual Machine (EVM). We focus on two prevalent and critical vulnerability types (reentrancy and integer overflow) by examining their underlying mechanisms, replicating attack scenarios, and assessing effective countermeasures.
Privacy-Preserving Orthogonal Aggregation for Guaranteeing Gender Fairness in Federated Recommendation
Nov 29, 2024



Under stringent privacy constraints, whether federated recommendation systems can achieve group fairness remains an inadequately explored question. Taking gender fairness as a representative issue, we identify three phenomena in federated recommendation systems: performance difference, data imbalance, and preference disparity. We discover that the state-of-the-art methods only focus on the first phenomenon. Consequently, their imposition of inappropriate fairness constraints detrimentally affects the model training. Moreover, due to insufficient sensitive attribute protection of existing works, we can infer the gender of all users with 99.90% accuracy even with the addition of maximal noise. In this work, we propose Privacy-Preserving Orthogonal Aggregation (PPOA), which employs the secure aggregation scheme and quantization technique, to prevent the suppression of minority groups by the majority and preserve the distinct preferences for better group fairness. PPOA can assist different groups in obtaining their respective model aggregation results through a designed orthogonal mapping while keeping their attributes private. Experimental results on three real-world datasets demonstrate that PPOA enhances recommendation effectiveness for both females and males by up to 8.25% and 6.36%, respectively, with a maximum overall improvement of 7.30%, and achieves optimal fairness in most cases. Extensive ablation experiments and visualizations indicate that PPOA successfully maintains preferences for different gender groups.
A Thorough Examination on Zero-shot Dense Retrieval
Apr 27, 2022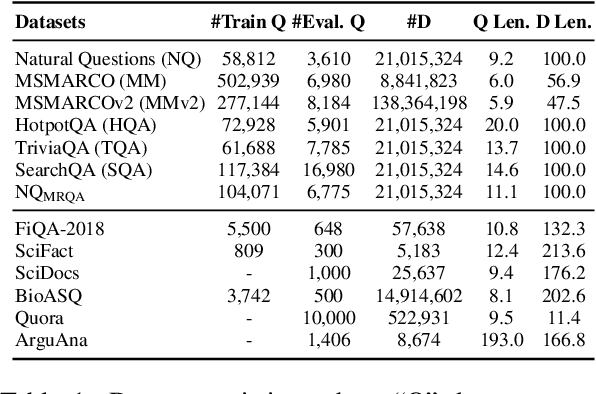
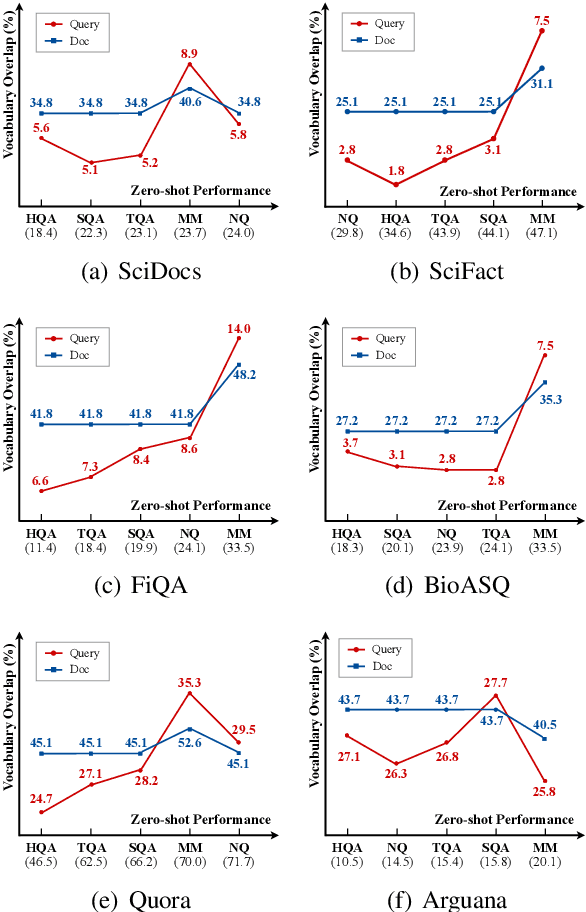
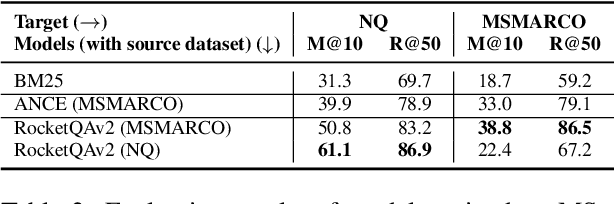
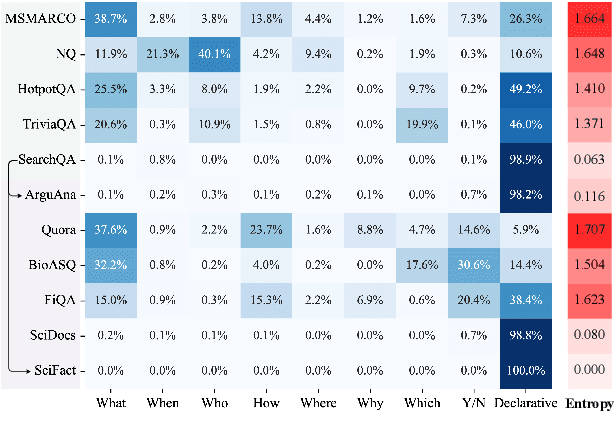
Recent years have witnessed the significant advance in dense retrieval (DR) based on powerful pre-trained language models (PLM). DR models have achieved excellent performance in several benchmark datasets, while they are shown to be not as competitive as traditional sparse retrieval models (e.g., BM25) in a zero-shot retrieval setting. However, in the related literature, there still lacks a detailed and comprehensive study on zero-shot retrieval. In this paper, we present the first thorough examination of the zero-shot capability of DR models. We aim to identify the key factors and analyze how they affect zero-shot retrieval performance. In particular, we discuss the effect of several key factors related to source training set, analyze the potential bias from the target dataset, and review and compare existing zero-shot DR models. Our findings provide important evidence to better understand and develop zero-shot DR models.
Real-time Face Mask Detection in Video Data
May 05, 2021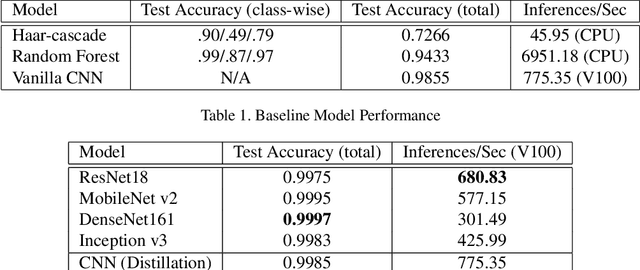
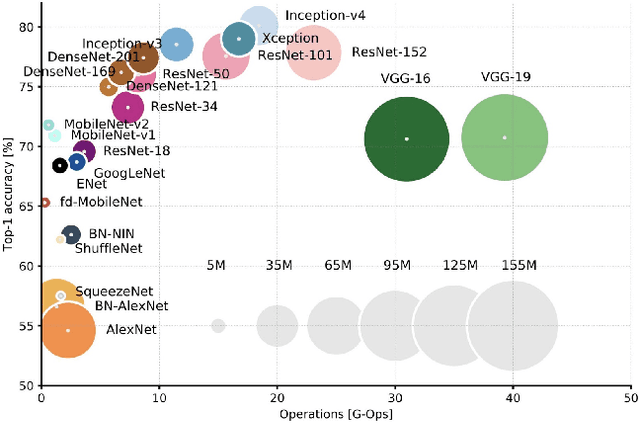
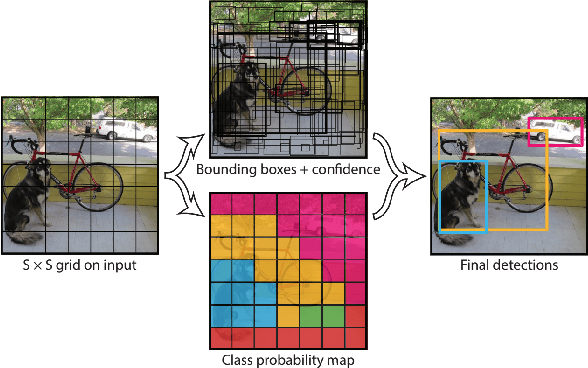
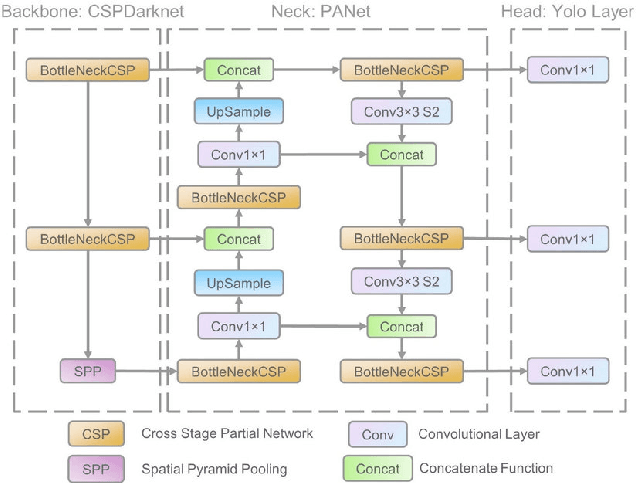
In response to the ongoing COVID-19 pandemic, we present a robust deep learning pipeline that is capable of identifying correct and incorrect mask-wearing from real-time video streams. To accomplish this goal, we devised two separate approaches and evaluated their performance and run-time efficiency. The first approach leverages a pre-trained face detector in combination with a mask-wearing image classifier trained on a large-scale synthetic dataset. The second approach utilizes a state-of-the-art object detection network to perform localization and classification of faces in one shot, fine-tuned on a small set of labeled real-world images. The first pipeline achieved a test accuracy of 99.97% on the synthetic dataset and maintained 6 FPS running on video data. The second pipeline achieved a mAP(0.5) of 89% on real-world images while sustaining 52 FPS on video data. We have concluded that if a larger dataset with bounding-box labels can be curated, this task is best suited using object detection architectures such as YOLO and SSD due to their superior inference speed and satisfactory performance on key evaluation metrics.