 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Object-Category Aware Reinforcement Learning
Oct 13, 2022
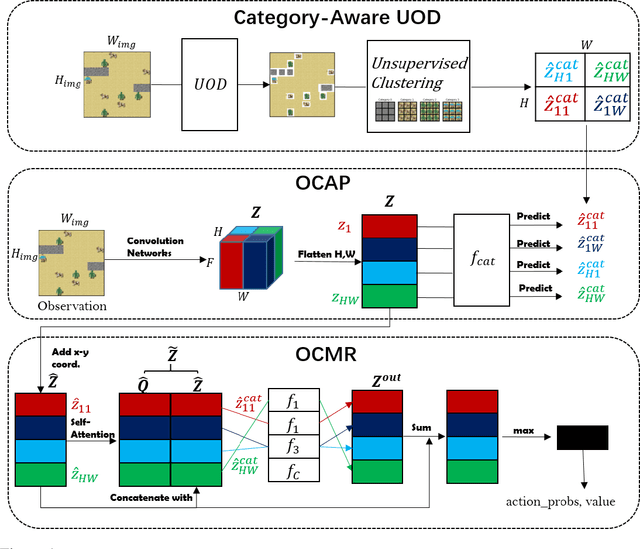

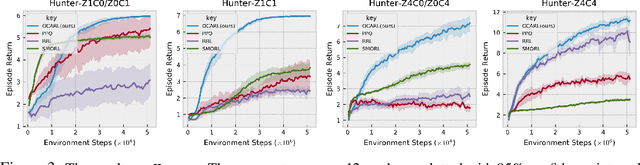

Object-oriented reinforcement learning (OORL) is a promising way to improve the sample efficiency and generalization ability over standard RL. Recent works that try to solve OORL tasks without additional feature engineering mainly focus on learning the object representations and then solving tasks via reasoning based on these object representations. However, none of these works tries to explicitly model the inherent similarity between different object instances of the same category. Objects of the same category should share similar functionalities; therefore, the category is the most critical property of an object. Following this insight, we propose a novel framework named Object-Category Aware Reinforcement Learning (OCARL), which utilizes the category information of objects to facilitate both perception and reasoning. OCARL consists of three parts: (1) Category-Aware Unsupervised Object Discovery (UOD), which discovers the objects as well as their corresponding categories; (2) Object-Category Aware Perception, which encodes the category information and is also robust to the incompleteness of (1) at the same time; (3) Object-Centric Modular Reasoning, which adopts multiple independent and object-category-specific networks when reasoning based on objects. Our experiments show that OCARL can improve both the sample efficiency and generalization in the OORL domain.
Visible-Infrared Person Re-Identification Using Privileged Intermediate Information
Sep 19, 2022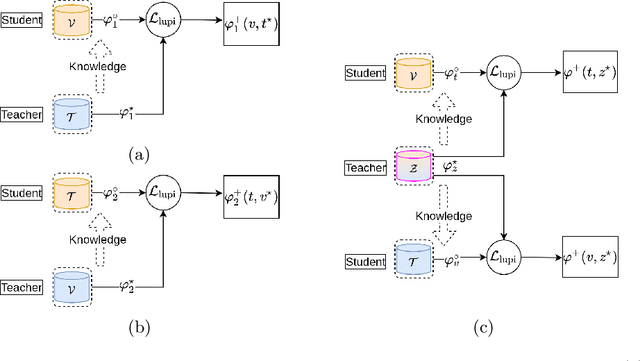
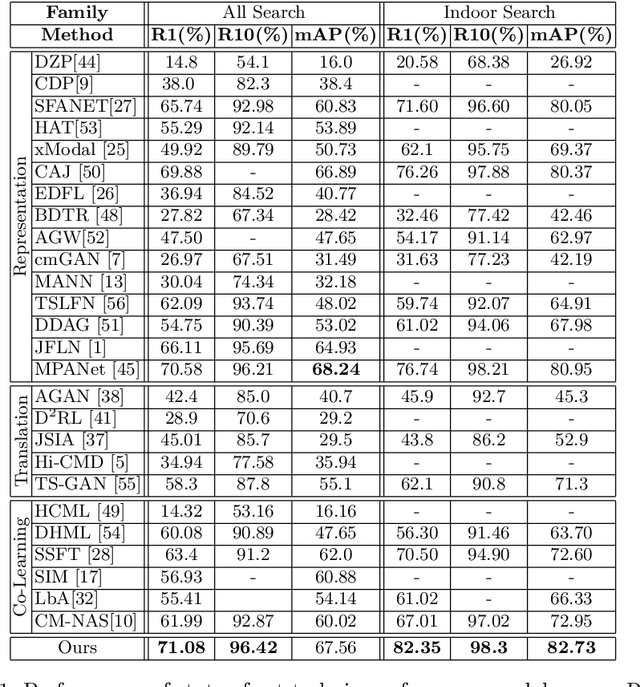

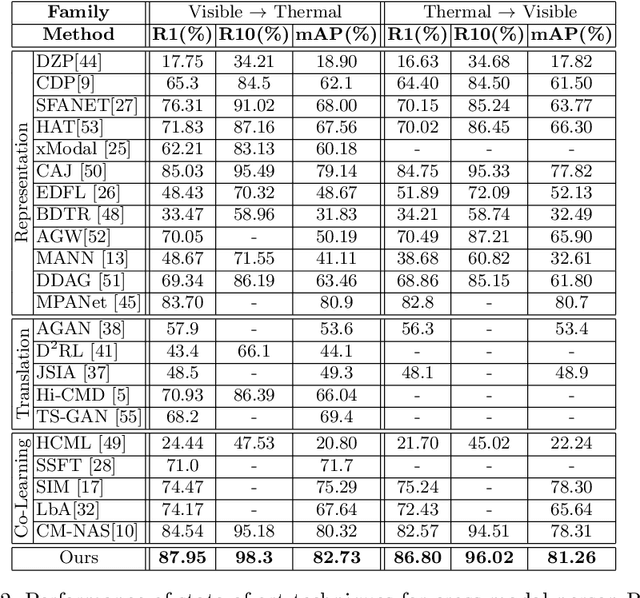
Visible-infrared person re-identification (ReID) aims to recognize a same person of interest across a network of RGB and IR cameras. Some deep learning (DL) models have directly incorporated both modalities to discriminate persons in a joint representation space. However, this cross-modal ReID problem remains challenging due to the large domain shift in data distributions between RGB and IR modalities. % This paper introduces a novel approach for a creating intermediate virtual domain that acts as bridges between the two main domains (i.e., RGB and IR modalities) during training. This intermediate domain is considered as privileged information (PI) that is unavailable at test time, and allows formulating this cross-modal matching task as a problem in learning under privileged information (LUPI). We devised a new method to generate images between visible and infrared domains that provide additional information to train a deep ReID model through an intermediate domain adaptation. In particular, by employing color-free and multi-step triplet loss objectives during training, our method provides common feature representation spaces that are robust to large visible-infrared domain shifts. % Experimental results on challenging visible-infrared ReID datasets indicate that our proposed approach consistently improves matching accuracy, without any computational overhead at test time. The code is available at: \href{https://github.com/alehdaghi/Cross-Modal-Re-ID-via-LUPI}{https://github.com/alehdaghi/Cross-Modal-Re-ID-via-LUPI}
Edge-assisted Collaborative Digital Twin for Safety-Critical Robotics in Industrial IoT
Sep 26, 2022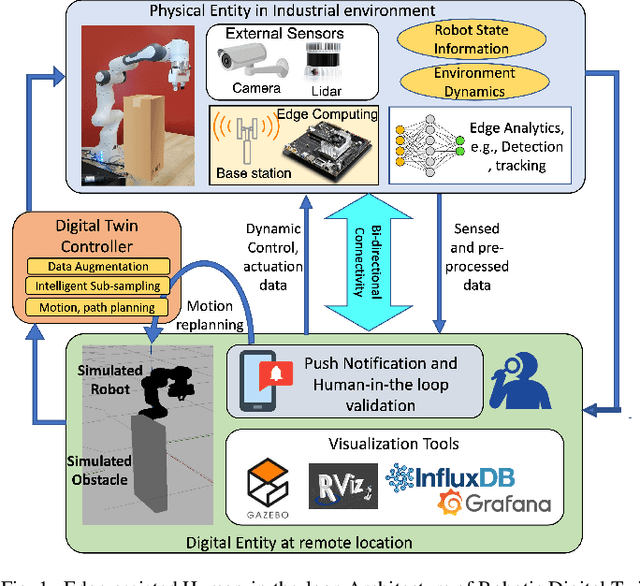

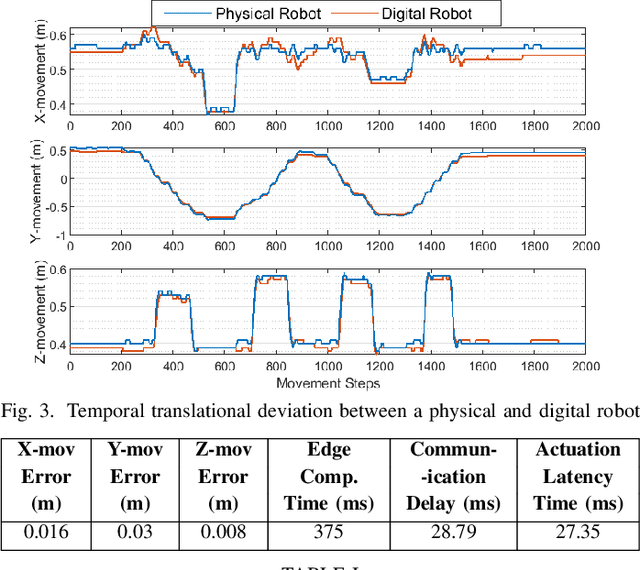
Digital Twin technology is playing a pivotal role in the modern industrial evolution. Especially, with the technological progress in the Internet-of-Things (IoT) and the increasing trend in autonomy, multi-sensor equipped robotics can create practical digital twin, which is particularly useful in the industrial applications for operations, maintenance and safety. Herein, we demonstrate a real-world digital twin of a safety-critical robotics applications with a Franka-Emika-Panda robotic arm. We develop and showcase an edge-assisted collaborative digital twin for dynamic obstacle avoidance which can be useful in real-time adaptation of the robots while operating in the uncertain and dynamic environments in industrial IoT.
Multitask Learning via Shared Features: Algorithms and Hardness
Sep 07, 2022
We investigate the computational efficiency of multitask learning of Boolean functions over the $d$-dimensional hypercube, that are related by means of a feature representation of size $k \ll d$ shared across all tasks. We present a polynomial time multitask learning algorithm for the concept class of halfspaces with margin $\gamma$, which is based on a simultaneous boosting technique and requires only $\textrm{poly}(k/\gamma)$ samples-per-task and $\textrm{poly}(k\log(d)/\gamma)$ samples in total. In addition, we prove a computational separation, showing that assuming there exists a concept class that cannot be learned in the attribute-efficient model, we can construct another concept class such that can be learned in the attribute-efficient model, but cannot be multitask learned efficiently -- multitask learning this concept class either requires super-polynomial time complexity or a much larger total number of samples.
RASR: Risk-Averse Soft-Robust MDPs with EVaR and Entropic Risk
Sep 09, 2022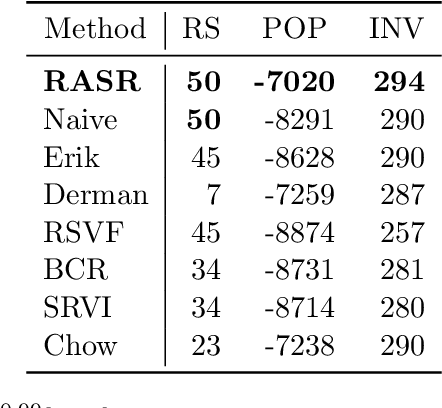

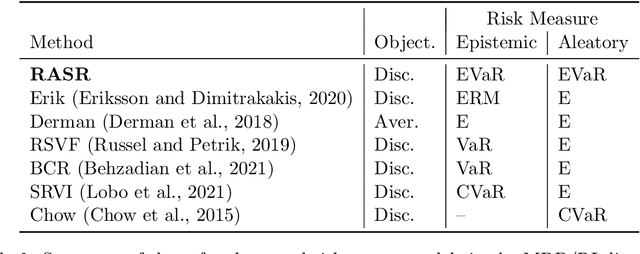
Prior work on safe Reinforcement Learning (RL) has studied risk-aversion to randomness in dynamics (aleatory) and to model uncertainty (epistemic) in isolation. We propose and analyze a new framework to jointly model the risk associated with epistemic and aleatory uncertainties in finite-horizon and discounted infinite-horizon MDPs. We call this framework that combines Risk-Averse and Soft-Robust methods RASR. We show that when the risk-aversion is defined using either EVaR or the entropic risk, the optimal policy in RASR can be computed efficiently using a new dynamic program formulation with a time-dependent risk level. As a result, the optimal risk-averse policies are deterministic but time-dependent, even in the infinite-horizon discounted setting. We also show that particular RASR objectives reduce to risk-averse RL with mean posterior transition probabilities. Our empirical results show that our new algorithms consistently mitigate uncertainty as measured by EVaR and other standard risk measures.
Guiding Safe Exploration with Weakest Preconditions
Sep 28, 2022
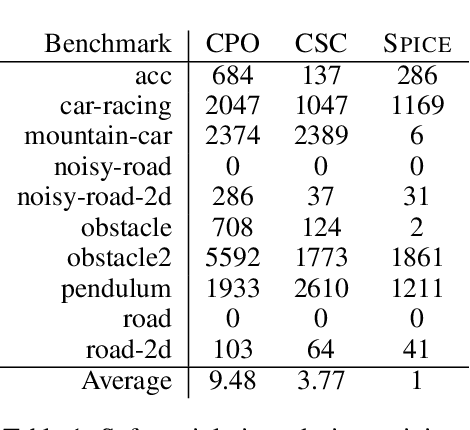
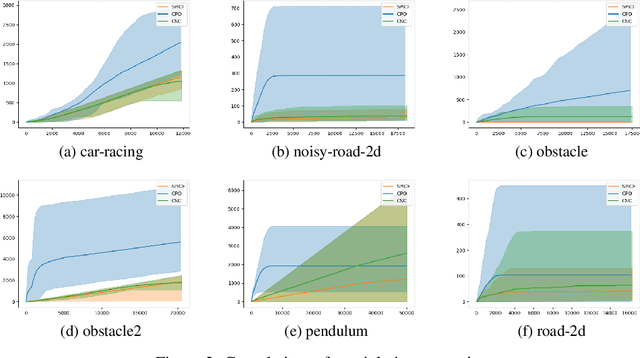
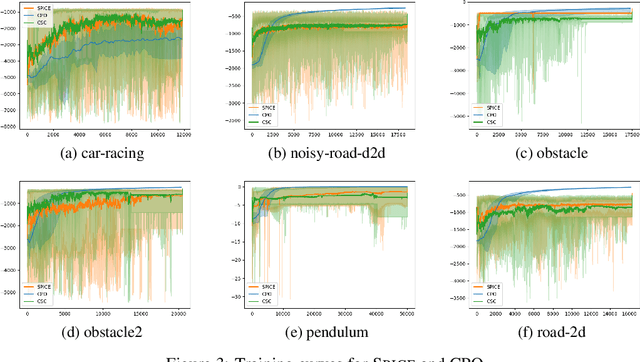
In reinforcement learning for safety-critical settings, it is often desirable for the agent to obey safety constraints at all points in time, including during training. We present a novel neurosymbolic approach called SPICE to solve this safe exploration problem. SPICE uses an online shielding layer based on symbolic weakest preconditions to achieve a more precise safety analysis than existing tools without unduly impacting the training process. We evaluate the approach on a suite of continuous control benchmarks and show that it can achieve comparable performance to existing safe learning techniques while incurring fewer safety violations. Additionally, we present theoretical results showing that SPICE converges to the optimal safe policy under reasonable assumptions.
P2M-DeTrack: Processing-in-Pixel-in-Memory for Energy-efficient and Real-Time Multi-Object Detection and Tracking
May 28, 2022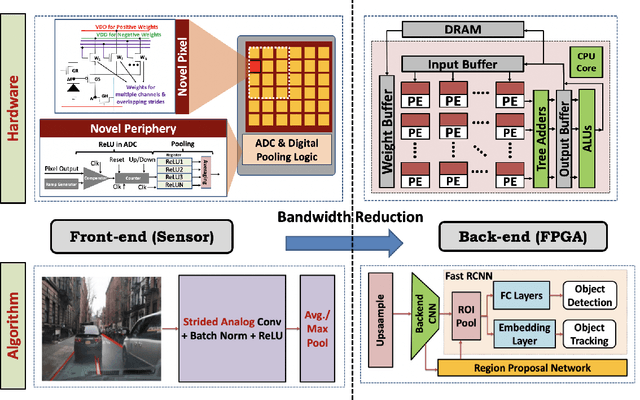
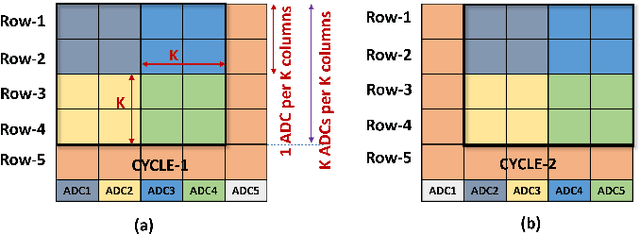
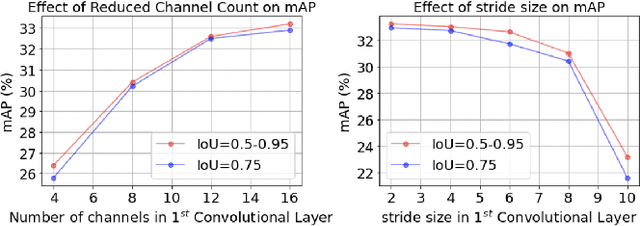
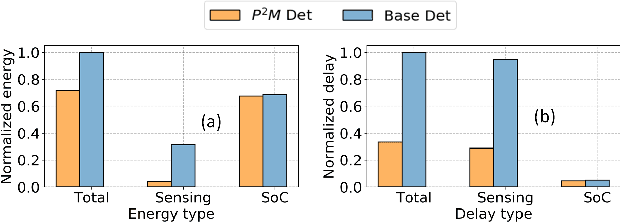
Today's high resolution, high frame rate cameras in autonomous vehicles generate a large volume of data that needs to be transferred and processed by a downstream processor or machine learning (ML) accelerator to enable intelligent computing tasks, such as multi-object detection and tracking. The massive amount of data transfer incurs significant energy, latency, and bandwidth bottlenecks, which hinders real-time processing. To mitigate this problem, we propose an algorithm-hardware co-design framework called Processing-in-Pixel-in-Memory-based object Detection and Tracking (P2M-DeTrack). P2M-DeTrack is based on a custom faster R-CNN-based model that is distributed partly inside the pixel array (front-end) and partly in a separate FPGA/ASIC (back-end). The proposed front-end in-pixel processing down-samples the input feature maps significantly with judiciously optimized strided convolution and pooling. Compared to a conventional baseline design that transfers frames of RGB pixels to the back-end, the resulting P2M-DeTrack designs reduce the data bandwidth between sensor and back-end by up to 24x. The designs also reduce the sensor and total energy (obtained from in-house circuit simulations at Globalfoundries 22nm technology node) per frame by 5.7x and 1.14x, respectively. Lastly, they reduce the sensing and total frame latency by an estimated 1.7x and 3x, respectively. We evaluate our approach on the multi-object object detection (tracking) task of the large-scale BDD100K dataset and observe only a 0.5% reduction in the mean average precision (0.8% reduction in the identification F1 score) compared to the state-of-the-art.
Attention Spiking Neural Networks
Sep 28, 2022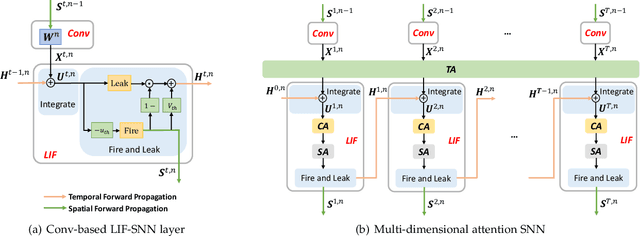
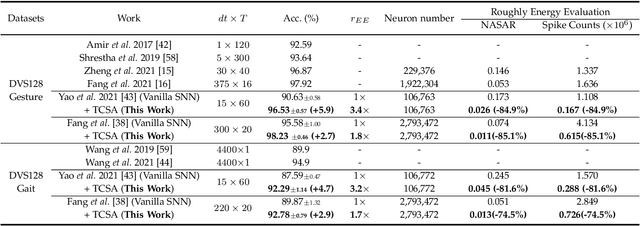
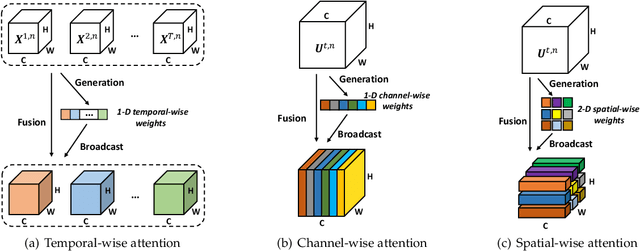
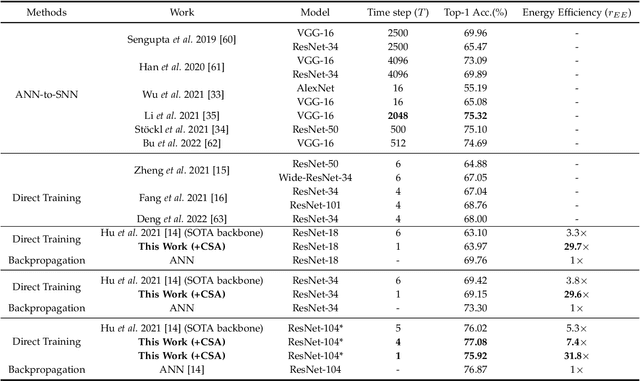
Benefiting from the event-driven and sparse spiking characteristics of the brain, spiking neural networks (SNNs) are becoming an energy-efficient alternative to artificial neural networks (ANNs). However, the performance gap between SNNs and ANNs has been a great hindrance to deploying SNNs ubiquitously for a long time. To leverage the full potential of SNNs, we study the effect of attention mechanisms in SNNs. We first present our idea of attention with a plug-and-play kit, termed the Multi-dimensional Attention (MA). Then, a new attention SNN architecture with end-to-end training called "MA-SNN" is proposed, which infers attention weights along the temporal, channel, as well as spatial dimensions separately or simultaneously. Based on the existing neuroscience theories, we exploit the attention weights to optimize membrane potentials, which in turn regulate the spiking response in a data-dependent way. At the cost of negligible additional parameters, MA facilitates vanilla SNNs to achieve sparser spiking activity, better performance, and energy efficiency concurrently. Experiments are conducted in event-based DVS128 Gesture/Gait action recognition and ImageNet-1k image classification. On Gesture/Gait, the spike counts are reduced by 84.9%/81.6%, and the task accuracy and energy efficiency are improved by 5.9%/4.7% and 3.4$\times$/3.2$\times$. On ImageNet-1K, we achieve top-1 accuracy of 75.92% and 77.08% on single/4-step Res-SNN-104, which are state-of-the-art results in SNNs. To our best knowledge, this is for the first time, that the SNN community achieves comparable or even better performance compared with its ANN counterpart in the large-scale dataset. Our work lights up SNN's potential as a general backbone to support various applications for SNNs, with a great balance between effectiveness and efficiency.
FRIDA: Fisheye Re-Identification Dataset with Annotations
Oct 04, 2022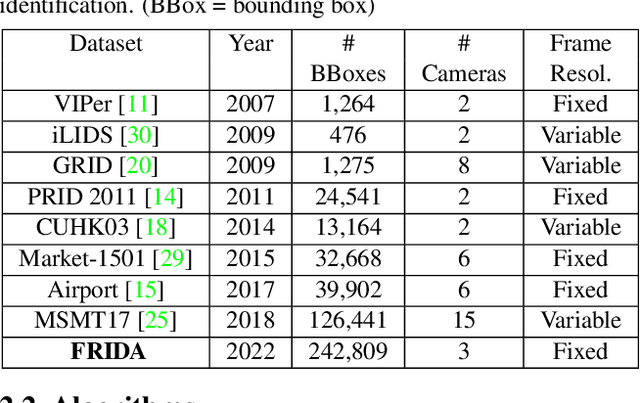
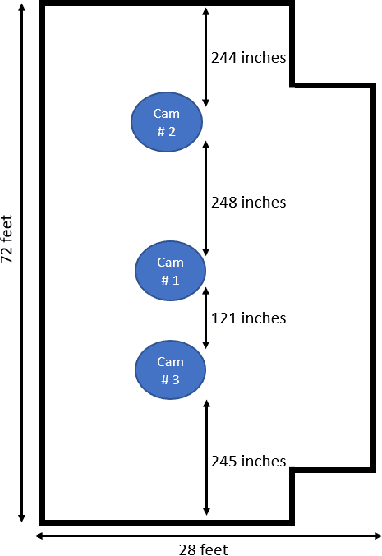


Person re-identification (PRID) from side-mounted rectilinear-lens cameras is a well-studied problem. On the other hand, PRID from overhead fisheye cameras is new and largely unstudied, primarily due to the lack of suitable image datasets. To fill this void, we introduce the "Fisheye Re-IDentification Dataset with Annotations" (FRIDA), with 240k+ bounding-box annotations of people, captured by 3 time-synchronized, ceiling-mounted fisheye cameras in a large indoor space. Due to a field-of-view overlap, PRID in this case differs from a typical PRID problem, which we discuss in depth. We also evaluate the performance of 10 state-of-the-art PRID algorithms on FRIDA. We show that for 6 CNN-based algorithms, training on FRIDA boosts the performance by up to 11.64% points in mAP compared to training on a common rectilinear-camera PRID dataset.
Unsupervised Sentence Textual Similarity with Compositional Phrase Semantics
Oct 05, 2022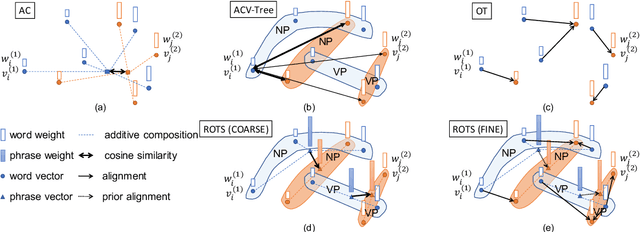


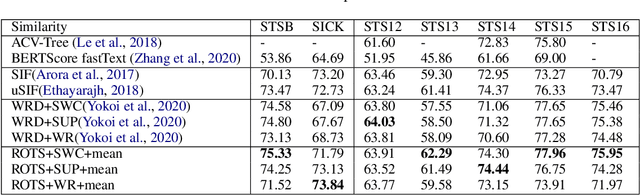
Measuring Sentence Textual Similarity (STS) is a classic task that can be applied to many downstream NLP applications such as text generation and retrieval. In this paper, we focus on unsupervised STS that works on various domains but only requires minimal data and computational resources. Theoretically, we propose a light-weighted Expectation-Correction (EC) formulation for STS computation. EC formulation unifies unsupervised STS approaches including the cosine similarity of Additively Composed (AC) sentence embeddings, Optimal Transport (OT), and Tree Kernels (TK). Moreover, we propose the Recursive Optimal Transport Similarity (ROTS) algorithm to capture the compositional phrase semantics by composing multiple recursive EC formulations. ROTS finishes in linear time and is faster than its predecessors. ROTS is empirically more effective and scalable than previous approaches. Extensive experiments on 29 STS tasks under various settings show the clear advantage of ROTS over existing approaches. Detailed ablation studies demonstrate the effectiveness of our approaches.