 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Commonsense Ontology Micropatterns
Feb 28, 2024
The previously introduced Modular Ontology Modeling methodology (MOMo) attempts to mimic the human analogical process by using modular patterns to assemble more complex concepts. To support this, MOMo organizes organizes ontology design patterns into design libraries, which are programmatically queryable, to support accelerated ontology development, for both human and automated processes. However, a major bottleneck to large-scale deployment of MOMo is the (to-date) limited availability of ready-to-use ontology design patterns. At the same time, Large Language Models have quickly become a source of common knowledge and, in some cases, replacing search engines for questions. In this paper, we thus present a collection of 104 ontology design patterns representing often occurring nouns, curated from the common-sense knowledge available in LLMs, organized into a fully-annotated modular ontology design library ready for use with MOMo.
Conformer: Embedding Continuous Attention in Vision Transformer for Weather Forecasting
Feb 28, 2024Operational weather forecasting system relies on computationally expensive physics-based models. Although Transformers-based models have shown remarkable potential in weather forecasting, Transformers are discrete models which limit their ability to learn the continuous spatio-temporal features of the dynamical weather system. We address this issue with Conformer, a spatio-temporal Continuous Vision Transformer for weather forecasting. Conformer is designed to learn the continuous weather evolution over time by implementing continuity in the multi-head attention mechanism. The attention mechanism is encoded as a differentiable function in the transformer architecture to model the complex weather dynamics. We evaluate Conformer against a state-of-the-art Numerical Weather Prediction (NWP) model and several deep learning based weather forecasting models. Conformer outperforms some of the existing data-driven models at all lead times while only being trained at lower resolution data.
Phase autoencoder for limit-cycle oscillators
Feb 28, 2024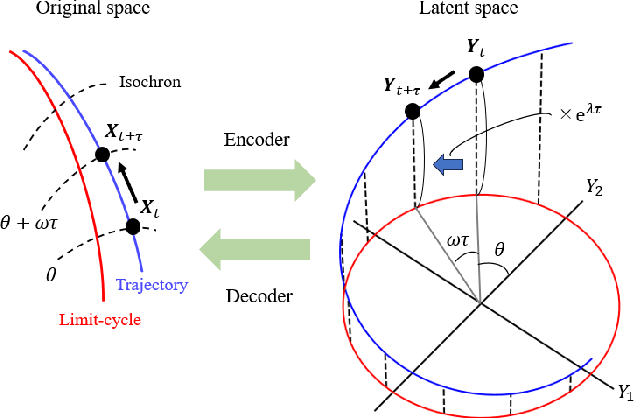
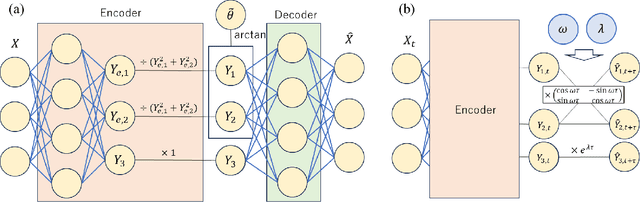
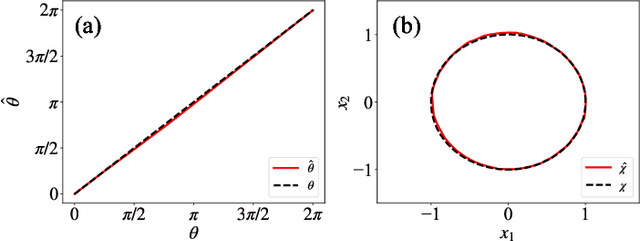
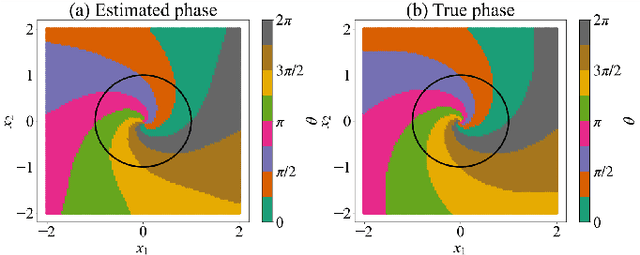
We present a phase autoencoder that encodes the asymptotic phase of a limit-cycle oscillator, a fundamental quantity characterizing its synchronization dynamics. This autoencoder is trained in such a way that its latent variables directly represent the asymptotic phase of the oscillator. The trained autoencoder can perform two functions without relying on the mathematical model of the oscillator: first, it can evaluate the asymptotic phase and phase sensitivity function of the oscillator; second, it can reconstruct the oscillator state on the limit cycle in the original space from the phase value as an input. Using several examples of limit-cycle oscillators, we demonstrate that the asymptotic phase and phase sensitivity function can be estimated only from time-series data by the trained autoencoder. We also present a simple method for globally synchronizing two oscillators as an application of the trained autoencoder.
Revisiting VAE for Unsupervised Time Series Anomaly Detection: A Frequency Perspective
Feb 05, 2024Time series Anomaly Detection (AD) plays a crucial role for web systems. Various web systems rely on time series data to monitor and identify anomalies in real time, as well as to initiate diagnosis and remediation procedures. Variational Autoencoders (VAEs) have gained popularity in recent decades due to their superior de-noising capabilities, which are useful for anomaly detection. However, our study reveals that VAE-based methods face challenges in capturing long-periodic heterogeneous patterns and detailed short-periodic trends simultaneously. To address these challenges, we propose Frequency-enhanced Conditional Variational Autoencoder (FCVAE), a novel unsupervised AD method for univariate time series. To ensure an accurate AD, FCVAE exploits an innovative approach to concurrently integrate both the global and local frequency features into the condition of Conditional Variational Autoencoder (CVAE) to significantly increase the accuracy of reconstructing the normal data. Together with a carefully designed "target attention" mechanism, our approach allows the model to pick the most useful information from the frequency domain for better short-periodic trend construction. Our FCVAE has been evaluated on public datasets and a large-scale cloud system, and the results demonstrate that it outperforms state-of-the-art methods. This confirms the practical applicability of our approach in addressing the limitations of current VAE-based anomaly detection models.
Learning reduced-order Quadratic-Linear models in Process Engineering using Operator Inference
Feb 27, 2024In this work, we address the challenge of efficiently modeling dynamical systems in process engineering. We use reduced-order model learning, specifically operator inference. This is a non-intrusive, data-driven method for learning dynamical systems from time-domain data. The application in our study is carbon dioxide methanation, an important reaction within the Power-to-X framework, to demonstrate its potential. The numerical results show the ability of the reduced-order models constructed with operator inference to provide a reduced yet accurate surrogate solution. This represents an important milestone towards the implementation of fast and reliable digital twin architectures.
Parallelized Spatiotemporal Binding
Feb 26, 2024While modern best practices advocate for scalable architectures that support long-range interactions, object-centric models are yet to fully embrace these architectures. In particular, existing object-centric models for handling sequential inputs, due to their reliance on RNN-based implementation, show poor stability and capacity and are slow to train on long sequences. We introduce Parallelizable Spatiotemporal Binder or PSB, the first temporally-parallelizable slot learning architecture for sequential inputs. Unlike conventional RNN-based approaches, PSB produces object-centric representations, known as slots, for all time-steps in parallel. This is achieved by refining the initial slots across all time-steps through a fixed number of layers equipped with causal attention. By capitalizing on the parallelism induced by our architecture, the proposed model exhibits a significant boost in efficiency. In experiments, we test PSB extensively as an encoder within an auto-encoding framework paired with a wide variety of decoder options. Compared to the state-of-the-art, our architecture demonstrates stable training on longer sequences, achieves parallelization that results in a 60% increase in training speed, and yields performance that is on par with or better on unsupervised 2D and 3D object-centric scene decomposition and understanding.
Scalable Robust Sparse Principal Component Analysis
Feb 26, 2024In this work, we propose an optimization framework for estimating a sparse robust one-dimensional subspace. Our objective is to minimize both the representation error and the penalty, in terms of the l1-norm criterion. Given that the problem is NP-hard, we introduce a linear relaxation-based approach. Additionally, we present a novel fitting procedure, utilizing simple ratios and sorting techniques. The proposed algorithm demonstrates a worst-case time complexity of $O(n^2 m \log n)$ and, in certain instances, achieves global optimality for the sparse robust subspace, thereby exhibiting polynomial time efficiency. Compared to extant methodologies, the proposed algorithm finds the subspace with the lowest discordance, offering a smoother trade-off between sparsity and fit. Its architecture affords scalability, evidenced by a 16-fold improvement in computational speeds for matrices of 2000x2000 over CPU version. Furthermore, this method is distinguished by several advantages, including its independence from initialization and deterministic and replicable procedures. Furthermore, this method is distinguished by several advantages, including its independence from initialization and deterministic and replicable procedures. The real-world example demonstrates the effectiveness of algorithm in achieving meaningful sparsity, underscoring its precise and useful application across various domains.
Contingency Planning Using Bi-level Markov Decision Processes for Space Missions
Feb 26, 2024This work focuses on autonomous contingency planning for scientific missions by enabling rapid policy computation from any off-nominal point in the state space in the event of a delay or deviation from the nominal mission plan. Successful contingency planning involves managing risks and rewards, often probabilistically associated with actions, in stochastic scenarios. Markov Decision Processes (MDPs) are used to mathematically model decision-making in such scenarios. However, in the specific case of planetary rover traverse planning, the vast action space and long planning time horizon pose computational challenges. A bi-level MDP framework is proposed to improve computational tractability, while also aligning with existing mission planning practices and enhancing explainability and trustworthiness of AI-driven solutions. We discuss the conversion of a mission planning MDP into a bi-level MDP, and test the framework on RoverGridWorld, a modified GridWorld environment for rover mission planning. We demonstrate the computational tractability and near-optimal policies achievable with the bi-level MDP approach, highlighting the trade-offs between compute time and policy optimality as the problem's complexity grows. This work facilitates more efficient and flexible contingency planning in the context of scientific missions.
Parallel Hyperparameter Optimization Of Spiking Neural Network
Mar 01, 2024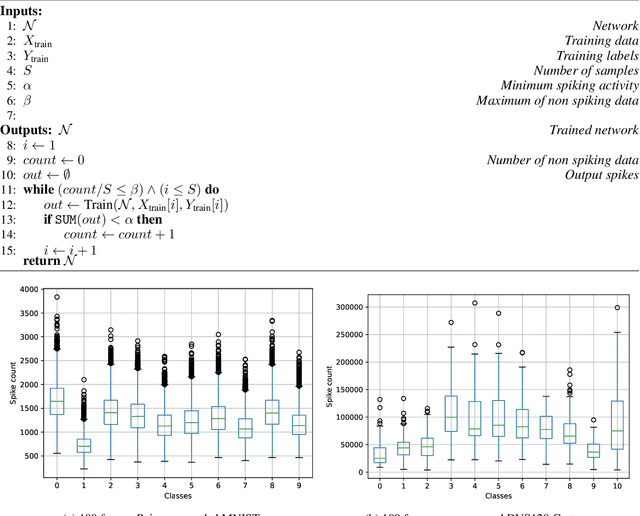
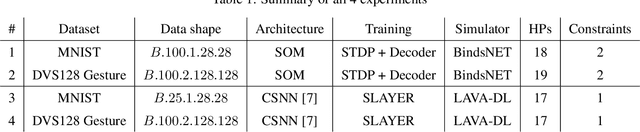
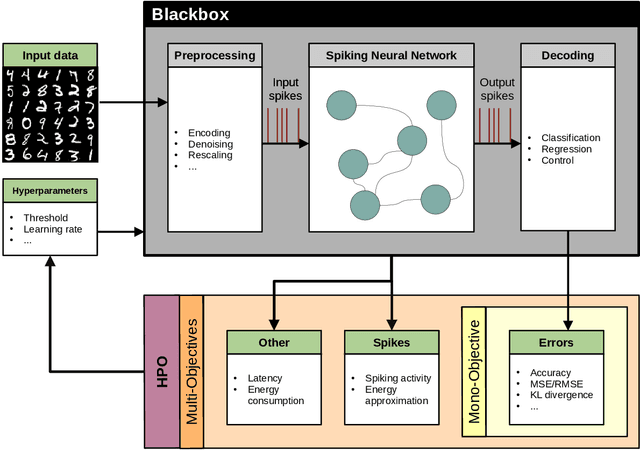
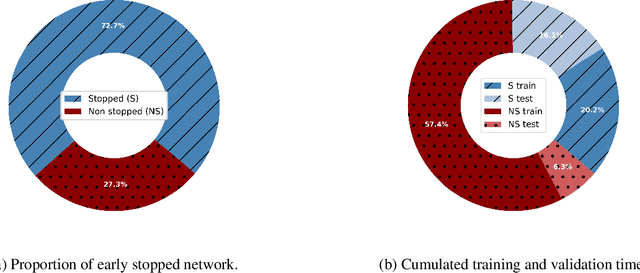
Spiking Neural Networks (SNN). SNNs are based on a more biologically inspired approach than usual artificial neural networks. Such models are characterized by complex dynamics between neurons and spikes. These are very sensitive to the hyperparameters, making their optimization challenging. To tackle hyperparameter optimization of SNNs, we initially extended the signal loss issue of SNNs to what we call silent networks. These networks fail to emit enough spikes at their outputs due to mistuned hyperparameters or architecture. Generally, search spaces are heavily restrained, sometimes even discretized, to prevent the sampling of such networks. By defining an early stopping criterion detecting silent networks and by designing specific constraints, we were able to instantiate larger and more flexible search spaces. We applied a constrained Bayesian optimization technique, which was asynchronously parallelized, as the evaluation time of a SNN is highly stochastic. Large-scale experiments were carried-out on a multi-GPU Petascale architecture. By leveraging silent networks, results show an acceleration of the search, while maintaining good performances of both the optimization algorithm and the best solution obtained. We were able to apply our methodology to two popular training algorithms, known as spike timing dependent plasticity and surrogate gradient. Early detection allowed us to prevent worthless and costly computation, directing the search toward promising hyperparameter combinations. Our methodology could be applied to multi-objective problems, where the spiking activity is often minimized to reduce the energy consumption. In this scenario, it becomes essential to find the delicate frontier between low-spiking and silent networks. Finally, our approach may have implications for neural architecture search, particularly in defining suitable spiking architectures.
SubGen: Token Generation in Sublinear Time and Memory
Feb 08, 2024Despite the significant success of large language models (LLMs), their extensive memory requirements pose challenges for deploying them in long-context token generation. The substantial memory footprint of LLM decoders arises from the necessity to store all previous tokens in the attention module, a requirement imposed by key-value (KV) caching. In this work, our focus is on developing an efficient compression technique for the KV cache. Empirical evidence indicates a significant clustering tendency within key embeddings in the attention module. Building on this key insight, we have devised a novel caching method with sublinear complexity, employing online clustering on key tokens and online $\ell_2$ sampling on values. The result is a provably accurate and efficient attention decoding algorithm, termed SubGen. Not only does this algorithm ensure a sublinear memory footprint and sublinear time complexity, but we also establish a tight error bound for our approach. Empirical evaluations on long-context question-answering tasks demonstrate that SubGen significantly outperforms existing and state-of-the-art KV cache compression methods in terms of performance and efficiency.