 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlight Validation of Learning-Based Trajectory Optimization for the Astrobee Free-Flyer
May 08, 2025Although widely used in commercial and industrial robotics, trajectory optimization has seen limited use in space applications due to its high computational demands. In this work, we present flight results from experiments with the Astrobee free-flying robot on board the International Space Station (ISS), that demonstrate how machine learning can accelerate on-board trajectory optimization while preserving theoretical solver guarantees. To the best of the authors' knowledge, this is the first-ever demonstration of learning-based control on the ISS. Our approach leverages the GuSTO sequential convex programming framework and uses a neural network, trained offline, to map problem parameters to effective initial ``warm-start'' trajectories, paving the way for faster real-time optimization on resource-constrained space platforms.
Adapting a Foundation Model for Space-based Tasks
Aug 12, 2024



Foundation models, e.g., large language models, possess attributes of intelligence which offer promise to endow a robot with the contextual understanding necessary to navigate complex, unstructured tasks in the wild. In the future of space robotics, we see three core challenges which motivate the use of a foundation model adapted to space-based applications: 1) Scalability of ground-in-the-loop operations; 2) Generalizing prior knowledge to novel environments; and 3) Multi-modality in tasks and sensor data. Therefore, as a first-step towards building a foundation model for space-based applications, we automatically label the AI4Mars dataset to curate a language annotated dataset of visual-question-answer tuples. We fine-tune a pretrained LLaVA checkpoint on this dataset to endow a vision-language model with the ability to perform spatial reasoning and navigation on Mars' surface. In this work, we demonstrate that 1) existing vision-language models are deficient visual reasoners in space-based applications, and 2) fine-tuning a vision-language model on extraterrestrial data significantly improves the quality of responses even with a limited training dataset of only a few thousand samples.
Diagnostic Runtime Monitoring with Martingales
Jul 31, 2024Machine learning systems deployed in safety-critical robotics settings must be robust to distribution shifts. However, system designers must understand the cause of a distribution shift in order to implement the appropriate intervention or mitigation strategy and prevent system failure. In this paper, we present a novel framework for diagnosing distribution shifts in a streaming fashion by deploying multiple stochastic martingales simultaneously. We show that knowledge of the underlying cause of a distribution shift can lead to proper interventions over the lifecycle of a deployed system. Our experimental framework can easily be adapted to different types of distribution shifts, models, and datasets. We find that our method outperforms existing work on diagnosing distribution shifts in terms of speed, accuracy, and flexibility, and validate the efficiency of our model in both simulated and live hardware settings.
Contingency Planning Using Bi-level Markov Decision Processes for Space Missions
Feb 26, 2024



This work focuses on autonomous contingency planning for scientific missions by enabling rapid policy computation from any off-nominal point in the state space in the event of a delay or deviation from the nominal mission plan. Successful contingency planning involves managing risks and rewards, often probabilistically associated with actions, in stochastic scenarios. Markov Decision Processes (MDPs) are used to mathematically model decision-making in such scenarios. However, in the specific case of planetary rover traverse planning, the vast action space and long planning time horizon pose computational challenges. A bi-level MDP framework is proposed to improve computational tractability, while also aligning with existing mission planning practices and enhancing explainability and trustworthiness of AI-driven solutions. We discuss the conversion of a mission planning MDP into a bi-level MDP, and test the framework on RoverGridWorld, a modified GridWorld environment for rover mission planning. We demonstrate the computational tractability and near-optimal policies achievable with the bi-level MDP approach, highlighting the trade-offs between compute time and policy optimality as the problem's complexity grows. This work facilitates more efficient and flexible contingency planning in the context of scientific missions.
A System-Level View on Out-of-Distribution Data in Robotics
Dec 28, 2022When testing conditions differ from those represented in training data, so-called out-of-distribution (OOD) inputs can mar the reliability of black-box learned components in the modern robot autonomy stack. Therefore, coping with OOD data is an important challenge on the path towards trustworthy learning-enabled open-world autonomy. In this paper, we aim to demystify the topic of OOD data and its associated challenges in the context of data-driven robotic systems, drawing connections to emerging paradigms in the ML community that study the effect of OOD data on learned models in isolation. We argue that as roboticists, we should reason about the overall system-level competence of a robot as it performs tasks in OOD conditions. We highlight key research questions around this system-level view of OOD problems to guide future research toward safe and reliable learning-enabled autonomy.
Data Lifecycle Management in Evolving Input Distributions for Learning-based Aerospace Applications
Sep 24, 2022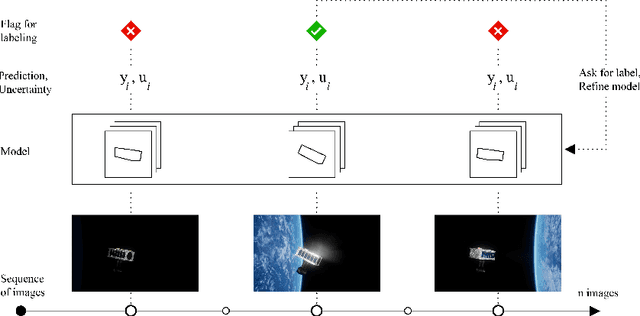

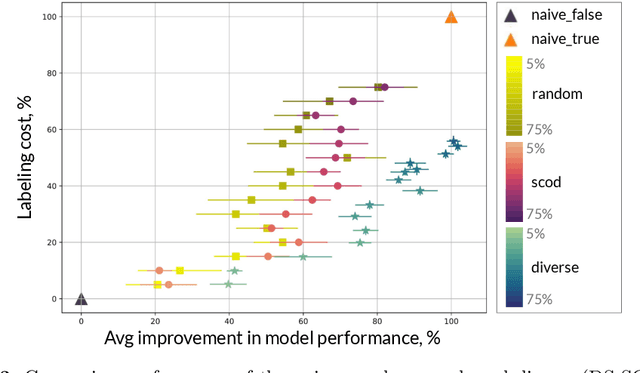
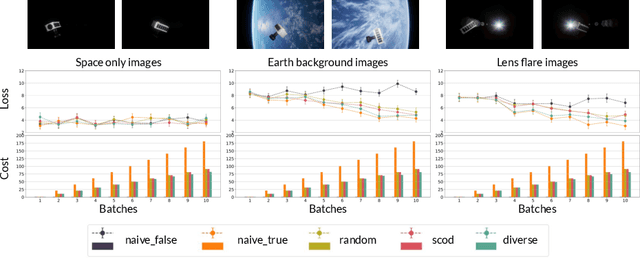
As input distributions evolve over a mission lifetime, maintaining performance of learning-based models becomes challenging. This paper presents a framework to incrementally retrain a model by selecting a subset of test inputs to label, which allows the model to adapt to changing input distributions. Algorithms within this framework are evaluated based on (1) model performance throughout mission lifetime and (2) cumulative costs associated with labeling and model retraining. We provide an open-source benchmark of a satellite pose estimation model trained on images of a satellite in space and deployed in novel scenarios (e.g., different backgrounds or misbehaving pixels), where algorithms are evaluated on their ability to maintain high performance by retraining on a subset of inputs. We also propose a novel algorithm to select a diverse subset of inputs for labeling, by characterizing the information gain from an input using Bayesian uncertainty quantification and choosing a subset that maximizes collective information gain using concepts from batch active learning. We show that our algorithm outperforms others on the benchmark, e.g., achieves comparable performance to an algorithm that labels 100% of inputs, while only labeling 50% of inputs, resulting in low costs and high performance over the mission lifetime.