 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Accelerating Wireless Federated Learning via Nesterov's Momentum and Distributed Principle Component Analysis
Mar 31, 2023
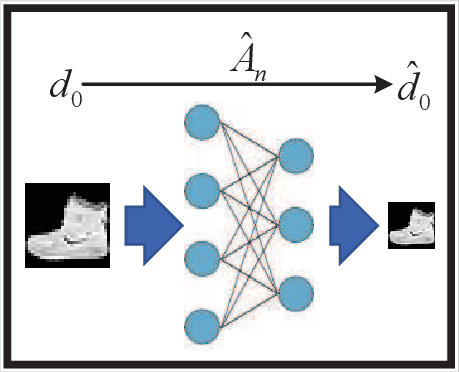
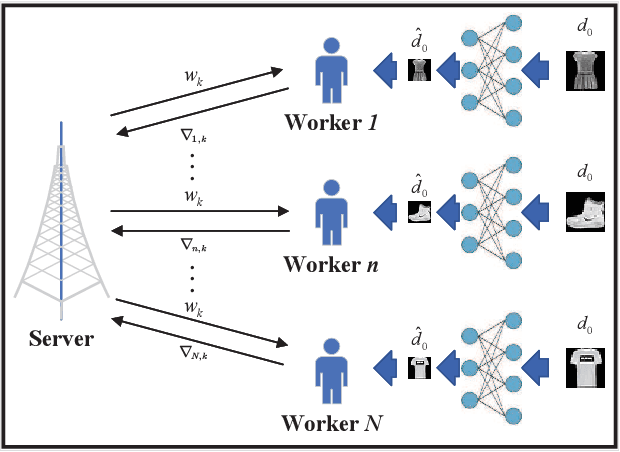
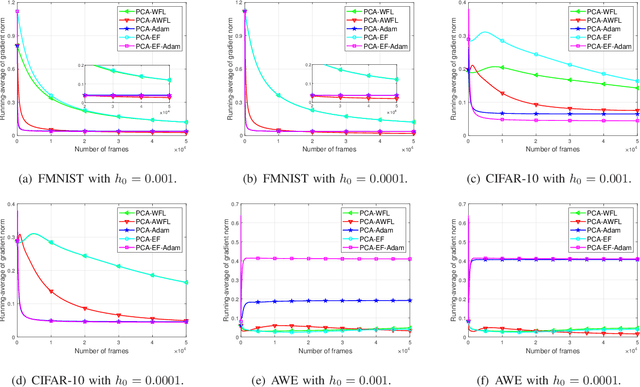
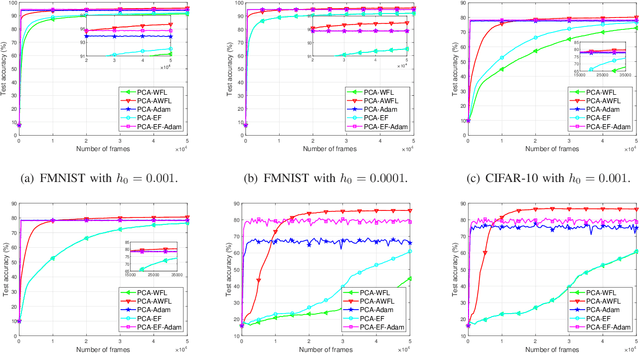
A wireless federated learning system is investigated by allowing a server and workers to exchange uncoded information via orthogonal wireless channels. Since the workers frequently upload local gradients to the server via bandwidth-limited channels, the uplink transmission from the workers to the server becomes a communication bottleneck. Therefore, a one-shot distributed principle component analysis (PCA) is leveraged to reduce the dimension of uploaded gradients such that the communication bottleneck is relieved. A PCA-based wireless federated learning (PCA-WFL) algorithm and its accelerated version (i.e., PCA-AWFL) are proposed based on the low-dimensional gradients and the Nesterov's momentum. For the non-convex loss functions, a finite-time analysis is performed to quantify the impacts of system hyper-parameters on the convergence of the PCA-WFL and PCA-AWFL algorithms. The PCA-AWFL algorithm is theoretically certified to converge faster than the PCA-WFL algorithm. Besides, the convergence rates of PCA-WFL and PCA-AWFL algorithms quantitatively reveal the linear speedup with respect to the number of workers over the vanilla gradient descent algorithm. Numerical results are used to demonstrate the improved convergence rates of the proposed PCA-WFL and PCA-AWFL algorithms over the benchmarks.
A Slow-Shifting Concerned Machine Learning Method for Short-term Traffic Flow Forecasting
Mar 31, 2023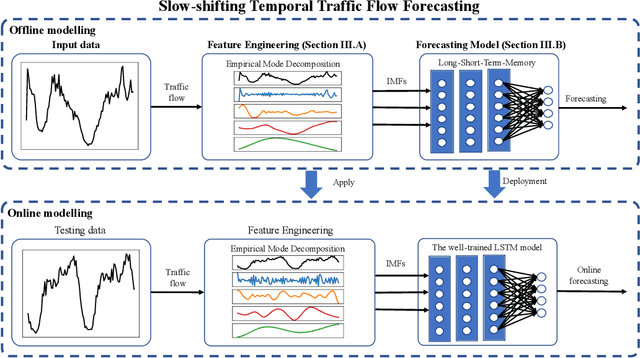
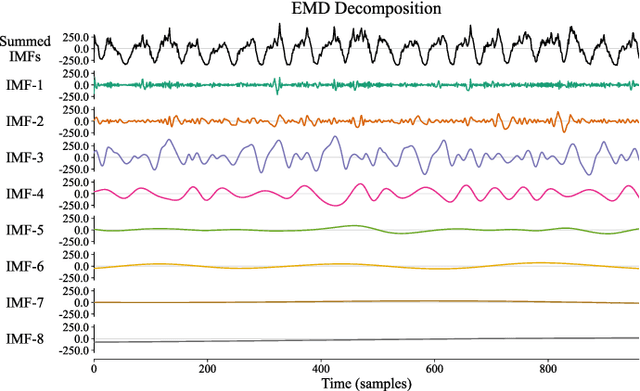
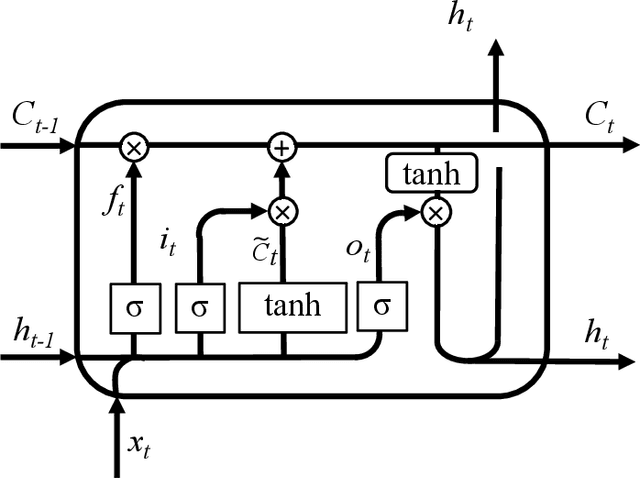
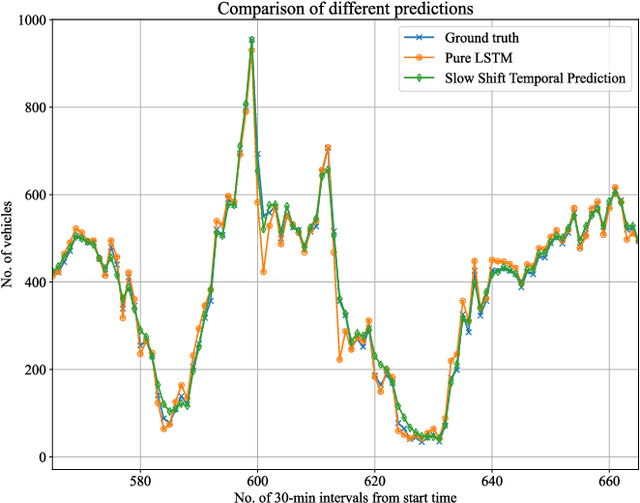
The ability to predict traffic flow over time for crowded areas during rush hours is increasingly important as it can help authorities make informed decisions for congestion mitigation or scheduling of infrastructure development in an area. However, a crucial challenge in traffic flow forecasting is the slow shifting in temporal peaks between daily and weekly cycles, resulting in the nonstationarity of the traffic flow signal and leading to difficulty in accurate forecasting. To address this challenge, we propose a slow shifting concerned machine learning method for traffic flow forecasting, which includes two parts. First, we take advantage of Empirical Mode Decomposition as the feature engineering to alleviate the nonstationarity of traffic flow data, yielding a series of stationary components. Second, due to the superiority of Long-Short-Term-Memory networks in capturing temporal features, an advanced traffic flow forecasting model is developed by taking the stationary components as inputs. Finally, we apply this method on a benchmark of real-world data and provide a comparison with other existing methods. Our proposed method outperforms the state-of-art results by 14.55% and 62.56% using the metrics of root mean squared error and mean absolute percentage error, respectively.
A Closer Look at Parameter-Efficient Tuning in Diffusion Models
Mar 31, 2023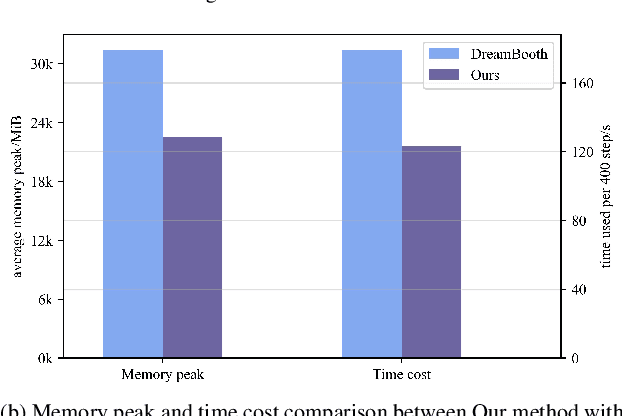

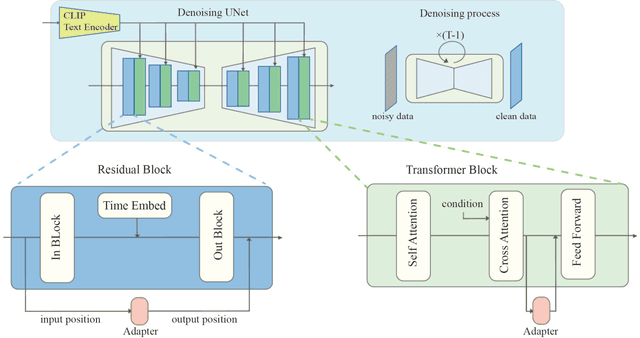
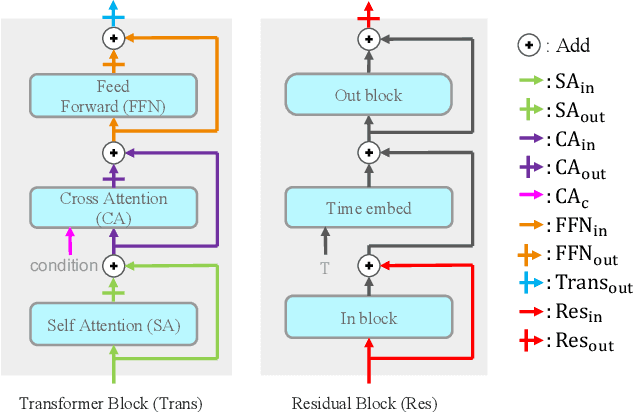
Large-scale diffusion models like Stable Diffusion are powerful and find various real-world applications while customizing such models by fine-tuning is both memory and time inefficient. Motivated by the recent progress in natural language processing, we investigate parameter-efficient tuning in large diffusion models by inserting small learnable modules (termed adapters). In particular, we decompose the design space of adapters into orthogonal factors -- the input position, the output position as well as the function form, and perform Analysis of Variance (ANOVA), a classical statistical approach for analyzing the correlation between discrete (design options) and continuous variables (evaluation metrics). Our analysis suggests that the input position of adapters is the critical factor influencing the performance of downstream tasks. Then, we carefully study the choice of the input position, and we find that putting the input position after the cross-attention block can lead to the best performance, validated by additional visualization analyses. Finally, we provide a recipe for parameter-efficient tuning in diffusion models, which is comparable if not superior to the fully fine-tuned baseline (e.g., DreamBooth) with only 0.75 \% extra parameters, across various customized tasks.
EA-BEV: Edge-aware Bird' s-Eye-View Projector for 3D Object Detection
Mar 31, 2023
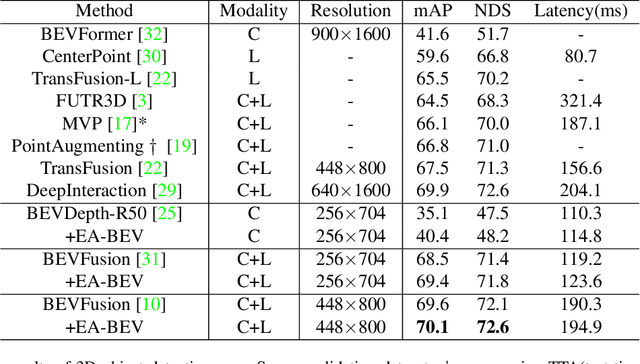
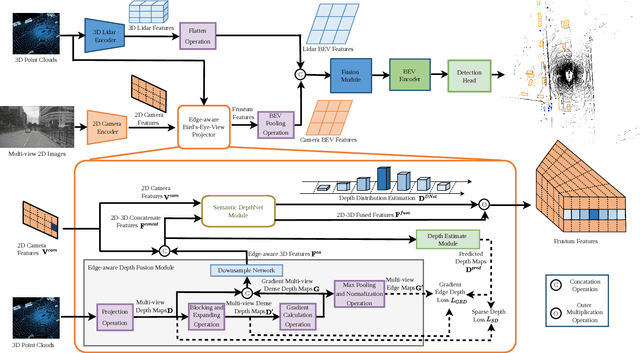
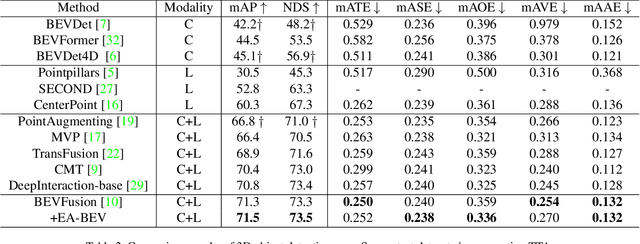
In recent years, great progress has been made in the Lift-Splat-Shot-based (LSS-based) 3D object detection method, which converts features of 2D camera view and 3D lidar view to Bird's-Eye-View (BEV) for feature fusion. However, inaccurate depth estimation (e.g. the 'depth jump' problem) is an obstacle to develop LSS-based methods. To alleviate the 'depth jump' problem, we proposed Edge-Aware Bird's-Eye-View (EA-BEV) projector. By coupling proposed edge-aware depth fusion module and depth estimate module, the proposed EA-BEV projector solves the problem and enforces refined supervision on depth. Besides, we propose sparse depth supervision and gradient edge depth supervision, for constraining learning on global depth and local marginal depth information. Our EA-BEV projector is a plug-and-play module for any LSS-based 3D object detection models, and effectively improves the baseline performance. We demonstrate the effectiveness on the nuScenes benchmark. On the nuScenes 3D object detection validation dataset, our proposed EA-BEV projector can boost several state-of-the-art LLS-based baselines on nuScenes 3D object detection benchmark and nuScenes BEV map segmentation benchmark with negligible increment of inference time.
GT-GAN: General Purpose Time Series Synthesis with Generative Adversarial Networks
Oct 05, 2022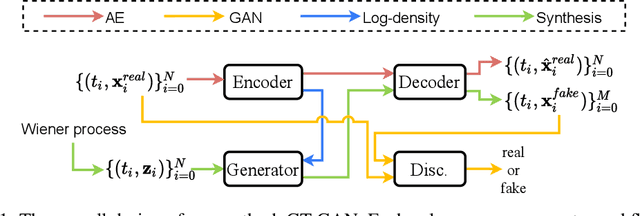
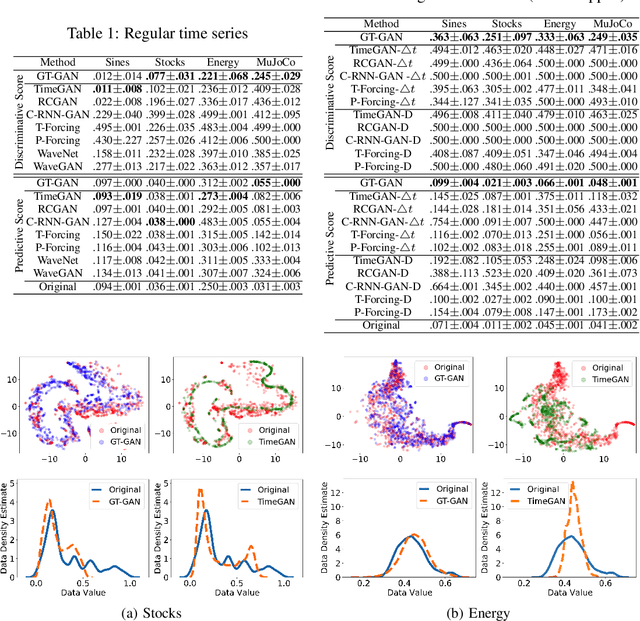
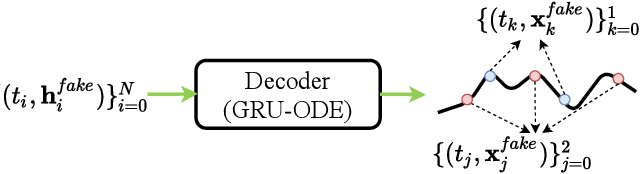
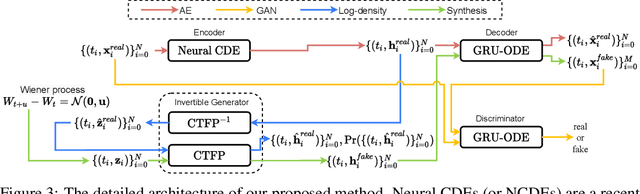
Time series synthesis is an important research topic in the field of deep learning, which can be used for data augmentation. Time series data types can be broadly classified into regular or irregular. However, there are no existing generative models that show good performance for both types without any model changes. Therefore, we present a general purpose model capable of synthesizing regular and irregular time series data. To our knowledge, we are the first designing a general purpose time series synthesis model, which is one of the most challenging settings for time series synthesis. To this end, we design a generative adversarial network-based method, where many related techniques are carefully integrated into a single framework, ranging from neural ordinary/controlled differential equations to continuous time-flow processes. Our method outperforms all existing methods.
Predicting Motion Plans for Articulating Everyday Objects
Mar 02, 2023
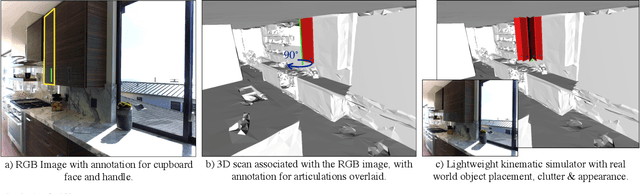
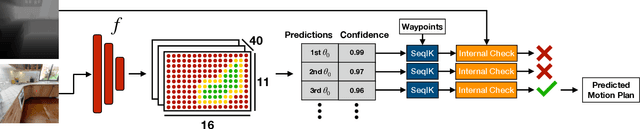
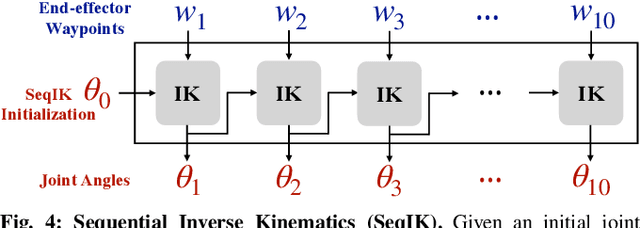
Mobile manipulation tasks such as opening a door, pulling open a drawer, or lifting a toilet lid require constrained motion of the end-effector under environmental and task constraints. This, coupled with partial information in novel environments, makes it challenging to employ classical motion planning approaches at test time. Our key insight is to cast it as a learning problem to leverage past experience of solving similar planning problems to directly predict motion plans for mobile manipulation tasks in novel situations at test time. To enable this, we develop a simulator, ArtObjSim, that simulates articulated objects placed in real scenes. We then introduce SeqIK+$\theta_0$, a fast and flexible representation for motion plans. Finally, we learn models that use SeqIK+$\theta_0$ to quickly predict motion plans for articulating novel objects at test time. Experimental evaluation shows improved speed and accuracy at generating motion plans than pure search-based methods and pure learning methods.
Hard Nominal Example-aware Template Mutual Matching for Industrial Anomaly Detection
Apr 04, 2023
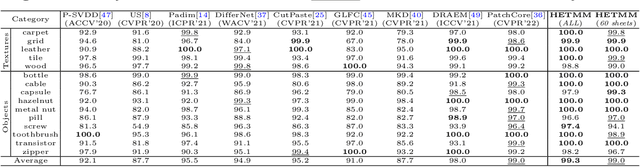
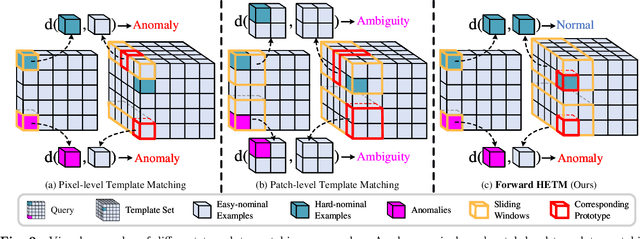
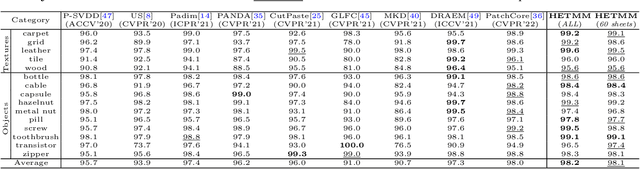
Anomaly detectors are widely used in industrial production to detect and localize unknown defects in query images. These detectors are trained on nominal images and have shown success in distinguishing anomalies from most normal samples. However, hard-nominal examples are scattered and far apart from most normalities, they are often mistaken for anomalies by existing anomaly detectors. To address this problem, we propose a simple yet efficient method: \textbf{H}ard Nominal \textbf{E}xample-aware \textbf{T}emplate \textbf{M}utual \textbf{M}atching (HETMM). Specifically, \textit{HETMM} aims to construct a robust prototype-based decision boundary, which can precisely distinguish between hard-nominal examples and anomalies, yielding fewer false-positive and missed-detection rates. Moreover, \textit{HETMM} mutually explores the anomalies in two directions between queries and the template set, and thus it is capable to capture the logical anomalies. This is a significant advantage over most anomaly detectors that frequently fail to detect logical anomalies. Additionally, to meet the speed-accuracy demands, we further propose \textbf{P}ixel-level \textbf{T}emplate \textbf{S}election (PTS) to streamline the original template set. \textit{PTS} selects cluster centres and hard-nominal examples to form a tiny set, maintaining the original decision boundaries. Comprehensive experiments on five real-world datasets demonstrate that our methods yield outperformance than existing advances under the real-time inference speed. Furthermore, \textit{HETMM} can be hot-updated by inserting novel samples, which may promptly address some incremental learning issues.
Sensing Performance of Cooperative Joint Sensing-Communication UAV Network
Apr 04, 2023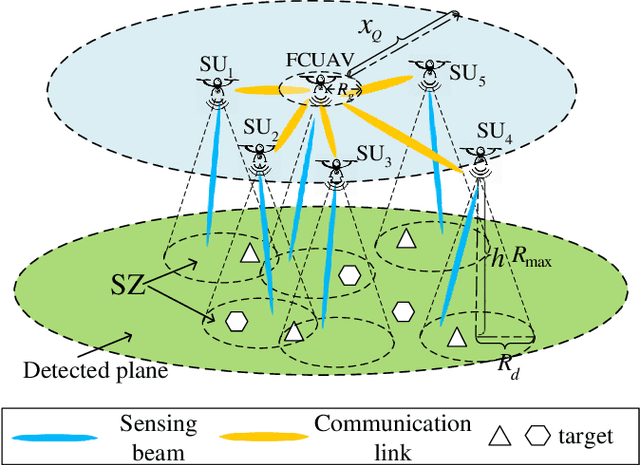
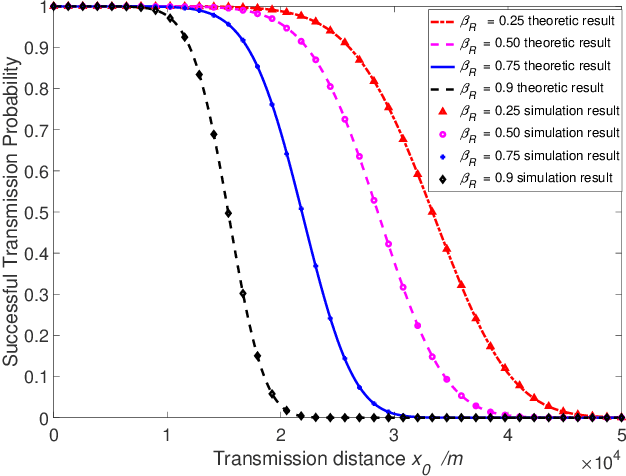
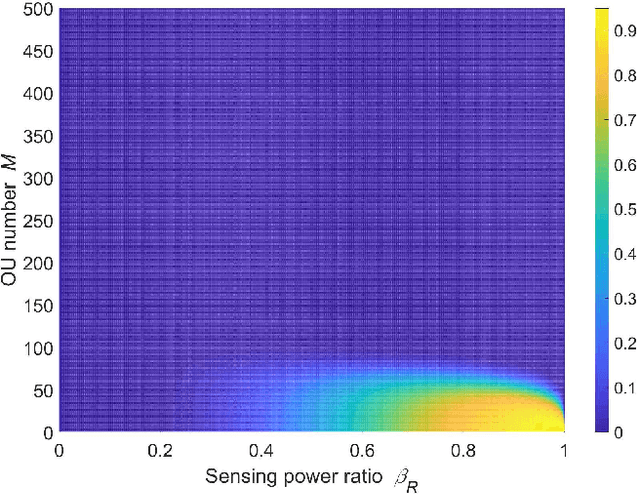

We propose a novel cooperative joint sensing-communication (JSC) unmanned aerial vehicle (UAV) network that can achieve downward-looking detection and transmit detection data simultaneously using the same time and frequency resources by exploiting the beam sharing scheme. The UAV network consists of a UAV that works as a fusion center (FCUAV) and multiple subordinate UAVs (SU). All UAVs fly at the fixed height. FCUAV integrates the sensing data of network and carries out downward-looking detection. SUs carry out downward-looking detection and transmit the sensing data to FCUAV. To achieve the beam sharing scheme, each UAV is equipped with a novel JSC antenna array that is composed of both the sensing subarray (SenA) and the communication subarray (ComA) in order to generate the sensing beam (SenB) and the communication beam (ComB) for detection and communication, respectively. SenB and ComB of each UAV share a total amount of radio power. Because of the spatial orthogonality of communication and sensing, SenB and ComB can be easily formed orthogonally. The upper bound of average cooperative sensing area (UB-ACSA) is defined as the metric to measure the sensing performance, which is related to the mutual sensing interference and the communication capacity. Numerical simulations prove the validity of the theoretical expressions for UB-ACSA of the network. The optimal number of UAVs and the optimal SenB power are identified under the total power constraint.
* 13 Pages, 14 figures, accepted by IEEE TVT
Image Blind Denoising Using Dual Convolutional Neural Network with Skip Connection
Apr 04, 2023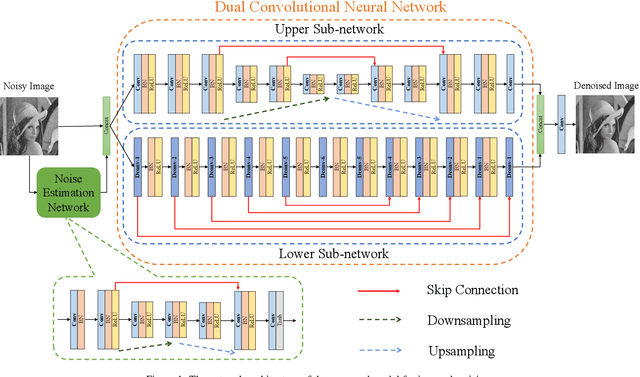

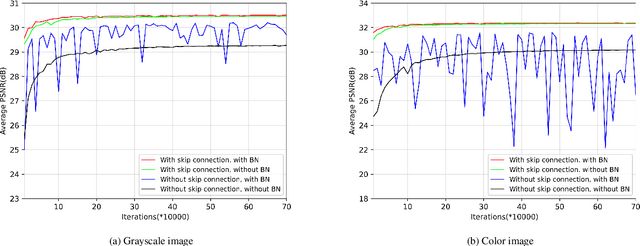
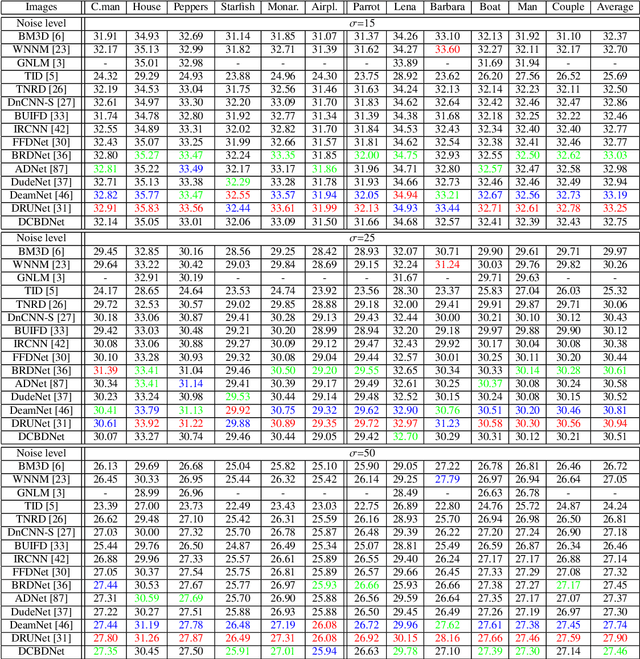
In recent years, deep convolutional neural networks have shown fascinating performance in the field of image denoising. However, deeper network architectures are often accompanied with large numbers of model parameters, leading to high training cost and long inference time, which limits their application in practical denoising tasks. In this paper, we propose a novel dual convolutional blind denoising network with skip connection (DCBDNet), which is able to achieve a desirable balance between the denoising effect and network complexity. The proposed DCBDNet consists of a noise estimation network and a dual convolutional neural network (CNN). The noise estimation network is used to estimate the noise level map, which improves the flexibility of the proposed model. The dual CNN contains two branches: a u-shaped sub-network is designed for the upper branch, and the lower branch is composed of the dilated convolution layers. Skip connections between layers are utilized in both the upper and lower branches. The proposed DCBDNet was evaluated on several synthetic and real-world image denoising benchmark datasets. Experimental results have demonstrated that the proposed DCBDNet can effectively remove gaussian noise in a wide range of levels, spatially variant noise and real noise. With a simple model structure, our proposed DCBDNet still can obtain competitive denoising performance compared to the state-of-the-art image denoising models containing complex architectures. Namely, a favorable trade-off between denoising performance and model complexity is achieved. Codes are available at https://github.com/WenCongWu/DCBDNet.
DLRover: An Elastic Deep Training Extension with Auto Job Resource Recommendation
Apr 04, 2023
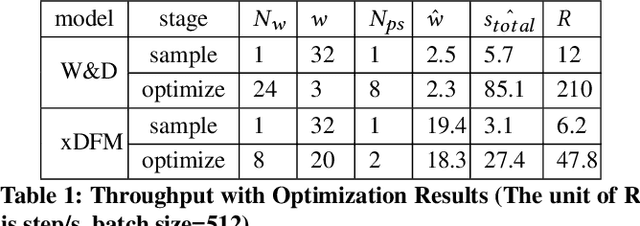
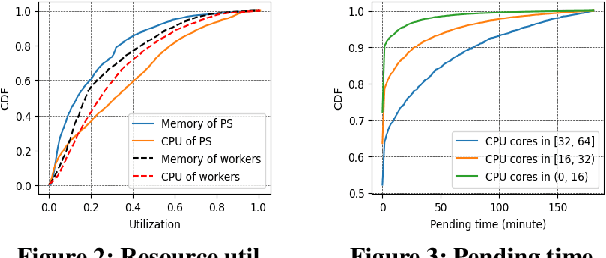
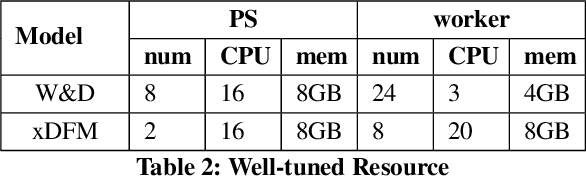
The cloud is still a popular platform for distributed deep learning (DL) training jobs since resource sharing in the cloud can improve resource utilization and reduce overall costs. However, such sharing also brings multiple challenges for DL training jobs, e.g., high-priority jobs could impact, even interrupt, low-priority jobs. Meanwhile, most existing distributed DL training systems require users to configure the resources (i.e., the number of nodes and resources like CPU and memory allocated to each node) of jobs manually before job submission and can not adjust the job's resources during the runtime. The resource configuration of a job deeply affect this job's performance (e.g., training throughput, resource utilization, and completion rate). However, this usually leads to poor performance of jobs since users fail to provide optimal resource configuration in most cases. \system~is a distributed DL framework can auto-configure a DL job's initial resources and dynamically tune the job's resources to win the better performance. With elastic capability, \system~can effectively adjusts the resources of a job when there are performance issues detected or a job fails because of faults or eviction. Evaluations results show \system~can outperform manual well-tuned resource configurations. Furthermore, in the production Kubernetes cluster of \company, \system~reduces the medium of job completion time by 31\%, and improves the job completion rate by 6\%, CPU utilization by 15\%, and memory utilization by 20\% compared with manual configuration.