 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
PSTNet: Point Spatio-Temporal Convolution on Point Cloud Sequences
May 27, 2022
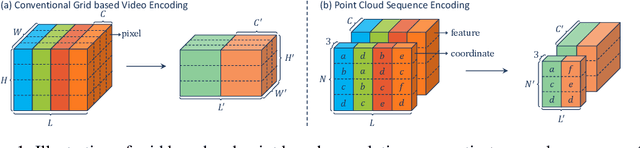
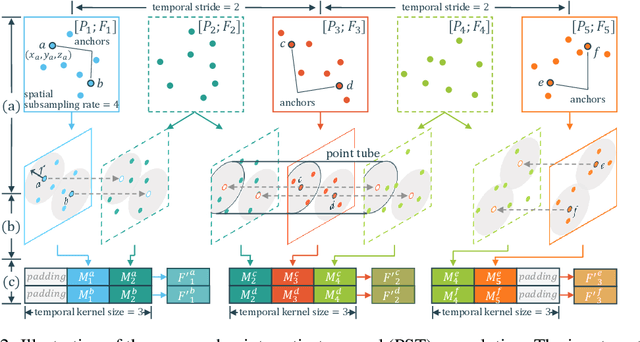
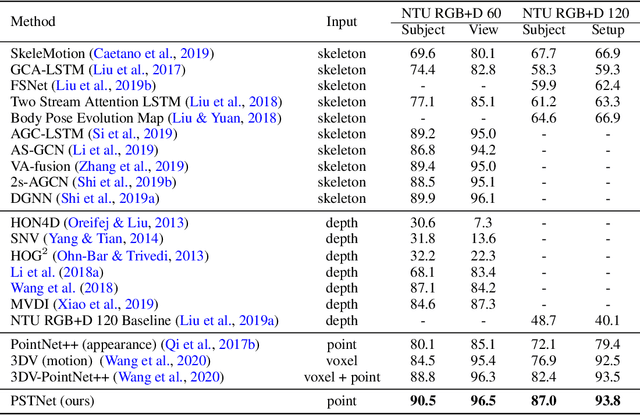
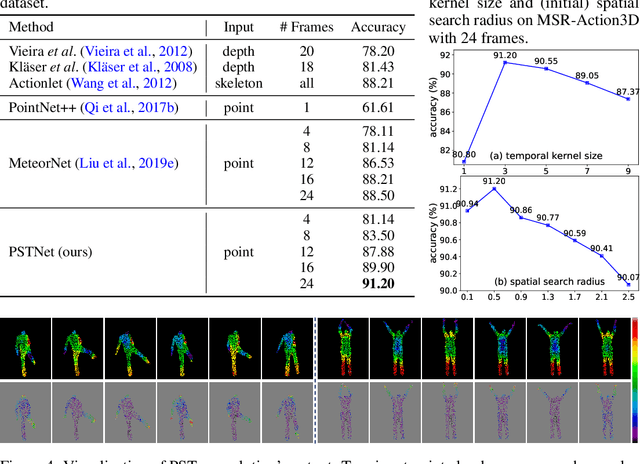
Point cloud sequences are irregular and unordered in the spatial dimension while exhibiting regularities and order in the temporal dimension. Therefore, existing grid based convolutions for conventional video processing cannot be directly applied to spatio-temporal modeling of raw point cloud sequences. In this paper, we propose a point spatio-temporal (PST) convolution to achieve informative representations of point cloud sequences. The proposed PST convolution first disentangles space and time in point cloud sequences. Then, a spatial convolution is employed to capture the local structure of points in the 3D space, and a temporal convolution is used to model the dynamics of the spatial regions along the time dimension. Furthermore, we incorporate the proposed PST convolution into a deep network, namely PSTNet, to extract features of point cloud sequences in a hierarchical manner. Extensive experiments on widely-used 3D action recognition and 4D semantic segmentation datasets demonstrate the effectiveness of PSTNet to model point cloud sequences.
Inner Monologue: Embodied Reasoning through Planning with Language Models
Jul 12, 2022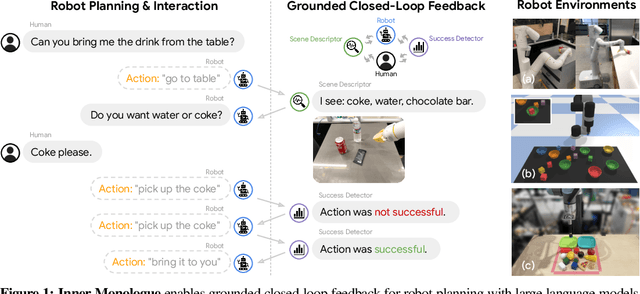
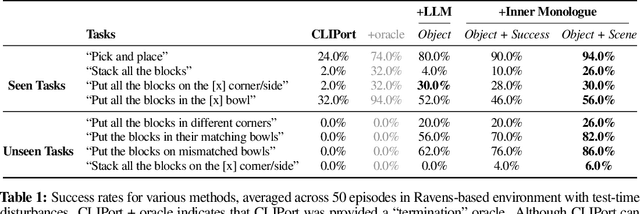


Recent works have shown how the reasoning capabilities of Large Language Models (LLMs) can be applied to domains beyond natural language processing, such as planning and interaction for robots. These embodied problems require an agent to understand many semantic aspects of the world: the repertoire of skills available, how these skills influence the world, and how changes to the world map back to the language. LLMs planning in embodied environments need to consider not just what skills to do, but also how and when to do them - answers that change over time in response to the agent's own choices. In this work, we investigate to what extent LLMs used in such embodied contexts can reason over sources of feedback provided through natural language, without any additional training. We propose that by leveraging environment feedback, LLMs are able to form an inner monologue that allows them to more richly process and plan in robotic control scenarios. We investigate a variety of sources of feedback, such as success detection, scene description, and human interaction. We find that closed-loop language feedback significantly improves high-level instruction completion on three domains, including simulated and real table top rearrangement tasks and long-horizon mobile manipulation tasks in a kitchen environment in the real world.
Liver Segmentation using Turbolift Learning for CT and Cone-beam C-arm Perfusion Imaging
Jul 20, 2022
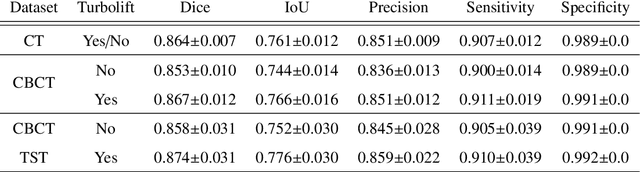

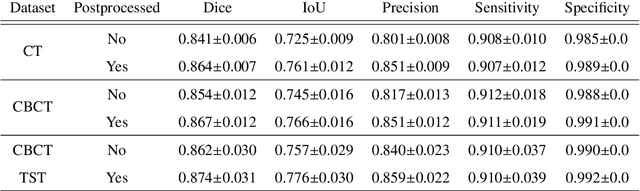
Model-based reconstruction employing the time separation technique (TST) was found to improve dynamic perfusion imaging of the liver using C-arm cone-beam computed tomography (CBCT). To apply TST using prior knowledge extracted from CT perfusion data, the liver should be accurately segmented from the CT scans. Reconstructions of primary and model-based CBCT data need to be segmented for proper visualisation and interpretation of perfusion maps. This research proposes Turbolift learning, which trains a modified version of the multi-scale Attention UNet on different liver segmentation tasks serially, following the order of the trainings CT, CBCT, CBCT TST - making the previous trainings act as pre-training stages for the subsequent ones - addressing the problem of limited number of datasets for training. For the final task of liver segmentation from CBCT TST, the proposed method achieved an overall Dice scores of 0.874$\pm$0.031 and 0.905$\pm$0.007 in 6-fold and 4-fold cross-validation experiments, respectively - securing statistically significant improvements over the model, which was trained only for that task. Experiments revealed that Turbolift not only improves the overall performance of the model but also makes it robust against artefacts originating from the embolisation materials and truncation artefacts. Additionally, in-depth analyses confirmed the order of the segmentation tasks. This paper shows the potential of segmenting the liver from CT, CBCT, and CBCT TST, learning from the available limited training data, which can possibly be used in the future for the visualisation and evaluation of the perfusion maps for the treatment evaluation of liver diseases.
Efficient Transformer-based Speech Enhancement Using Long Frames and STFT Magnitudes
Jun 23, 2022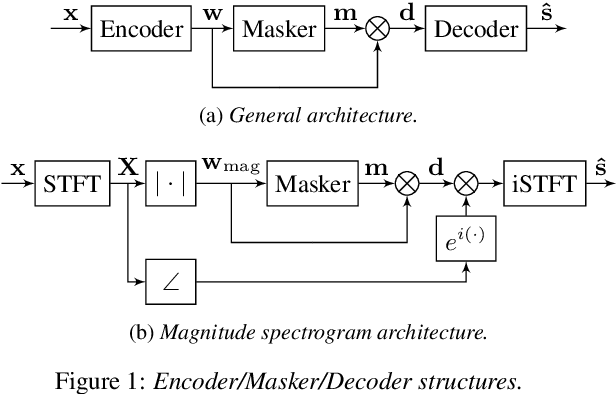
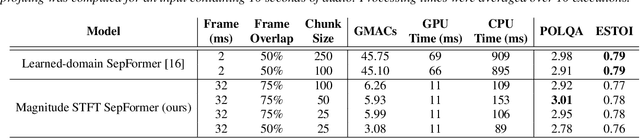
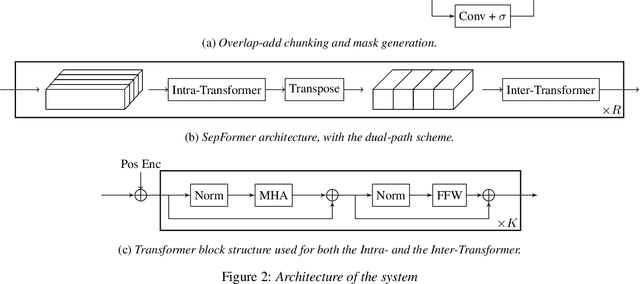
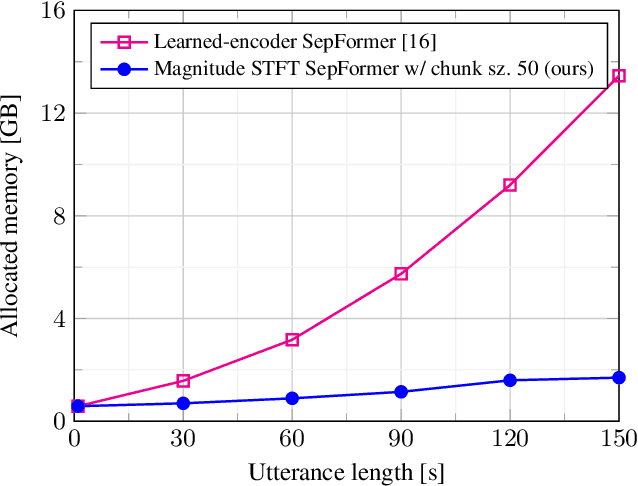
The SepFormer architecture shows very good results in speech separation. Like other learned-encoder models, it uses short frames, as they have been shown to obtain better performance in these cases. This results in a large number of frames at the input, which is problematic; since the SepFormer is transformer-based, its computational complexity drastically increases with longer sequences. In this paper, we employ the SepFormer in a speech enhancement task and show that by replacing the learned-encoder features with a magnitude short-time Fourier transform (STFT) representation, we can use long frames without compromising perceptual enhancement performance. We obtained equivalent quality and intelligibility evaluation scores while reducing the number of operations by a factor of approximately 8 for a 10-second utterance.
MANI-Rank: Multiple Attribute and Intersectional Group Fairness for Consensus Ranking
Jul 20, 2022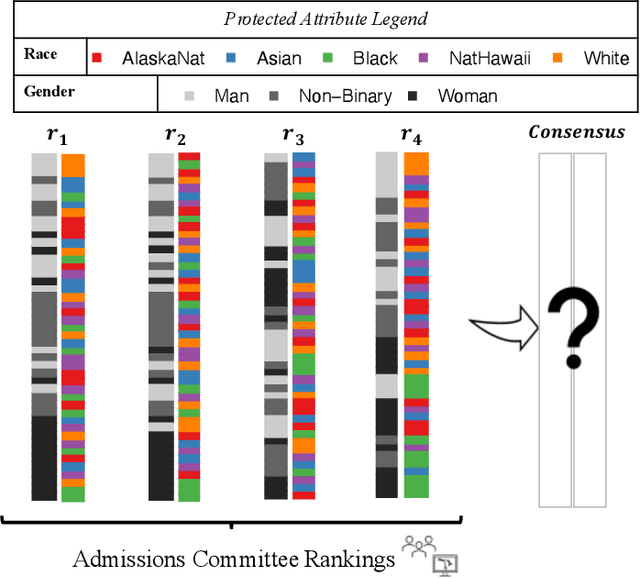

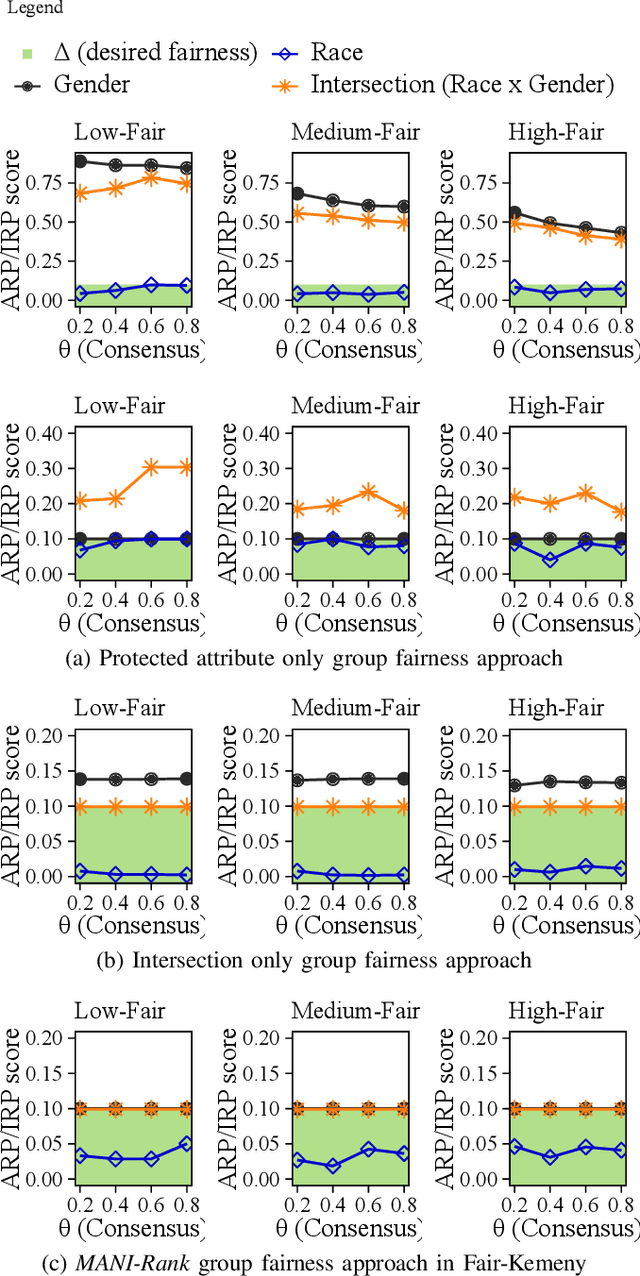
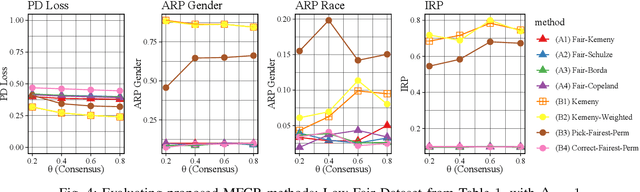
Combining the preferences of many rankers into one single consensus ranking is critical for consequential applications from hiring and admissions to lending. While group fairness has been extensively studied for classification, group fairness in rankings and in particular rank aggregation remains in its infancy. Recent work introduced the concept of fair rank aggregation for combining rankings but restricted to the case when candidates have a single binary protected attribute, i.e., they fall into two groups only. Yet it remains an open problem how to create a consensus ranking that represents the preferences of all rankers while ensuring fair treatment for candidates with multiple protected attributes such as gender, race, and nationality. In this work, we are the first to define and solve this open Multi-attribute Fair Consensus Ranking (MFCR) problem. As a foundation, we design novel group fairness criteria for rankings, called MANI-RANK, ensuring fair treatment of groups defined by individual protected attributes and their intersection. Leveraging the MANI-RANK criteria, we develop a series of algorithms that for the first time tackle the MFCR problem. Our experimental study with a rich variety of consensus scenarios demonstrates our MFCR methodology is the only approach to achieve both intersectional and protected attribute fairness while also representing the preferences expressed through many base rankings. Our real-world case study on merit scholarships illustrates the effectiveness of our MFCR methods to mitigate bias across multiple protected attributes and their intersections. This is an extended version of "MANI-Rank: Multiple Attribute and Intersectional Group Fairness for Consensus Ranking", to appear in ICDE 2022.
Wasserstein Graph Distance based on $L_1$-Approximated Tree Edit Distance between Weisfeiler-Lehman Subtrees
Jul 09, 2022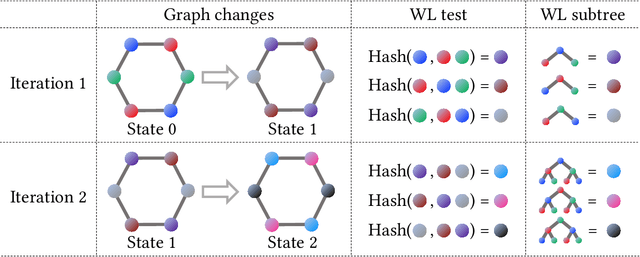
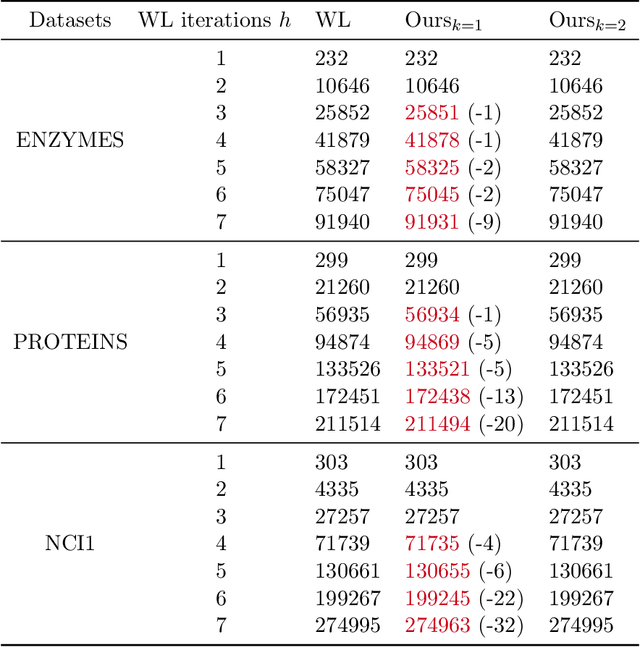
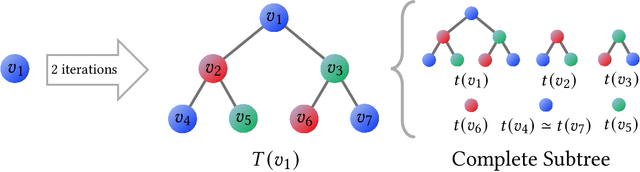
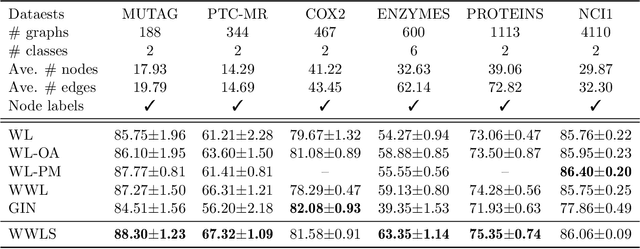
The Weisfeiler-Lehman (WL) test has been widely applied to graph kernels, metrics, and neural networks. However, it considers only the graph consistency, resulting in the weak descriptive power of structural information. Thus, it limits the performance improvement of applied methods. In addition, the similarity and distance between graphs defined by the WL test are in coarse measurements. To the best of our knowledge, this paper clarifies these facts for the first time and defines a metric we call the Wasserstein WL subtree (WWLS) distance. We introduce the WL subtree as the structural information in the neighborhood of nodes and assign it to each node. Then we define a new graph embedding space based on $L_1$-approximated tree edit distance ($L_1$-TED): the $L_1$ norm of the difference between node feature vectors on the space is the $L_1$-TED between these nodes. We further propose a fast algorithm for graph embedding. Finally, we use the Wasserstein distance to reflect the $L_1$-TED to the graph level. The WWLS can capture small changes in structure that are difficult with traditional metrics. We demonstrate its performance in several graph classification and metric validation experiments.
Forecasting Foreign Exchange Rates With Parameter-Free Regression Networks Tuned By Bayesian Optimization
Apr 26, 2022

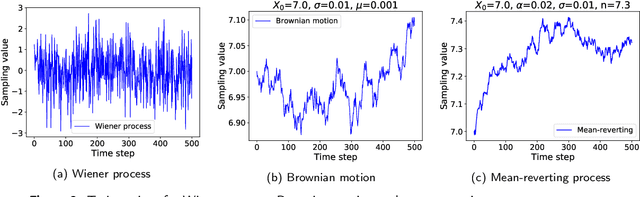

The article is concerned with the problem of multi-step financial time series forecasting of Foreign Exchange (FX) rates. To address this problem, we introduce a parameter-free regression network termed RegPred Net. The exchange rate to forecast is treated as a stochastic process. It is assumed to follow a generalization of Brownian motion and the mean-reverting process referred to as the generalized Ornstein-Uhlenbeck (OU) process, with time-dependent coefficients. Using past observed values of the input time series, these coefficients can be regressed online by the cells of the first half of the network (Reg). The regressed coefficients depend only on - but are very sensitive to - a small number of hyperparameters required to be set by a global optimization procedure for which, Bayesian optimization is an adequate heuristic. Thanks to its multi-layered architecture, the second half of the regression network (Pred) can project time-dependent values for the OU process coefficients and generate realistic trajectories of the time series. Predictions can be easily derived in the form of expected values estimated by averaging values obtained by Monte Carlo simulation. The forecasting accuracy on a 100 days horizon is evaluated for several of the most important FX rates such as EUR/USD, EUR/CNY, and EUR/GBP. Our experimental results show that the RegPred Net significantly outperforms ARMA, ARIMA, LSTMs, and Autoencoder-LSTM models in this task.
COVID-19 Disease Identification on Chest-CT images using CNN and VGG16
Jul 09, 2022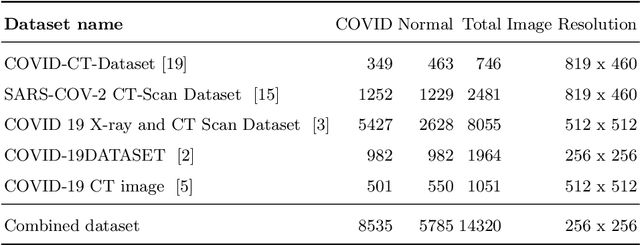
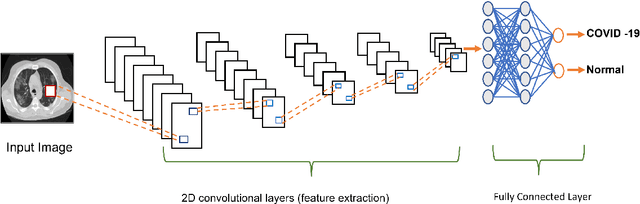
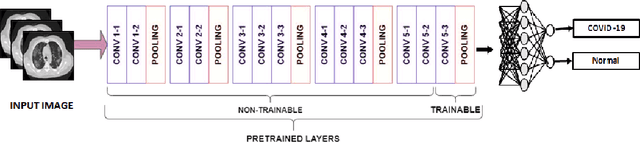

A newly identified coronavirus disease called COVID-19 mainly affects the human respiratory system. COVID-19 is an infectious disease caused by a virus originating in Wuhan, China, in December 2019. Early diagnosis is the primary challenge of health care providers. In the earlier stage, medical organizations were dazzled because there were no proper health aids or medicine to detect a COVID-19. A new diagnostic tool RT-PCR (Reverse Transcription Polymerase Chain Reaction), was introduced. It collects swab specimens from the patient's nose or throat, where the COVID-19 virus gathers. This method has some limitations related to accuracy and testing time. Medical experts suggest an alternative approach called CT (Computed Tomography) that can quickly diagnose the infected lung areas and identify the COVID-19 in an earlier stage. Using chest CT images, computer researchers developed several deep learning models identifying the COVID-19 disease. This study presents a Convolutional Neural Network (CNN) and VGG16-based model for automated COVID-19 identification on chest CT images. The experimental results using a public dataset of 14320 CT images showed a classification accuracy of 96.34% and 96.99% for CNN and VGG16, respectively.
Time separation technique with the basis of trigonometric functions as an efficient method for flat detector CT brain perfusion imaging
Oct 18, 2021
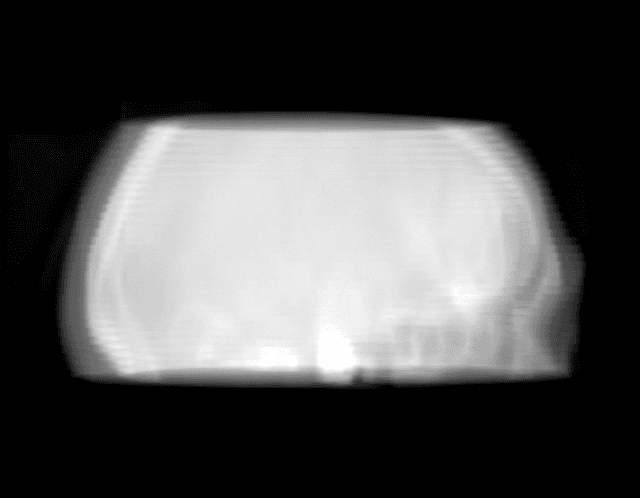
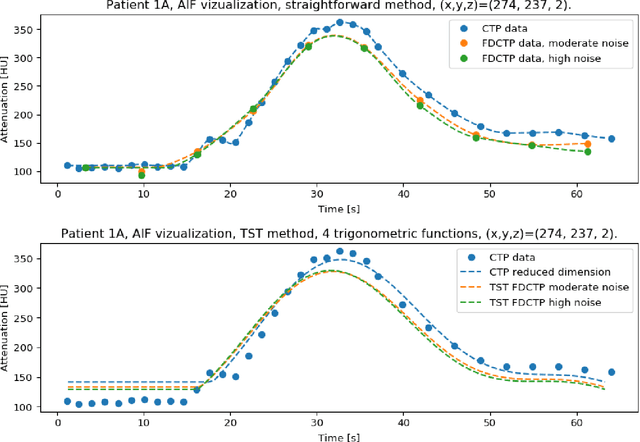

Dynamic perfusion imaging is routinely used in the diagnostic workup of acute ischemic stroke (AIS). At present, perfusion imaging can also be performed within the angio suite using flat detector computed tomography (FDCT). However, higher noise level, slower rotation speed and lower frame rate need to be considered in FDCT perfusion (FDCTP) data processing algorithms. The Time Separation Technique (TST) is a model-based perfusion data reconstruction method developed to solve these problems. In this contribution, we used TST and dimension reduction, where we approximate the time attenuation curves by a linear combination of trigonometric functions. Our goal was to show that TST with this data reduction does not impair clinical perfusion measurements. We performed a realistic simulation of FDCTP acquisition based on CT perfusion (CTP) data. Using these FDCTP data, we showed that TST provides better results than classical straightforward processing. Moreover we found that TST is robust to additional noise. Furthermore, we achieved a total processing time from reconstruction of FDCTP data to generation of perfusion maps of under 5 minutes. Perfusion maps created using TST with a trigonometric basis from FDCTP data show equivalent perfusion deficits as CT perfusion maps. Therefore, this technique can be considered a fast reliable tool for FDCTP imaging in AIS.
AutoDiCE: Fully Automated Distributed CNN Inference at the Edge
Jul 20, 2022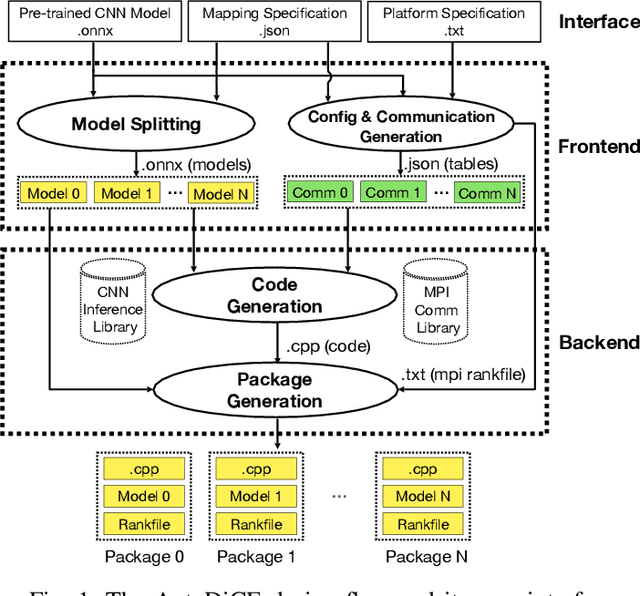
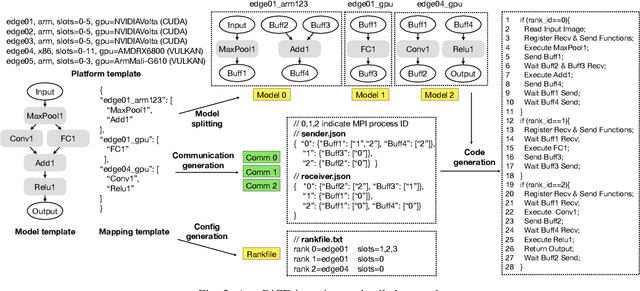
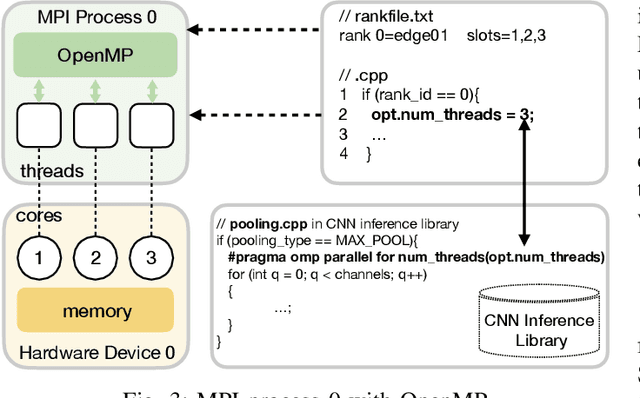
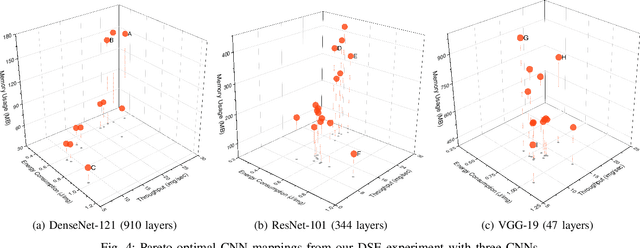
Deep Learning approaches based on Convolutional Neural Networks (CNNs) are extensively utilized and very successful in a wide range of application areas, including image classification and speech recognition. For the execution of trained CNNs, i.e. model inference, we nowadays witness a shift from the Cloud to the Edge. Unfortunately, deploying and inferring large, compute and memory intensive CNNs on edge devices is challenging because these devices typically have limited power budgets and compute/memory resources. One approach to address this challenge is to leverage all available resources across multiple edge devices to deploy and execute a large CNN by properly partitioning the CNN and running each CNN partition on a separate edge device. Although such distribution, deployment, and execution of large CNNs on multiple edge devices is a desirable and beneficial approach, there currently does not exist a design and programming framework that takes a trained CNN model, together with a CNN partitioning specification, and fully automates the CNN model splitting and deployment on multiple edge devices to facilitate distributed CNN inference at the Edge. Therefore, in this paper, we propose a novel framework, called AutoDiCE, for automated splitting of a CNN model into a set of sub-models and automated code generation for distributed and collaborative execution of these sub-models on multiple, possibly heterogeneous, edge devices, while supporting the exploitation of parallelism among and within the edge devices. Our experimental results show that AutoDiCE can deliver distributed CNN inference with reduced energy consumption and memory usage per edge device, and improved overall system throughput at the same time.