 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Moccasin: Efficient Tensor Rematerialization for Neural Networks
Apr 27, 2023
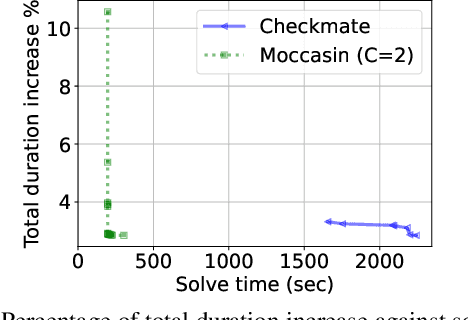
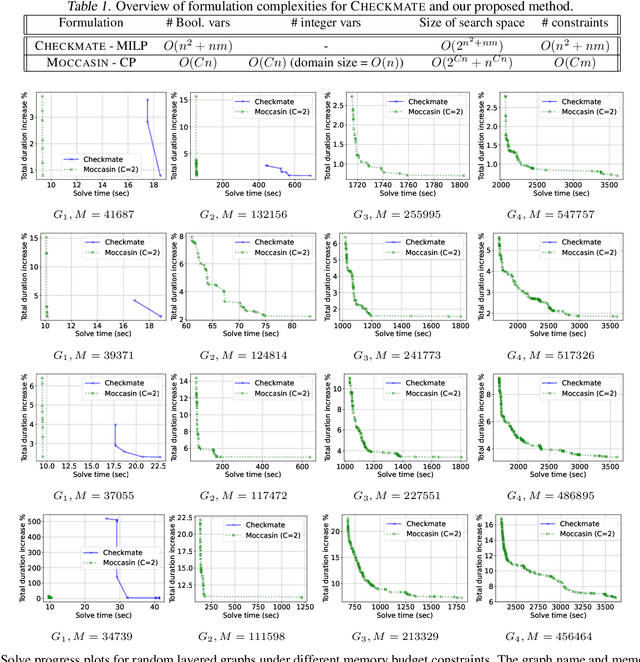
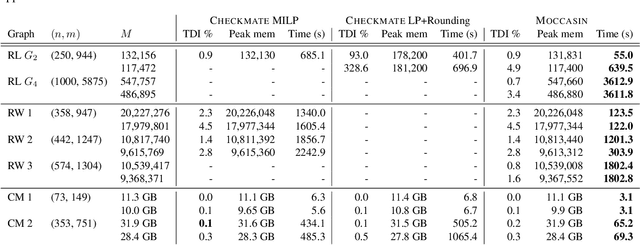
The deployment and training of neural networks on edge computing devices pose many challenges. The low memory nature of edge devices is often one of the biggest limiting factors encountered in the deployment of large neural network models. Tensor rematerialization or recompute is a way to address high memory requirements for neural network training and inference. In this paper we consider the problem of execution time minimization of compute graphs subject to a memory budget. In particular, we develop a new constraint programming formulation called \textsc{Moccasin} with only $O(n)$ integer variables, where $n$ is the number of nodes in the compute graph. This is a significant improvement over the works in the recent literature that propose formulations with $O(n^2)$ Boolean variables. We present numerical studies that show that our approach is up to an order of magnitude faster than recent work especially for large-scale graphs.
One-Step Distributional Reinforcement Learning
Apr 27, 2023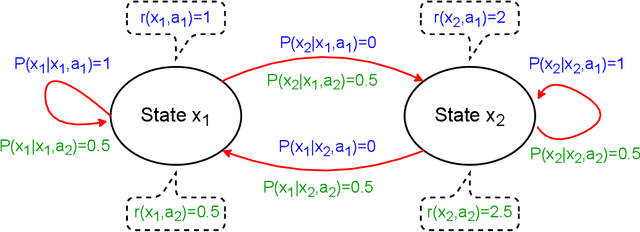
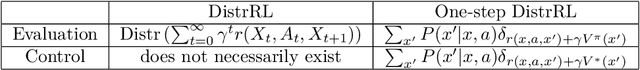
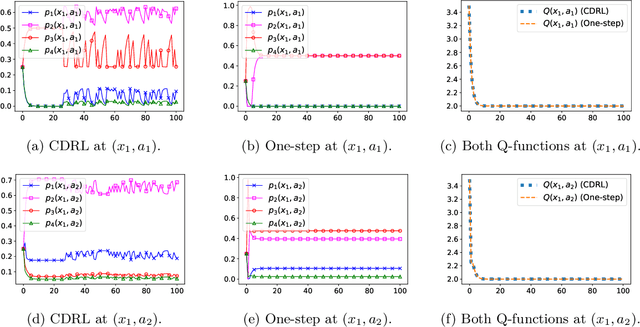

Reinforcement learning (RL) allows an agent interacting sequentially with an environment to maximize its long-term expected return. In the distributional RL (DistrRL) paradigm, the agent goes beyond the limit of the expected value, to capture the underlying probability distribution of the return across all time steps. The set of DistrRL algorithms has led to improved empirical performance. Nevertheless, the theory of DistrRL is still not fully understood, especially in the control case. In this paper, we present the simpler one-step distributional reinforcement learning (OS-DistrRL) framework encompassing only the randomness induced by the one-step dynamics of the environment. Contrary to DistrRL, we show that our approach comes with a unified theory for both policy evaluation and control. Indeed, we propose two OS-DistrRL algorithms for which we provide an almost sure convergence analysis. The proposed approach compares favorably with categorical DistrRL on various environments.
Incremental Generalized Category Discovery
Apr 27, 2023We explore the problem of Incremental Generalized Category Discovery (IGCD). This is a challenging category incremental learning setting where the goal is to develop models that can correctly categorize images from previously seen categories, in addition to discovering novel ones. Learning is performed over a series of time steps where the model obtains new labeled and unlabeled data, and discards old data, at each iteration. The difficulty of the problem is compounded in our generalized setting as the unlabeled data can contain images from categories that may or may not have been observed before. We present a new method for IGCD which combines non-parametric categorization with efficient image sampling to mitigate catastrophic forgetting. To quantify performance, we propose a new benchmark dataset named iNatIGCD that is motivated by a real-world fine-grained visual categorization task. In our experiments we outperform existing related methods
Time-Efficient Reward Learning via Visually Assisted Cluster Ranking
Nov 30, 2022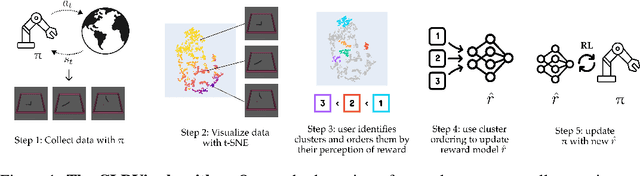
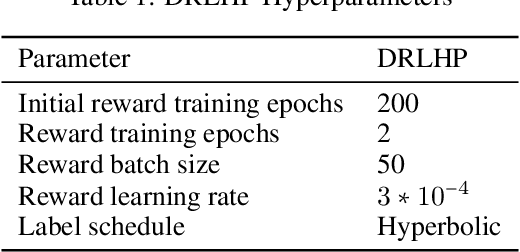

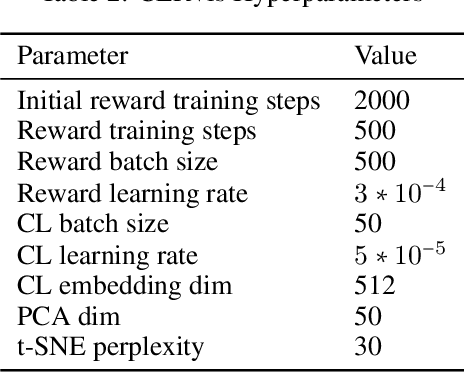
One of the most successful paradigms for reward learning uses human feedback in the form of comparisons. Although these methods hold promise, human comparison labeling is expensive and time consuming, constituting a major bottleneck to their broader applicability. Our insight is that we can greatly improve how effectively human time is used in these approaches by batching comparisons together, rather than having the human label each comparison individually. To do so, we leverage data dimensionality-reduction and visualization techniques to provide the human with a interactive GUI displaying the state space, in which the user can label subportions of the state space. Across some simple Mujoco tasks, we show that this high-level approach holds promise and is able to greatly increase the performance of the resulting agents, provided the same amount of human labeling time.
Synthetic Aperture Anomaly Imaging
Apr 26, 2023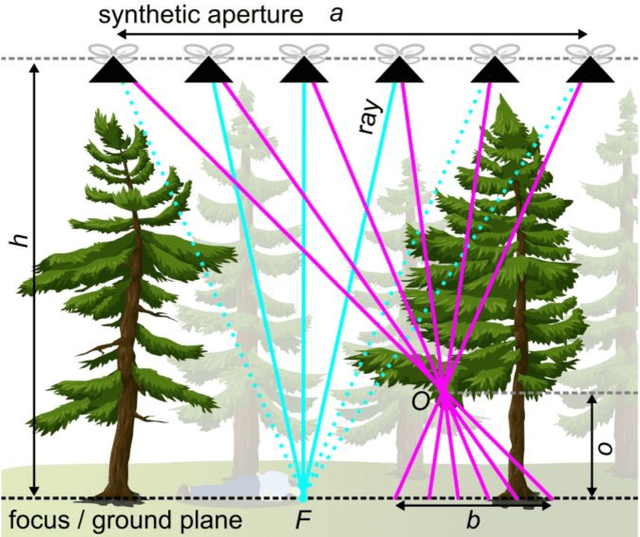
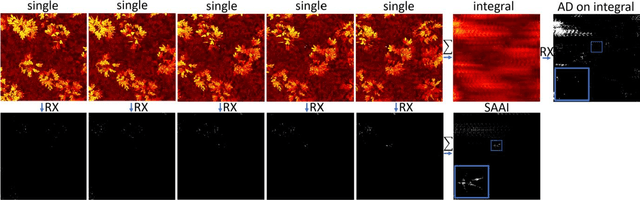
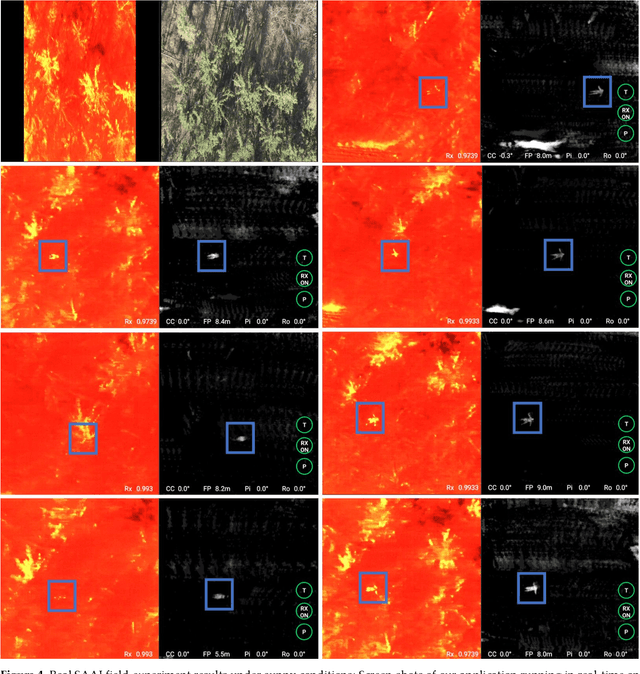
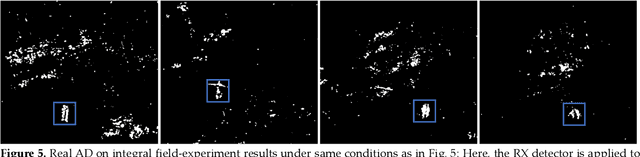
Previous research has shown that in the presence of foliage occlusion, anomaly detection performs significantly better in integral images resulting from synthetic aperture imaging compared to applying it to conventional aerial images. In this article, we hypothesize and demonstrate that integrating detected anomalies is even more effective than detecting anomalies in integrals. This results in enhanced occlusion removal, outlier suppression, and higher chances of visually as well as computationally detecting targets that are otherwise occluded. Our hypothesis was validated through both: simulations and field experiments. We also present a real-time application that makes our findings practically available for blue-light organizations and others using commercial drone platforms. It is designed to address use-cases that suffer from strong occlusion caused by vegetation, such as search and rescue, wildlife observation, early wildfire detection, and sur-veillance.
Tensor Decomposition for Model Reduction in Neural Networks: A Review
Apr 26, 2023
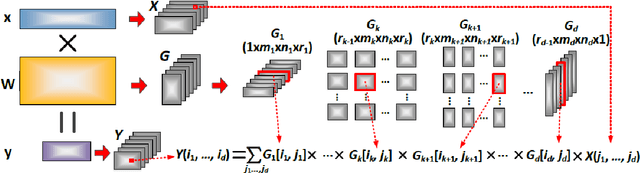
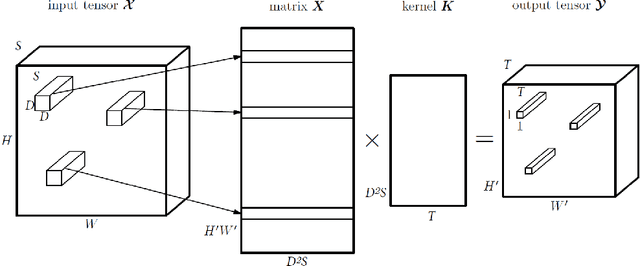
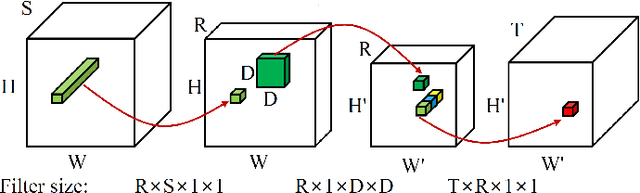
Modern neural networks have revolutionized the fields of computer vision (CV) and Natural Language Processing (NLP). They are widely used for solving complex CV tasks and NLP tasks such as image classification, image generation, and machine translation. Most state-of-the-art neural networks are over-parameterized and require a high computational cost. One straightforward solution is to replace the layers of the networks with their low-rank tensor approximations using different tensor decomposition methods. This paper reviews six tensor decomposition methods and illustrates their ability to compress model parameters of convolutional neural networks (CNNs), recurrent neural networks (RNNs) and Transformers. The accuracy of some compressed models can be higher than the original versions. Evaluations indicate that tensor decompositions can achieve significant reductions in model size, run-time and energy consumption, and are well suited for implementing neural networks on edge devices.
Association Rules Mining with Auto-Encoders
Apr 26, 2023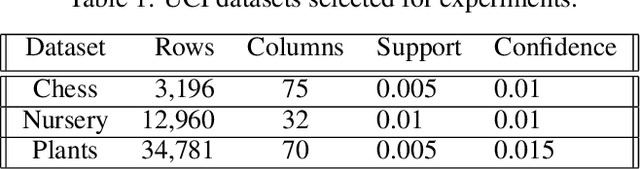
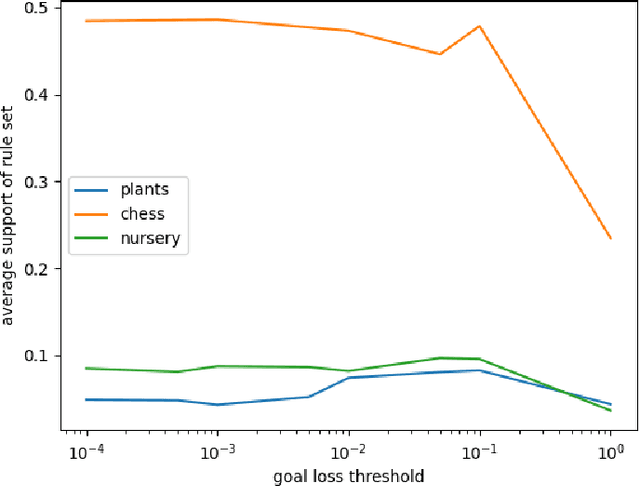


Association rule mining is one of the most studied research fields of data mining, with applications ranging from grocery basket problems to explainable classification systems. Classical association rule mining algorithms have several limitations, especially with regards to their high execution times and number of rules produced. Over the past decade, neural network solutions have been used to solve various optimization problems, such as classification, regression or clustering. However there are still no efficient way association rules using neural networks. In this paper, we present an auto-encoder solution to mine association rule called ARM-AE. We compare our algorithm to FP-Growth and NSGAII on three categorical datasets, and show that our algorithm discovers high support and confidence rule set and has a better execution time than classical methods while preserving the quality of the rule set produced.
Faster OreFSDet : A Lightweight and Effective Few-shot Object Detector for Ore Images
May 02, 2023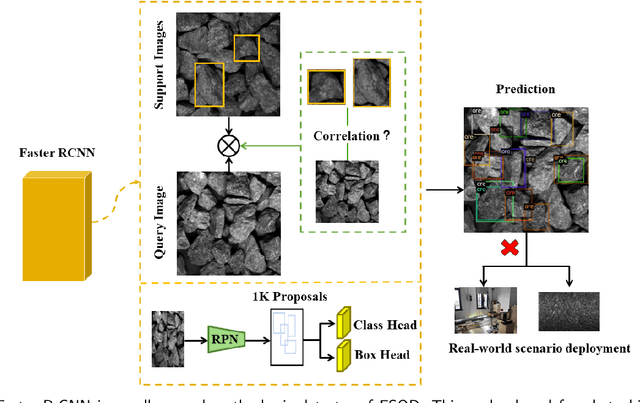
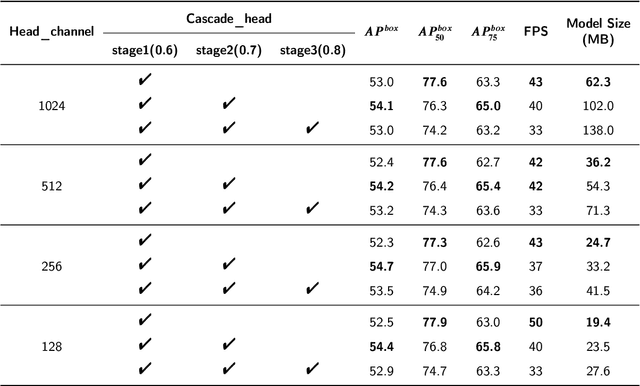
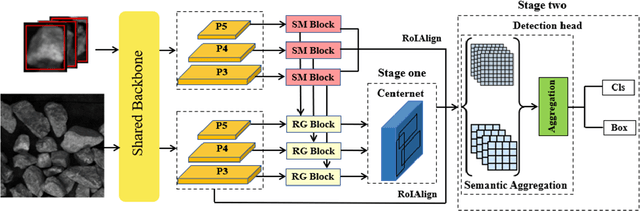
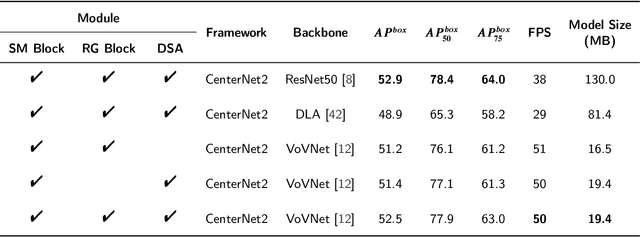
For the ore particle size detection, obtaining a sizable amount of high-quality ore labeled data is time-consuming and expensive. General object detection methods often suffer from severe over-fitting with scarce labeled data. Despite their ability to eliminate over-fitting, existing few-shot object detectors encounter drawbacks such as slow detection speed and high memory requirements, making them difficult to implement in a real-world deployment scenario. To this end, we propose a lightweight and effective few-shot detector to achieve competitive performance with general object detection with only a few samples for ore images. First, the proposed support feature mining block characterizes the importance of location information in support features. Next, the relationship guidance block makes full use of support features to guide the generation of accurate candidate proposals. Finally, the dual-scale semantic aggregation module retrieves detailed features at different resolutions to contribute with the prediction process. Experimental results show that our method consistently exceeds the few-shot detectors with an excellent performance gap on all metrics. Moreover, our method achieves the smallest model size of 19MB as well as being competitive at 50 FPS detection speed compared with general object detectors. The source code is available at https://github.com/MVME-HBUT/Faster-OreFSDet.
EasyPortrait -- Face Parsing and Portrait Segmentation Dataset
May 02, 2023
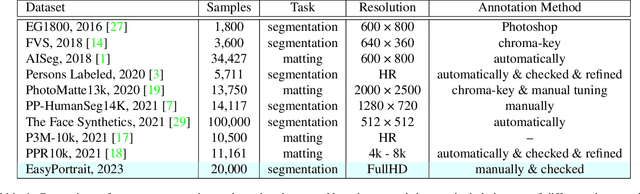
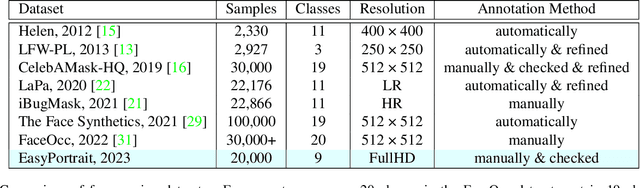

Recently, due to COVID-19 and the growing demand for remote work, video conferencing apps have become especially widespread. The most valuable features of video chats are real-time background removal and face beautification. While solving these tasks, computer vision researchers face the problem of having relevant data for the training stage. There is no large dataset with high-quality labeled and diverse images of people in front of a laptop or smartphone camera to train a lightweight model without additional approaches. To boost the progress in this area, we provide a new image dataset, EasyPortrait, for portrait segmentation and face parsing tasks. It contains 20,000 primarily indoor photos of 8,377 unique users, and fine-grained segmentation masks separated into 9 classes. Images are collected and labeled from crowdsourcing platforms. Unlike most face parsing datasets, in EasyPortrait, the beard is not considered part of the skin mask, and the inside area of the mouth is separated from the teeth. These features allow using EasyPortrait for skin enhancement and teeth whitening tasks. This paper describes the pipeline for creating a large-scale and clean image segmentation dataset using crowdsourcing platforms without additional synthetic data. Moreover, we trained several models on EasyPortrait and showed experimental results. Proposed dataset and trained models are publicly available.
An Asynchronous Decentralized Algorithm for Wasserstein Barycenter Problem
Apr 23, 2023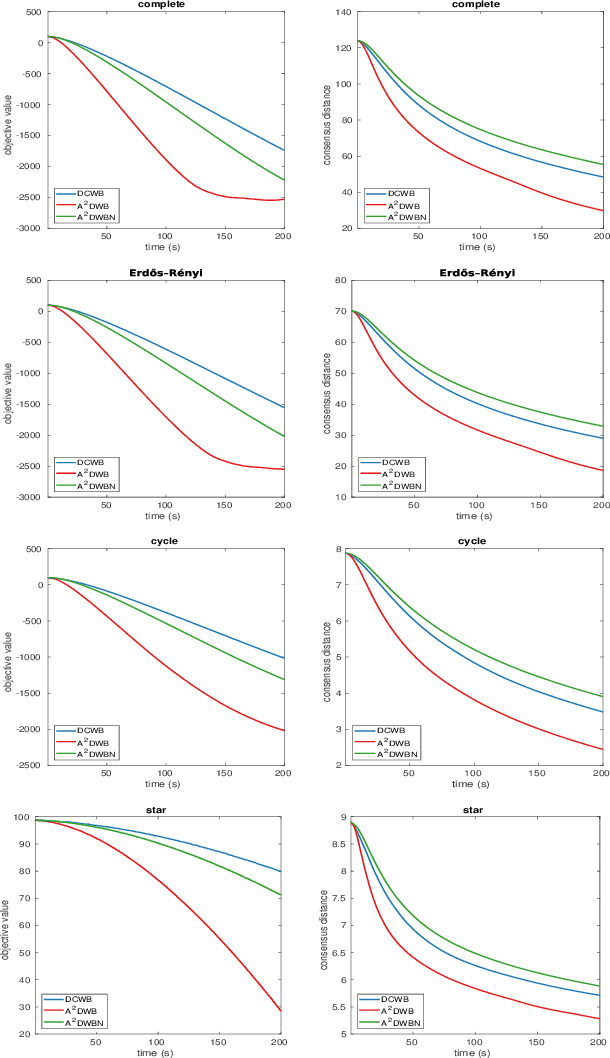
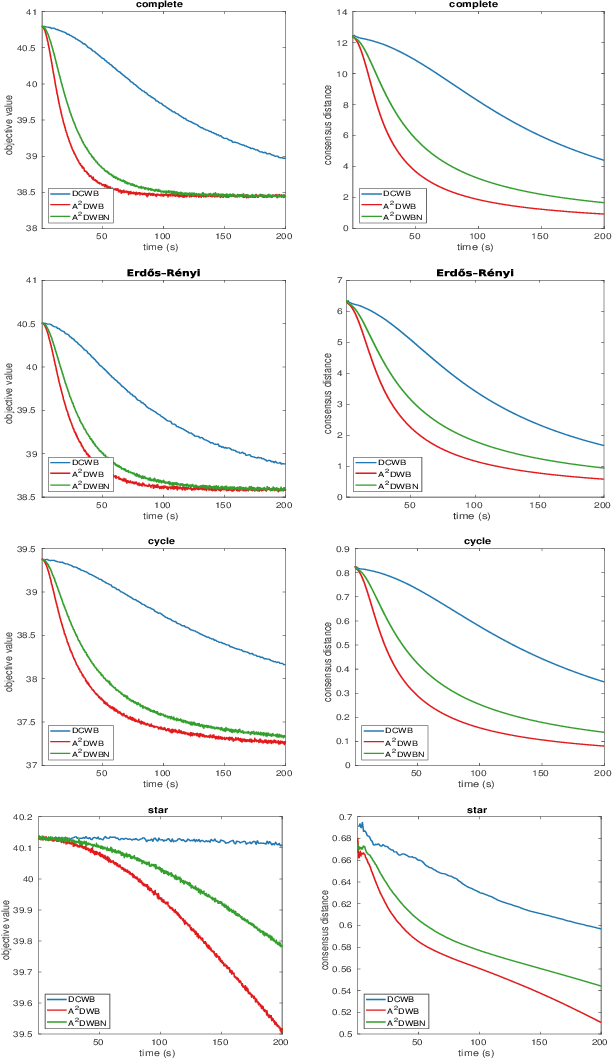
Wasserstein Barycenter Problem (WBP) has recently received much attention in the field of artificial intelligence. In this paper, we focus on the decentralized setting for WBP and propose an asynchronous decentralized algorithm (A$^2$DWB). A$^2$DWB is induced by a novel stochastic block coordinate descent method to optimize the dual of entropy regularized WBP. To our knowledge, A$^2$DWB is the first asynchronous decentralized algorithm for WBP. Unlike its synchronous counterpart, it updates local variables in a manner that only relies on the stale neighbor information, which effectively alleviate the waiting overhead, and thus substantially improve the time efficiency. Empirical results validate its superior performance compared to the latest synchronous algorithm.