 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Asymptotically Near-Optimal Hybrid Beamforming for mmWave IRS-Aided MIMO Systems
Mar 14, 2024
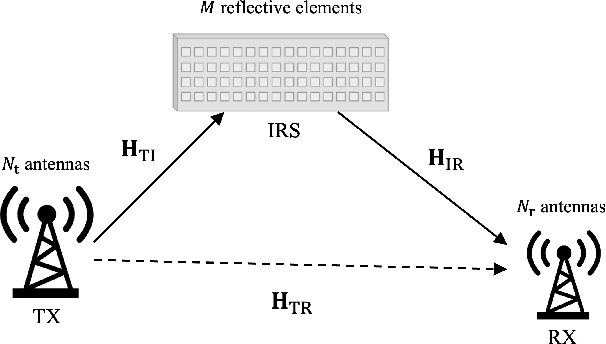
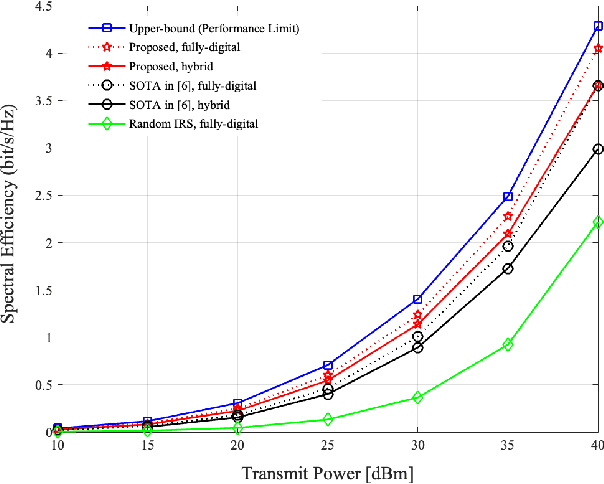
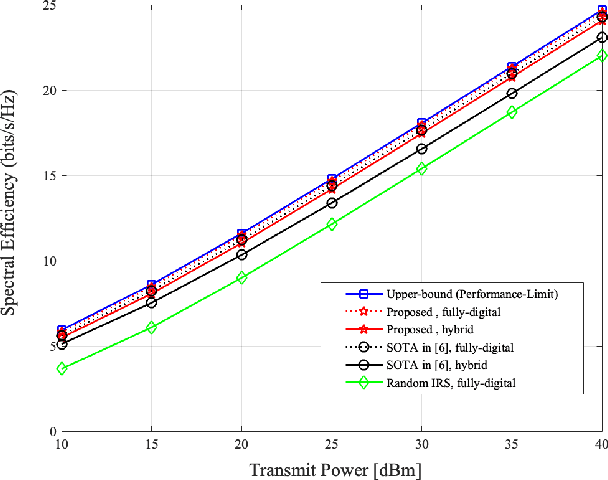
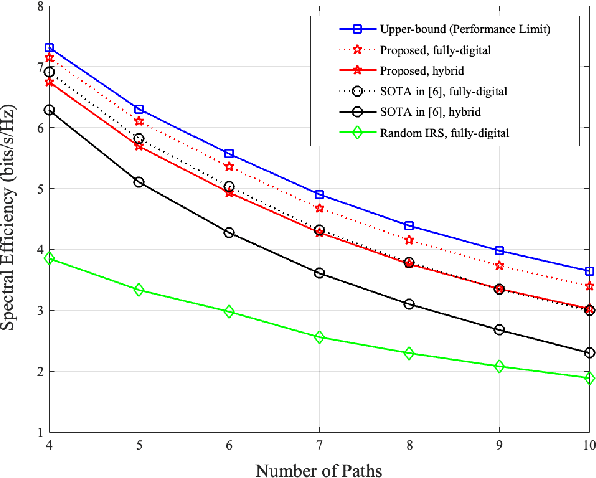
Hybrid beamforming is an emerging technology for massive multiple-input multiple-output (MIMO) systems due to the advantages of lower complexity, cost, and power consumption. Recently, intelligent reflection surface (IRS) has been proposed as the cost-effective technique for robust millimeter-wave (mmWave) MIMO systems. Thus, it is required to jointly optimize a reflection vector and hybrid beamforming matrices for IRS-aided mmWave MIMO systems. Due to the lack of RF chain in the IRS, it is unavailable to acquire the TX-IRS and IRS-RX channels separately. Instead, there are efficient methods to estimate the so-called effective (or cascaded) channel in literature. We for the first time derive the near-optimal solution of the aforementioned joint optimization only using the effective channel. Based on our theoretical analysis, we develop the practical reflection vector and hybrid beamforming matrices by projecting the asymptotic solution into the modulus constraint. Via simulations, it is demonstrated that the proposed construction can outperform the state-of-the-art (SOTA) method, where the latter even requires the knowledge of the TX-IRS ad IRS-RX channels separately. Furthermore, our construction can provide the robustness for channel estimation errors, which is inevitable for practical massive MIMO systems.
A Survey on Federated Learning in Intelligent Transportation Systems
Mar 14, 2024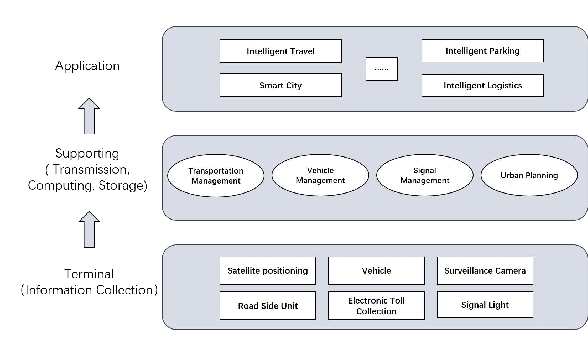
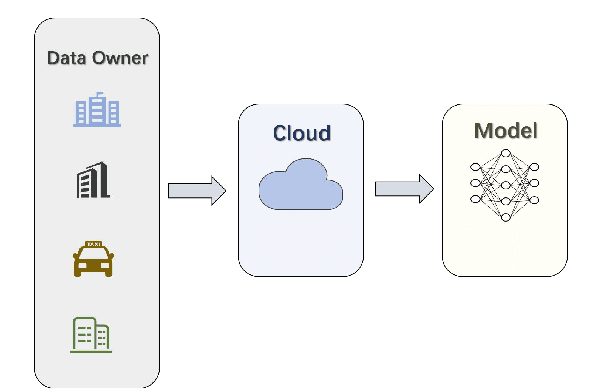
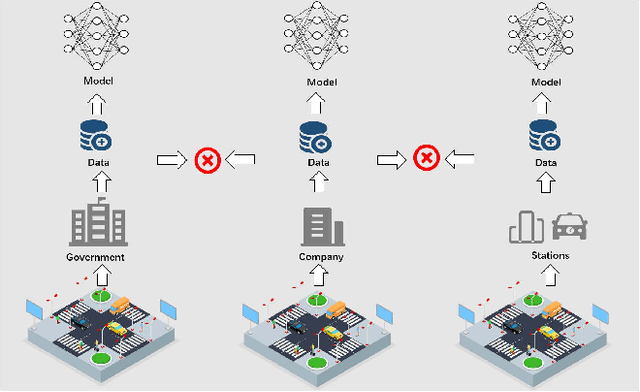
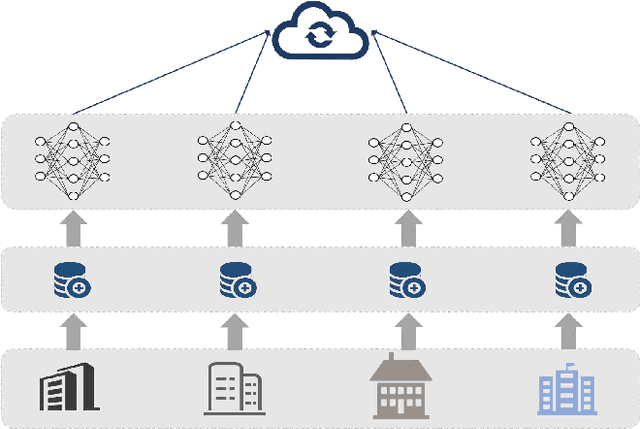
The development of Intelligent Transportation System (ITS) has brought about comprehensive urban traffic information that not only provides convenience to urban residents in their daily lives but also enhances the efficiency of urban road usage, leading to a more harmonious and sustainable urban life. Typical scenarios in ITS mainly include traffic flow prediction, traffic target recognition, and vehicular edge computing. However, most current ITS applications rely on a centralized training approach where users upload source data to a cloud server with high computing power for management and centralized training. This approach has limitations such as poor real-time performance, data silos, and difficulty in guaranteeing data privacy. To address these limitations, federated learning (FL) has been proposed as a promising solution. In this paper, we present a comprehensive review of the application of FL in ITS, with a particular focus on three key scenarios: traffic flow prediction, traffic target recognition, and vehicular edge computing. For each scenario, we provide an in-depth analysis of its key characteristics, current challenges, and specific manners in which FL is leveraged. Moreover, we discuss the benefits that FL can offer as a potential solution to the limitations of the centralized training approach currently used in ITS applications.
Socially Integrated Navigation: A Social Acting Robot with Deep Reinforcement Learning
Mar 14, 2024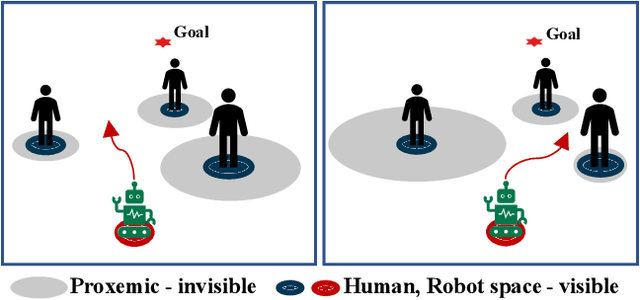
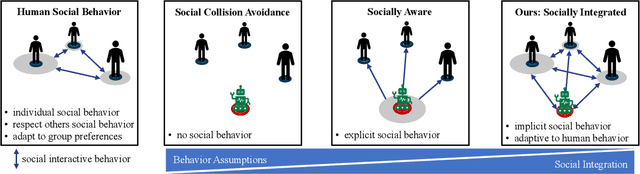
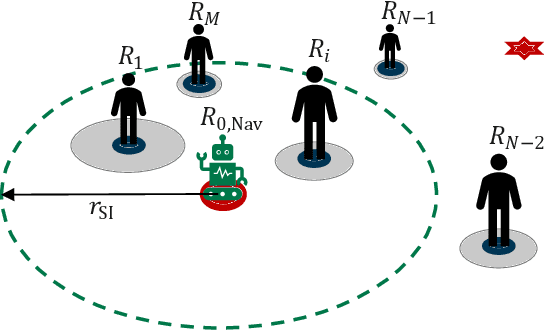

Mobile robots are being used on a large scale in various crowded situations and become part of our society. The socially acceptable navigation behavior of a mobile robot with individual human consideration is an essential requirement for scalable applications and human acceptance. Deep Reinforcement Learning (DRL) approaches are recently used to learn a robot's navigation policy and to model the complex interactions between robots and humans. We propose to divide existing DRL-based navigation approaches based on the robot's exhibited social behavior and distinguish between social collision avoidance with a lack of social behavior and socially aware approaches with explicit predefined social behavior. In addition, we propose a novel socially integrated navigation approach where the robot's social behavior is adaptive and emerges from the interaction with humans. The formulation of our approach is derived from a sociological definition, which states that social acting is oriented toward the acting of others. The DRL policy is trained in an environment where other agents interact socially integrated and reward the robot's behavior individually. The simulation results indicate that the proposed socially integrated navigation approach outperforms a socially aware approach in terms of distance traveled, time to completion, and negative impact on all agents within the environment.
GaussianImage: 1000 FPS Image Representation and Compression by 2D Gaussian Splatting
Mar 14, 2024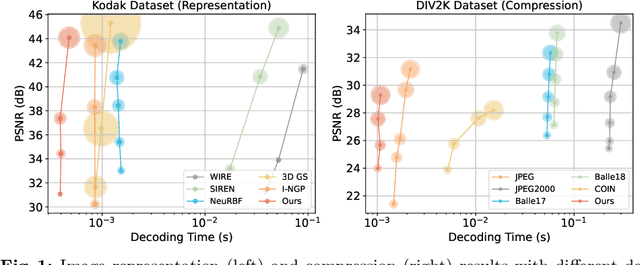
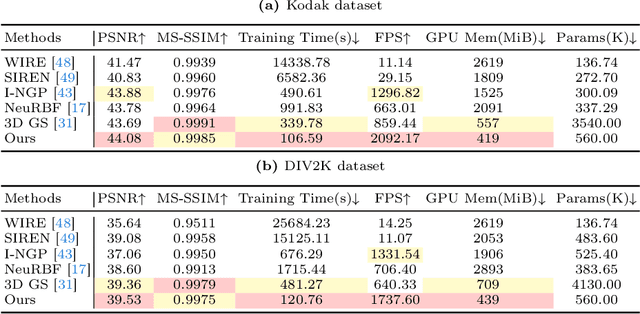

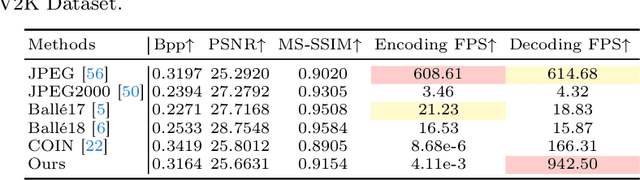
Implicit neural representations (INRs) recently achieved great success in image representation and compression, offering high visual quality and fast rendering speeds with 10-1000 FPS, assuming sufficient GPU resources are available. However, this requirement often hinders their use on low-end devices with limited memory. In response, we propose a groundbreaking paradigm of image representation and compression by 2D Gaussian Splatting, named GaussianImage. We first introduce 2D Gaussian to represent the image, where each Gaussian has 8 parameters including position, covariance and color. Subsequently, we unveil a novel rendering algorithm based on accumulated summation. Remarkably, our method with a minimum of 3$\times$ lower GPU memory usage and 5$\times$ faster fitting time not only rivals INRs (e.g., WIRE, I-NGP) in representation performance, but also delivers a faster rendering speed of 1500-2000 FPS regardless of parameter size. Furthermore, we integrate existing vector quantization technique to build an image codec. Experimental results demonstrate that our codec attains rate-distortion performance comparable to compression-based INRs such as COIN and COIN++, while facilitating decoding speeds of approximately 1000 FPS. Additionally, preliminary proof of concept shows that our codec surpasses COIN and COIN++ in performance when using partial bits-back coding.
Machine learning predicts long-term mortality after acute myocardial infarction using systolic time intervals and routinely collected clinical data
Mar 03, 2024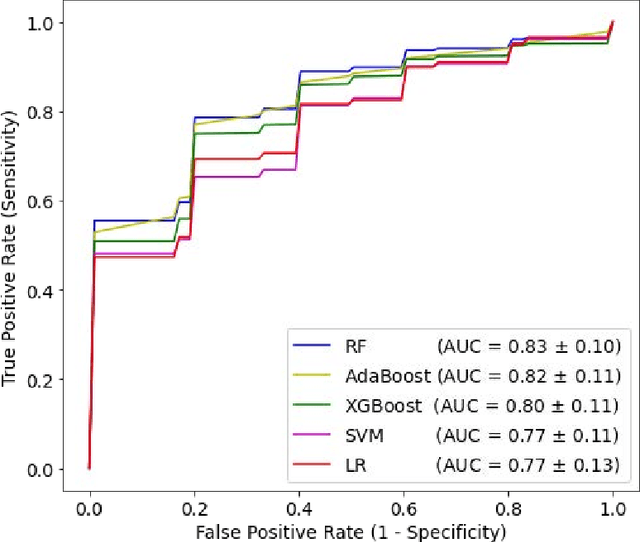
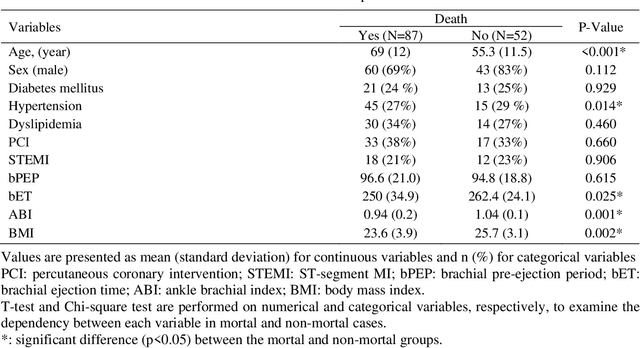
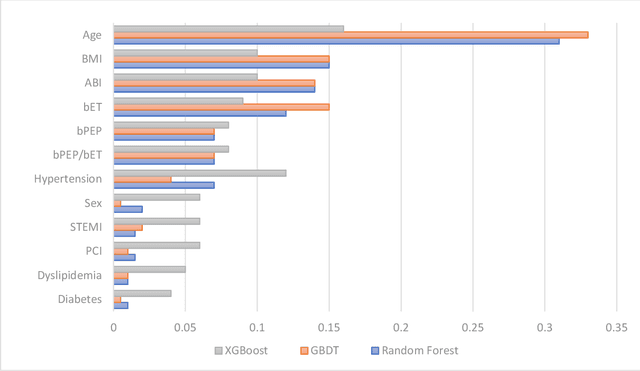
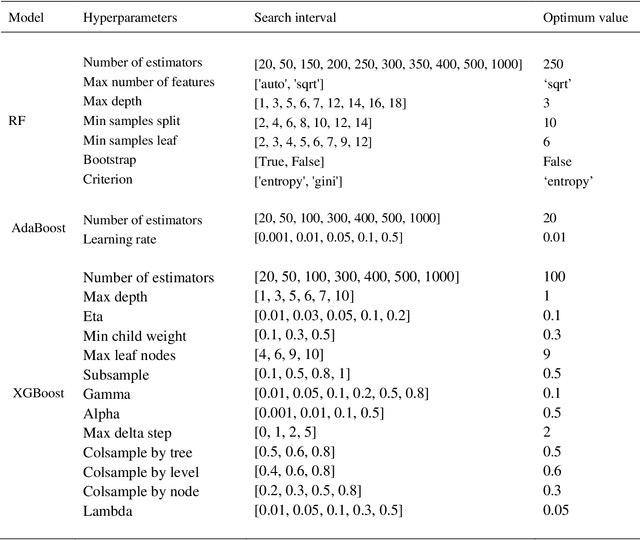
Precise estimation of cardiac patients' current and future comorbidities is an important factor in prioritizing continuous physiological monitoring and new therapies. ML models have shown satisfactory performance in short-term mortality prediction of patients with heart disease, while their utility in long-term predictions is limited. This study aims to investigate the performance of tree-based ML models on long-term mortality prediction and the effect of two recently introduced biomarkers on long-term mortality. This study utilized publicly available data from CCHIA at the Ministry of Health and Welfare, Taiwan, China. Medical records were used to gather demographic and clinical data, including age, gender, BMI, percutaneous coronary intervention (PCI) status, and comorbidities such as hypertension, dyslipidemia, ST-segment elevation myocardial infarction (STEMI), and non-STEMI. Using medical and demographic records as well as two recently introduced biomarkers, brachial pre-ejection period (bPEP) and brachial ejection time (bET), collected from 139 patients with acute myocardial infarction, we investigated the performance of advanced ensemble tree-based ML algorithms (random forest, AdaBoost, and XGBoost) to predict all-cause mortality within 14 years. The developed ML models achieved significantly better performance compared to the baseline LR (C-Statistic, 0.80 for random forest, 0.79 for AdaBoost, and 0.78 for XGBoost, vs 0.77 for LR) (P-RF<0.001, PAdaBoost<0.001, PXGBoost<0.05). Adding bPEP and bET to our feature set significantly improved the algorithms' performance, leading to an absolute increase in C-Statistic of up to 0.03 (C-Statistic, 0.83 for random forest, 0.82 for AdaBoost, and 0.80 for XGBoost, vs 0.74 for LR) (P-RF<0.001, PAdaBoost<0.001, PXGBoost<0.05). This advancement may enable better treatment prioritization for high-risk individuals.
JSTR: Joint Spatio-Temporal Reasoning for Event-based Moving Object Detection
Mar 12, 2024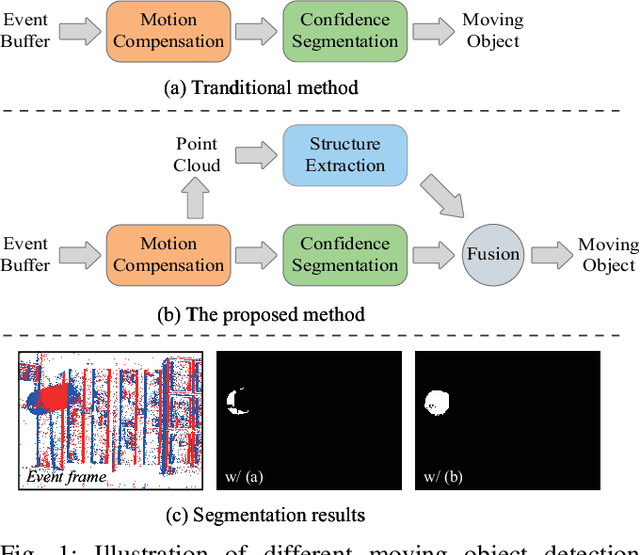
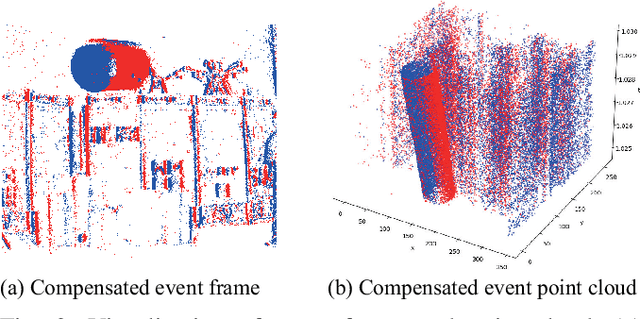
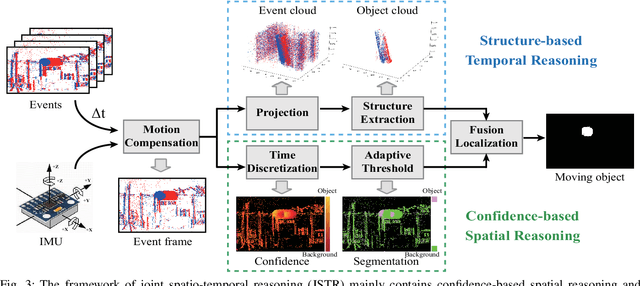

Event-based moving object detection is a challenging task, where static background and moving object are mixed together. Typically, existing methods mainly align the background events to the same spatial coordinate system via motion compensation to distinguish the moving object. However, they neglect the potential spatial tailing effect of moving object events caused by excessive motion, which may affect the structure integrity of the extracted moving object. We discover that the moving object has a complete columnar structure in the point cloud composed of motion-compensated events along the timestamp. Motivated by this, we propose a novel joint spatio-temporal reasoning method for event-based moving object detection. Specifically, we first compensate the motion of background events using inertial measurement unit. In spatial reasoning stage, we project the compensated events into the same image coordinate, discretize the timestamp of events to obtain a time image that can reflect the motion confidence, and further segment the moving object through adaptive threshold on the time image. In temporal reasoning stage, we construct the events into a point cloud along timestamp, and use RANSAC algorithm to extract the columnar shape in the cloud for peeling off the background. Finally, we fuse the results from the two reasoning stages to extract the final moving object region. This joint spatio-temporal reasoning framework can effectively detect the moving object from motion confidence and geometric structure. Moreover, we conduct extensive experiments on various datasets to verify that the proposed method can improve the moving object detection accuracy by 13\%.
Architectural Implications of Neural Network Inference for High Data-Rate, Low-Latency Scientific Applications
Mar 13, 2024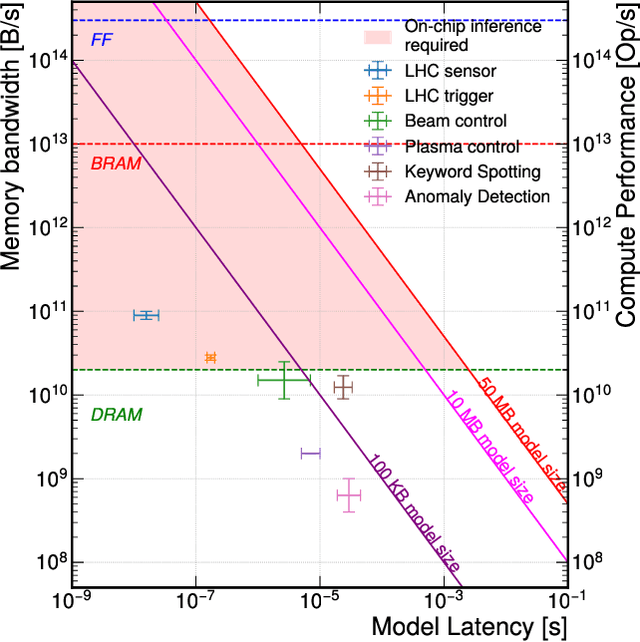

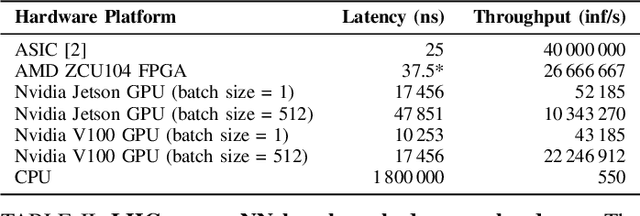
With more scientific fields relying on neural networks (NNs) to process data incoming at extreme throughputs and latencies, it is crucial to develop NNs with all their parameters stored on-chip. In many of these applications, there is not enough time to go off-chip and retrieve weights. Even more so, off-chip memory such as DRAM does not have the bandwidth required to process these NNs as fast as the data is being produced (e.g., every 25 ns). As such, these extreme latency and bandwidth requirements have architectural implications for the hardware intended to run these NNs: 1) all NN parameters must fit on-chip, and 2) codesigning custom/reconfigurable logic is often required to meet these latency and bandwidth constraints. In our work, we show that many scientific NN applications must run fully on chip, in the extreme case requiring a custom chip to meet such stringent constraints.
Bifurcated Attention for Single-Context Large-Batch Sampling
Mar 13, 2024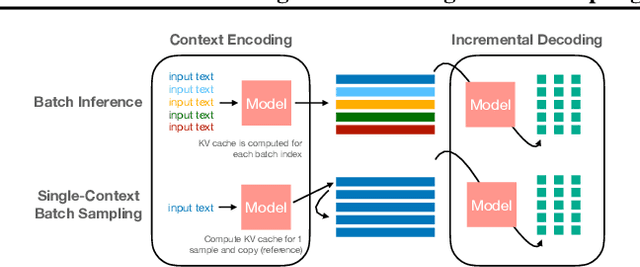
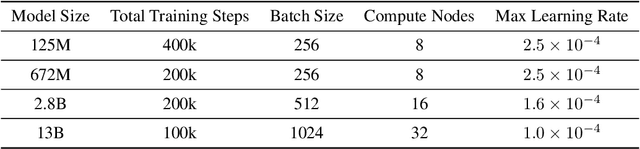
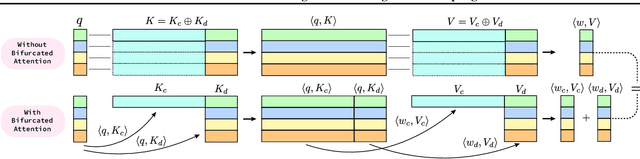
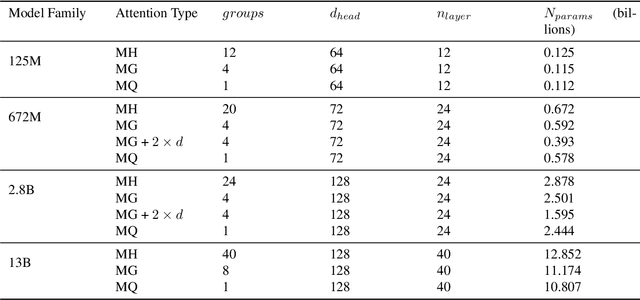
In our study, we present bifurcated attention, a method developed for language model inference in single-context batch sampling contexts. This approach aims to reduce redundant memory IO costs, a significant factor in latency for high batch sizes and long context lengths. Bifurcated attention achieves this by dividing the attention mechanism during incremental decoding into two distinct GEMM operations, focusing on the KV cache from prefill and the decoding process. This method ensures precise computation and maintains the usual computational load (FLOPs) of standard attention mechanisms, but with reduced memory IO. Bifurcated attention is also compatible with multi-query attention mechanism known for reduced memory IO for KV cache, further enabling higher batch size and context length. The resulting efficiency leads to lower latency, improving suitability for real-time applications, e.g., enabling massively-parallel answer generation without substantially increasing latency, enhancing performance when integrated with postprocessing techniques such as reranking.
Reconstructing Blood Flow in Data-Poor Regimes: A Vasculature Network Kernel for Gaussian Process Regression
Mar 14, 2024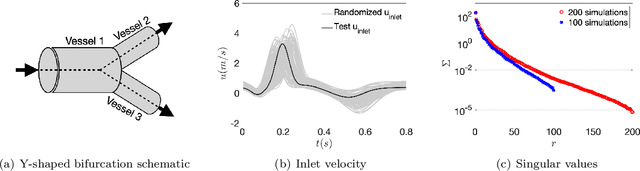
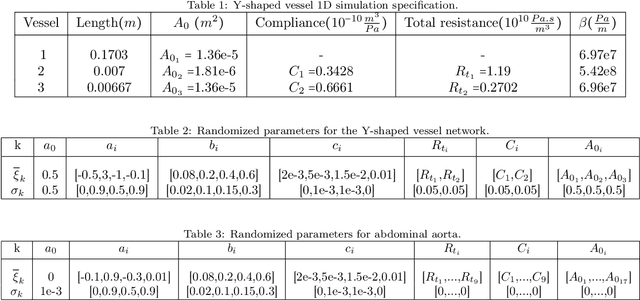
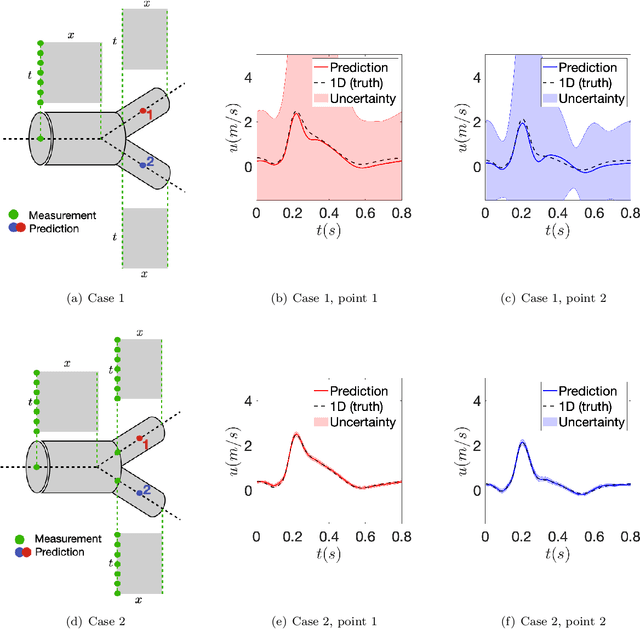
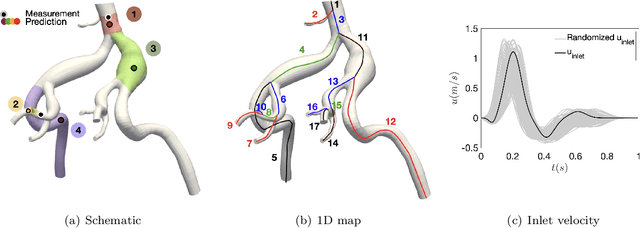
Blood flow reconstruction in the vasculature is important for many clinical applications. However, in clinical settings, the available data are often quite limited. For instance, Transcranial Doppler ultrasound (TCD) is a noninvasive clinical tool that is commonly used in the clinical settings to measure blood velocity waveform at several locations on brain's vasculature. This amount of data is grossly insufficient for training machine learning surrogate models, such as deep neural networks or Gaussian process regression. In this work, we propose a Gaussian process regression approach based on physics-informed kernels, enabling near-real-time reconstruction of blood flow in data-poor regimes. We introduce a novel methodology to reconstruct the kernel within the vascular network, which is a non-Euclidean space. The proposed kernel encodes both spatiotemporal and vessel-to-vessel correlations, thus enabling blood flow reconstruction in vessels that lack direct measurements. We demonstrate that any prediction made with the proposed kernel satisfies the conservation of mass principle. The kernel is constructed by running stochastic one-dimensional blood flow simulations, where the stochasticity captures the epistemic uncertainties, such as lack of knowledge about boundary conditions and uncertainties in vasculature geometries. We demonstrate the performance of the model on three test cases, namely, a simple Y-shaped bifurcation, abdominal aorta, and the Circle of Willis in the brain.
VIRUS-NeRF -- Vision, InfraRed and UltraSonic based Neural Radiance Fields
Mar 14, 2024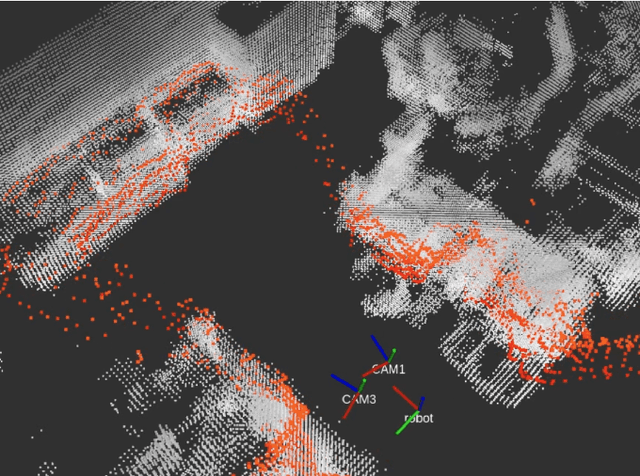

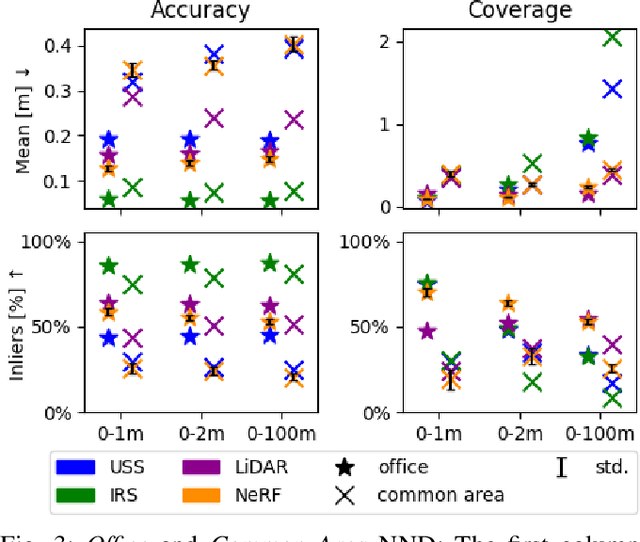
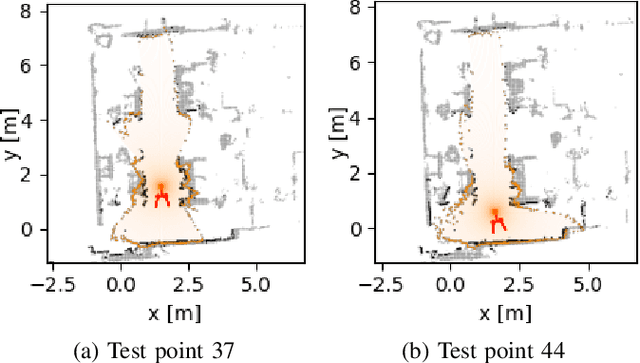
Autonomous mobile robots are an increasingly integral part of modern factory and warehouse operations. Obstacle detection, avoidance and path planning are critical safety-relevant tasks, which are often solved using expensive LiDAR sensors and depth cameras. We propose to use cost-effective low-resolution ranging sensors, such as ultrasonic and infrared time-of-flight sensors by developing VIRUS-NeRF - Vision, InfraRed, and UltraSonic based Neural Radiance Fields. Building upon Instant Neural Graphics Primitives with a Multiresolution Hash Encoding (Instant-NGP), VIRUS-NeRF incorporates depth measurements from ultrasonic and infrared sensors and utilizes them to update the occupancy grid used for ray marching. Experimental evaluation in 2D demonstrates that VIRUS-NeRF achieves comparable mapping performance to LiDAR point clouds regarding coverage. Notably, in small environments, its accuracy aligns with that of LiDAR measurements, while in larger ones, it is bounded by the utilized ultrasonic sensors. An in-depth ablation study reveals that adding ultrasonic and infrared sensors is highly effective when dealing with sparse data and low view variation. Further, the proposed occupancy grid of VIRUS-NeRF improves the mapping capabilities and increases the training speed by 46% compared to Instant-NGP. Overall, VIRUS-NeRF presents a promising approach for cost-effective local mapping in mobile robotics, with potential applications in safety and navigation tasks. The code can be found at https://github.com/ethz-asl/virus nerf.