 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTG-Insight: A Multi-Agent Interpretable LLM Framework for Cardiotocography Analysis and Classification
Jul 29, 2025Remote fetal monitoring technologies are becoming increasingly common. Yet, most current systems offer limited interpretability, leaving expectant parents with raw cardiotocography (CTG) data that is difficult to understand. In this work, we present CTG-Insight, a multi-agent LLM system that provides structured interpretations of fetal heart rate (FHR) and uterine contraction (UC) signals. Drawing from established medical guidelines, CTG-Insight decomposes each CTG trace into five medically defined features: baseline, variability, accelerations, decelerations, and sinusoidal pattern, each analyzed by a dedicated agent. A final aggregation agent synthesizes the outputs to deliver a holistic classification of fetal health, accompanied by a natural language explanation. We evaluate CTG-Insight on the NeuroFetalNet Dataset and compare it against deep learning models and the single-agent LLM baseline. Results show that CTG-Insight achieves state-of-the-art accuracy (96.4%) and F1-score (97.8%) while producing transparent and interpretable outputs. This work contributes an interpretable and extensible CTG analysis framework.
From Model Explanation to Data Misinterpretation: Uncovering the Pitfalls of Post Hoc Explainers in Business Research
Aug 30, 2024



Machine learning models have been increasingly used in business research. However, most state-of-the-art machine learning models, such as deep neural networks and XGBoost, are black boxes in nature. Therefore, post hoc explainers that provide explanations for machine learning models by, for example, estimating numerical importance of the input features, have been gaining wide usage. Despite the intended use of post hoc explainers being explaining machine learning models, we found a growing trend in business research where post hoc explanations are used to draw inferences about the data. In this work, we investigate the validity of such use. Specifically, we investigate with extensive experiments whether the explanations obtained by the two most popular post hoc explainers, SHAP and LIME, provide correct information about the true marginal effects of X on Y in the data, which we call data-alignment. We then identify what factors influence the alignment of explanations. Finally, we propose a set of mitigation strategies to improve the data-alignment of explanations and demonstrate their effectiveness with real-world data in an econometric context. In spite of this effort, we nevertheless conclude that it is often not appropriate to infer data insights from post hoc explanations. We articulate appropriate alternative uses, the most important of which is to facilitate the proposition and subsequent empirical investigation of hypotheses. The ultimate goal of this paper is to caution business researchers against translating post hoc explanations of machine learning models into potentially false insights and understanding of data.
Exoplanet Detection in Starshade Images
Mar 17, 2021
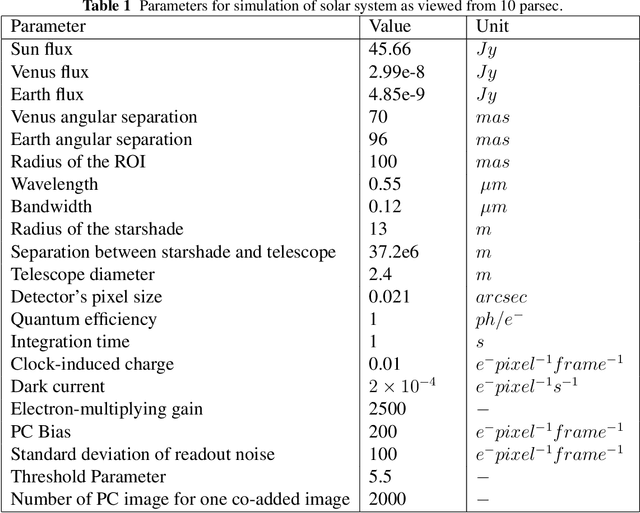
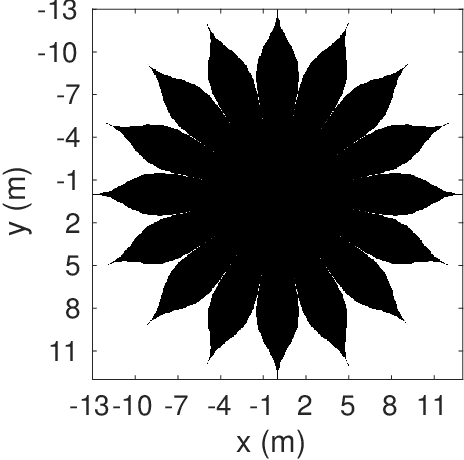

A starshade suppresses starlight by a factor of 1E11 in the image plane of a telescope, which is crucial for directly imaging Earth-like exoplanets. The state of the art in high contrast post-processing and signal detection methods were developed specifically for images taken with an internal coronagraph system and focus on the removal of quasi-static speckles. These methods are less useful for starshade images where such speckles are not present. This paper is dedicated to investigating signal processing methods tailored to work efficiently on starshade images. We describe a signal detection method, the generalized likelihood ratio test (GLRT), for starshade missions and look into three important problems. First, even with the light suppression provided by the starshade, rocky exoplanets are still difficult to detect in reflected light due to their absolute faintness. GLRT can successfully flag these dim planets. Moreover, GLRT provides estimates of the planets' positions and intensities and the theoretical false alarm rate of the detection. Second, small starshade shape errors, such as a truncated petal tip, can cause artifacts that are hard to distinguish from real planet signals; the detection method can help distinguish planet signals from such artifacts. The third direct imaging problem is that exozodiacal dust degrades detection performance. We develop an iterative generalized likelihood ratio test to mitigate the effect of dust on the image. In addition, we provide guidance on how to choose the number of photon counting images to combine into one co-added image before doing detection, which will help utilize the observation time efficiently. All the methods are demonstrated on realistic simulated images.
Early Predictions for Medical Crowdfunding: A Deep Learning Approach Using Diverse Inputs
Nov 09, 2019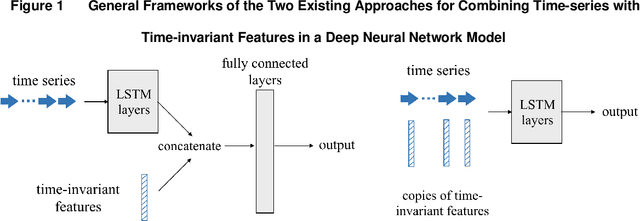
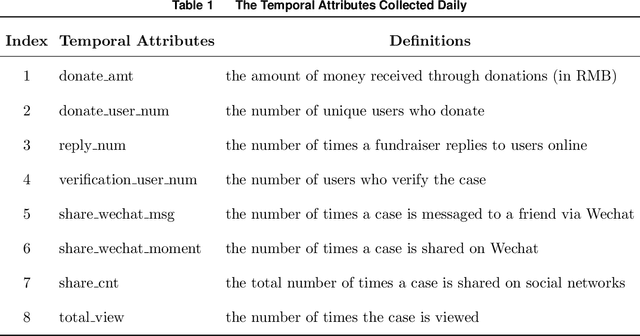
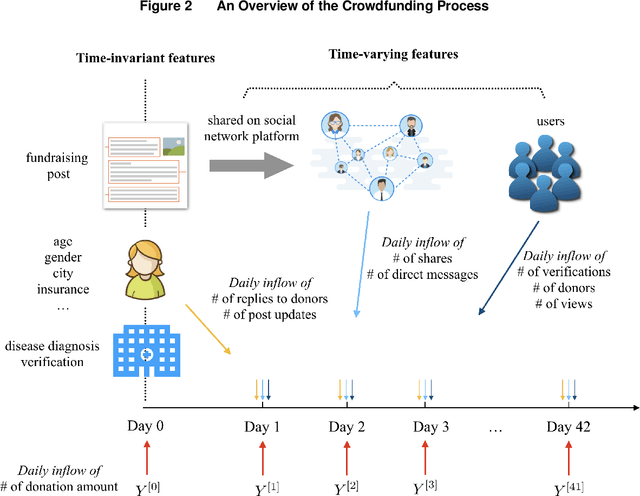
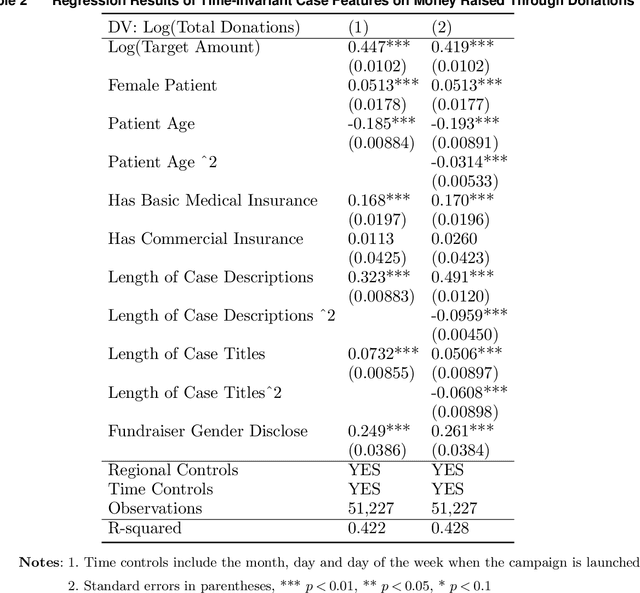
Medical crowdfunding is a popular channel for people needing financial help paying medical bills to collect donations from large numbers of people. However, large heterogeneity exists in donations across cases, and fundraisers face significant uncertainty in whether their crowdfunding campaigns can meet fundraising goals. Therefore, it is important to provide early warnings for fundraisers if such a channel will eventually fail. In this study, we aim to develop novel algorithms to provide accurate and timely predictions of fundraising performance, to better inform fundraisers. In particular, we propose a new approach to combine time-series features and time-invariant features in the deep learning model, to process diverse sources of input data. Compared with baseline models, our model achieves better accuracy and requires a shorter observation window of the time-varying features from the campaign launch to provide robust predictions with high confidence. To extract interpretable insights, we further conduct a multivariate time-series clustering analysis and identify four typical temporal donation patterns. This demonstrates the heterogeneity in the features and how they relate to the fundraising outcome. The prediction model and the interpretable insights can be applied to assist fundraisers with better promoting their fundraising campaigns and can potentially help crowdfunding platforms to provide more timely feedback to all fundraisers. Our proposed framework is also generalizable to other fields where diverse structured and unstructured data are valuable for predictions.