 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Pattern Spotting and Image Retrieval in Historical Documents using Deep Hashing
Aug 04, 2022
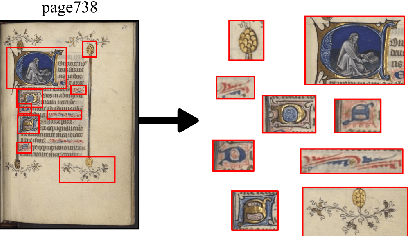
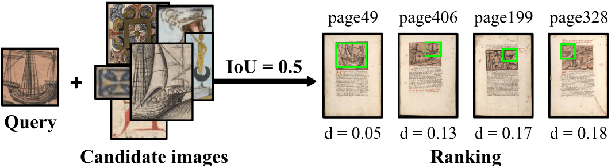


This paper presents a deep learning approach for image retrieval and pattern spotting in digital collections of historical documents. First, a region proposal algorithm detects object candidates in the document page images. Next, deep learning models are used for feature extraction, considering two distinct variants, which provide either real-valued or binary code representations. Finally, candidate images are ranked by computing the feature similarity with a given input query. A robust experimental protocol evaluates the proposed approach considering each representation scheme (real-valued and binary code) on the DocExplore image database. The experimental results show that the proposed deep models compare favorably to the state-of-the-art image retrieval approaches for images of historical documents, outperforming other deep models by 2.56 percentage points using the same techniques for pattern spotting. Besides, the proposed approach also reduces the search time by up to 200x and the storage cost up to 6,000x when compared to related works based on real-valued representations.
On Synchronization of Wireless Acoustic Sensor Networks in the Presence of Time-varying Sampling Rate Offsets and Speaker Changes
Oct 25, 2021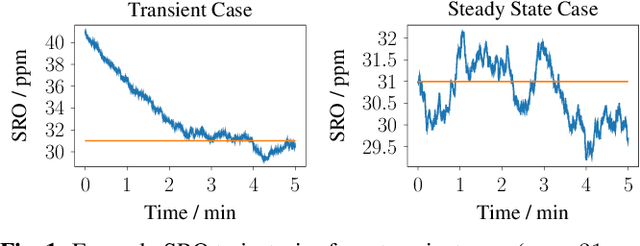
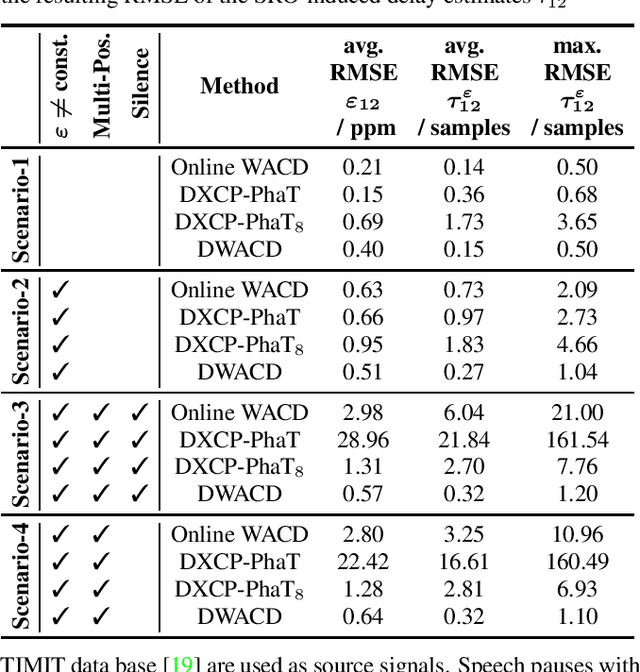
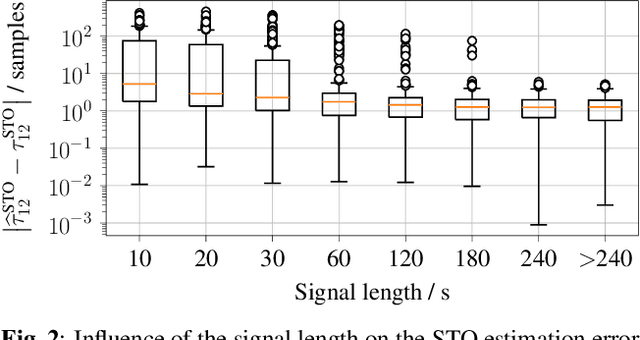
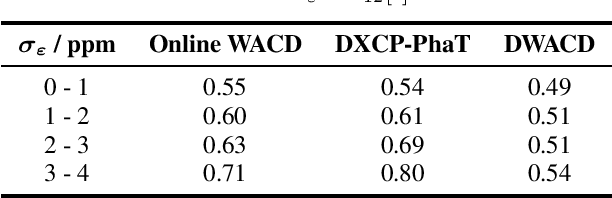
A wireless acoustic sensor network records audio signals with sampling time and sampling rate offsets between the audio streams, if the analog-digital converters (ADCs) of the network devices are not synchronized. Here, we introduce a new sampling rate offset model to simulate time-varying sampling frequencies caused, for example, by temperature changes of ADC crystal oscillators, and propose an estimation algorithm to handle this dynamic aspect in combination with changing acoustic source positions. Furthermore, we show how deep neural network based estimates of the distances between microphones and human speakers can be used to determine the sampling time offsets. This enables a synchronization of the audio streams to reflect the physical time differences of flight.
Pose-based Tremor Classification for Parkinson's Disease Diagnosis from Video
Jul 14, 2022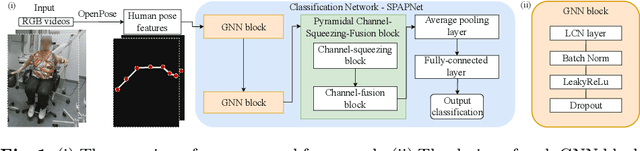
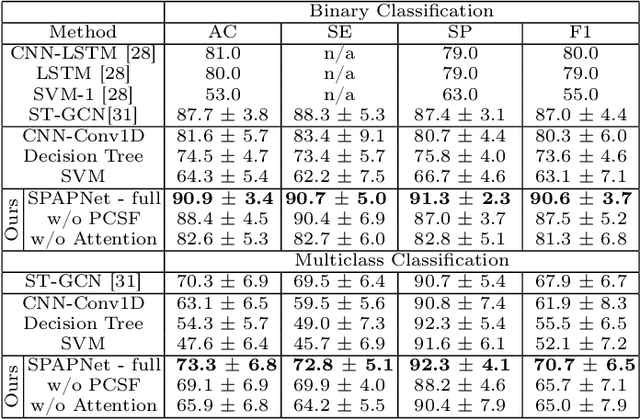
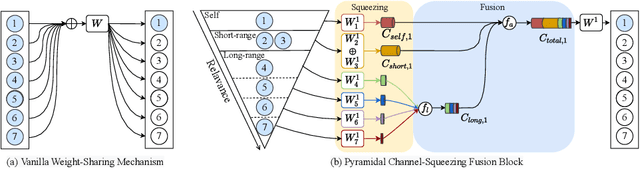
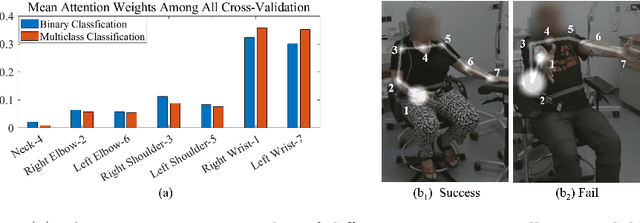
Parkinson's disease (PD) is a progressive neurodegenerative disorder that results in a variety of motor dysfunction symptoms, including tremors, bradykinesia, rigidity and postural instability. The diagnosis of PD mainly relies on clinical experience rather than a definite medical test, and the diagnostic accuracy is only about 73-84% since it is challenged by the subjective opinions or experiences of different medical experts. Therefore, an efficient and interpretable automatic PD diagnosis system is valuable for supporting clinicians with more robust diagnostic decision-making. To this end, we propose to classify Parkinson's tremor since it is one of the most predominant symptoms of PD with strong generalizability. Different from other computer-aided time and resource-consuming Parkinson's Tremor (PT) classification systems that rely on wearable sensors, we propose SPAPNet, which only requires consumer-grade non-intrusive video recording of camera-facing human movements as input to provide undiagnosed patients with low-cost PT classification results as a PD warning sign. For the first time, we propose to use a novel attention module with a lightweight pyramidal channel-squeezing-fusion architecture to extract relevant PT information and filter the noise efficiently. This design aids in improving both classification performance and system interpretability. Experimental results show that our system outperforms state-of-the-arts by achieving a balanced accuracy of 90.9% and an F1-score of 90.6% in classifying PT with the non-PT class.
Near-optimal control of dynamical systems with neural ordinary differential equations
Jun 22, 2022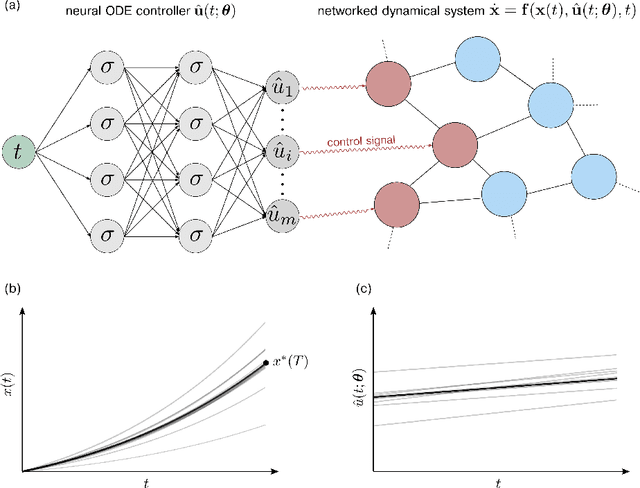
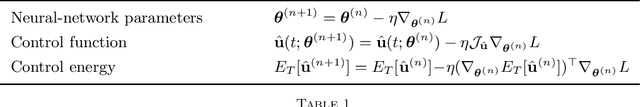
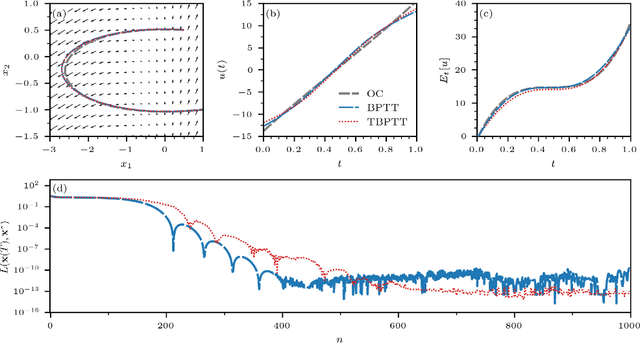
Optimal control problems naturally arise in many scientific applications where one wishes to steer a dynamical system from a certain initial state $\mathbf{x}_0$ to a desired target state $\mathbf{x}^*$ in finite time $T$. Recent advances in deep learning and neural network-based optimization have contributed to the development of methods that can help solve control problems involving high-dimensional dynamical systems. In particular, the framework of neural ordinary differential equations (neural ODEs) provides an efficient means to iteratively approximate continuous time control functions associated with analytically intractable and computationally demanding control tasks. Although neural ODE controllers have shown great potential in solving complex control problems, the understanding of the effects of hyperparameters such as network structure and optimizers on learning performance is still very limited. Our work aims at addressing some of these knowledge gaps to conduct efficient hyperparameter optimization. To this end, we first analyze how truncated and non-truncated backpropagation through time affect runtime performance and the ability of neural networks to learn optimal control functions. Using analytical and numerical methods, we then study the role of parameter initializations, optimizers, and neural-network architecture. Finally, we connect our results to the ability of neural ODE controllers to implicitly regularize control energy.
Minkowski Tracker: A Sparse Spatio-Temporal R-CNN for Joint Object Detection and Tracking
Aug 23, 2022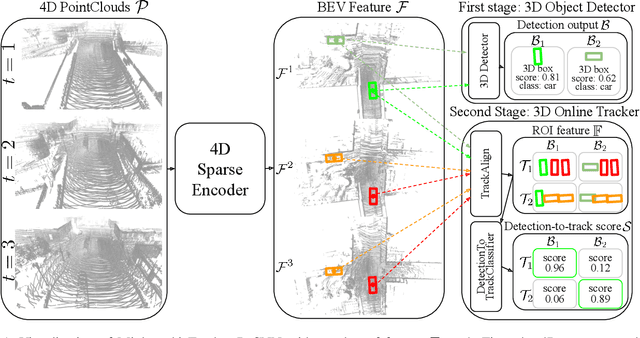
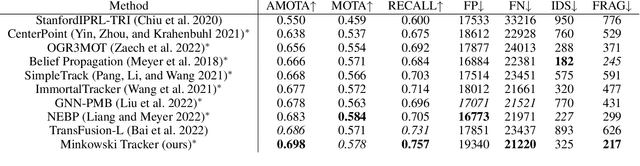
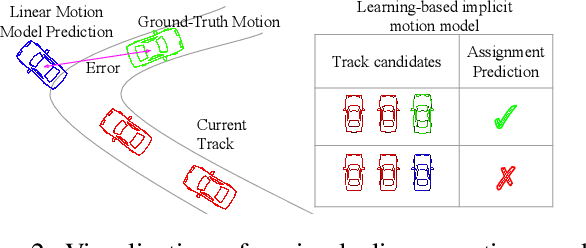
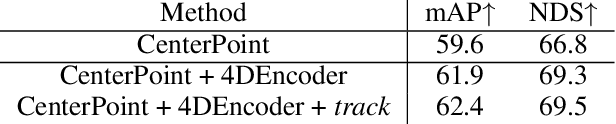
Recent research in multi-task learning reveals the benefit of solving related problems in a single neural network. 3D object detection and multi-object tracking (MOT) are two heavily intertwined problems predicting and associating an object instance location across time. However, most previous works in 3D MOT treat the detector as a preceding separated pipeline, disjointly taking the output of the detector as an input to the tracker. In this work, we present Minkowski Tracker, a sparse spatio-temporal R-CNN that jointly solves object detection and tracking. Inspired by region-based CNN (R-CNN), we propose to solve tracking as a second stage of the object detector R-CNN that predicts assignment probability to tracks. First, Minkowski Tracker takes 4D point clouds as input to generate a spatio-temporal Bird's-eye-view (BEV) feature map through a 4D sparse convolutional encoder network. Then, our proposed TrackAlign aggregates the track region-of-interest (ROI) features from the BEV features. Finally, Minkowski Tracker updates the track and its confidence score based on the detection-to-track match probability predicted from the ROI features. We show in large-scale experiments that the overall performance gain of our method is due to four factors: 1. The temporal reasoning of the 4D encoder improves the detection performance 2. The multi-task learning of object detection and MOT jointly enhances each other 3. The detection-to-track match score learns implicit motion model to enhance track assignment 4. The detection-to-track match score improves the quality of the track confidence score. As a result, Minkowski Tracker achieved the state-of-the-art performance on Nuscenes dataset tracking task without hand-designed motion models.
Generative Adversarial Learning for Intelligent Trust Management in 6G Wireless Networks
Aug 02, 2022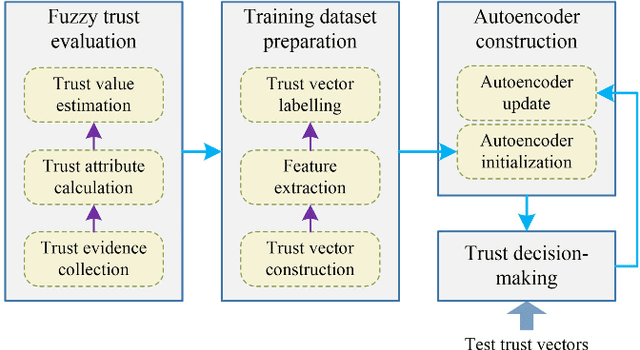
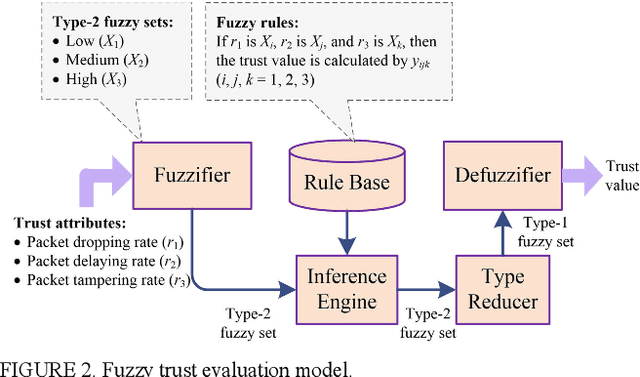
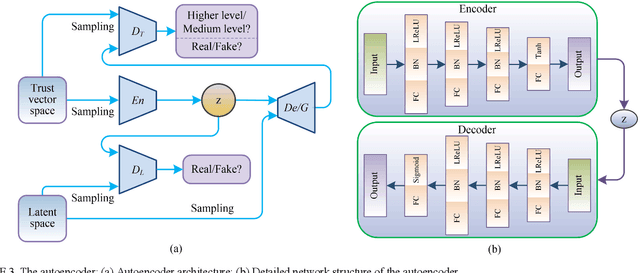
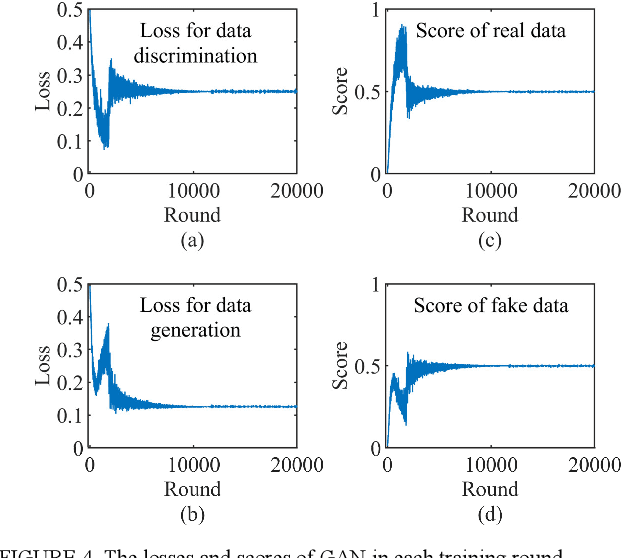
Emerging six generation (6G) is the integration of heterogeneous wireless networks, which can seamlessly support anywhere and anytime networking. But high Quality-of-Trust should be offered by 6G to meet mobile user expectations. Artificial intelligence (AI) is considered as one of the most important components in 6G. Then AI-based trust management is a promising paradigm to provide trusted and reliable services. In this article, a generative adversarial learning-enabled trust management method is presented for 6G wireless networks. Some typical AI-based trust management schemes are first reviewed, and then a potential heterogeneous and intelligent 6G architecture is introduced. Next, the integration of AI and trust management is developed to optimize the intelligence and security. Finally, the presented AI-based trust management method is applied to secure clustering to achieve reliable and real-time communications. Simulation results have demonstrated its excellent performance in guaranteeing network security and service quality.
ClearBuds: Wireless Binaural Earbuds for Learning-Based Speech Enhancement
Jun 27, 2022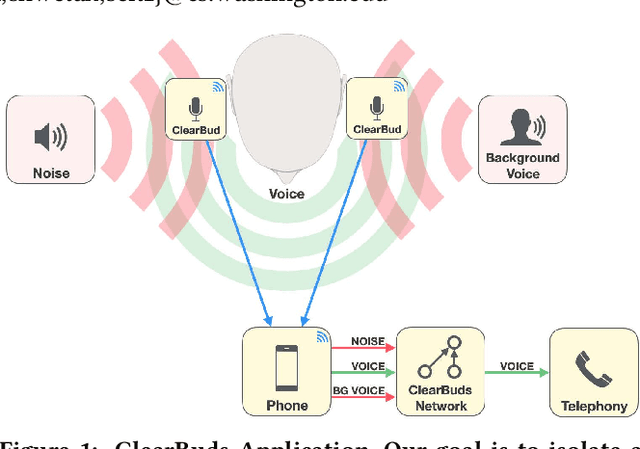

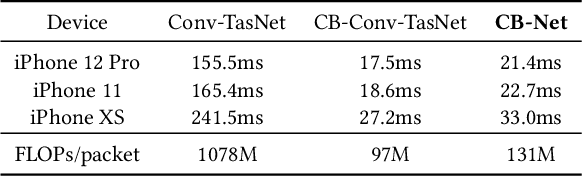
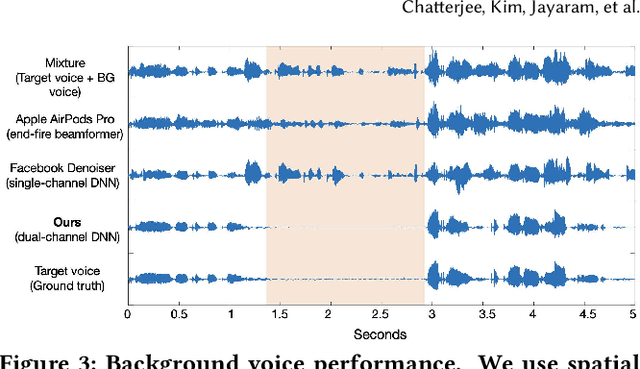
We present ClearBuds, the first hardware and software system that utilizes a neural network to enhance speech streamed from two wireless earbuds. Real-time speech enhancement for wireless earbuds requires high-quality sound separation and background cancellation, operating in real-time and on a mobile phone. Clear-Buds bridges state-of-the-art deep learning for blind audio source separation and in-ear mobile systems by making two key technical contributions: 1) a new wireless earbud design capable of operating as a synchronized, binaural microphone array, and 2) a lightweight dual-channel speech enhancement neural network that runs on a mobile device. Our neural network has a novel cascaded architecture that combines a time-domain conventional neural network with a spectrogram-based frequency masking neural network to reduce the artifacts in the audio output. Results show that our wireless earbuds achieve a synchronization error less than 64 microseconds and our network has a runtime of 21.4 milliseconds on an accompanying mobile phone. In-the-wild evaluation with eight users in previously unseen indoor and outdoor multipath scenarios demonstrates that our neural network generalizes to learn both spatial and acoustic cues to perform noise suppression and background speech removal. In a user-study with 37 participants who spent over 15.4 hours rating 1041 audio samples collected in-the-wild, our system achieves improved mean opinion score and background noise suppression. Project page with demos: https://clearbuds.cs.washington.edu
EfficientNeRF: Efficient Neural Radiance Fields
Jun 02, 2022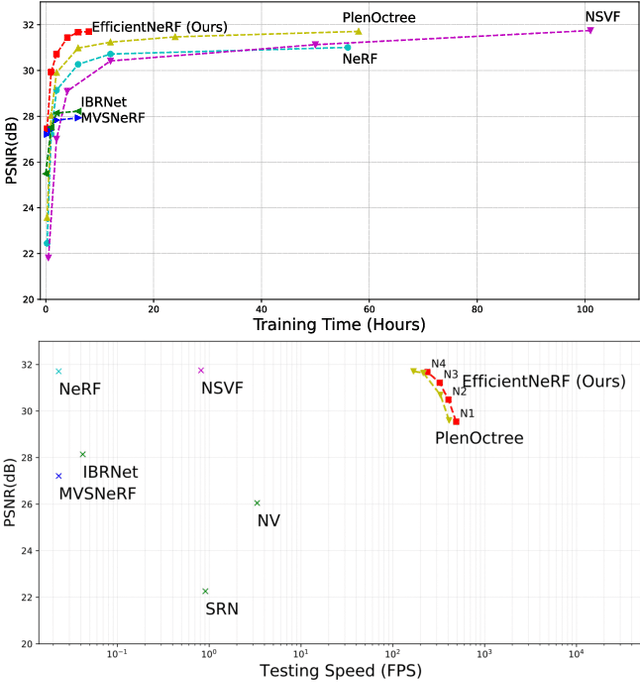

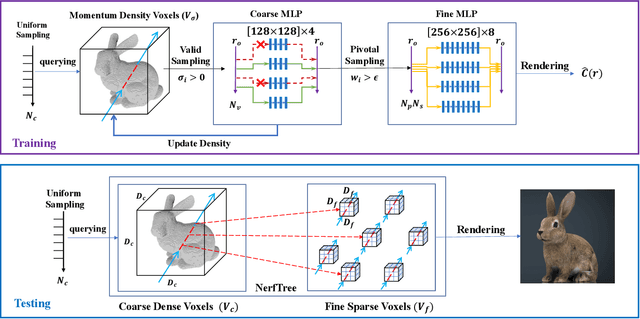
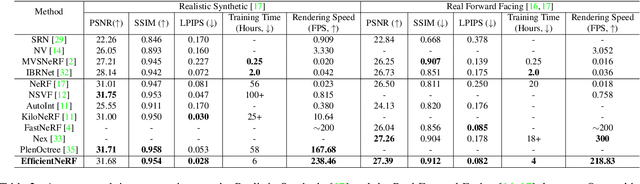
Neural Radiance Fields (NeRF) has been wildly applied to various tasks for its high-quality representation of 3D scenes. It takes long per-scene training time and per-image testing time. In this paper, we present EfficientNeRF as an efficient NeRF-based method to represent 3D scene and synthesize novel-view images. Although several ways exist to accelerate the training or testing process, it is still difficult to much reduce time for both phases simultaneously. We analyze the density and weight distribution of the sampled points then propose valid and pivotal sampling at the coarse and fine stage, respectively, to significantly improve sampling efficiency. In addition, we design a novel data structure to cache the whole scene during testing to accelerate the rendering speed. Overall, our method can reduce over 88\% of training time, reach rendering speed of over 200 FPS, while still achieving competitive accuracy. Experiments prove that our method promotes the practicality of NeRF in the real world and enables many applications.
Accelerating Numerical Solvers for Large-Scale Simulation of Dynamical System via NeurVec
Aug 07, 2022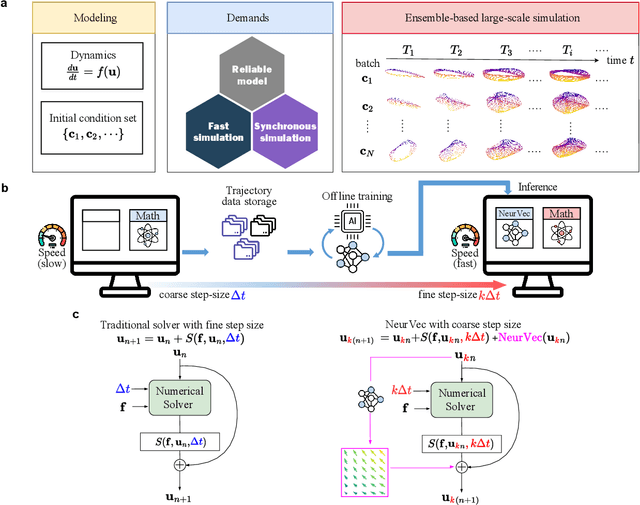

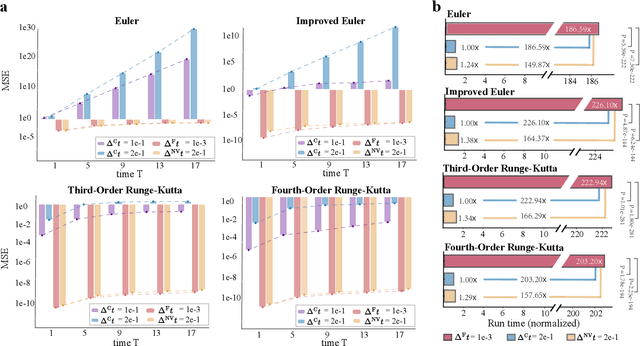
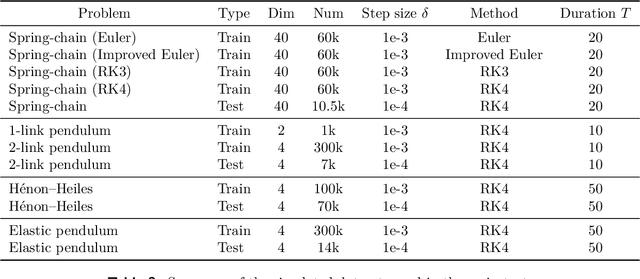
Ensemble-based large-scale simulation of dynamical systems is essential to a wide range of science and engineering problems. Conventional numerical solvers used in the simulation are significantly limited by the step size for time integration, which hampers efficiency and feasibility especially when high accuracy is desired. To overcome this limitation, we propose a data-driven corrector method that allows using large step sizes while compensating for the integration error for high accuracy. This corrector is represented in the form of a vector-valued function and is modeled by a neural network to regress the error in the phase space. Hence we name the corrector neural vector (NeurVec). We show that NeurVec can achieve the same accuracy as traditional solvers with much larger step sizes. We empirically demonstrate that NeurVec can accelerate a variety of numerical solvers significantly and overcome the stability restriction of these solvers. Our results on benchmark problems, ranging from high-dimensional problems to chaotic systems, suggest that NeurVec is capable of capturing the leading error term and maintaining the statistics of ensemble forecasts.
Looking for a Needle in a Haystack: A Comprehensive Study of Hallucinations in Neural Machine Translation
Aug 10, 2022

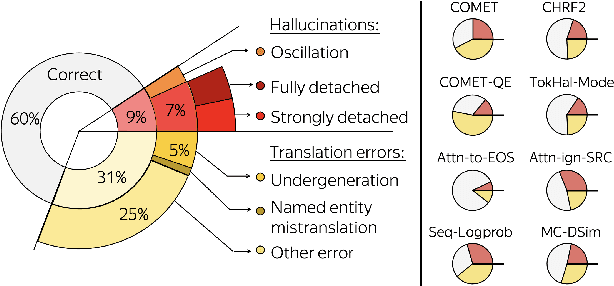
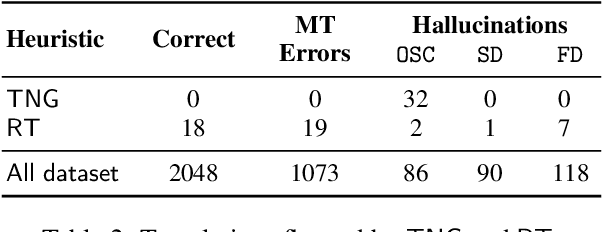
Although the problem of hallucinations in neural machine translation (NMT) has received some attention, research on this highly pathological phenomenon lacks solid ground. Previous work has been limited in several ways: it often resorts to artificial settings where the problem is amplified, it disregards some (common) types of hallucinations, and it does not validate adequacy of detection heuristics. In this paper, we set foundations for the study of NMT hallucinations. First, we work in a natural setting, i.e., in-domain data without artificial noise neither in training nor in inference. Next, we annotate a dataset of over 3.4k sentences indicating different kinds of critical errors and hallucinations. Then, we turn to detection methods and both revisit methods used previously and propose using glass-box uncertainty-based detectors. Overall, we show that for preventive settings, (i) previously used methods are largely inadequate, (ii) sequence log-probability works best and performs on par with reference-based methods. Finally, we propose DeHallucinator, a simple method for alleviating hallucinations at test time that significantly reduces the hallucinatory rate. To ease future research, we release our annotated dataset for WMT18 German-English data, along with the model, training data, and code.