 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Natural Language Deduction with Incomplete Information
Nov 01, 2022

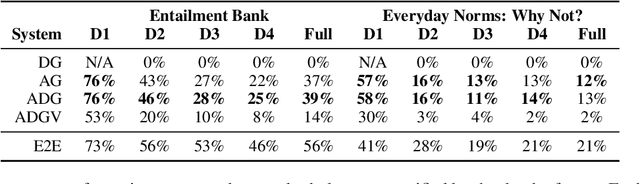

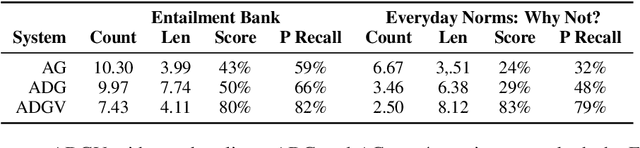
A growing body of work studies how to answer a question or verify a claim by generating a natural language "proof": a chain of deductive inferences yielding the answer based on a set of premises. However, these methods can only make sound deductions when they follow from evidence that is given. We propose a new system that can handle the underspecified setting where not all premises are stated at the outset; that is, additional assumptions need to be materialized to prove a claim. By using a natural language generation model to abductively infer a premise given another premise and a conclusion, we can impute missing pieces of evidence needed for the conclusion to be true. Our system searches over two fringes in a bidirectional fashion, interleaving deductive (forward-chaining) and abductive (backward-chaining) generation steps. We sample multiple possible outputs for each step to achieve coverage of the search space, at the same time ensuring correctness by filtering low-quality generations with a round-trip validation procedure. Results on a modified version of the EntailmentBank dataset and a new dataset called Everyday Norms: Why Not? show that abductive generation with validation can recover premises across in- and out-of-domain settings.
Learning Task-Aware Effective Brain Connectivity for fMRI Analysis with Graph Neural Networks
Nov 01, 2022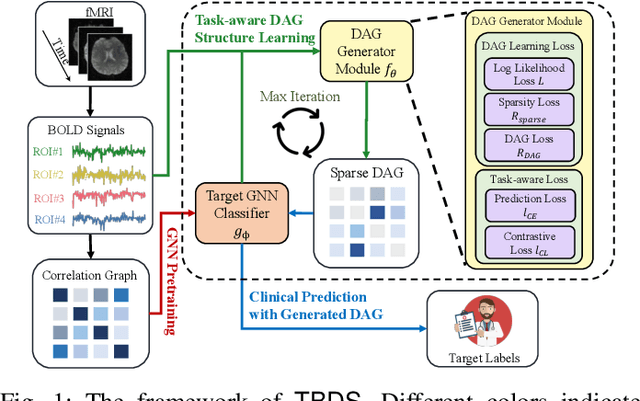
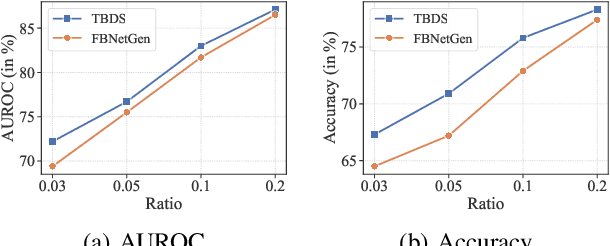
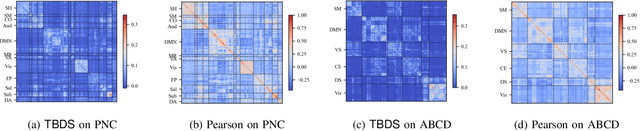

Functional magnetic resonance imaging (fMRI) has become one of the most common imaging modalities for brain function analysis. Recently, graph neural networks (GNN) have been adopted for fMRI analysis with superior performance. Unfortunately, traditional functional brain networks are mainly constructed based on similarities among region of interests (ROI), which are noisy and agnostic to the downstream prediction tasks and can lead to inferior results for GNN-based models. To better adapt GNNs for fMRI analysis, we propose TBDS, an end-to-end framework based on \underline{T}ask-aware \underline{B}rain connectivity \underline{D}AG (short for Directed Acyclic Graph) \underline{S}tructure generation for fMRI analysis. The key component of TBDS is the brain network generator which adopts a DAG learning approach to transform the raw time-series into task-aware brain connectivities. Besides, we design an additional contrastive regularization to inject task-specific knowledge during the brain network generation process. Comprehensive experiments on two fMRI datasets, namely Adolescent Brain Cognitive Development (ABCD) and Philadelphia Neuroimaging Cohort (PNC) datasets demonstrate the efficacy of TBDS. In addition, the generated brain networks also highlight the prediction-related brain regions and thus provide unique interpretations of the prediction results. Our implementation will be published to https://github.com/yueyu1030/TBDS upon acceptance.
Robot to Human Object Handover using Vision and Joint Torque Sensor Modalities
Oct 27, 2022
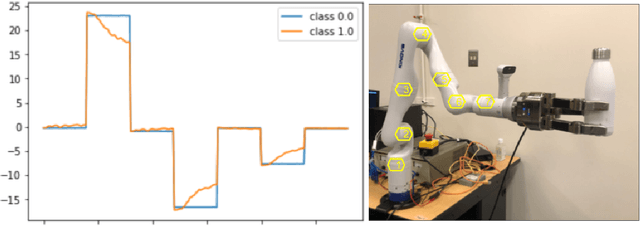
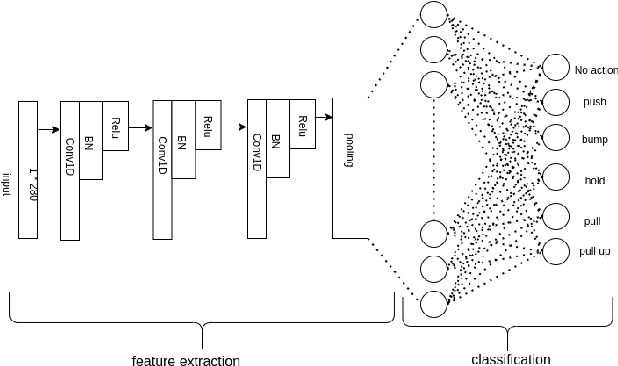
We present a robot-to-human object handover algorithm and implement it on a 7-DOF arm equipped with a 3-finger mechanical hand. The system performs a fully autonomous and robust object handover to a human receiver in real-time. Our algorithm relies on two complementary sensor modalities: joint torque sensors on the arm and an eye-in-hand RGB-D camera for sensor feedback. Our approach is entirely implicit, i.e., there is no explicit communication between the robot and the human receiver. Information obtained via the aforementioned sensor modalities is used as inputs to their related deep neural networks. While the torque sensor network detects the human receiver's "intention" such as: pull, hold, or bump, the vision sensor network detects if the receiver's fingers have wrapped around the object. Networks' outputs are then fused, based on which a decision is made to either release the object or not. Despite substantive challenges in sensor feedback synchronization, object, and human hand detection, our system achieves robust robot-to-human handover with 98\% accuracy in our preliminary real experiments using human receivers.
Decentralized Federated Learning via Non-Coherent Over-the-Air Consensus
Oct 27, 2022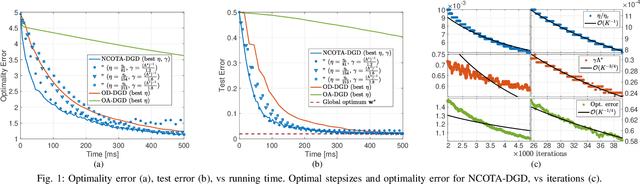
This paper presents NCOTA-DGD, a Decentralized Gradient Descent (DGD) algorithm that combines local gradient descent with Non-Coherent Over-The-Air (NCOTA) consensus at the receivers to solve distributed machine-learning problems over wirelessly-connected systems. NCOTA-DGD leverages the waveform superposition properties of the wireless channels: it enables simultaneous transmissions under half-duplex constraints, by mapping local signals to a mixture of preamble sequences, and consensus via non-coherent combining at the receivers. NCOTA-DGD operates without channel state information and leverages the average channel pathloss to mix signals, without explicit knowledge of the mixing weights (typically known in consensus-based optimization algorithms). It is shown both theoretically and numerically that, for smooth and strongly-convex problems with fixed consensus and learning stepsizes, the updates of NCOTA-DGD converge (in Euclidean distance) to the global optimum with rate $\mathcal O(K^{-1/4})$ for a target number of iterations $K$. NCOTA-DGD is evaluated numerically over a logistic regression problem, showing faster convergence vis-\`a-vis running time than implementations of the classical DGD algorithm over digital and analog orthogonal channels.
Adaptive Estimation of $\text{MTP}_2$ Graphical Models
Oct 27, 2022
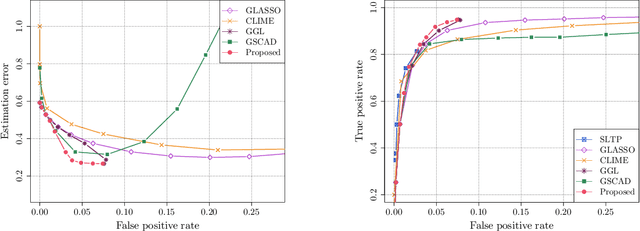
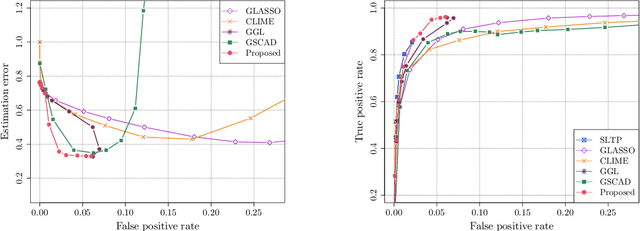
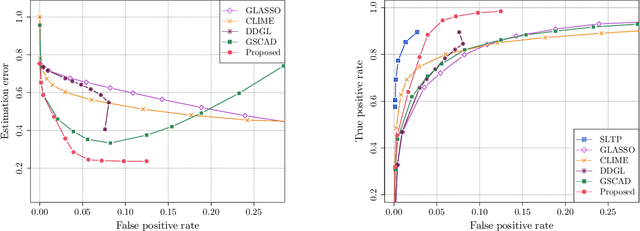
We consider the problem of estimating (diagonally dominant) M-matrices as precision matrices in Gaussian graphical models. Such models have received increasing attention in recent years, and have shown interesting properties, e.g., the maximum likelihood estimator exists with as little as two observations regardless of the underlying dimension. In this paper, we propose an adaptive estimation method, which consists of multiple stages: In the first stage, we solve an $\ell_1$-regularized maximum likelihood estimation problem, which leads to an initial estimate; in the subsequent stages, we iteratively refine the initial estimate by solving a sequence of weighted $\ell_1$-regularized problems. We further establish the theoretical guarantees on the estimation error, which consists of optimization error and statistical error. The optimization error decays to zero at a linear rate, indicating that the estimate is refined iteratively in subsequent stages, and the statistical error characterizes the statistical rate. The proposed method outperforms state-of-the-art methods in estimating precision matrices and identifying graph edges, as evidenced by synthetic and financial time-series data sets.
An Adversarial Active Sampling-based Data Augmentation Framework for Manufacturable Chip Design
Oct 27, 2022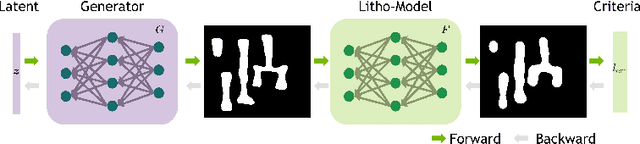
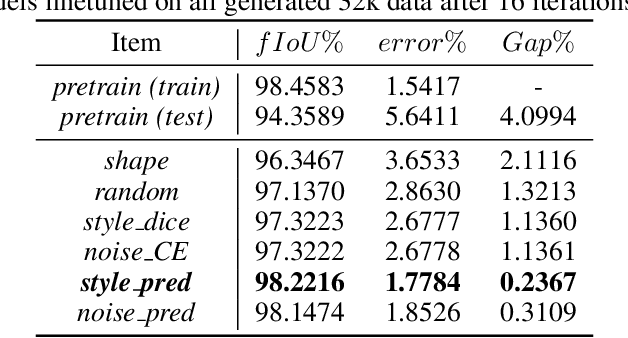
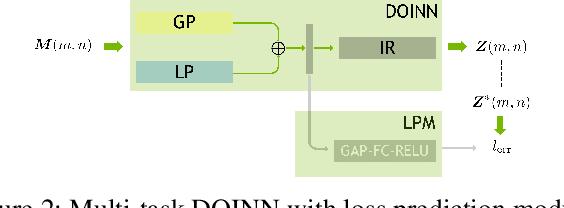
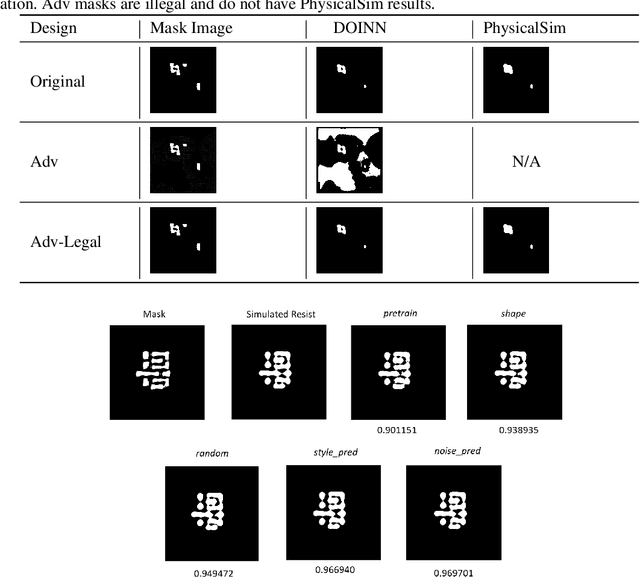
Lithography modeling is a crucial problem in chip design to ensure a chip design mask is manufacturable. It requires rigorous simulations of optical and chemical models that are computationally expensive. Recent developments in machine learning have provided alternative solutions in replacing the time-consuming lithography simulations with deep neural networks. However, the considerable accuracy drop still impedes its industrial adoption. Most importantly, the quality and quantity of the training dataset directly affect the model performance. To tackle this problem, we propose a litho-aware data augmentation (LADA) framework to resolve the dilemma of limited data and improve the machine learning model performance. First, we pretrain the neural networks for lithography modeling and a gradient-friendly StyleGAN2 generator. We then perform adversarial active sampling to generate informative and synthetic in-distribution mask designs. These synthetic mask images will augment the original limited training dataset used to finetune the lithography model for improved performance. Experimental results demonstrate that LADA can successfully exploits the neural network capacity by narrowing down the performance gap between the training and testing data instances.
Joint Waveform and Passive Beamformer Design in Multi-IRS Aided Radar
Oct 27, 2022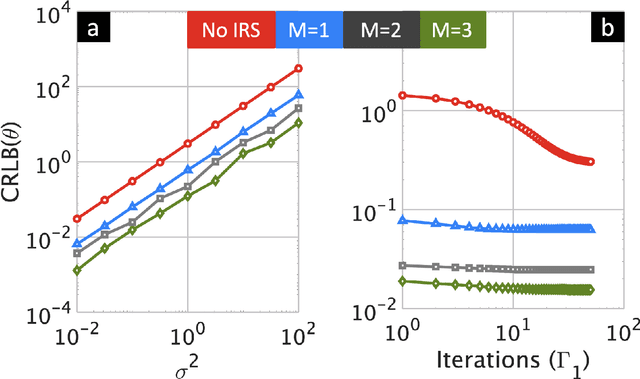
Intelligent reflecting surface (IRS) technology has recently attracted a significant interest in non-light-of-sight radar remote sensing. Prior works have largely focused on designing single IRS beamformers for this problem. For the first time in the literature, this paper considers multi-IRS-aided multiple-input multiple-output (MIMO) radar and jointly designs the transmit unimodular waveforms and optimal IRS beamformers. To this end, we derive the Cramer-Rao lower bound (CRLB) of target direction-of-arrival (DoA) as a performance metric. Unimodular transmit sequences are the preferred waveforms from a hardware perspective. We show that, through suitable transformations, the joint design problem can be reformulated as two unimodular quadratic programs (UQP). To deal with the NP-hard nature of both UQPs, we propose unimodular waveform and beamforming design for multi-IRS radar (UBeR) algorithm that takes advantage of the low-cost power method-like iterations. Numerical experiments illustrate that the MIMO waveforms and phase shifts obtained from our UBeR algorithm are effective in improving the CRLB of DoA estimation.
A Novel Approach for Neuromorphic Vision Data Compression based on Deep Belief Network
Oct 27, 2022
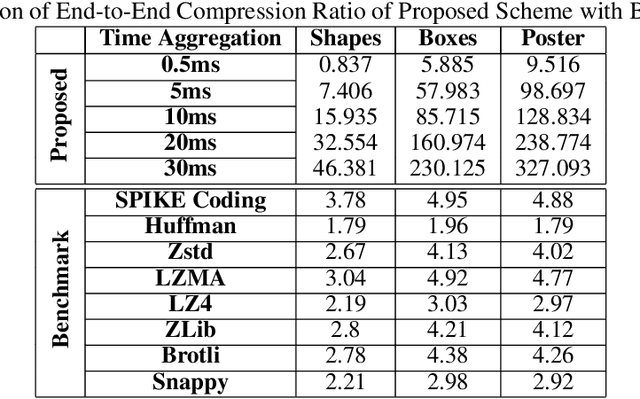
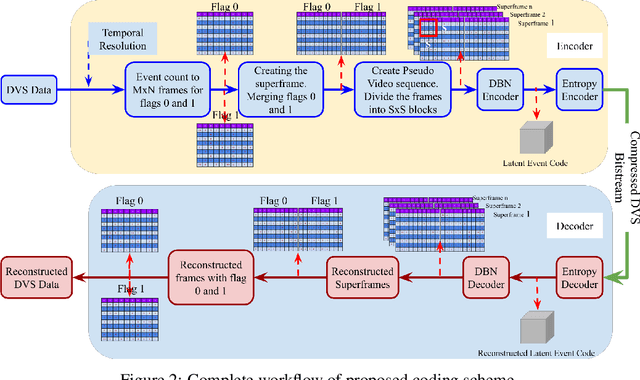
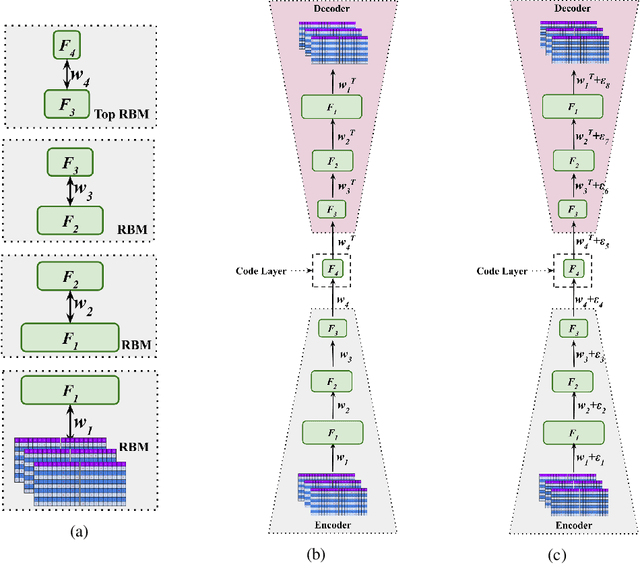
A neuromorphic camera is an image sensor that emulates the human eyes capturing only changes in local brightness levels. They are widely known as event cameras, silicon retinas or dynamic vision sensors (DVS). DVS records asynchronous per-pixel brightness changes, resulting in a stream of events that encode the brightness change's time, location, and polarity. DVS consumes little power and can capture a wider dynamic range with no motion blur and higher temporal resolution than conventional frame-based cameras. Although this method of event capture results in a lower bit rate than traditional video capture, it is further compressible. This paper proposes a novel deep learning-based compression scheme for event data. Using a deep belief network (DBN), the high dimensional event data is reduced into a latent representation and later encoded using an entropy-based coding technique. The proposed scheme is among the first to incorporate deep learning for event compression. It achieves a high compression ratio while maintaining good reconstruction quality outperforming state-of-the-art event data coders and other lossless benchmark techniques.
Private Isotonic Regression
Oct 27, 2022In this paper, we consider the problem of differentially private (DP) algorithms for isotonic regression. For the most general problem of isotonic regression over a partially ordered set (poset) $\mathcal{X}$ and for any Lipschitz loss function, we obtain a pure-DP algorithm that, given $n$ input points, has an expected excess empirical risk of roughly $\mathrm{width}(\mathcal{X}) \cdot \log|\mathcal{X}| / n$, where $\mathrm{width}(\mathcal{X})$ is the width of the poset. In contrast, we also obtain a near-matching lower bound of roughly $(\mathrm{width}(\mathcal{X}) + \log |\mathcal{X}|) / n$, that holds even for approximate-DP algorithms. Moreover, we show that the above bounds are essentially the best that can be obtained without utilizing any further structure of the poset. In the special case of a totally ordered set and for $\ell_1$ and $\ell_2^2$ losses, our algorithm can be implemented in near-linear running time; we also provide extensions of this algorithm to the problem of private isotonic regression with additional structural constraints on the output function.
FCTalker: Fine and Coarse Grained Context Modeling for Expressive Conversational Speech Synthesis
Oct 27, 2022
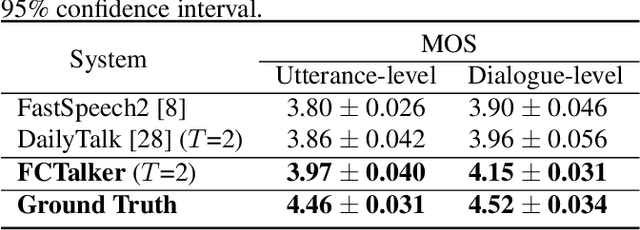
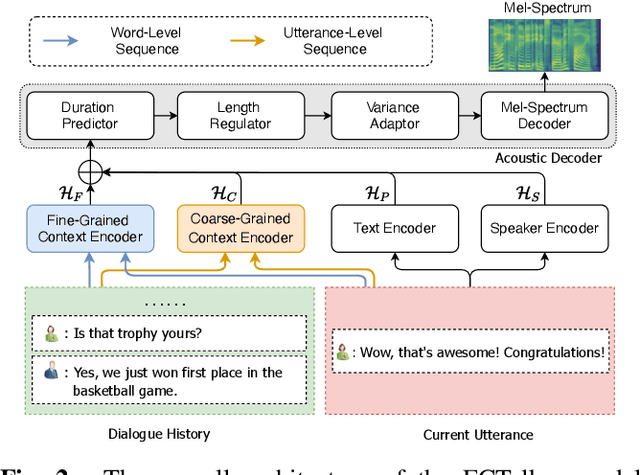
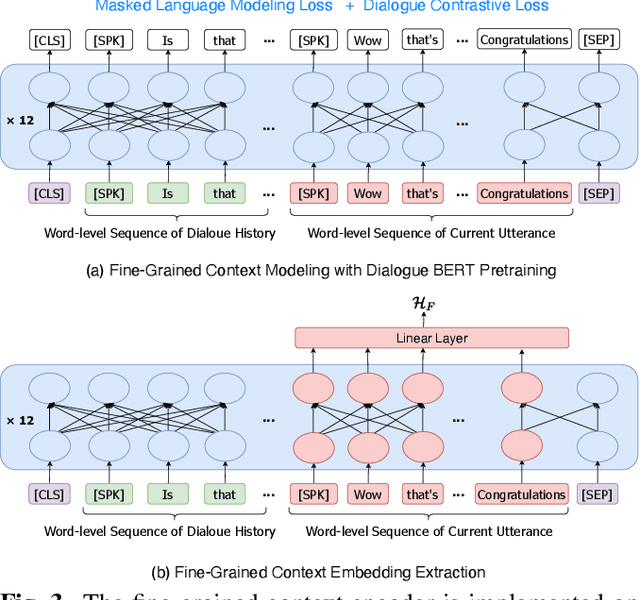
Conversational Text-to-Speech (TTS) aims to synthesis an utterance with the right linguistic and affective prosody in a conversational context. The correlation between the current utterance and the dialogue history at the utterance level was used to improve the expressiveness of synthesized speech. However, the fine-grained information in the dialogue history at the word level also has an important impact on the prosodic expression of an utterance, which has not been well studied in the prior work. Therefore, we propose a novel expressive conversational TTS model, termed as FCTalker, that learn the fine and coarse grained context dependency at the same time during speech generation. Specifically, the FCTalker includes fine and coarse grained encoders to exploit the word and utterance-level context dependency. To model the word-level dependencies between an utterance and its dialogue history, the fine-grained dialogue encoder is built on top of a dialogue BERT model. The experimental results show that the proposed method outperforms all baselines and generates more expressive speech that is contextually appropriate. We release the source code at: https://github.com/walker-hyf/FCTalker.