 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
RLPeri: Accelerating Visual Perimetry Test with Reinforcement Learning and Convolutional Feature Extraction
Mar 08, 2024
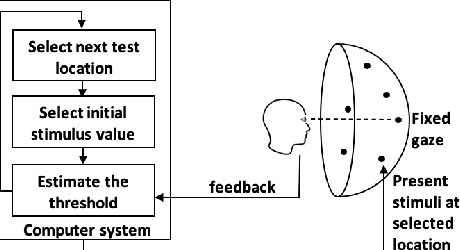
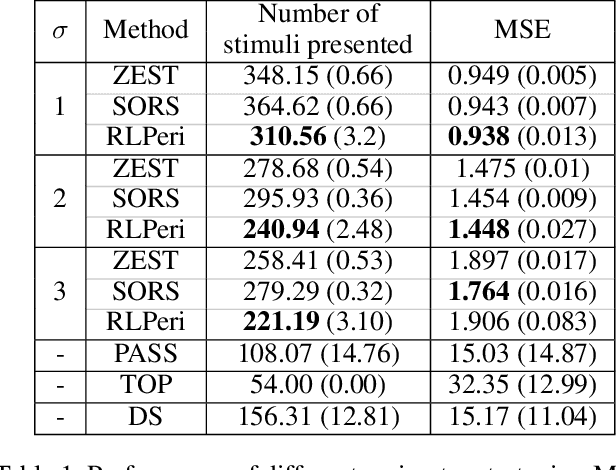
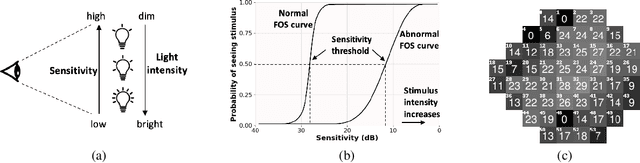
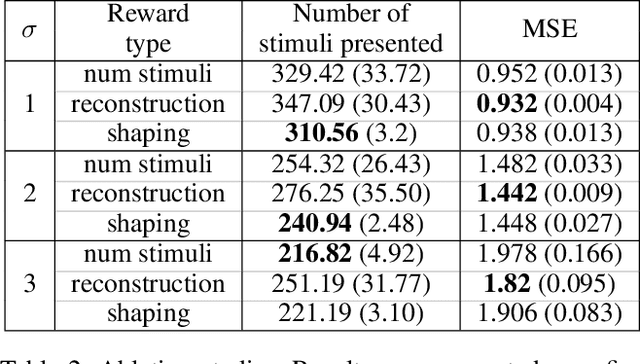
Visual perimetry is an important eye examination that helps detect vision problems caused by ocular or neurological conditions. During the test, a patient's gaze is fixed at a specific location while light stimuli of varying intensities are presented in central and peripheral vision. Based on the patient's responses to the stimuli, the visual field mapping and sensitivity are determined. However, maintaining high levels of concentration throughout the test can be challenging for patients, leading to increased examination times and decreased accuracy. In this work, we present RLPeri, a reinforcement learning-based approach to optimize visual perimetry testing. By determining the optimal sequence of locations and initial stimulus values, we aim to reduce the examination time without compromising accuracy. Additionally, we incorporate reward shaping techniques to further improve the testing performance. To monitor the patient's responses over time during testing, we represent the test's state as a pair of 3D matrices. We apply two different convolutional kernels to extract spatial features across locations as well as features across different stimulus values for each location. Through experiments, we demonstrate that our approach results in a 10-20% reduction in examination time while maintaining the accuracy as compared to state-of-the-art methods. With the presented approach, we aim to make visual perimetry testing more efficient and patient-friendly, while still providing accurate results.
* Published at AAAI-24
Structural Knowledge Informed Continual Multivariate Time Series Forecasting
Feb 20, 2024Recent studies in multivariate time series (MTS) forecasting reveal that explicitly modeling the hidden dependencies among different time series can yield promising forecasting performance and reliable explanations. However, modeling variable dependencies remains underexplored when MTS is continuously accumulated under different regimes (stages). Due to the potential distribution and dependency disparities, the underlying model may encounter the catastrophic forgetting problem, i.e., it is challenging to memorize and infer different types of variable dependencies across different regimes while maintaining forecasting performance. To address this issue, we propose a novel Structural Knowledge Informed Continual Learning (SKI-CL) framework to perform MTS forecasting within a continual learning paradigm, which leverages structural knowledge to steer the forecasting model toward identifying and adapting to different regimes, and selects representative MTS samples from each regime for memory replay. Specifically, we develop a forecasting model based on graph structure learning, where a consistency regularization scheme is imposed between the learned variable dependencies and the structural knowledge while optimizing the forecasting objective over the MTS data. As such, MTS representations learned in each regime are associated with distinct structural knowledge, which helps the model memorize a variety of conceivable scenarios and results in accurate forecasts in the continual learning context. Meanwhile, we develop a representation-matching memory replay scheme that maximizes the temporal coverage of MTS data to efficiently preserve the underlying temporal dynamics and dependency structures of each regime. Thorough empirical studies on synthetic and real-world benchmarks validate SKI-CL's efficacy and advantages over the state-of-the-art for continual MTS forecasting tasks.
Physics-constrained Active Learning for Soil Moisture Estimation and Optimal Sensor Placement
Mar 12, 2024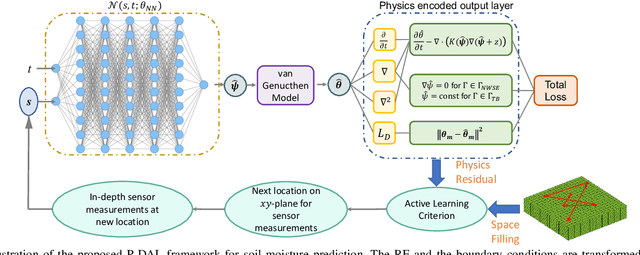
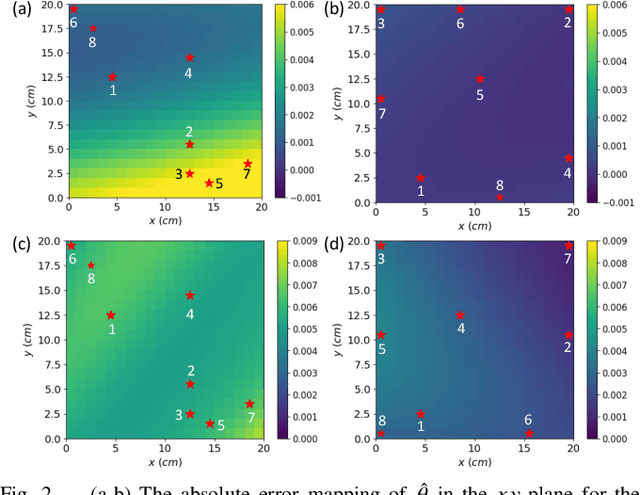
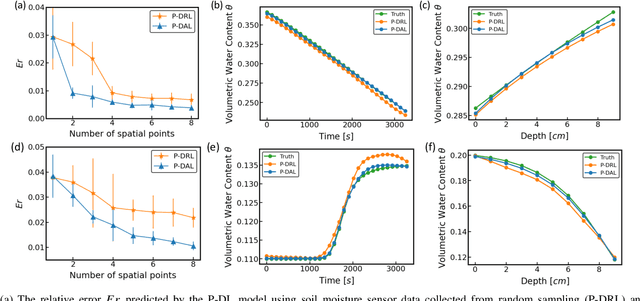
Soil moisture is a crucial hydrological state variable that has significant importance to the global environment and agriculture. Precise monitoring of soil moisture in crop fields is critical to reducing agricultural drought and improving crop yield. In-situ soil moisture sensors, which are buried at pre-determined depths and distributed across the field, are promising solutions for monitoring soil moisture. However, high-density sensor deployment is neither economically feasible nor practical. Thus, to achieve a higher spatial resolution of soil moisture dynamics using a limited number of sensors, we integrate a physics-based agro-hydrological model based on Richards' equation in a physics-constrained deep learning framework to accurately predict soil moisture dynamics in the soil's root zone. This approach ensures that soil moisture estimates align well with sensor observations while obeying physical laws at the same time. Furthermore, to strategically identify the locations for sensor placement, we introduce a novel active learning framework that combines space-filling design and physics residual-based sampling to maximize data acquisition potential with limited sensors. Our numerical results demonstrate that integrating Physics-constrained Deep Learning (P-DL) with an active learning strategy within a unified framework--named the Physics-constrained Active Learning (P-DAL) framework--significantly improves the predictive accuracy and effectiveness of field-scale soil moisture monitoring using in-situ sensors.
VANP: Learning Where to See for Navigation with Self-Supervised Vision-Action Pre-Training
Mar 12, 2024
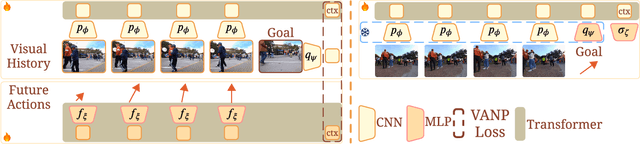

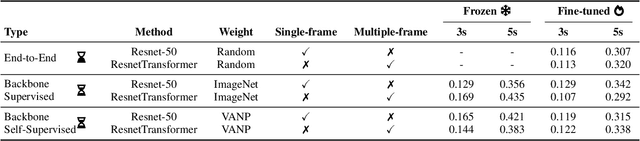
Humans excel at efficiently navigating through crowds without collision by focusing on specific visual regions relevant to navigation. However, most robotic visual navigation methods rely on deep learning models pre-trained on vision tasks, which prioritize salient objects -- not necessarily relevant to navigation and potentially misleading. Alternative approaches train specialized navigation models from scratch, requiring significant computation. On the other hand, self-supervised learning has revolutionized computer vision and natural language processing, but its application to robotic navigation remains underexplored due to the difficulty of defining effective self-supervision signals. Motivated by these observations, in this work, we propose a Self-Supervised Vision-Action Model for Visual Navigation Pre-Training (VANP). Instead of detecting salient objects that are beneficial for tasks such as classification or detection, VANP learns to focus only on specific visual regions that are relevant to the navigation task. To achieve this, VANP uses a history of visual observations, future actions, and a goal image for self-supervision, and embeds them using two small Transformer Encoders. Then, VANP maximizes the information between the embeddings by using a mutual information maximization objective function. We demonstrate that most VANP-extracted features match with human navigation intuition. VANP achieves comparable performance as models learned end-to-end with half the training time and models trained on a large-scale, fully supervised dataset, i.e., ImageNet, with only 0.08% data.
ClickVOS: Click Video Object Segmentation
Mar 10, 2024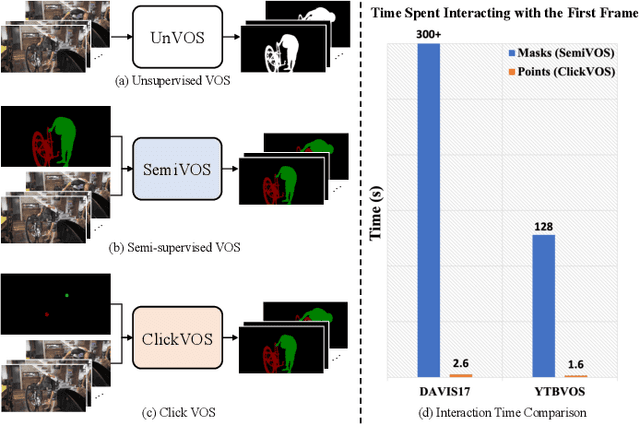
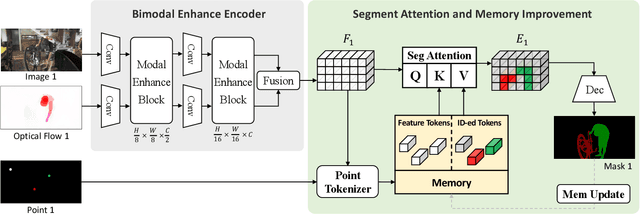
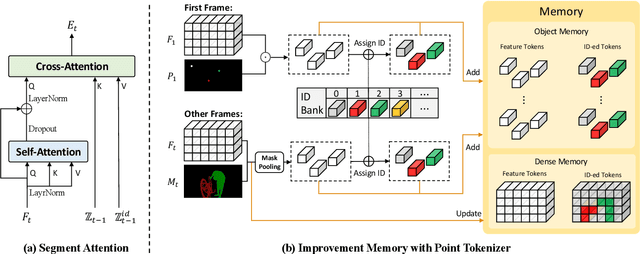
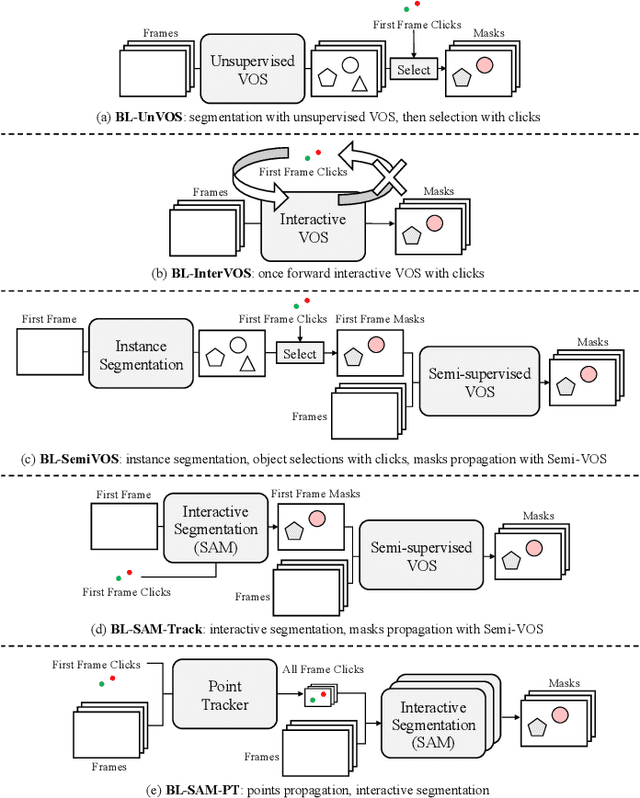
Video Object Segmentation (VOS) task aims to segment objects in videos. However, previous settings either require time-consuming manual masks of target objects at the first frame during inference or lack the flexibility to specify arbitrary objects of interest. To address these limitations, we propose the setting named Click Video Object Segmentation (ClickVOS) which segments objects of interest across the whole video according to a single click per object in the first frame. And we provide the extended datasets DAVIS-P and YouTubeVOSP that with point annotations to support this task. ClickVOS is of significant practical applications and research implications due to its only 1-2 seconds interaction time for indicating an object, comparing annotating the mask of an object needs several minutes. However, ClickVOS also presents increased challenges. To address this task, we propose an end-to-end baseline approach named called Attention Before Segmentation (ABS), motivated by the attention process of humans. ABS utilizes the given point in the first frame to perceive the target object through a concise yet effective segmentation attention. Although the initial object mask is possibly inaccurate, in our ABS, as the video goes on, the initially imprecise object mask can self-heal instead of deteriorating due to error accumulation, which is attributed to our designed improvement memory that continuously records stable global object memory and updates detailed dense memory. In addition, we conduct various baseline explorations utilizing off-the-shelf algorithms from related fields, which could provide insights for the further exploration of ClickVOS. The experimental results demonstrate the superiority of the proposed ABS approach. Extended datasets and codes will be available at https://github.com/PinxueGuo/ClickVOS.
Improving the Successful Robotic Grasp Detection Using Convolutional Neural Networks
Mar 08, 2024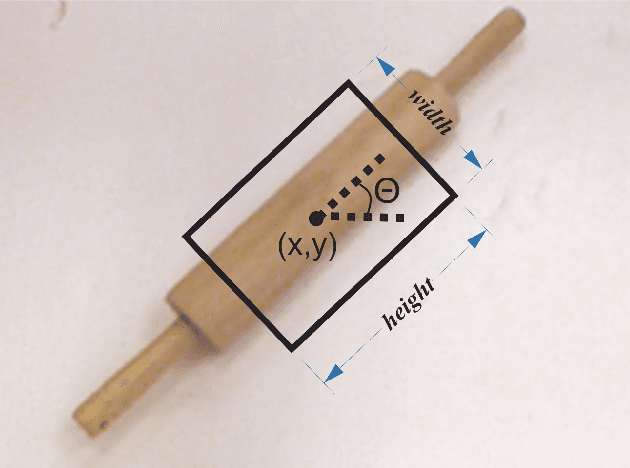

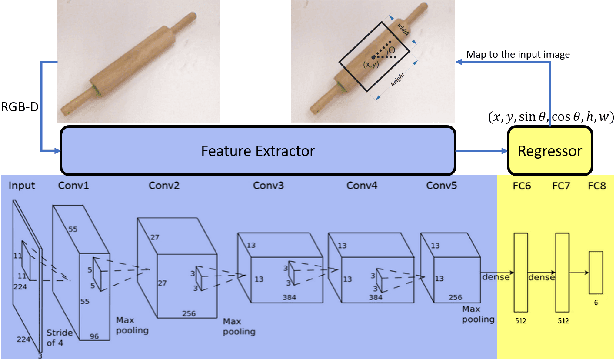
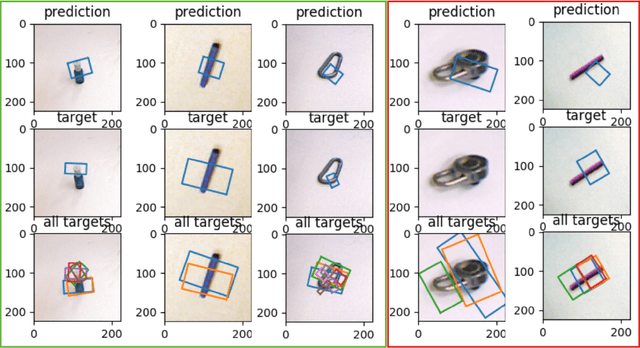
Robotic grasp should be carried out in a real-time manner by proper accuracy. Perception is the first and significant step in this procedure. This paper proposes an improved pipeline model trying to detect grasp as a rectangle representation for different seen or unseen objects. It helps the robot to start control procedures from nearer to the proper part of the object. The main idea consists in pre-processing, output normalization, and data augmentation to improve accuracy by 4.3 percent without making the system slow. Also, a comparison has been conducted over different pre-trained models like AlexNet, ResNet, Vgg19, which are the most famous feature extractors for image processing in object detection. Although AlexNet has less complexity than other ones, it outperformed them, which helps the real-time property.
LHMap-loc: Cross-Modal Monocular Localization Using LiDAR Point Cloud Heat Map
Mar 11, 2024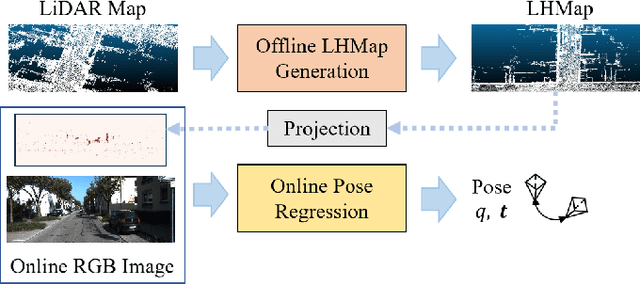
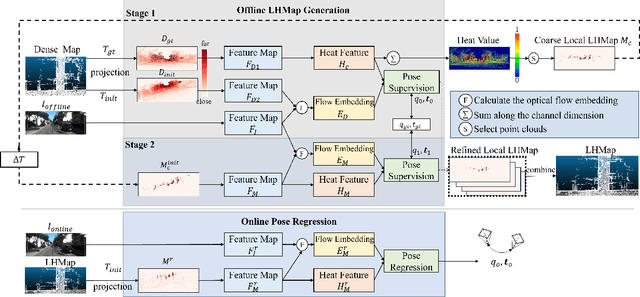
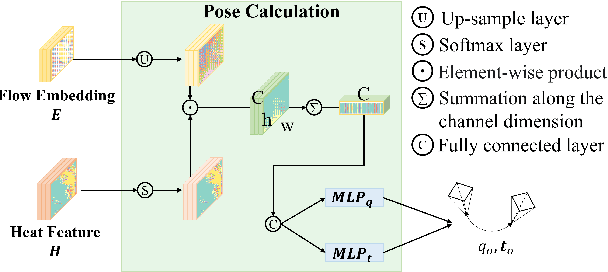

Localization using a monocular camera in the pre-built LiDAR point cloud map has drawn increasing attention in the field of autonomous driving and mobile robotics. However, there are still many challenges (e.g. difficulties of map storage, poor localization robustness in large scenes) in accurately and efficiently implementing cross-modal localization. To solve these problems, a novel pipeline termed LHMap-loc is proposed, which achieves accurate and efficient monocular localization in LiDAR maps. Firstly, feature encoding is carried out on the original LiDAR point cloud map by generating offline heat point clouds, by which the size of the original LiDAR map is compressed. Then, an end-to-end online pose regression network is designed based on optical flow estimation and spatial attention to achieve real-time monocular visual localization in a pre-built map. In addition, a series of experiments have been conducted to prove the effectiveness of the proposed method. Our code is available at: https://github.com/IRMVLab/LHMap-loc.
FreGS: 3D Gaussian Splatting with Progressive Frequency Regularization
Mar 11, 2024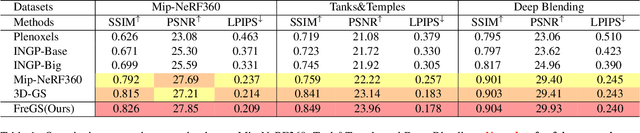
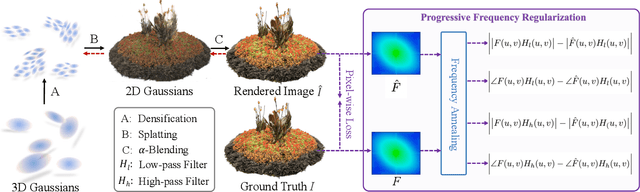
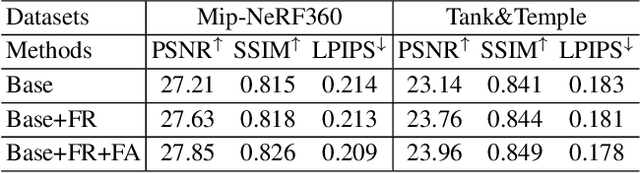
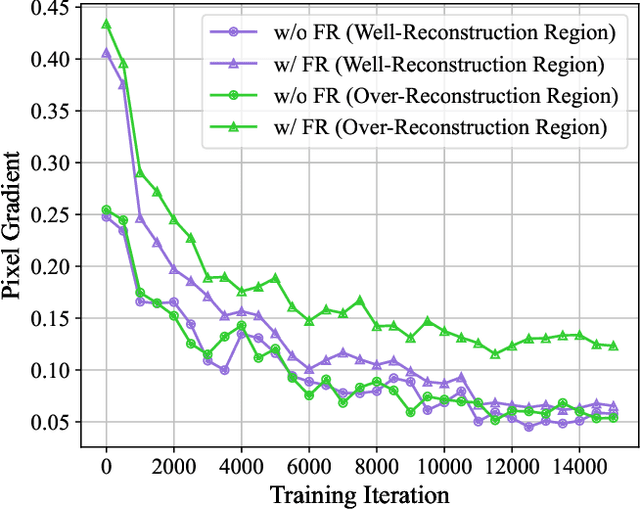
3D Gaussian splatting has achieved very impressive performance in real-time novel view synthesis. However, it often suffers from over-reconstruction during Gaussian densification where high-variance image regions are covered by a few large Gaussians only, leading to blur and artifacts in the rendered images. We design a progressive frequency regularization (FreGS) technique to tackle the over-reconstruction issue within the frequency space. Specifically, FreGS performs coarse-to-fine Gaussian densification by exploiting low-to-high frequency components that can be easily extracted with low-pass and high-pass filters in the Fourier space. By minimizing the discrepancy between the frequency spectrum of the rendered image and the corresponding ground truth, it achieves high-quality Gaussian densification and alleviates the over-reconstruction of Gaussian splatting effectively. Experiments over multiple widely adopted benchmarks (e.g., Mip-NeRF360, Tanks-and-Temples and Deep Blending) show that FreGS achieves superior novel view synthesis and outperforms the state-of-the-art consistently.
A cascaded deep network for automated tumor detection and segmentation in clinical PET imaging of diffuse large B-cell lymphoma
Mar 11, 2024Accurate detection and segmentation of diffuse large B-cell lymphoma (DLBCL) from PET images has important implications for estimation of total metabolic tumor volume, radiomics analysis, surgical intervention and radiotherapy. Manual segmentation of tumors in whole-body PET images is time-consuming, labor-intensive and operator-dependent. In this work, we develop and validate a fast and efficient three-step cascaded deep learning model for automated detection and segmentation of DLBCL tumors from PET images. As compared to a single end-to-end network for segmentation of tumors in whole-body PET images, our three-step model is more effective (improves 3D Dice score from 58.9% to 78.1%) since each of its specialized modules, namely the slice classifier, the tumor detector and the tumor segmentor, can be trained independently to a high degree of skill to carry out a specific task, rather than a single network with suboptimal performance on overall segmentation.
* 8 pages, 3 figures, 3 tables
A Collision Cone Approach for Control Barrier Functions
Mar 11, 2024
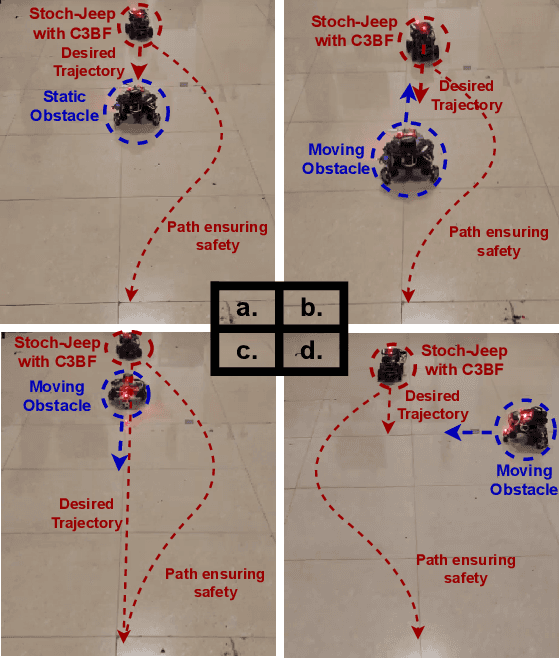
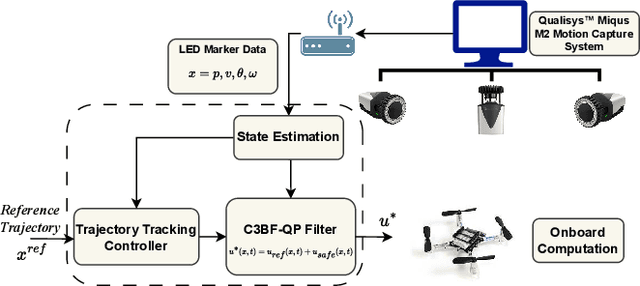
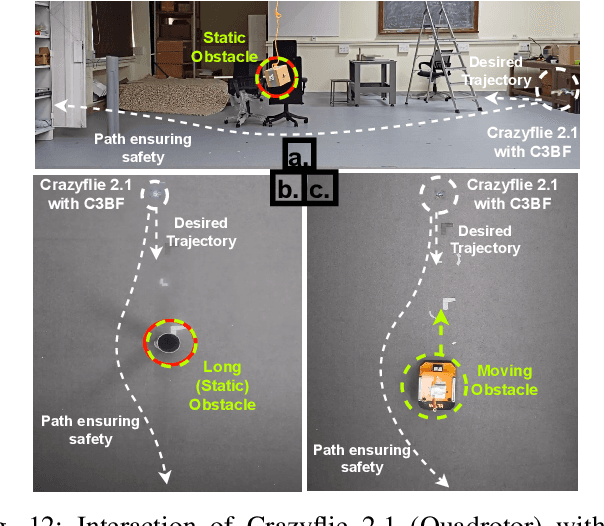
This work presents a unified approach for collision avoidance using Collision-Cone Control Barrier Functions (CBFs) in both ground (UGV) and aerial (UAV) unmanned vehicles. We propose a novel CBF formulation inspired by collision cones, to ensure safety by constraining the relative velocity between the vehicle and the obstacle to always point away from each other. The efficacy of this approach is demonstrated through simulations and hardware implementations on the TurtleBot, Stoch-Jeep, and Crazyflie 2.1 quadrotor robot, showcasing its effectiveness in avoiding collisions with dynamic obstacles in both ground and aerial settings. The real-time controller is developed using CBF Quadratic Programs (CBF-QPs). Comparative analysis with the state-of-the-art CBFs highlights the less conservative nature of the proposed approach. Overall, this research contributes to a novel control formation that can give a guarantee for collision avoidance in unmanned vehicles by modifying the control inputs from existing path-planning controllers.