 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePush-Placement: A Hybrid Approach Integrating Prehensile and Non-Prehensile Manipulation for Object Rearrangement
Feb 14, 2026Efficient tabletop rearrangement remains challenging due to collisions and the need for temporary buffering when target poses are obstructed. Prehensile pick-and-place provides precise control but often requires extra moves, whereas non-prehensile pushing can be more efficient but suffers from complex, imprecise dynamics. This paper proposes push-placement, a hybrid action primitive that uses the grasped object to displace obstructing items while being placed, thereby reducing explicit buffering. The method is integrated into a physics-in-the-loop Monte Carlo Tree Search (MCTS) planner and evaluated in the PyBullet simulator. Empirical results show push-placement reduces the manipulator travel cost by up to 11.12% versus a baseline MCTS planner and 8.56% versus dynamic stacking. These findings indicate that hybrid prehensile/non-prehensile action primitives can substantially improve efficiency in long-horizon rearrangement tasks.
Grasp the Graph (GtG) 2.0: Ensemble of GNNs for High-Precision Grasp Pose Detection in Clutter
May 05, 2025Grasp pose detection in cluttered, real-world environments remains a significant challenge due to noisy and incomplete sensory data combined with complex object geometries. This paper introduces Grasp the Graph 2.0 (GtG 2.0) method, a lightweight yet highly effective hypothesis-and-test robotics grasping framework which leverages an ensemble of Graph Neural Networks for efficient geometric reasoning from point cloud data. Building on the success of GtG 1.0, which demonstrated the potential of Graph Neural Networks for grasp detection but was limited by assumptions of complete, noise-free point clouds and 4-Dof grasping, GtG 2.0 employs a conventional Grasp Pose Generator to efficiently produce 7-Dof grasp candidates. Candidates are assessed with an ensemble Graph Neural Network model which includes points within the gripper jaws (inside points) and surrounding contextual points (outside points). This improved representation boosts grasp detection performance over previous methods using the same generator. GtG 2.0 shows up to a 35% improvement in Average Precision on the GraspNet-1Billion benchmark compared to hypothesis-and-test and Graph Neural Network-based methods, ranking it among the top three frameworks. Experiments with a 3-Dof Delta Parallel robot and Kinect-v1 camera show a success rate of 91% and a clutter completion rate of 100%, demonstrating its flexibility and reliability.
Real-Time Imitation of Human Head Motions, Blinks and Emotions by Nao Robot: A Closed-Loop Approach
Apr 28, 2025



This paper introduces a novel approach for enabling real-time imitation of human head motion by a Nao robot, with a primary focus on elevating human-robot interactions. By using the robust capabilities of the MediaPipe as a computer vision library and the DeepFace as an emotion recognition library, this research endeavors to capture the subtleties of human head motion, including blink actions and emotional expressions, and seamlessly incorporate these indicators into the robot's responses. The result is a comprehensive framework which facilitates precise head imitation within human-robot interactions, utilizing a closed-loop approach that involves gathering real-time feedback from the robot's imitation performance. This feedback loop ensures a high degree of accuracy in modeling head motion, as evidenced by an impressive R2 score of 96.3 for pitch and 98.9 for yaw. Notably, the proposed approach holds promise in improving communication for children with autism, offering them a valuable tool for more effective interaction. In essence, proposed work explores the integration of real-time head imitation and real-time emotion recognition to enhance human-robot interactions, with potential benefits for individuals with unique communication needs.
DTFSal: Audio-Visual Dynamic Token Fusion for Video Saliency Prediction
Apr 16, 2025



Audio-visual saliency prediction aims to mimic human visual attention by identifying salient regions in videos through the integration of both visual and auditory information. Although visual-only approaches have significantly advanced, effectively incorporating auditory cues remains challenging due to complex spatio-temporal interactions and high computational demands. To address these challenges, we propose Dynamic Token Fusion Saliency (DFTSal), a novel audio-visual saliency prediction framework designed to balance accuracy with computational efficiency. Our approach features a multi-scale visual encoder equipped with two novel modules: the Learnable Token Enhancement Block (LTEB), which adaptively weights tokens to emphasize crucial saliency cues, and the Dynamic Learnable Token Fusion Block (DLTFB), which employs a shifting operation to reorganize and merge features, effectively capturing long-range dependencies and detailed spatial information. In parallel, an audio branch processes raw audio signals to extract meaningful auditory features. Both visual and audio features are integrated using our Adaptive Multimodal Fusion Block (AMFB), which employs local, global, and adaptive fusion streams for precise cross-modal fusion. The resulting fused features are processed by a hierarchical multi-decoder structure, producing accurate saliency maps. Extensive evaluations on six audio-visual benchmarks demonstrate that DFTSal achieves SOTA performance while maintaining computational efficiency.
AI-Driven Relocation Tracking in Dynamic Kitchen Environments
Mar 03, 2025



As smart homes become more prevalent in daily life, the ability to understand dynamic environments is essential which is increasingly dependent on AI systems. This study focuses on developing an intelligent algorithm which can navigate a robot through a kitchen, recognizing objects, and tracking their relocation. The kitchen was chosen as the testing ground due to its dynamic nature as objects are frequently moved, rearranged and replaced. Various techniques, such as SLAM feature-based tracking and deep learning-based object detection (e.g., Faster R-CNN), are commonly used for object tracking. Additionally, methods such as optical flow analysis and 3D reconstruction have also been used to track the relocation of objects. These approaches often face challenges when it comes to problems such as lighting variations and partial occlusions, where parts of the object are hidden in some frames but visible in others. The proposed method in this study leverages the YOLOv5 architecture, initialized with pre-trained weights and subsequently fine-tuned on a custom dataset. A novel method was developed, introducing a frame-scoring algorithm which calculates a score for each object based on its location and features within all frames. This scoring approach helps to identify changes by determining the best-associated frame for each object and comparing the results in each scene, overcoming limitations seen in other methods while maintaining simplicity in design. The experimental results demonstrate an accuracy of 97.72%, a precision of 95.83% and a recall of 96.84% for this algorithm, which highlights the efficacy of the model in detecting spatial changes.
Scene Understanding in Pick-and-Place Tasks: Analyzing Transformations Between Initial and Final Scenes
Sep 26, 2024



With robots increasingly collaborating with humans in everyday tasks, it is important to take steps toward robotic systems capable of understanding the environment. This work focuses on scene understanding to detect pick and place tasks given initial and final images from the scene. To this end, a dataset is collected for object detection and pick and place task detection. A YOLOv5 network is subsequently trained to detect the objects in the initial and final scenes. Given the detected objects and their bounding boxes, two methods are proposed to detect the pick and place tasks which transform the initial scene into the final scene. A geometric method is proposed which tracks objects' movements in the two scenes and works based on the intersection of the bounding boxes which moved within scenes. Contrarily, the CNN-based method utilizes a Convolutional Neural Network to classify objects with intersected bounding boxes into 5 classes, showing the spatial relationship between the involved objects. The performed pick and place tasks are then derived from analyzing the experiments with both scenes. Results show that the CNN-based method, using a VGG16 backbone, outscores the geometric method by roughly 12 percentage points in certain scenarios, with an overall success rate of 84.3%.
Improving the Successful Robotic Grasp Detection Using Convolutional Neural Networks
Mar 08, 2024



Robotic grasp should be carried out in a real-time manner by proper accuracy. Perception is the first and significant step in this procedure. This paper proposes an improved pipeline model trying to detect grasp as a rectangle representation for different seen or unseen objects. It helps the robot to start control procedures from nearer to the proper part of the object. The main idea consists in pre-processing, output normalization, and data augmentation to improve accuracy by 4.3 percent without making the system slow. Also, a comparison has been conducted over different pre-trained models like AlexNet, ResNet, Vgg19, which are the most famous feature extractors for image processing in object detection. Although AlexNet has less complexity than other ones, it outperformed them, which helps the real-time property.
AGILE: Approach-based Grasp Inference Learned from Element Decomposition
Feb 06, 2024



Humans, this species expert in grasp detection, can grasp objects by taking into account hand-object positioning information. This work proposes a method to enable a robot manipulator to learn the same, grasping objects in the most optimal way according to how the gripper has approached the object. Built on deep learning, the proposed method consists of two main stages. In order to generalize the network on unseen objects, the proposed Approach-based Grasping Inference involves an element decomposition stage to split an object into its main parts, each with one or more annotated grasps for a particular approach of the gripper. Subsequently, a grasp detection network utilizes the decomposed elements by Mask R-CNN and the information on the approach of the gripper in order to detect the element the gripper has approached and the most optimal grasp. In order to train the networks, the study introduces a robotic grasping dataset collected in the Coppeliasim simulation environment. The dataset involves 10 different objects with annotated element decomposition masks and grasp rectangles. The proposed method acquires a 90% grasp success rate on seen objects and 78% on unseen objects in the Coppeliasim simulation environment. Lastly, simulation-to-reality domain adaptation is performed by applying transformations on the training set collected in simulation and augmenting the dataset, which results in a 70% physical grasp success performance using a Delta parallel robot and a 2 -fingered gripper.
Real-Time Facial Expression Recognition using Facial Landmarks and Neural Networks
Jan 31, 2022


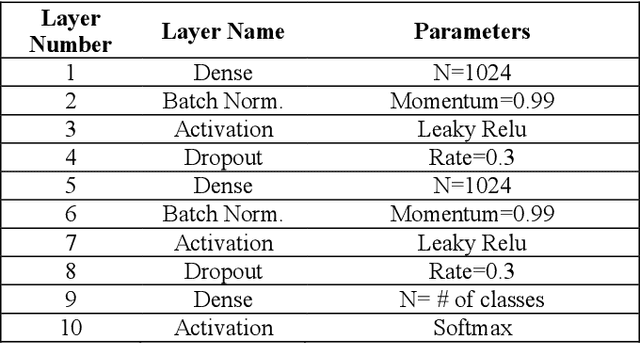
This paper presents a lightweight algorithm for feature extraction, classification of seven different emotions, and facial expression recognition in a real-time manner based on static images of the human face. In this regard, a Multi-Layer Perceptron (MLP) neural network is trained based on the foregoing algorithm. In order to classify human faces, first, some pre-processing is applied to the input image, which can localize and cut out faces from it. In the next step, a facial landmark detection library is used, which can detect the landmarks of each face. Then, the human face is split into upper and lower faces, which enables the extraction of the desired features from each part. In the proposed model, both geometric and texture-based feature types are taken into account. After the feature extraction phase, a normalized vector of features is created. A 3-layer MLP is trained using these feature vectors, leading to 96% accuracy on the test set.
Learning Enhancement of CNNs via Separation Index Maximizing at the First Convolutional Layer
Jan 13, 2022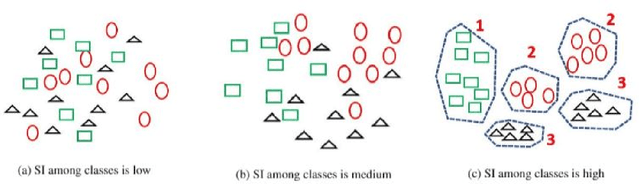
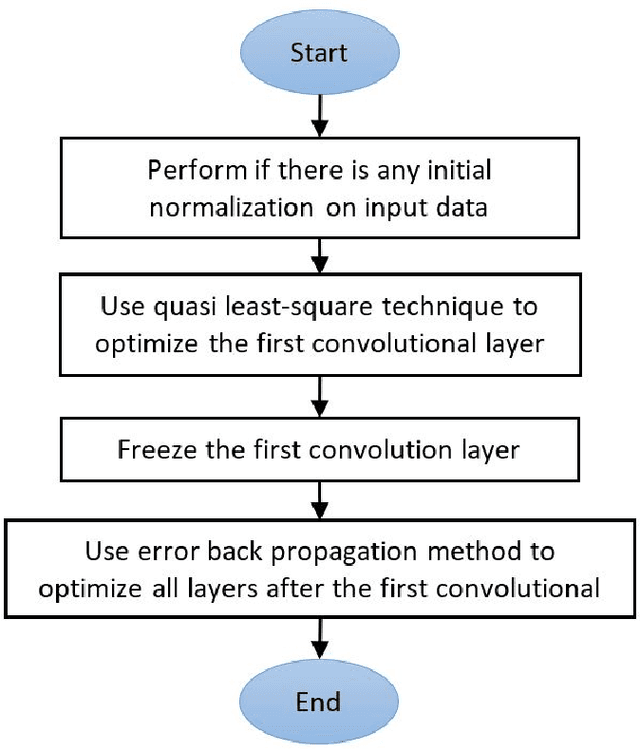

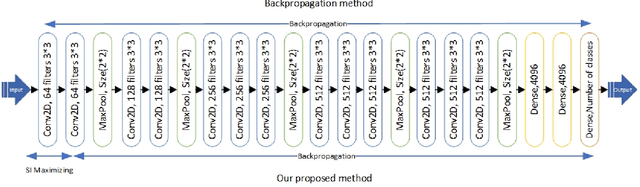
In this paper, a straightforward enhancement learning algorithm based on Separation Index (SI) concept is proposed for Convolutional Neural Networks (CNNs). At first, the SI as a supervised complexity measure is explained its usage in better learning of CNNs for classification problems illustrate. Then, a learning strategy proposes through which the first layer of a CNN is optimized by maximizing the SI, and the further layers are trained through the backpropagation algorithm to learn further layers. In order to maximize the SI at the first layer, A variant of ranking loss is optimized by using the quasi least square error technique. Applying such a learning strategy to some known CNNs and datasets, its enhancement impact in almost all cases is demonstrated.