 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Formalizing and Evaluating Requirements of Perception Systems for Automated Vehicles using Spatio-Temporal Perception Logic
Jun 29, 2022
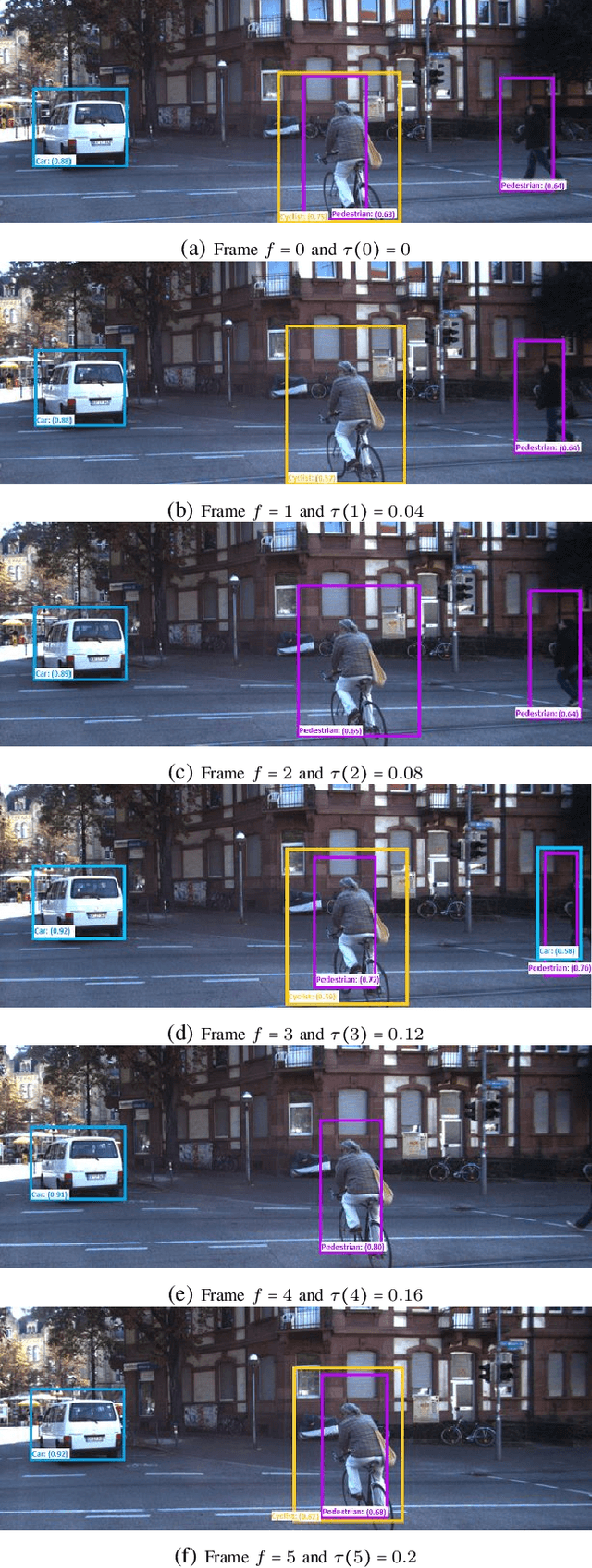


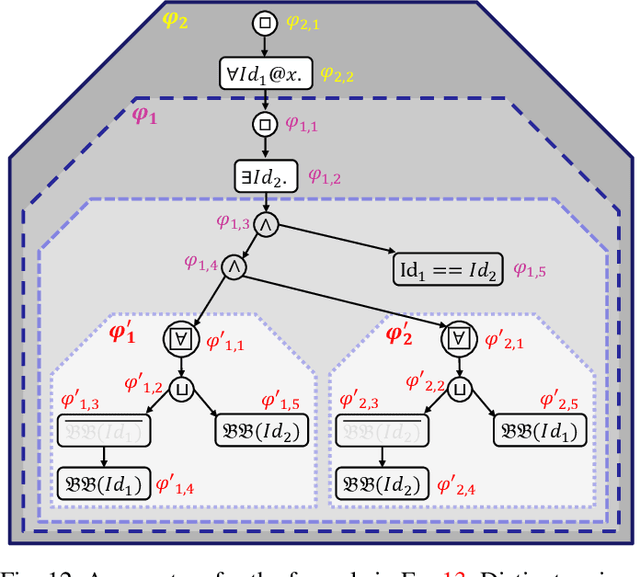
Automated vehicles (AV) heavily depend on robust perception systems. Current methods for evaluating vision systems focus mainly on frame-by-frame performance. Such evaluation methods appear to be inadequate in assessing the performance of a perception subsystem when used within an AV. In this paper, we present a logic -- referred to as Spatio-Temporal Perception Logic (STPL) -- which utilizes both spatial and temporal modalities. STPL enables reasoning over perception data using spatial and temporal relations. One major advantage of STPL is that it facilitates basic sanity checks on the real-time performance of the perception system, even without ground-truth data in some cases. We identify a fragment of STPL which is efficiently monitorable offline in polynomial time. Finally, we present a range of specifications for AV perception systems to highlight the types of requirements that can be expressed and analyzed through offline monitoring with STPL.
Diagnosing and Remedying Shot Sensitivity with Cosine Few-Shot Learners
Jul 07, 2022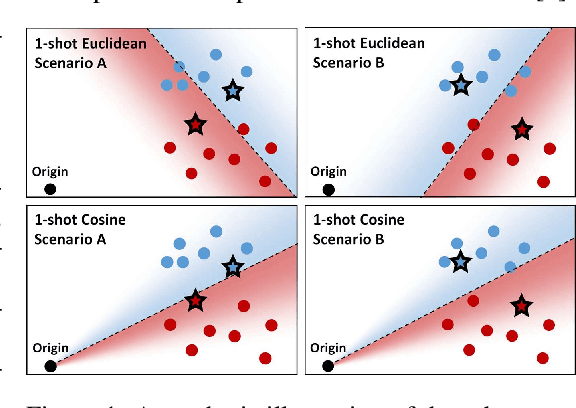
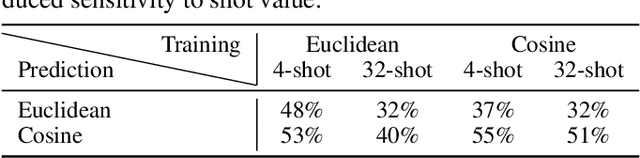
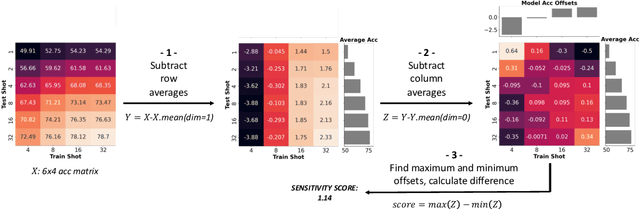
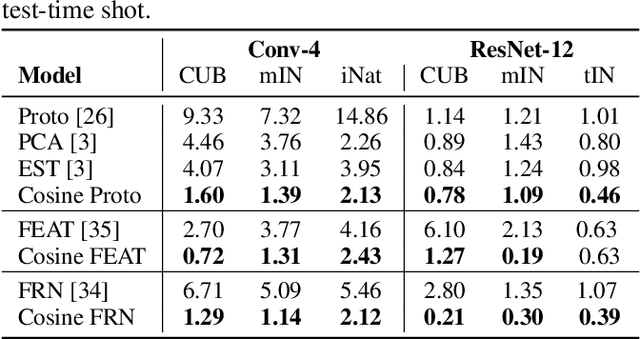
Few-shot recognition involves training an image classifier to distinguish novel concepts at test time using few examples (shot). Existing approaches generally assume that the shot number at test time is known in advance. This is not realistic, and the performance of a popular and foundational method has been shown to suffer when train and test shots do not match. We conduct a systematic empirical study of this phenomenon. In line with prior work, we find that shot sensitivity is broadly present across metric-based few-shot learners, but in contrast to prior work, larger neural architectures provide a degree of built-in robustness to varying test shot. More importantly, a simple, previously known but greatly overlooked class of approaches based on cosine distance consistently and greatly improves robustness to shot variation, by removing sensitivity to sample noise. We derive cosine alternatives to popular and recent few-shot classifiers, broadening their applicability to realistic settings. These cosine models consistently improve shot-robustness, outperform prior shot-robust state of the art, and provide competitive accuracy on a range of benchmarks and architectures, including notable gains in the very-low-shot regime.
Mobility State Detection of Cellular-Connected UAVs based on Handover Count Statistics
Jun 27, 2022
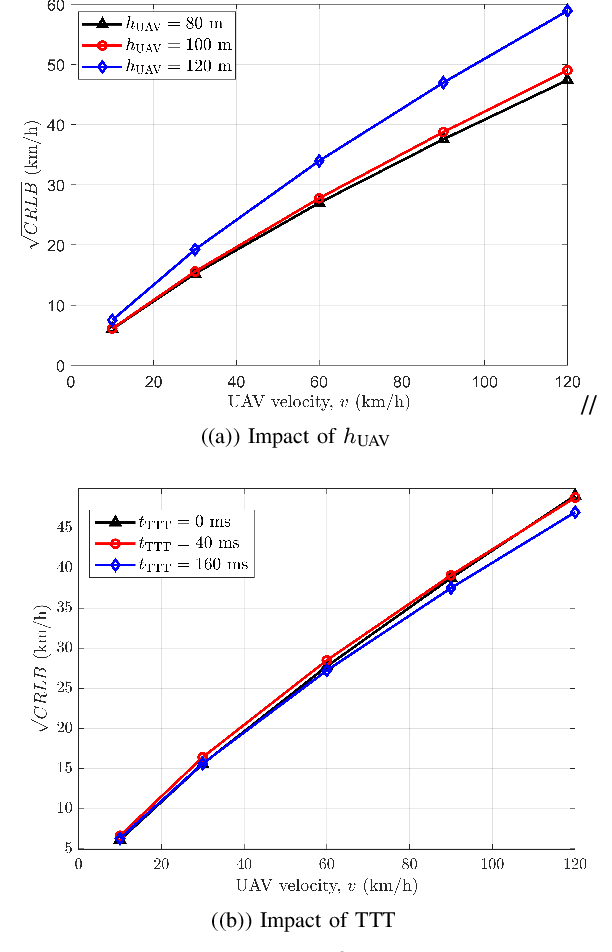
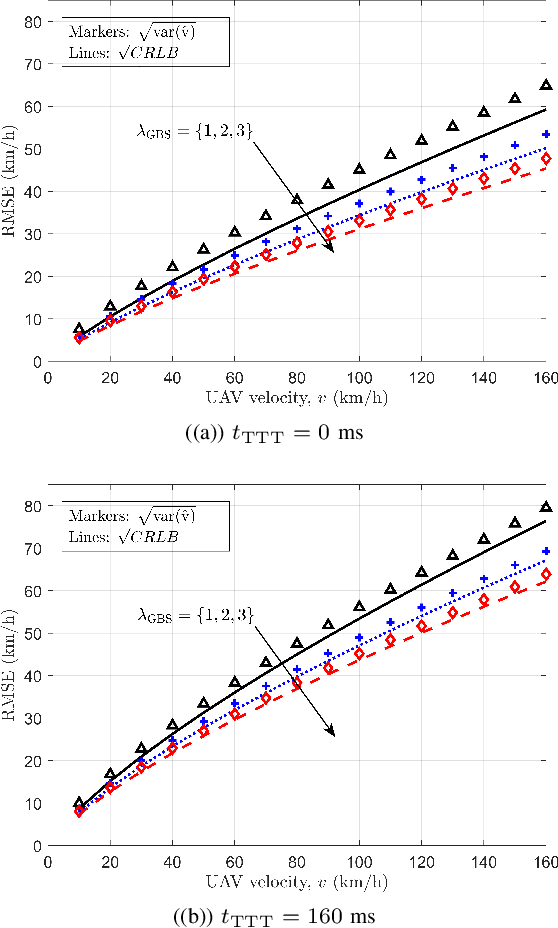
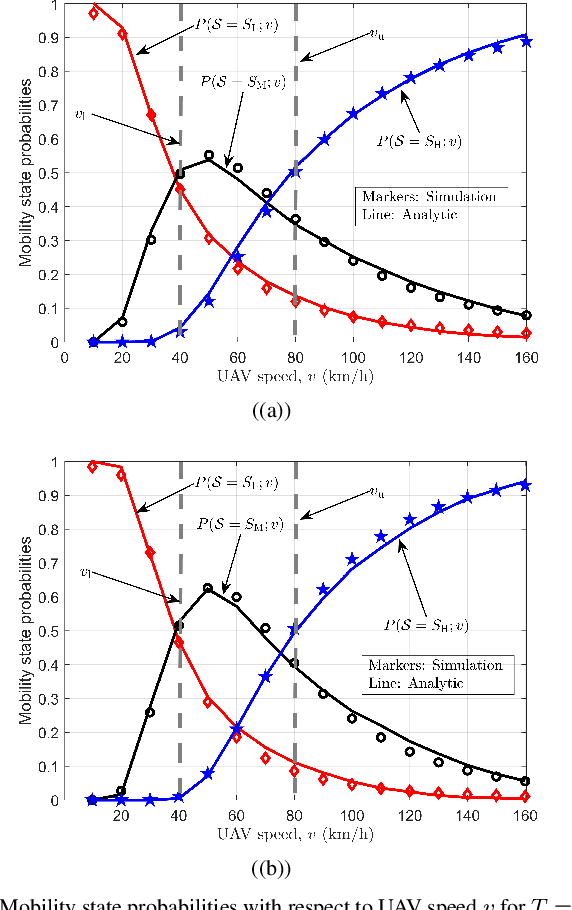
To ensure reliable and effective mobility management for aerial user equipment (UE), estimating the speed of cellular-connected unmanned aerial vehicles (UAVs) carries critical importance since this can help to improve the quality of service of the cellular network. The 3GPP LTE standard uses the number of handovers made by a UE during a predefined time period to estimate the speed and the mobility state efficiently. In this paper, we introduce an approximation to the probability mass function of handover count (HOC) as a function of a cellular-connected UAV's height and velocity, HOC measurement time window, and different ground base station (GBS) densities. Afterward, we derive the Cramer-Rao lower bound (CRLB) for the speed estimate of a UAV, and also provide a simple biased estimator for the UAV's speed which depends on the GBS density and HOC measurement period. Interestingly, for a low time-to-trigger (TTT) parameter, the biased estimator turns into a minimum variance unbiased estimator (MVUE). By exploiting this speed estimator, we study the problem of detecting the mobility state of a UAV as low, medium, or high mobility as per the LTE specifications. Using CRLBs and our proposed MVUE, we characterize the accuracy improvement in speed estimation and mobility state detection as the GBS density and the HOC measurement window increase. Our analysis also shows that the accuracy of the proposed estimator does not vary significantly with respect to the TTT parameter.
Analysis of Quality Diversity Algorithms for the Knapsack Problem
Jul 28, 2022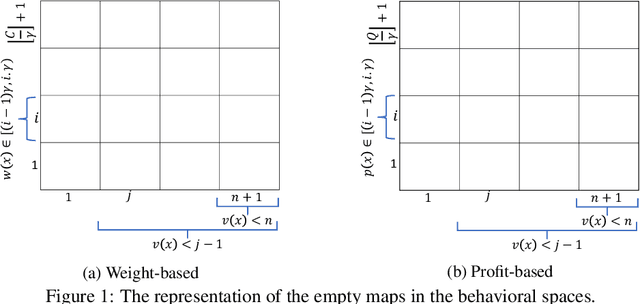

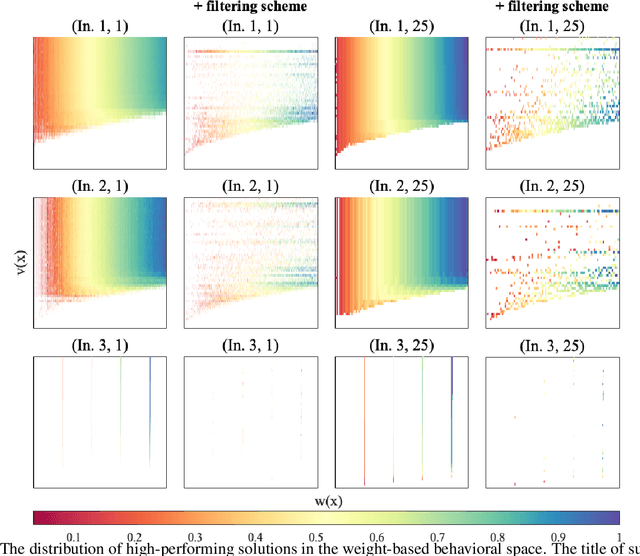

Quality diversity (QD) algorithms have been shown to be very successful when dealing with problems in areas such as robotics, games and combinatorial optimization. They aim to maximize the quality of solutions for different regions of the so-called behavioural space of the underlying problem. In this paper, we apply the QD paradigm to simulate dynamic programming behaviours on knapsack problem, and provide a first runtime analysis of QD algorithms. We show that they are able to compute an optimal solution within expected pseudo-polynomial time, and reveal parameter settings that lead to a fully polynomial randomised approximation scheme (FPRAS). Our experimental investigations evaluate the different approaches on classical benchmark sets in terms of solutions constructed in the behavioural space as well as the runtime needed to obtain an optimal solution.
StarVQA: Space-Time Attention for Video Quality Assessment
Aug 22, 2021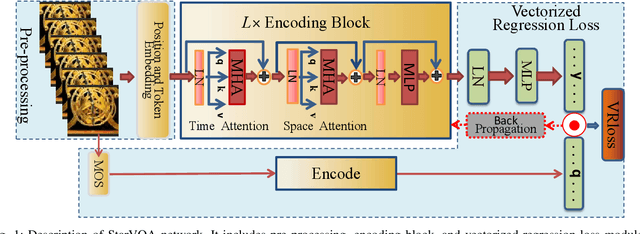
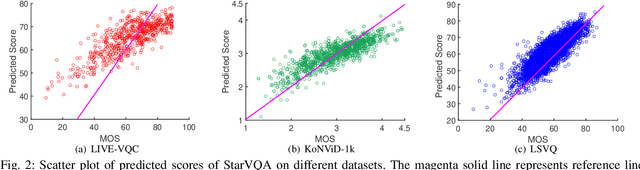
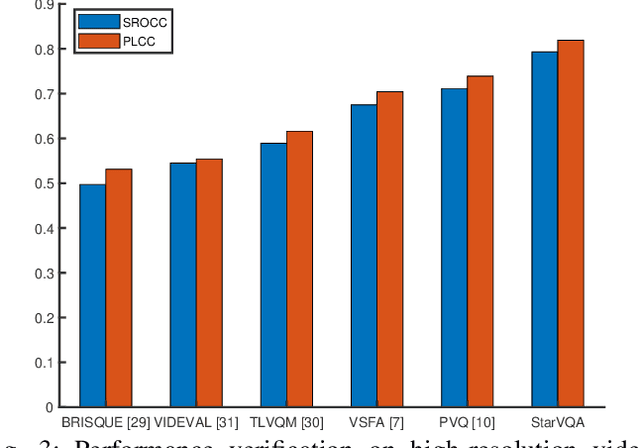
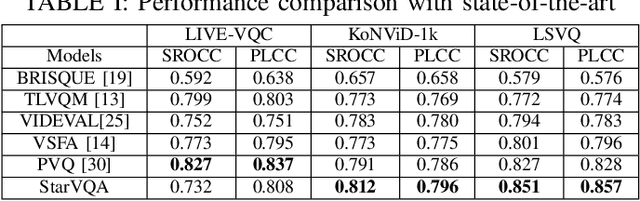
The attention mechanism is blooming in computer vision nowadays. However, its application to video quality assessment (VQA) has not been reported. Evaluating the quality of in-the-wild videos is challenging due to the unknown of pristine reference and shooting distortion. This paper presents a novel \underline{s}pace-\underline{t}ime \underline{a}ttention network fo\underline{r} the \underline{VQA} problem, named StarVQA. StarVQA builds a Transformer by alternately concatenating the divided space-time attention. To adapt the Transformer architecture for training, StarVQA designs a vectorized regression loss by encoding the mean opinion score (MOS) to the probability vector and embedding a special vectorized label token as the learnable variable. To capture the long-range spatiotemporal dependencies of a video sequence, StarVQA encodes the space-time position information of each patch to the input of the Transformer. Various experiments are conducted on the de-facto in-the-wild video datasets, including LIVE-VQC, KoNViD-1k, LSVQ, and LSVQ-1080p. Experimental results demonstrate the superiority of the proposed StarVQA over the state-of-the-art. Code and model will be available at: https://github.com/DVL/StarVQA.
Cross Attention Based Style Distribution for Controllable Person Image Synthesis
Aug 01, 2022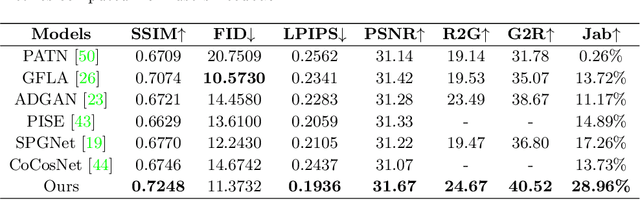
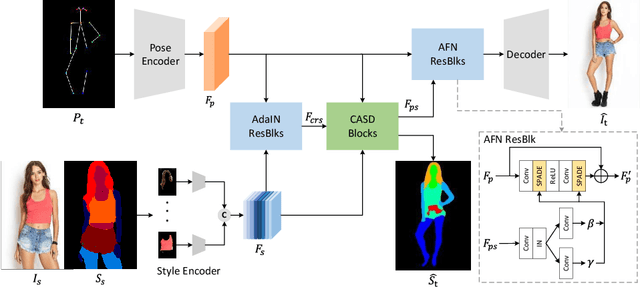
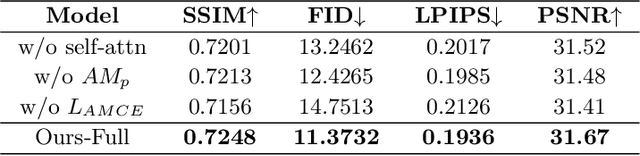
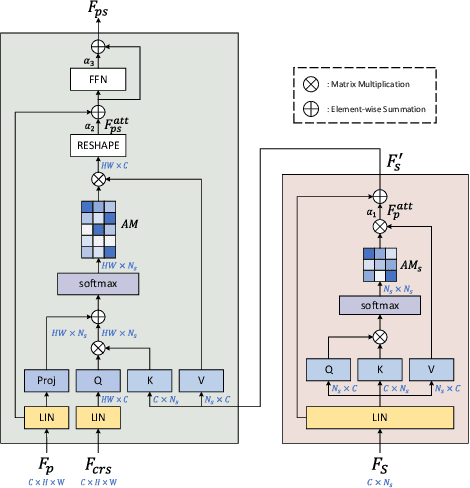
Controllable person image synthesis task enables a wide range of applications through explicit control over body pose and appearance. In this paper, we propose a cross attention based style distribution module that computes between the source semantic styles and target pose for pose transfer. The module intentionally selects the style represented by each semantic and distributes them according to the target pose. The attention matrix in cross attention expresses the dynamic similarities between the target pose and the source styles for all semantics. Therefore, it can be utilized to route the color and texture from the source image, and is further constrained by the target parsing map to achieve a clearer objective. At the same time, to encode the source appearance accurately, the self attention among different semantic styles is also added. The effectiveness of our model is validated quantitatively and qualitatively on pose transfer and virtual try-on tasks.
One-shot Generative Prior Learned from Hankel-k-space for Parallel Imaging Reconstruction
Aug 15, 2022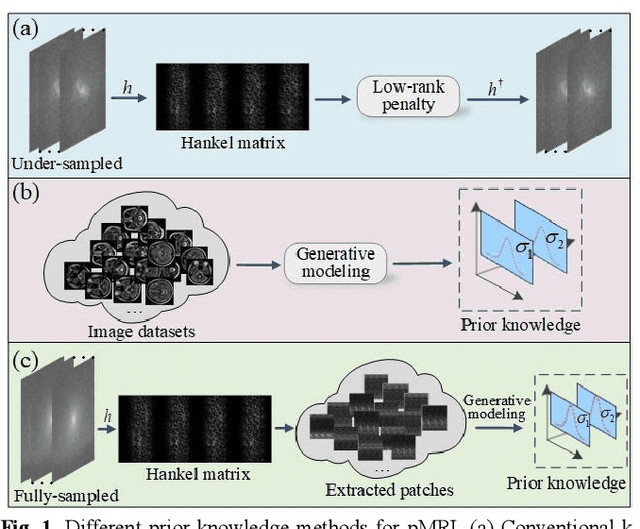
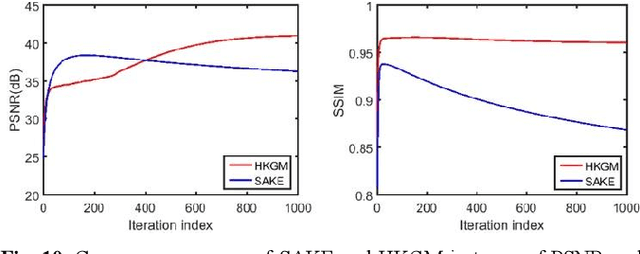
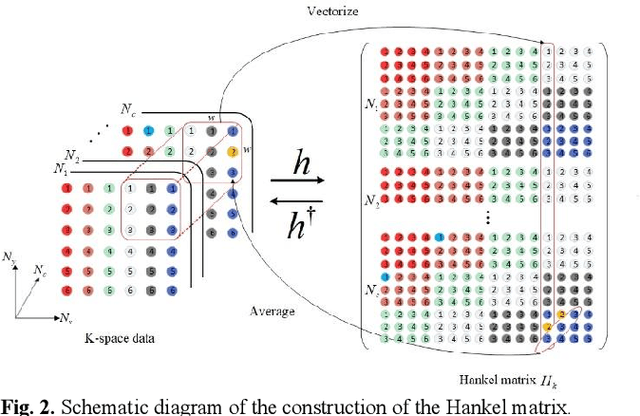
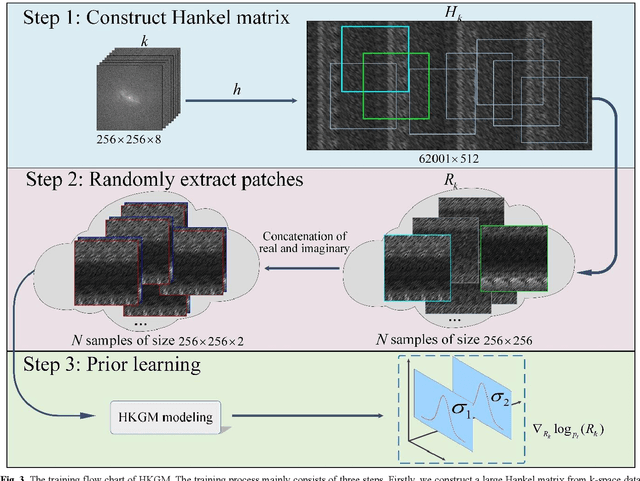
Magnetic resonance imaging serves as an essential tool for clinical diagnosis. However, it suffers from a long acquisition time. The utilization of deep learning, especially the deep generative models, offers aggressive acceleration and better reconstruction in magnetic resonance imaging. Nevertheless, learning the data distribution as prior knowledge and reconstructing the image from limited data remains challenging. In this work, we propose a novel Hankel-k-space generative model (HKGM), which can generate samples from a training set of as little as one k-space data. At the prior learning stage, we first construct a large Hankel matrix from k-space data, then extract multiple structured k-space patches from the large Hankel matrix to capture the internal distribution among different patches. Extracting patches from a Hankel matrix enables the generative model to be learned from redundant and low-rank data space. At the iterative reconstruction stage, it is observed that the desired solution obeys the learned prior knowledge. The intermediate reconstruction solution is updated by taking it as the input of the generative model. The updated result is then alternatively operated by imposing low-rank penalty on its Hankel matrix and data consistency con-strain on the measurement data. Experimental results confirmed that the internal statistics of patches within a single k-space data carry enough information for learning a powerful generative model and provide state-of-the-art reconstruction.
A Survey on Chirp Spread Spectrum-based Waveform Design for IoT
Aug 22, 2022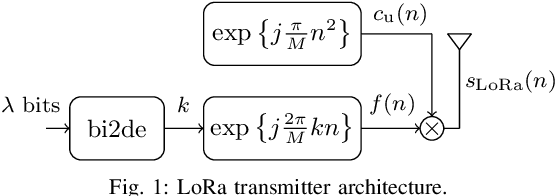
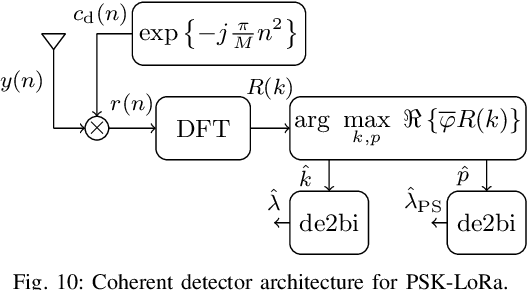
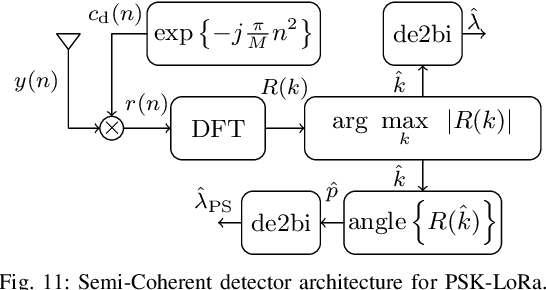
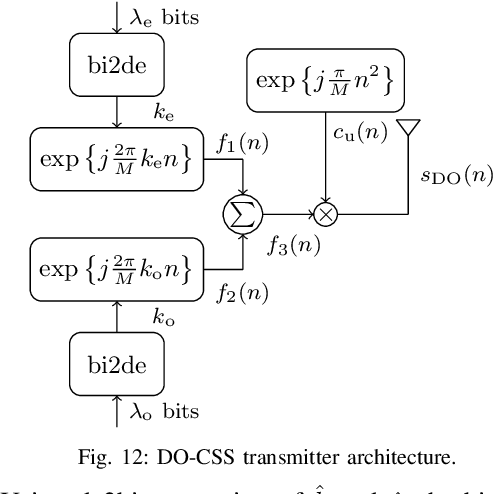
Long Range (LoRa) is one of the most promising and widespread chirp spread spectrum (CSS)-based physical (PHY) layer technique for low-power wide-area networks (LPWANs). Using different spreading factors, LoRa can attain different spectral/energy efficiencies, and can target multitude of Internet-of-Thing (IoT) applications. However, one of the limiting factors for LoRa is the low bit rate. Little to no effort has been made in order to improve the achievable rate of LoRa, until recently, when a number of CSS-based PHY layer LoRa alternative are proposed for LPWANs. In this survey, for the first time, we present a comprehensive waveform design of these CSS-based schemes that have been proposed between 2019 to 2022. In total, fifteen alternatives to LoRa are compared. Other survey articles related to LoRa mostly tackle different issues, such as LoRa networking, LoRa deployment in massive IoT networks, and LoRa architectures, etc. This survey, on the other hand, comprehensively elucidates the waveform design of LoRa alternatives. The CSS schemes studied in this survey are divided into single chirp, multiple chirp, and index modulation based on the multiplexing pattern of the chirps. Complete transceiver architecture of these CSS schemes is studied, and performance is evaluated in terms of energy efficiency (EE), spectral efficiency (SE), bit-error rate (BER) performance in additive white Gaussian noise, BER in the presence of phase and frequency offsets. It has been observed that the EE, SE and robustness against the offsets is primarily linked to transmit symbol frame structure. The public versions of the MATLAB codes for the CSS schemes studied in this survey shall be provided to promote reproducible research.
Boosted Embeddings for Time Series Forecasting
Apr 10, 2021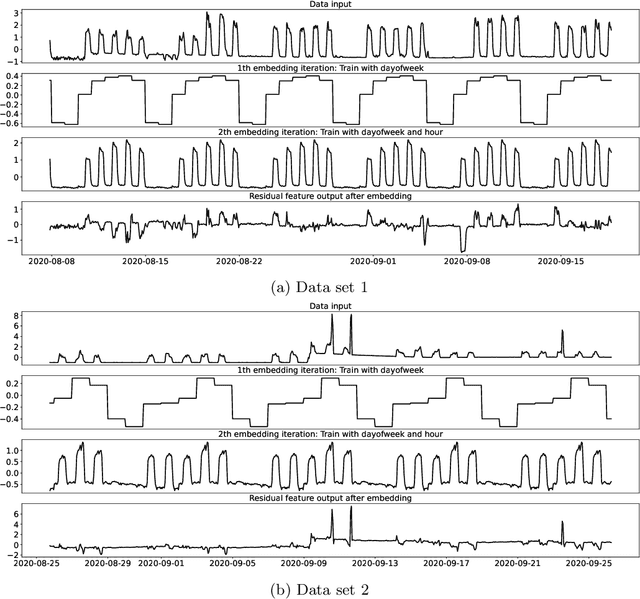

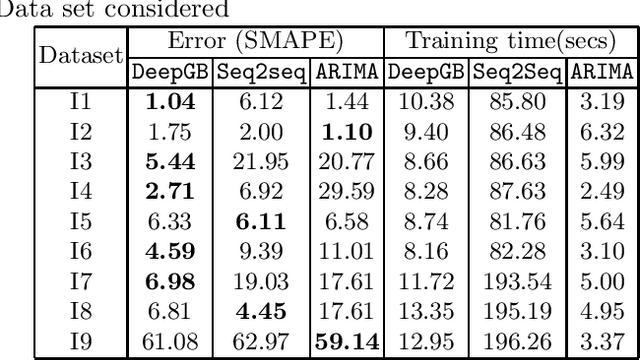
Time series forecasting is a fundamental task emerging from diverse data-driven applications. Many advanced autoregressive methods such as ARIMA were used to develop forecasting models. Recently, deep learning based methods such as DeepAr, NeuralProphet, Seq2Seq have been explored for time series forecasting problem. In this paper, we propose a novel time series forecast model, DeepGB. We formulate and implement a variant of Gradient boosting wherein the weak learners are DNNs whose weights are incrementally found in a greedy manner over iterations. In particular, we develop a new embedding architecture that improves the performance of many deep learning models on time series using Gradient boosting variant. We demonstrate that our model outperforms existing comparable state-of-the-art models using real-world sensor data and public dataset.
Challenges and Complexities in Machine Learning based Credit Card Fraud Detection
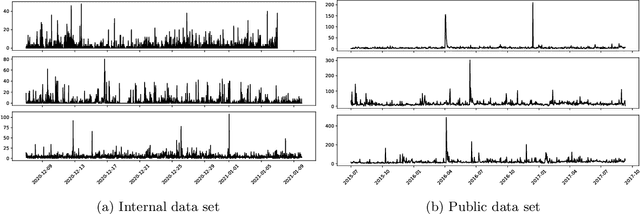
Aug 20, 2022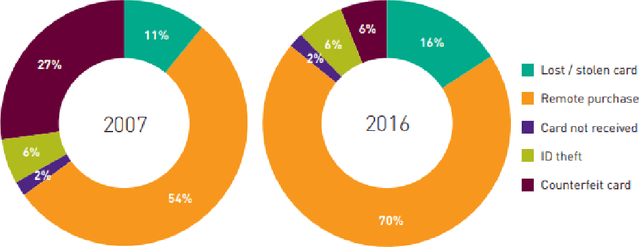

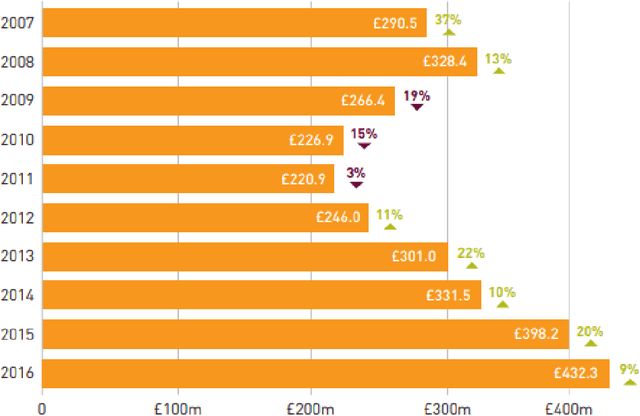

Credit cards play an exploding role in modern economies. Its popularity and ubiquity have created a fertile ground for fraud, assisted by the cross boarder reach and instantaneous confirmation. While transactions are growing, the fraud percentages are also on the rise as well as the true cost of a dollar fraud. Volume of transactions, uniqueness of frauds and ingenuity of the fraudster are main challenges in detecting frauds. The advent of machine learning, artificial intelligence and big data has opened up new tools in the fight against frauds. Given past transactions, a machine learning algorithm has the ability to 'learn' infinitely complex characteristics in order to identify frauds in real-time, surpassing the best human investigators. However, the developments in fraud detection algorithms has been challenging and slow due the massively unbalanced nature of fraud data, absence of benchmarks and standard evaluation metrics to identify better performing classifiers, lack of sharing and disclosure of research findings and the difficulties in getting access to confidential transaction data for research. This work investigates the properties of typical massively imbalanced fraud data sets, their availability, suitability for research use while exploring the widely varying nature of fraud distributions. Furthermore, we show how human annotation errors compound with machine classification errors. We also carry out experiments to determine the effect of PCA obfuscation (as a means of disseminating sensitive transaction data for research and machine learning) on algorithmic performance of classifiers and show that while PCA does not significantly degrade performance, care should be taken to use the appropriate principle component size (dimensions) to avoid overfitting.