 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Cost of Language: Centroid Erasure Exposes and Exploits Modal Competition in Multimodal Language Models
Apr 15, 2026Multimodal language models systematically underperform on visual perception tasks, yet the structure underlying this failure remains poorly understood. We propose centroid replacement, collapsing each token to its nearest K-means centroid, as a controlled probe for modal dependence. Across seven models spanning three architecture families, erasing text centroid structure costs 4$\times$ more accuracy than erasing visual centroid structure, exposing a universal imbalance where language representations overshadow vision even on tasks that demand visual reasoning. We exploit this asymmetry through text centroid contrastive decoding, recovering up to +16.9% accuracy on individual tasks by contrastively decoding against a text-centroid-erased reference. This intervention varies meaningfully with training approaches: standard fine-tuned models show larger gains (+5.6% on average) than preference-optimized models (+1.5% on average). Our findings suggest that modal competition is structurally localized, correctable at inference time without retraining, and quantifiable as a diagnostic signal to guide future multimodal training.
DeltaDorsal: Enhancing Hand Pose Estimation with Dorsal Features in Egocentric Views
Jan 26, 2026The proliferation of XR devices has made egocentric hand pose estimation a vital task, yet this perspective is inherently challenged by frequent finger occlusions. To address this, we propose a novel approach that leverages the rich information in dorsal hand skin deformation, unlocked by recent advances in dense visual featurizers. We introduce a dual-stream delta encoder that learns pose by contrasting features from a dynamic hand with a baseline relaxed position. Our evaluation demonstrates that, using only cropped dorsal images, our method reduces the Mean Per Joint Angle Error (MPJAE) by 18% in self-occluded scenarios (fingers >= 50% occluded) compared to state-of-the-art techniques that depend on the whole hand's geometry and large model backbones. Consequently, our method not only enhances the reliability of downstream tasks like index finger pinch and tap estimation in occluded scenarios but also unlocks new interaction paradigms, such as detecting isometric force for a surface "click" without visible movement while minimizing model size.
"What's Up, Doc?": Analyzing How Users Seek Health Information in Large-Scale Conversational AI Datasets
Jun 26, 2025People are increasingly seeking healthcare information from large language models (LLMs) via interactive chatbots, yet the nature and inherent risks of these conversations remain largely unexplored. In this paper, we filter large-scale conversational AI datasets to achieve HealthChat-11K, a curated dataset of 11K real-world conversations composed of 25K user messages. We use HealthChat-11K and a clinician-driven taxonomy for how users interact with LLMs when seeking healthcare information in order to systematically study user interactions across 21 distinct health specialties. Our analysis reveals insights into the nature of how and why users seek health information, such as common interactions, instances of incomplete context, affective behaviors, and interactions (e.g., leading questions) that can induce sycophancy, underscoring the need for improvements in the healthcare support capabilities of LLMs deployed as conversational AI. Code and artifacts to retrieve our analyses and combine them into a curated dataset can be found here: https://github.com/yahskapar/HealthChat
Steerable Chatbots: Personalizing LLMs with Preference-Based Activation Steering
May 07, 2025



As large language models (LLMs) improve in their capacity to serve as personal AI assistants, their ability to output uniquely tailored, personalized responses that align with the soft preferences of their users is essential for enhancing user satisfaction and retention. However, untrained lay users have poor prompt specification abilities and often struggle with conveying their latent preferences to AI assistants. To address this, we leverage activation steering to guide LLMs to align with interpretable preference dimensions during inference. In contrast to memory-based personalization methods that require longer user history, steering is extremely lightweight and can be easily controlled by the user via an linear strength factor. We embed steering into three different interactive chatbot interfaces and conduct a within-subjects user study (n=14) to investigate how end users prefer to personalize their conversations. The results demonstrate the effectiveness of preference-based steering for aligning real-world conversations with hidden user preferences, and highlight further insights on how diverse values around control, usability, and transparency lead users to prefer different interfaces.
ClearBuds: Wireless Binaural Earbuds for Learning-Based Speech Enhancement
Jun 27, 2022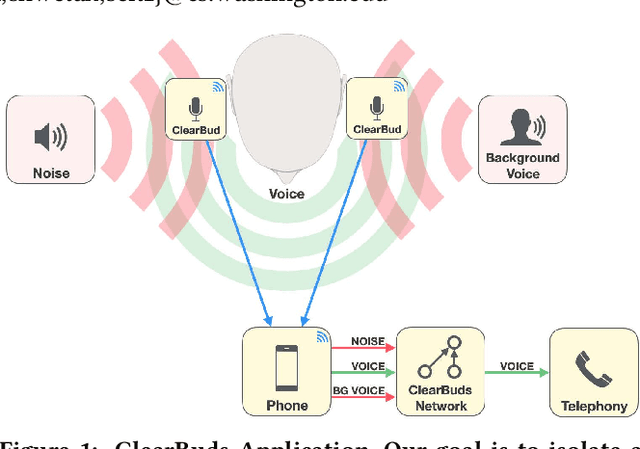

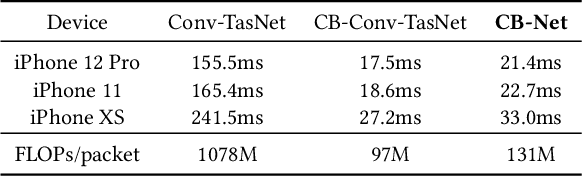
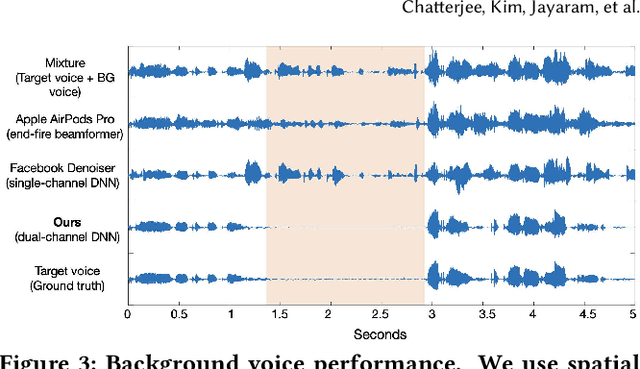
We present ClearBuds, the first hardware and software system that utilizes a neural network to enhance speech streamed from two wireless earbuds. Real-time speech enhancement for wireless earbuds requires high-quality sound separation and background cancellation, operating in real-time and on a mobile phone. Clear-Buds bridges state-of-the-art deep learning for blind audio source separation and in-ear mobile systems by making two key technical contributions: 1) a new wireless earbud design capable of operating as a synchronized, binaural microphone array, and 2) a lightweight dual-channel speech enhancement neural network that runs on a mobile device. Our neural network has a novel cascaded architecture that combines a time-domain conventional neural network with a spectrogram-based frequency masking neural network to reduce the artifacts in the audio output. Results show that our wireless earbuds achieve a synchronization error less than 64 microseconds and our network has a runtime of 21.4 milliseconds on an accompanying mobile phone. In-the-wild evaluation with eight users in previously unseen indoor and outdoor multipath scenarios demonstrates that our neural network generalizes to learn both spatial and acoustic cues to perform noise suppression and background speech removal. In a user-study with 37 participants who spent over 15.4 hours rating 1041 audio samples collected in-the-wild, our system achieves improved mean opinion score and background noise suppression. Project page with demos: https://clearbuds.cs.washington.edu