 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Near-Field Low-WISL Unimodular Waveform Design for Terahertz Automotive Radar
Mar 08, 2023
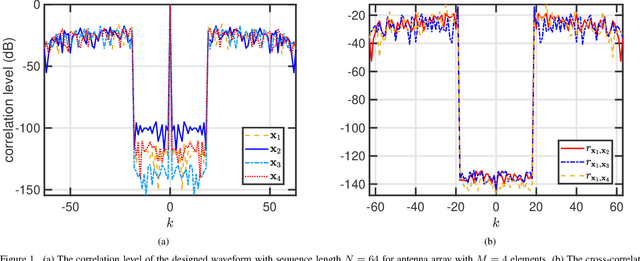
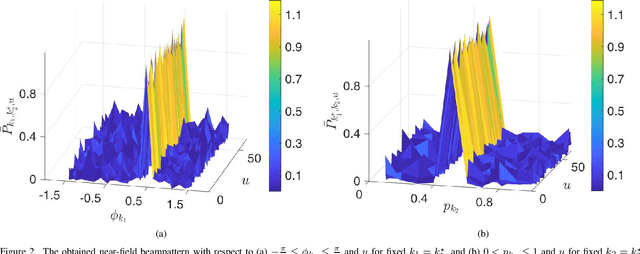
Conventional sensing applications rely on electromagnetic far-field channel models with plane wave propagation. However, recent ultra-short-range automotive radar applications at upper millimeter-wave or low terahertz (THz) frequencies envisage operation in the near-field region, where the wavefront is spherical. Unlike far-field, the near-field beampattern is dependent on both range and angle, thus requiring a different approach to waveform design. For the first time in the literature, we adopt the beampattern matching approach to design unimodular waveforms for THz automotive radars with low weighted integrated sidelobe levels (WISL). We formulate this problem as a unimodular bi-quadratic matrix program, and solve its constituent quadratic sub-problems using our cyclic power method-like iterations (CyPMLI) algorithm. Numerical experiments demonstrate that the CyPMLI approach yields the required beampattern with low autocorrelation levels.
Lower Generalization Bounds for GD and SGD in Smooth Stochastic Convex Optimization
Mar 19, 2023
Recent progress was made in characterizing the generalization error of gradient methods for general convex loss by the learning theory community. In this work, we focus on how training longer might affect generalization in smooth stochastic convex optimization (SCO) problems. We first provide tight lower bounds for general non-realizable SCO problems. Furthermore, existing upper bound results suggest that sample complexity can be improved by assuming the loss is realizable, i.e. an optimal solution simultaneously minimizes all the data points. However, this improvement is compromised when training time is long and lower bounds are lacking. Our paper examines this observation by providing excess risk lower bounds for gradient descent (GD) and stochastic gradient descent (SGD) in two realizable settings: 1) realizable with $T = O(n)$, and (2) realizable with $T = \Omega(n)$, where $T$ denotes the number of training iterations and $n$ is the size of the training dataset. These bounds are novel and informative in characterizing the relationship between $T$ and $n$. In the first small training horizon case, our lower bounds almost tightly match and provide the first optimal certificates for the corresponding upper bounds. However, for the realizable case with $T = \Omega(n)$, a gap exists between the lower and upper bounds. We provide a conjecture to address this problem, that the gap can be closed by improving upper bounds, which is supported by our analyses in one-dimensional and linear regression scenarios.
Going faster to see further: GPU-accelerated value iteration and simulation for perishable inventory control using JAX
Mar 19, 2023
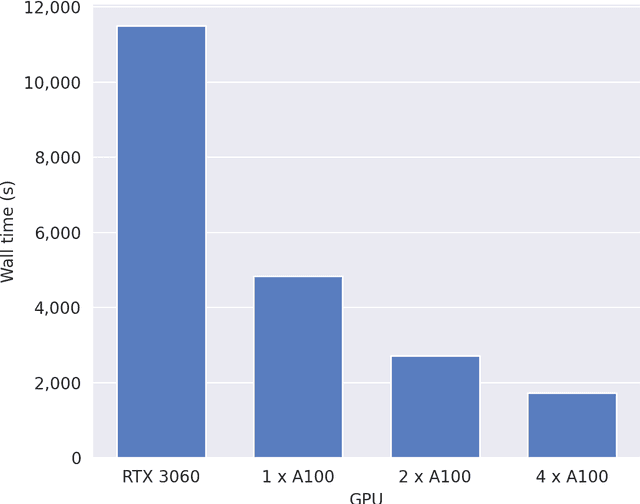

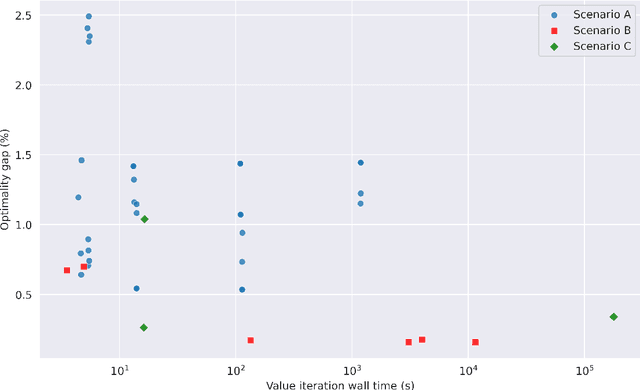
Value iteration can find the optimal replenishment policy for a perishable inventory problem, but is computationally demanding due to the large state spaces that are required to represent the age profile of stock. The parallel processing capabilities of modern GPUs can reduce the wall time required to run value iteration by updating many states simultaneously. The adoption of GPU-accelerated approaches has been limited in operational research relative to other fields like machine learning, in which new software frameworks have made GPU programming widely accessible. We used the Python library JAX to implement value iteration and simulators of the underlying Markov decision processes in a high-level API, and relied on this library's function transformations and compiler to efficiently utilize GPU hardware. Our method can extend use of value iteration to settings that were previously considered infeasible or impractical. We demonstrate this on example scenarios from three recent studies which include problems with over 16 million states and additional problem features, such as substitution between products, that increase computational complexity. We compare the performance of the optimal replenishment policies to heuristic policies, fitted using simulation optimization in JAX which allowed the parallel evaluation of multiple candidate policy parameters on thousands of simulated years. The heuristic policies gave a maximum optimality gap of 2.49%. Our general approach may be applicable to a wide range of problems in operational research that would benefit from large-scale parallel computation on consumer-grade GPU hardware.
Multi-Channel Attentive Feature Fusion for Radio Frequency Fingerprinting
Mar 19, 2023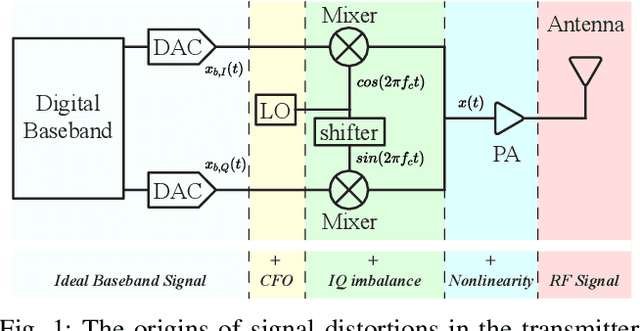
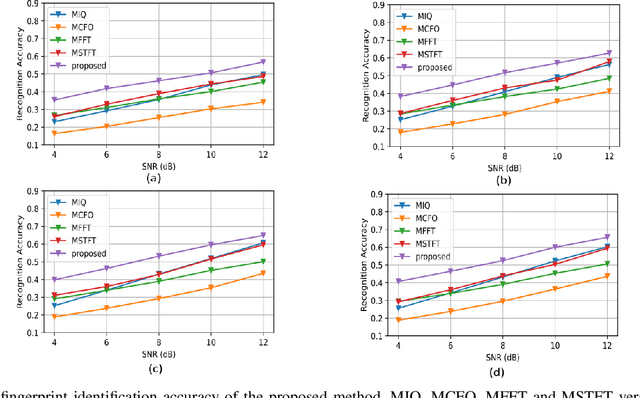
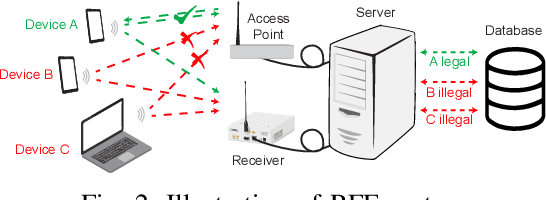
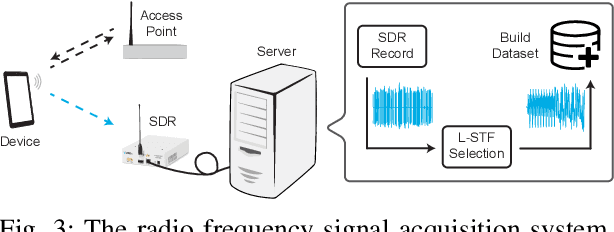
Radio frequency fingerprinting (RFF) is a promising device authentication technique for securing the Internet of things. It exploits the intrinsic and unique hardware impairments of the transmitters for RF device identification. In real-world communication systems, hardware impairments across transmitters are subtle, which are difficult to model explicitly. Recently, due to the superior performance of deep learning (DL)-based classification models on real-world datasets, DL networks have been explored for RFF. Most existing DL-based RFF models use a single representation of radio signals as the input. Multi-channel input model can leverage information from different representations of radio signals and improve the identification accuracy of the RF fingerprint. In this work, we propose a novel multi-channel attentive feature fusion (McAFF) method for RFF. It utilizes multi-channel neural features extracted from multiple representations of radio signals, including IQ samples, carrier frequency offset, fast Fourier transform coefficients and short-time Fourier transform coefficients, for better RF fingerprint identification. The features extracted from different channels are fused adaptively using a shared attention module, where the weights of neural features from multiple channels are learned during training the McAFF model. In addition, we design a signal identification module using a convolution-based ResNeXt block to map the fused features to device identities. To evaluate the identification performance of the proposed method, we construct a WiFi dataset, named WFDI, using commercial WiFi end-devices as the transmitters and a Universal Software Radio Peripheral (USRP) as the receiver. ...
Controllable Video Generation by Learning the Underlying Dynamical System with Neural ODE
Mar 09, 2023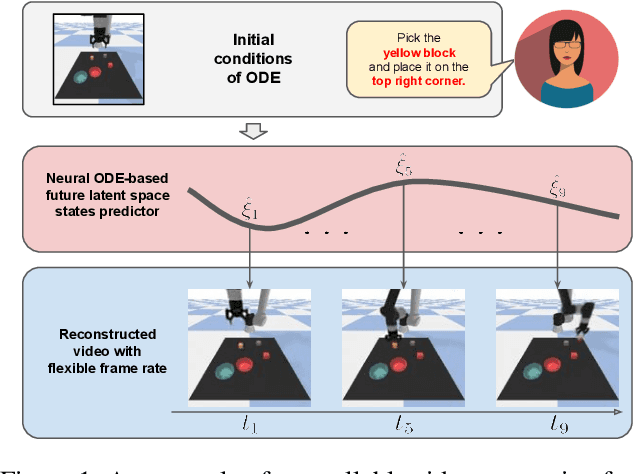
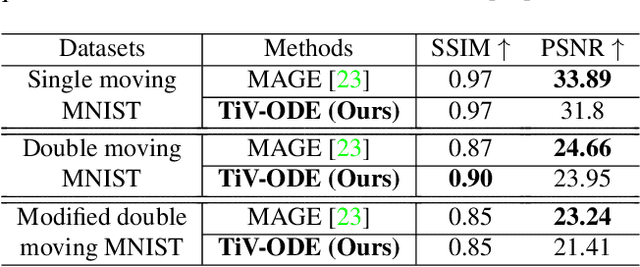
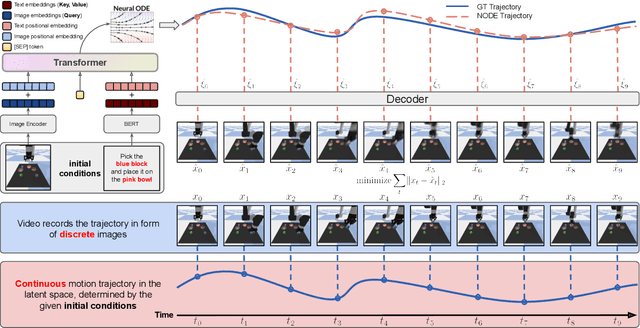
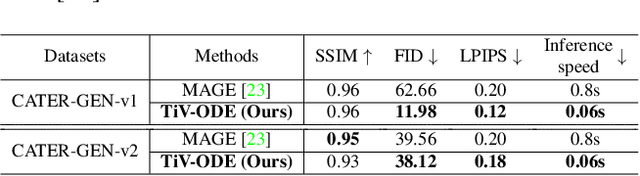
Videos depict the change of complex dynamical systems over time in the form of discrete image sequences. Generating controllable videos by learning the dynamical system is an important yet underexplored topic in the computer vision community. This paper presents a novel framework, TiV-ODE, to generate highly controllable videos from a static image and a text caption. Specifically, our framework leverages the ability of Neural Ordinary Differential Equations~(Neural ODEs) to represent complex dynamical systems as a set of nonlinear ordinary differential equations. The resulting framework is capable of generating videos with both desired dynamics and content. Experiments demonstrate the ability of the proposed method in generating highly controllable and visually consistent videos, and its capability of modeling dynamical systems. Overall, this work is a significant step towards developing advanced controllable video generation models that can handle complex and dynamic scenes.
Learning Rational Subgoals from Demonstrations and Instructions
Mar 09, 2023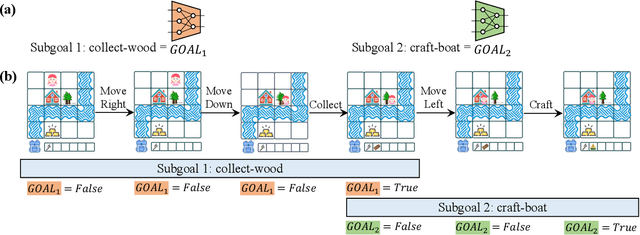
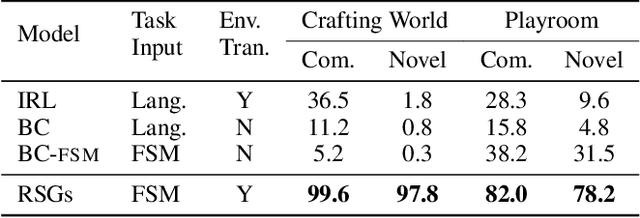
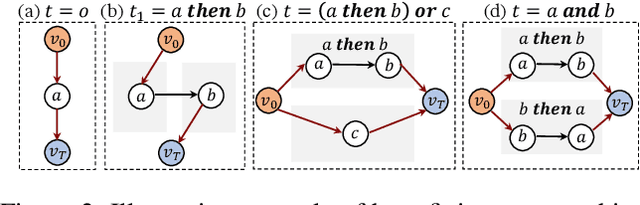
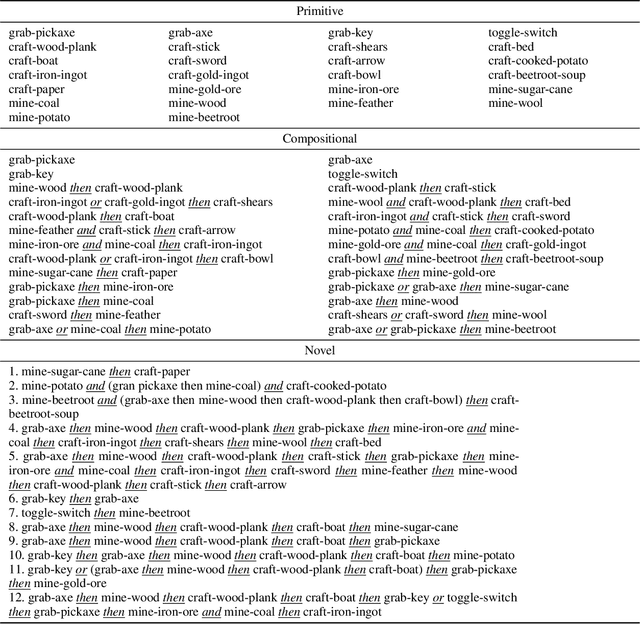
We present a framework for learning useful subgoals that support efficient long-term planning to achieve novel goals. At the core of our framework is a collection of rational subgoals (RSGs), which are essentially binary classifiers over the environmental states. RSGs can be learned from weakly-annotated data, in the form of unsegmented demonstration trajectories, paired with abstract task descriptions, which are composed of terms initially unknown to the agent (e.g., collect-wood then craft-boat then go-across-river). Our framework also discovers dependencies between RSGs, e.g., the task collect-wood is a helpful subgoal for the task craft-boat. Given a goal description, the learned subgoals and the derived dependencies facilitate off-the-shelf planning algorithms, such as A* and RRT, by setting helpful subgoals as waypoints to the planner, which significantly improves performance-time efficiency.
PDSketch: Integrated Planning Domain Programming and Learning
Mar 09, 2023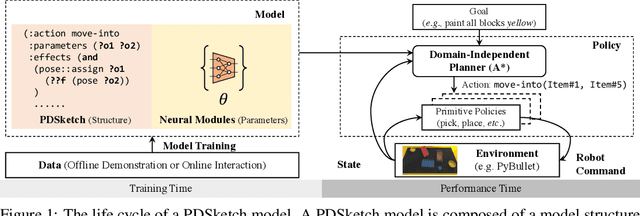
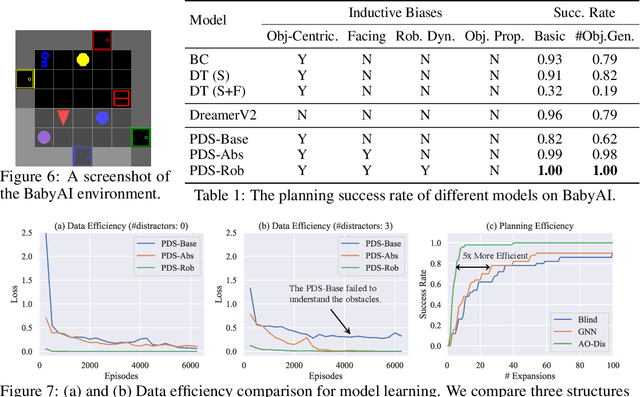

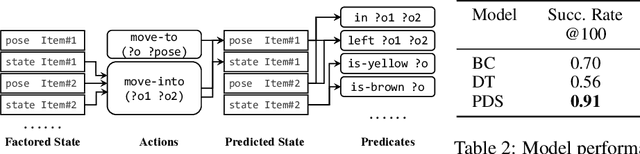
This paper studies a model learning and online planning approach towards building flexible and general robots. Specifically, we investigate how to exploit the locality and sparsity structures in the underlying environmental transition model to improve model generalization, data-efficiency, and runtime-efficiency. We present a new domain definition language, named PDSketch. It allows users to flexibly define high-level structures in the transition models, such as object and feature dependencies, in a way similar to how programmers use TensorFlow or PyTorch to specify kernel sizes and hidden dimensions of a convolutional neural network. The details of the transition model will be filled in by trainable neural networks. Based on the defined structures and learned parameters, PDSketch automatically generates domain-independent planning heuristics without additional training. The derived heuristics accelerate the performance-time planning for novel goals.
Prefix-tree Decoding for Predicting Mass Spectra from Molecules
Mar 11, 2023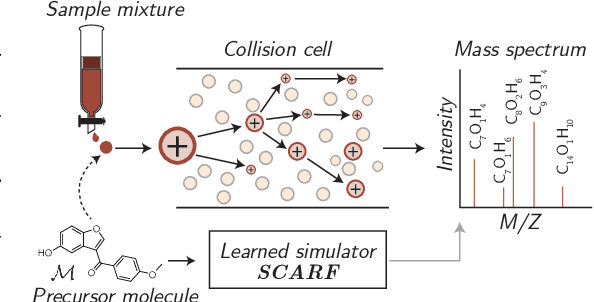
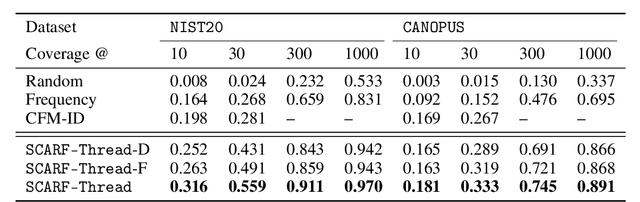
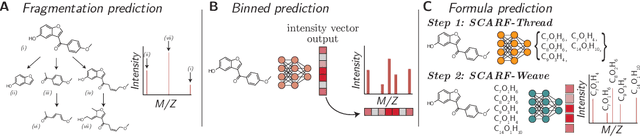
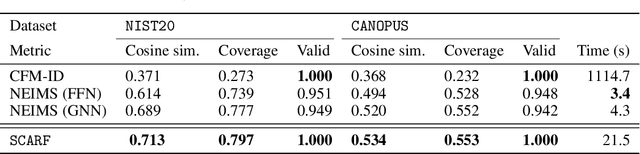
Computational predictions of mass spectra from molecules have enabled the discovery of clinically relevant metabolites. However, such predictive tools are still limited as they occupy one of two extremes, either operating (a) by fragmenting molecules combinatorially with overly rigid constraints on potential rearrangements and poor time complexity or (b) by decoding lossy and nonphysical discretized spectra vectors. In this work, we introduce a new intermediate strategy for predicting mass spectra from molecules by treating mass spectra as sets of chemical formulae, which are themselves multisets of atoms. After first encoding an input molecular graph, we decode a set of chemical subformulae, each of which specify a predicted peak in the mass spectra, the intensities of which are predicted by a second model. Our key insight is to overcome the combinatorial possibilities for chemical subformulae by decoding the formula set using a prefix tree structure, atom-type by atom-type, representing a general method for ordered multiset decoding. We show promising empirical results on mass spectra prediction tasks.
A Theoretical Analysis Of Nearest Neighbor Search On Approximate Near Neighbor Graph
Mar 10, 2023
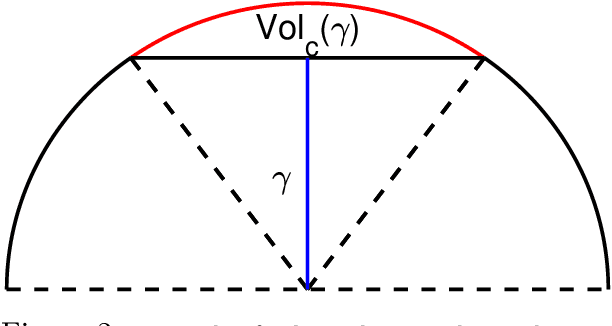
Graph-based algorithms have demonstrated state-of-the-art performance in the nearest neighbor search (NN-Search) problem. These empirical successes urge the need for theoretical results that guarantee the search quality and efficiency of these algorithms. However, there exists a practice-to-theory gap in the graph-based NN-Search algorithms. Current theoretical literature focuses on greedy search on exact near neighbor graph while practitioners use approximate near neighbor graph (ANN-Graph) to reduce the preprocessing time. This work bridges this gap by presenting the theoretical guarantees of solving NN-Search via greedy search on ANN-Graph for low dimensional and dense vectors. To build this bridge, we leverage several novel tools from computational geometry. Our results provide quantification of the trade-offs associated with the approximation while building a near neighbor graph. We hope our results will open the door for more provable efficient graph-based NN-Search algorithms.
Multi-Robot-Guided Crowd Evacuation: Two-Scale Modeling and Control Based on Mean-Field Hydrodynamic Models
Feb 28, 2023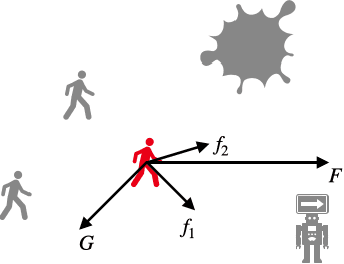
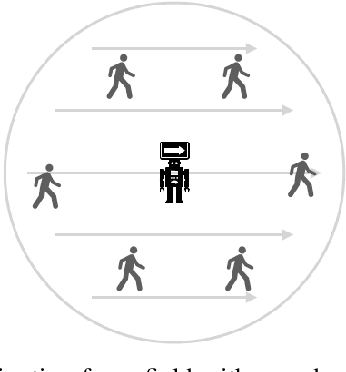
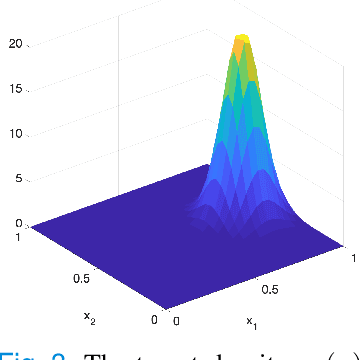
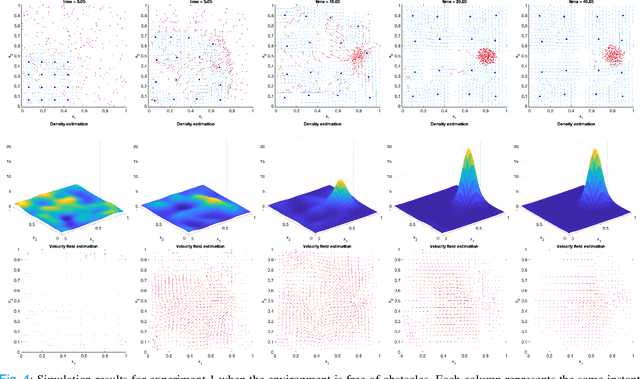
Emergency evacuation describes a complex situation involving time-critical decision-making by evacuees. Mobile robots are being actively explored as a potential solution to provide timely guidance. In this work, we study a robot-guided crowd evacuation problem where a small group of robots is used to guide a large human crowd to safe locations. The challenge lies in how to utilize micro-level human-robot interactions to indirectly influence a population that significantly outnumbers the robots to achieve the collective evacuation objective. To address the challenge, we follow a two-scale modeling strategy and explore mean-field hydrodynamic models which consist of a family of microscopic social-force models that explicitly describe how human movements are locally affected by other humans, the environment, and the robots, and associated macroscopic equations for the temporal and spatial evolution of the crowd density and flow velocity. We design controllers for the robots such that they not only automatically explore the environment (with unknown dynamic obstacles) to cover it as much as possible but also dynamically adjust the directions of their local navigation force fields based on the real-time macro-states of the crowd to guide the crowd to a safe location. We prove the stability of the proposed evacuation algorithm and conduct a series of simulations (involving unknown dynamic obstacles) to validate the performance of the algorithm.