 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShield-Loco: Shielding Locomotion Policies with Predictive Safety Filtering
Jun 05, 2026Reinforcement learning (RL) policies enable dynamic legged locomotion but lack mechanisms to avoid violations of safety constraints that are absent during training. Large-scale offline safe learning is impractical for covering all edge cases. Existing safety frameworks either rely on reduced-order models that cannot reason about whole-body behaviors or require conservative recovery controllers that degrade task performance. We propose a predictive safety filter that post-hoc filters the nominal contact locations fed to the RL policy. When a collision is predicted, a sampling-based optimizer asynchronously searches for safer contact sequences using a full-physics model, while a learned value function bootstraps long-horizon returns. Our three algorithmic components (geometric projection of sampled contacts, momentum-augmented updates, and replica-exchange) make the optimization tractable in a discontinuous contact landscape. We validate the filter on a quadruped robot in dense, cluttered environments, both in simulation and in the real world, showing substantial reductions in safety violations with minimal deviation from the nominal input.
Energy-Efficient Quadruped Locomotion with Compliant Feet
May 14, 2026Quadruped robots are often designed with rigid feet to simplify control and maintain stable contact during locomotion. While this approach is straightforward, it limits the ability of the legs to absorb impact forces and reuse stored elastic energy, leading to higher energy expenditure during locomotion. To explore whether compliant feet can provide an advantage, we integrate foot compliance into a reinforcement learning (RL) locomotion controller and study its effect on walking efficiency. In simulation, we train eight policies corresponding to eight different spring stiffness values and then cross-evaluate their performance by measuring mechanical energy consumed per meter traveled. In experiments done on a developed quadruped, the energy consumption for the intermediate stiffness spring is lower by ~ 17% when compared to a very stiff or a very flexible spring incorporated in the feet, with similar trends appearing in the simulation results. These results indicate that selecting an appropriate foot compliance can improve locomotion efficiency without destabilizing the robot during motion.
A Co-Design Framework for High-Performance Jumping of a Five-Bar Monoped with Actuator Optimization
Apr 07, 2026The performance of legged robots depends strongly on both mechanical design and control, motivating co-design approaches that jointly optimize these parameters. However, most existing co-design studies focus on optimizing link dimensions and transmission ratios while neglecting detailed actuator design, particularly motor and gearbox parameter optimization, and are largely limited to serial open-chain mechanisms. In this work, we present a co-design framework for a planar closed-chain five-bar monoped that jointly optimizes mechanical design, motor and gearbox parameters, and control parameters for dynamic jumping. The objective is to maximize jump distance while minimizing mechanical energy consumption. The framework uses a two-stage optimization approach, where actuator optimization generates a mapping from gear ratio to actuator mass, efficiency, and peak torque, which is then used in co-design optimization of the robot design and control using CMA-ES. Simulation results show an improvement of approximately 42% in jump distance and a 15.8% reduction in mechanical energy consumption compared to a nominal design, demonstrating the effectiveness of the proposed framework in identifying optimal design, actuator, and control parameters for high-performance and energy-efficient planar jumping.
VIP-Loco: A Visually Guided Infinite Horizon Planning Framework for Legged Locomotion
Mar 15, 2026Perceptive locomotion for legged robots requires anticipating and adapting to complex, dynamic environments. Model Predictive Control (MPC) serves as a strong baseline, providing interpretable motion planning with constraint enforcement, but struggles with high-dimensional perceptual inputs and rapidly changing terrain. In contrast, model-free Reinforcement Learning (RL) adapts well across visually challenging scenarios but lacks planning. To bridge this gap, we propose VIP-Loco, a framework that integrates vision-based scene understanding with RL and planning. During training, an internal model maps proprioceptive states and depth images into compact kinodynamic features used by the RL policy. At deployment, the learned models are used within an infinite-horizon MPC formulation, combining adaptability with structured planning. We validate VIP-Loco in simulation on challenging locomotion tasks, including slopes, stairs, crawling, tilting, gap jumping, and climbing, across three robot morphologies: a quadruped (Unitree Go1), a biped (Cassie), and a wheeled-biped (TronA1-W). Through ablations and comparisons with state-of-the-art methods, we show that VIP-Loco unifies planning and perception, enabling robust, interpretable locomotion in diverse environments.
Data-Driven Physics Embedded Dynamics with Predictive Control and Reinforcement Learning for Quadrupeds
Mar 15, 2026State of the art quadrupedal locomotion approaches integrate Model Predictive Control (MPC) with Reinforcement Learning (RL), enabling complex motion capabilities with planning and terrain adaptive behaviors. However, they often face compounding errors over long horizons and have limited interpretability due to the absence of physical inductive biases. We address these issues by integrating Lagrangian Neural Networks (LNNs) into an RL MPC framework, enabling physically consistent dynamics learning. At deployment, our inverse dynamics infinite horizon MPC scheme avoids costly matrix inversions, improving computational efficiency by up to 4x with minimal loss of task performance. We validate our framework through multiple ablations of the proposed LNN and its variants. We show improved sample efficiency, reduced long-horizon error, and faster real time planning compared to unstructured neural dynamics. Lastly, we also test our framework on the Unitree Go1 robot to show real world viability.
STRIDE: Structured Lagrangian and Stochastic Residual Dynamics via Flow Matching
Mar 09, 2026Robotic systems operating in unstructured environments must operate under significant uncertainty arising from intermittent contacts, frictional variability, and unmodeled compliance. While recent model-free approaches have demonstrated impressive performance, many deployment settings still require predictive models that support planning, constraint handling, and online adaptation. Analytical rigid-body models provide strong physical structure but often fail to capture complex interaction effects, whereas purely data-driven models may violate physical consistency, exhibit data bias, and accumulate long-horizon drift. In this work, we propose STRIDE, a dynamics learning framework that explicitly separates conservative rigid-body mechanics from uncertain, effectively stochastic non-conservative interaction effects. The structured component is modeled using a Lagrangian Neural Network (LNN) to preserve energy-consistent inertial dynamics, while residual interaction forces are represented using Conditional Flow Matching (CFM) to capture multi-modal interaction phenomena. The two components are trained jointly end-to-end, enabling the model to retain physical structure while representing complex stochastic behavior. We evaluate STRIDE on systems of increasing complexity, including a pendulum, the Unitree Go1 quadruped, and the Unitree G1 humanoid. Results show 20% reduction in long-horizon prediction error and 30% reduction in contact force prediction error compared to deterministic residual baselines, supporting more reliable model-based control in uncertain robotic environments.
V-OCBF: Learning Safety Filters from Offline Data via Value-Guided Offline Control Barrier Functions
Dec 11, 2025Ensuring safety in autonomous systems requires controllers that satisfy hard, state-wise constraints without relying on online interaction. While existing Safe Offline RL methods typically enforce soft expected-cost constraints, they do not guarantee forward invariance. Conversely, Control Barrier Functions (CBFs) provide rigorous safety guarantees but usually depend on expert-designed barrier functions or full knowledge of the system dynamics. We introduce Value-Guided Offline Control Barrier Functions (V-OCBF), a framework that learns a neural CBF entirely from offline demonstrations. Unlike prior approaches, V-OCBF does not assume access to the dynamics model; instead, it derives a recursive finite-difference barrier update, enabling model-free learning of a barrier that propagates safety information over time. Moreover, V-OCBF incorporates an expectile-based objective that avoids querying the barrier on out-of-distribution actions and restricts updates to the dataset-supported action set. The learned barrier is then used with a Quadratic Program (QP) formulation to synthesize real-time safe control. Across multiple case studies, V-OCBF yields substantially fewer safety violations than baseline methods while maintaining strong task performance, highlighting its scalability for offline synthesis of safety-critical controllers without online interaction or hand-engineered barriers.
Real-Time Gait Adaptation for Quadrupeds using Model Predictive Control and Reinforcement Learning
Oct 23, 2025Model-free reinforcement learning (RL) has enabled adaptable and agile quadruped locomotion; however, policies often converge to a single gait, leading to suboptimal performance. Traditionally, Model Predictive Control (MPC) has been extensively used to obtain task-specific optimal policies but lacks the ability to adapt to varying environments. To address these limitations, we propose an optimization framework for real-time gait adaptation in a continuous gait space, combining the Model Predictive Path Integral (MPPI) algorithm with a Dreamer module to produce adaptive and optimal policies for quadruped locomotion. At each time step, MPPI jointly optimizes the actions and gait variables using a learned Dreamer reward that promotes velocity tracking, energy efficiency, stability, and smooth transitions, while penalizing abrupt gait changes. A learned value function is incorporated as terminal reward, extending the formulation to an infinite-horizon planner. We evaluate our framework in simulation on the Unitree Go1, demonstrating an average reduction of up to 36.48\% in energy consumption across varying target speeds, while maintaining accurate tracking and adaptive, task-appropriate gaits.
COMPAct: Computational Optimization and Automated Modular design of Planetary Actuators
Oct 08, 2025



The optimal design of robotic actuators is a critical area of research, yet limited attention has been given to optimizing gearbox parameters and automating actuator CAD. This paper introduces COMPAct: Computational Optimization and Automated Modular Design of Planetary Actuators, a framework that systematically identifies optimal gearbox parameters for a given motor across four gearbox types, single-stage planetary gearbox (SSPG), compound planetary gearbox (CPG), Wolfrom planetary gearbox (WPG), and double-stage planetary gearbox (DSPG). The framework minimizes mass and actuator width while maximizing efficiency, and further automates actuator CAD generation to enable direct 3D printing without manual redesign. Using this framework, optimal gearbox designs are explored over a wide range of gear ratios, providing insights into the suitability of different gearbox types across various gear ratio ranges. In addition, the framework is used to generate CAD models of all four gearbox types with varying gear ratios and motors. Two actuator types are fabricated and experimentally evaluated through power efficiency, no-load backlash, and transmission stiffness tests. Experimental results indicate that the SSPG actuator achieves a mechanical efficiency of 60-80 %, a no-load backlash of 0.59 deg, and a transmission stiffness of 242.7 Nm/rad, while the CPG actuator demonstrates 60 % efficiency, 2.6 deg backlash, and a stiffness of 201.6 Nm/rad. Code available at: https://anonymous.4open.science/r/COMPAct-SubNum-3408 Video: https://youtu.be/99zOKgxsDho
Signal Temporal Logic Compliant Co-design of Planning and Control
Jul 17, 2025
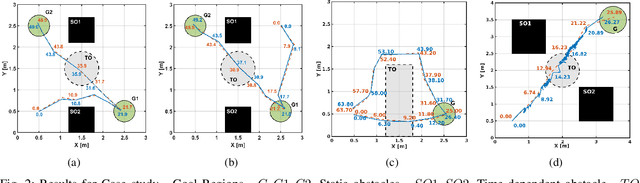

This work presents a novel co-design strategy that integrates trajectory planning and control to handle STL-based tasks in autonomous robots. The method consists of two phases: $(i)$ learning spatio-temporal motion primitives to encapsulate the inherent robot-specific constraints and $(ii)$ constructing an STL-compliant motion plan from these primitives. Initially, we employ reinforcement learning to construct a library of control policies that perform trajectories described by the motion primitives. Then, we map motion primitives to spatio-temporal characteristics. Subsequently, we present a sampling-based STL-compliant motion planning strategy tailored to meet the STL specification. The proposed model-free approach, which generates feasible STL-compliant motion plans across various environments, is validated on differential-drive and quadruped robots across various STL specifications. Demonstration videos are available at https://tinyurl.com/m6zp7rsm.