 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
COVID-CT-H-UNet: a novel COVID-19 CT segmentation network based on attention mechanism and Bi-category Hybrid loss
Mar 16, 2024
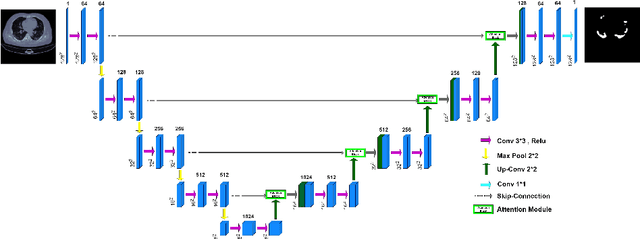
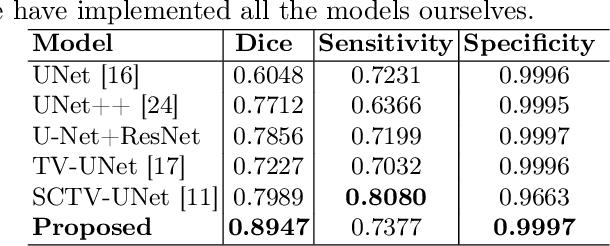
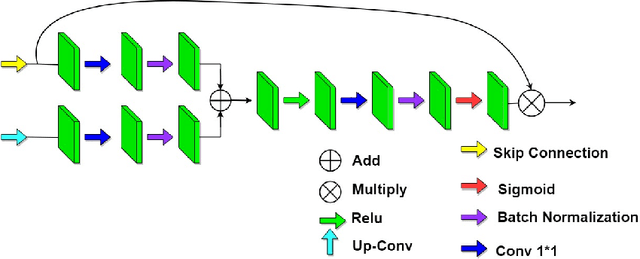
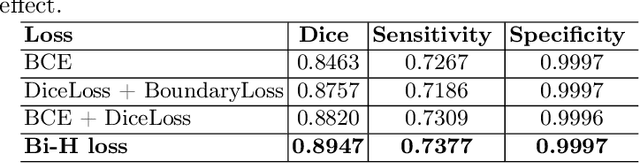
Since 2019, the global COVID-19 outbreak has emerged as a crucial focus in healthcare research. Although RT-PCR stands as the primary method for COVID-19 detection, its extended detection time poses a significant challenge. Consequently, supplementing RT-PCR with the pathological study of COVID-19 through CT imaging has become imperative. The current segmentation approach based on TVLoss enhances the connectivity of afflicted areas. Nevertheless, it tends to misclassify normal pixels between certain adjacent diseased regions as diseased pixels. The typical Binary cross entropy(BCE) based U-shaped network only concentrates on the entire CT images without emphasizing on the affected regions, which results in hazy borders and low contrast in the projected output. In addition, the fraction of infected pixels in CT images is much less, which makes it a challenge for segmentation models to make accurate predictions. In this paper, we propose COVID-CT-H-UNet, a COVID-19 CT segmentation network to solve these problems. To recognize the unaffected pixels between neighbouring diseased regions, extra visual layer information is captured by combining the attention module on the skip connections with the proposed composite function Bi-category Hybrid Loss. The issue of hazy boundaries and poor contrast brought on by the BCE Loss in conventional techniques is resolved by utilizing the composite function Bi-category Hybrid Loss that concentrates on the pixels in the diseased area. The experiment shows when compared to the previous COVID-19 segmentation networks, the proposed COVID-CT-H-UNet's segmentation impact has greatly improved, and it may be used to identify and study clinical COVID-19.
Skeleton-Based Human Action Recognition with Noisy Labels
Mar 15, 2024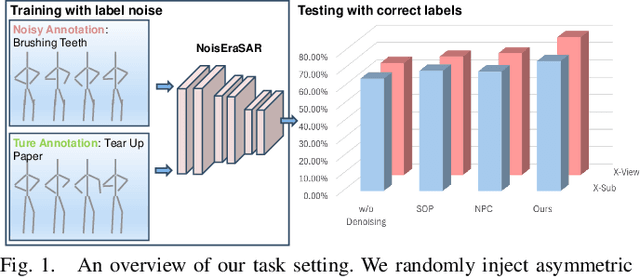
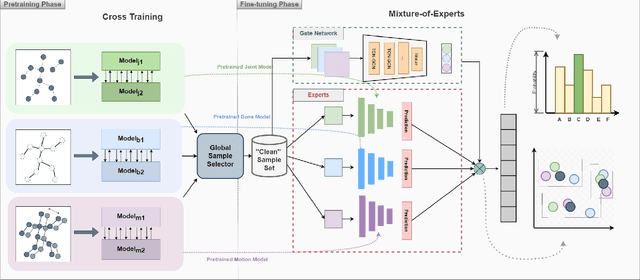
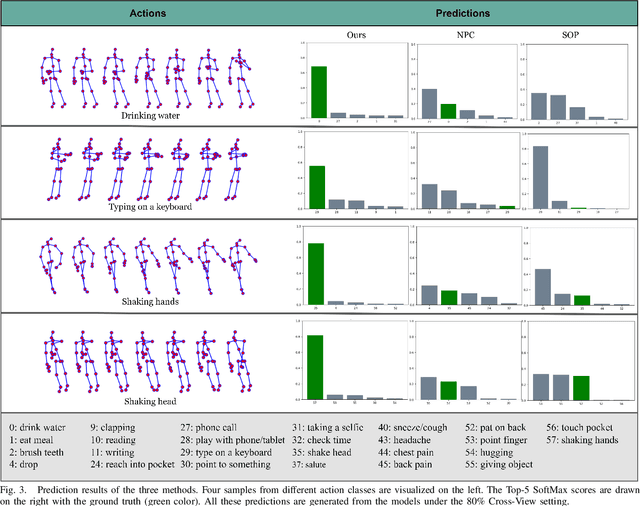
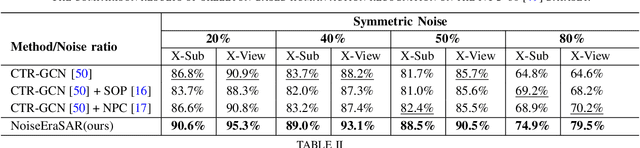
Understanding human actions from body poses is critical for assistive robots sharing space with humans in order to make informed and safe decisions about the next interaction. However, precise temporal localization and annotation of activity sequences is time-consuming and the resulting labels are often noisy. If not effectively addressed, label noise negatively affects the model's training, resulting in lower recognition quality. Despite its importance, addressing label noise for skeleton-based action recognition has been overlooked so far. In this study, we bridge this gap by implementing a framework that augments well-established skeleton-based human action recognition methods with label-denoising strategies from various research areas to serve as the initial benchmark. Observations reveal that these baselines yield only marginal performance when dealing with sparse skeleton data. Consequently, we introduce a novel methodology, NoiseEraSAR, which integrates global sample selection, co-teaching, and Cross-Modal Mixture-of-Experts (CM-MOE) strategies, aimed at mitigating the adverse impacts of label noise. Our proposed approach demonstrates better performance on the established benchmark, setting new state-of-the-art standards. The source code for this study will be made accessible at https://github.com/xuyizdby/NoiseEraSAR.
A Novel Framework for Multi-Person Temporal Gaze Following and Social Gaze Prediction
Mar 15, 2024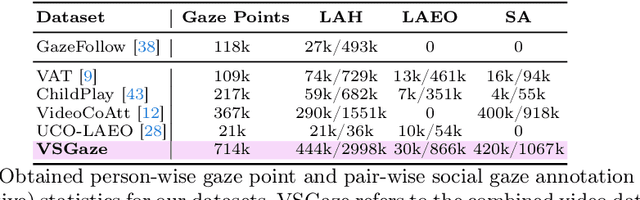
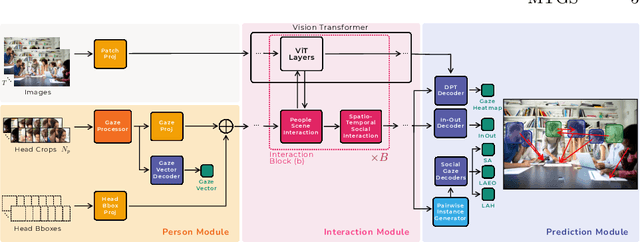
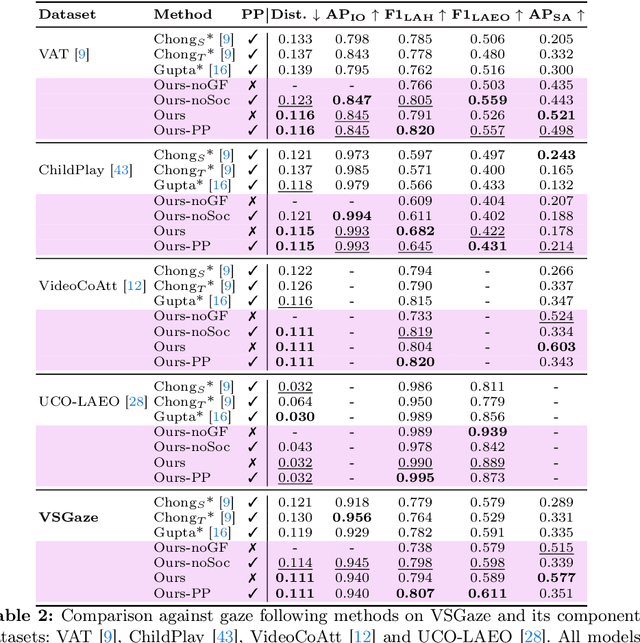
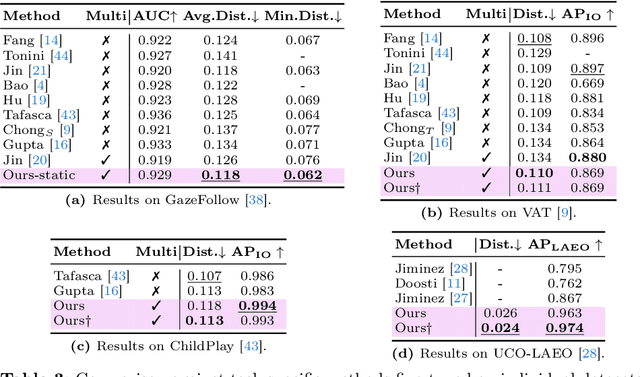
Gaze following and social gaze prediction are fundamental tasks providing insights into human communication behaviors, intent, and social interactions. Most previous approaches addressed these tasks separately, either by designing highly specialized social gaze models that do not generalize to other social gaze tasks or by considering social gaze inference as an ad-hoc post-processing of the gaze following task. Furthermore, the vast majority of gaze following approaches have proposed static models that can handle only one person at a time, therefore failing to take advantage of social interactions and temporal dynamics. In this paper, we address these limitations and introduce a novel framework to jointly predict the gaze target and social gaze label for all people in the scene. The framework comprises of: (i) a temporal, transformer-based architecture that, in addition to image tokens, handles person-specific tokens capturing the gaze information related to each individual; (ii) a new dataset, VSGaze, that unifies annotation types across multiple gaze following and social gaze datasets. We show that our model trained on VSGaze can address all tasks jointly, and achieves state-of-the-art results for multi-person gaze following and social gaze prediction.
HawkEye: Training Video-Text LLMs for Grounding Text in Videos
Mar 15, 2024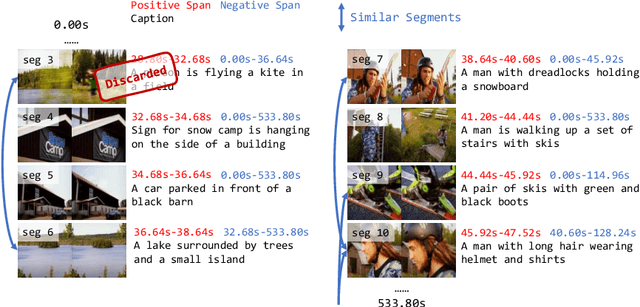
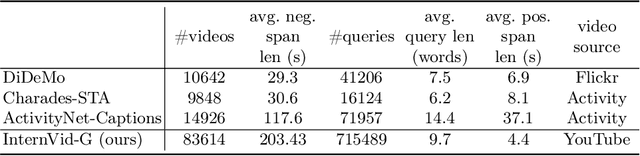
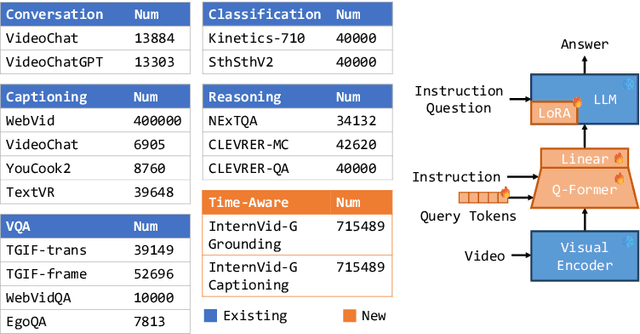

Video-text Large Language Models (video-text LLMs) have shown remarkable performance in answering questions and holding conversations on simple videos. However, they perform almost the same as random on grounding text queries in long and complicated videos, having little ability to understand and reason about temporal information, which is the most fundamental difference between videos and images. In this paper, we propose HawkEye, one of the first video-text LLMs that can perform temporal video grounding in a fully text-to-text manner. To collect training data that is applicable for temporal video grounding, we construct InternVid-G, a large-scale video-text corpus with segment-level captions and negative spans, with which we introduce two new time-aware training objectives to video-text LLMs. We also propose a coarse-grained method of representing segments in videos, which is more robust and easier for LLMs to learn and follow than other alternatives. Extensive experiments show that HawkEye is better at temporal video grounding and comparable on other video-text tasks with existing video-text LLMs, which verifies its superior video-text multi-modal understanding abilities.
PyHySCO: GPU-Enabled Susceptibility Artifact Distortion Correction in Seconds
Mar 15, 2024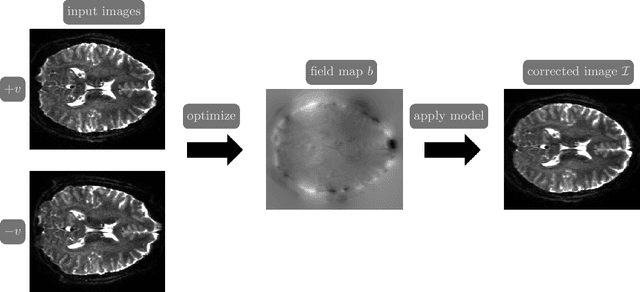

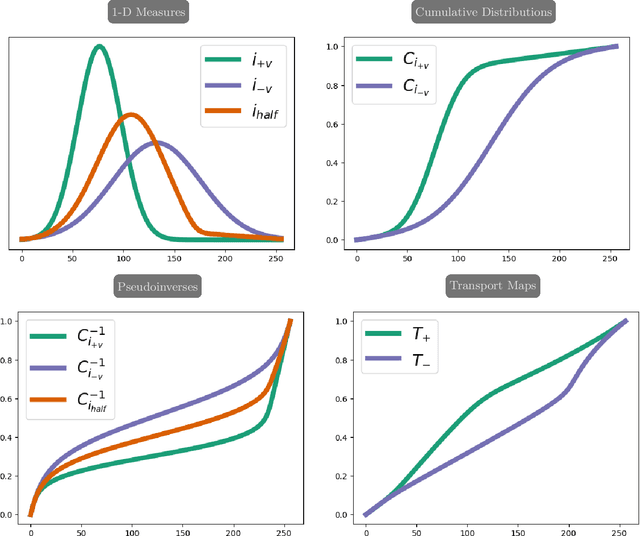
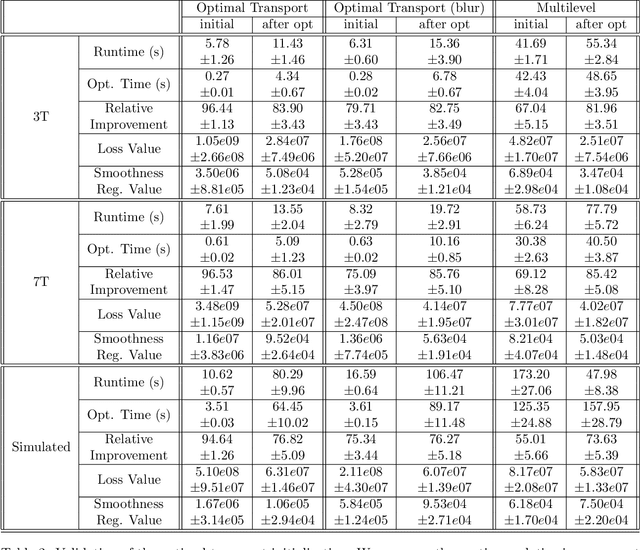
Over the past decade, reversed Gradient Polarity (RGP) methods have become a popular approach for correcting susceptibility artifacts in Echo-Planar Imaging (EPI). Although several post-processing tools for RGP are available, their implementations do not fully leverage recent hardware, algorithmic, and computational advances, leading to correction times of several minutes per image volume. To enable 3D RGP correction in seconds, we introduce PyHySCO, a user-friendly EPI distortion correction tool implemented in PyTorch that enables multi-threading and efficient use of graphics processing units (GPUs). PyHySCO uses a time-tested physical distortion model and mathematical formulation and is, therefore, reliable without training. An algorithmic improvement in PyHySCO is its novel initialization scheme that uses 1D optimal transport. PyHySCO is published under the GNU public license and can be used from the command line or its Python interface. Our extensive numerical validation using 3T and 7T data from the Human Connectome Project suggests that PyHySCO achieves accuracy comparable to that of leading RGP tools at a fraction of the cost. We also validate the new initialization scheme, compare different optimization algorithms, and test the algorithm on different hardware and arithmetic precision.
Spiking Neural Networks for Fast-Moving Object Detection on Neuromorphic Hardware Devices Using an Event-Based Camera
Mar 15, 2024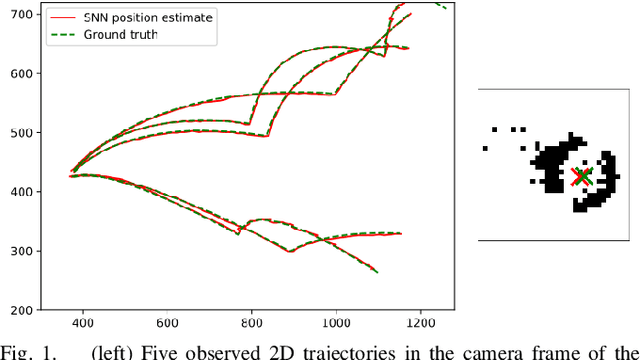
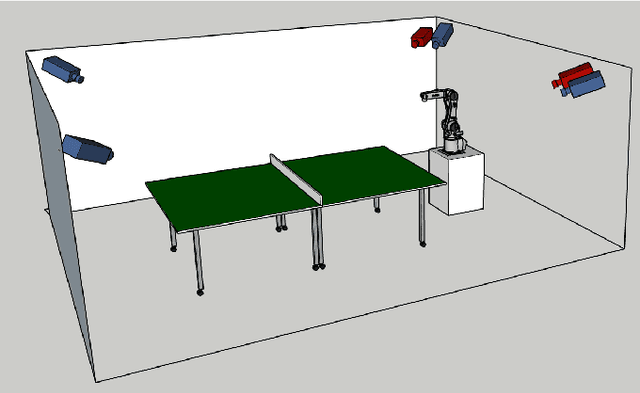
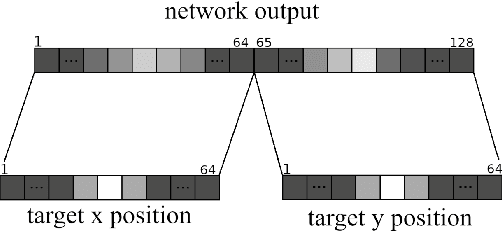
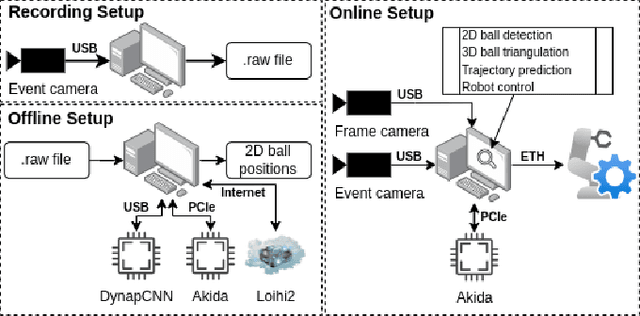
Table tennis is a fast-paced and exhilarating sport that demands agility, precision, and fast reflexes. In recent years, robotic table tennis has become a popular research challenge for robot perception algorithms. Fast and accurate ball detection is crucial for enabling a robotic arm to rally the ball back successfully. Previous approaches have employed conventional frame-based cameras with Convolutional Neural Networks (CNNs) or traditional computer vision methods. In this paper, we propose a novel solution that combines an event-based camera with Spiking Neural Networks (SNNs) for ball detection. We use multiple state-of-the-art SNN frameworks and develop a SNN architecture for each of them, complying with their corresponding constraints. Additionally, we implement the SNN solution across multiple neuromorphic edge devices, conducting comparisons of their accuracies and run-times. This furnishes robotics researchers with a benchmark illustrating the capabilities achievable with each SNN framework and a corresponding neuromorphic edge device. Next to this comparison of SNN solutions for robots, we also show that an SNN on a neuromorphic edge device is able to run in real-time in a closed loop robotic system, a table tennis robot in our use case.
COVID-19 Computer-aided Diagnosis through AI-assisted CT Imaging Analysis: Deploying a Medical AI System
Mar 12, 2024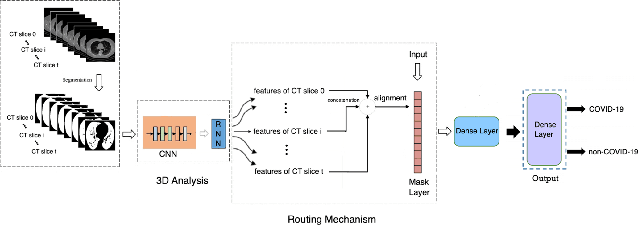
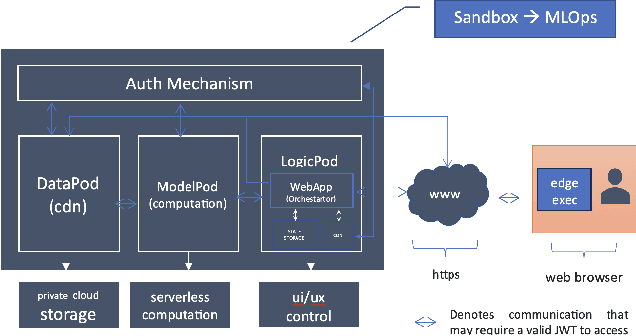
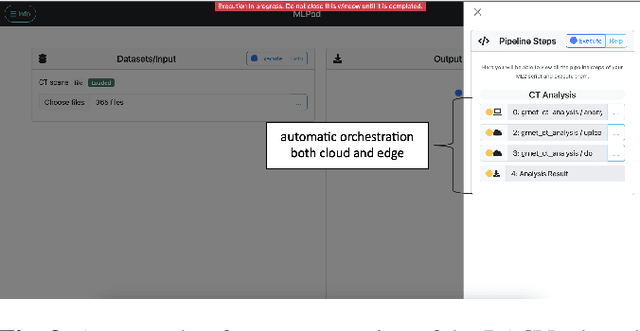
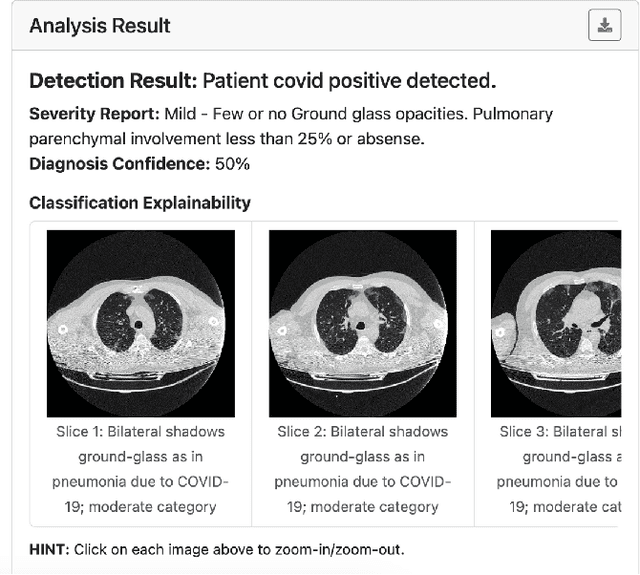
Computer-aided diagnosis (CAD) systems stand out as potent aids for physicians in identifying the novel Coronavirus Disease 2019 (COVID-19) through medical imaging modalities. In this paper, we showcase the integration and reliable and fast deployment of a state-of-the-art AI system designed to automatically analyze CT images, offering infection probability for the swift detection of COVID-19. The suggested system, comprising both classification and segmentation components, is anticipated to reduce physicians' detection time and enhance the overall efficiency of COVID-19 detection. We successfully surmounted various challenges, such as data discrepancy and anonymisation, testing the time-effectiveness of the model, and data security, enabling reliable and scalable deployment of the system on both cloud and edge environments. Additionally, our AI system assigns a probability of infection to each 3D CT scan and enhances explainability through anchor set similarity, facilitating timely confirmation and segregation of infected patients by physicians.
Learning Generalizable Feature Fields for Mobile Manipulation
Mar 12, 2024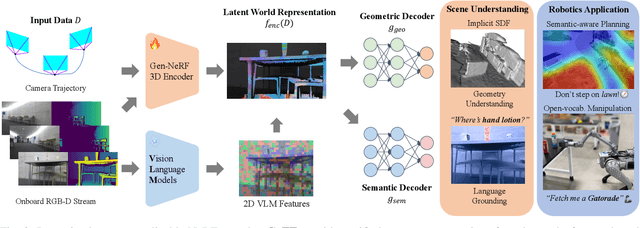


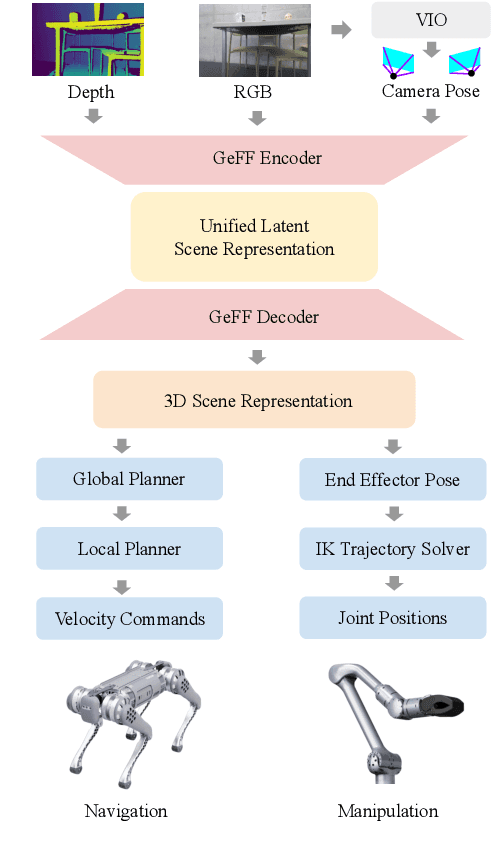
An open problem in mobile manipulation is how to represent objects and scenes in a unified manner, so that robots can use it both for navigating in the environment and manipulating objects. The latter requires capturing intricate geometry while understanding fine-grained semantics, whereas the former involves capturing the complexity inherit to an expansive physical scale. In this work, we present GeFF (Generalizable Feature Fields), a scene-level generalizable neural feature field that acts as a unified representation for both navigation and manipulation that performs in real-time. To do so, we treat generative novel view synthesis as a pre-training task, and then align the resulting rich scene priors with natural language via CLIP feature distillation. We demonstrate the effectiveness of this approach by deploying GeFF on a quadrupedal robot equipped with a manipulator. We evaluate GeFF's ability to generalize to open-set objects as well as running time, when performing open-vocabulary mobile manipulation in dynamic scenes.
Time to Cite: Modeling Citation Networks using the Dynamic Impact Single-Event Embedding Model
Feb 28, 2024

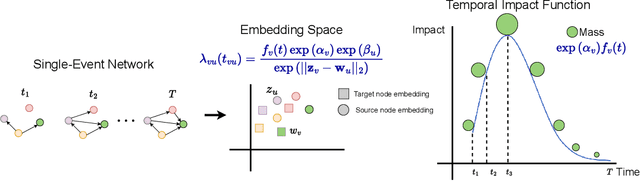
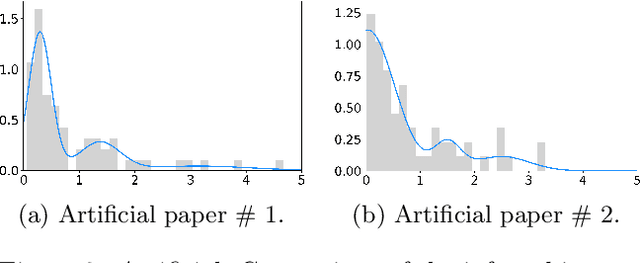
Understanding the structure and dynamics of scientific research, i.e., the science of science (SciSci), has become an important area of research in order to address imminent questions including how scholars interact to advance science, how disciplines are related and evolve, and how research impact can be quantified and predicted. Central to the study of SciSci has been the analysis of citation networks. Here, two prominent modeling methodologies have been employed: one is to assess the citation impact dynamics of papers using parametric distributions, and the other is to embed the citation networks in a latent space optimal for characterizing the static relations between papers in terms of their citations. Interestingly, citation networks are a prominent example of single-event dynamic networks, i.e., networks for which each dyad only has a single event (i.e., the point in time of citation). We presently propose a novel likelihood function for the characterization of such single-event networks. Using this likelihood, we propose the Dynamic Impact Single-Event Embedding model (DISEE). The \textsc{\modelabbrev} model characterizes the scientific interactions in terms of a latent distance model in which random effects account for citation heterogeneity while the time-varying impact is characterized using existing parametric representations for assessment of dynamic impact. We highlight the proposed approach on several real citation networks finding that the DISEE well reconciles static latent distance network embedding approaches with classical dynamic impact assessments.
MultiGripperGrasp: A Dataset for Robotic Grasping from Parallel Jaw Grippers to Dexterous Hands
Mar 14, 2024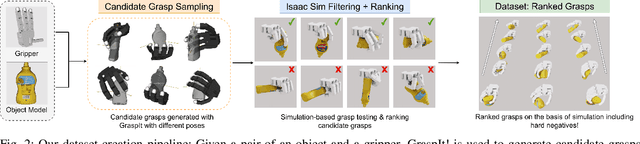

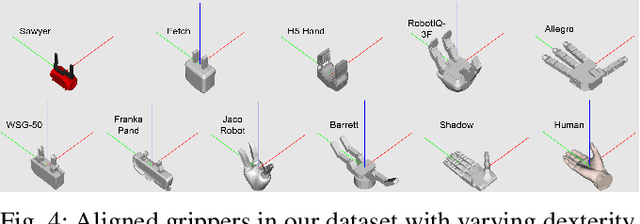

We introduce a large-scale dataset named MultiGripperGrasp for robotic grasping. Our dataset contains 30.4M grasps from 11 grippers for 345 objects. These grippers range from two-finger grippers to five-finger grippers, including a human hand. All grasps in the dataset are verified in Isaac Sim to classify them as successful and unsuccessful grasps. Additionally, the object fall-off time for each grasp is recorded as a grasp quality measurement. Furthermore, the grippers in our dataset are aligned according to the orientation and position of their palms, allowing us to transfer grasps from one gripper to another. The grasp transfer significantly increases the number of successful grasps for each gripper in the dataset. Our dataset is useful to study generalized grasp planning and grasp transfer across different grippers.