 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCanViT: Toward Active-Vision Foundation Models
Mar 23, 2026Active computer vision promises efficient, biologically plausible perception through sequential, localized glimpses, but lacks scalable general-purpose architectures and pretraining pipelines. As a result, Active-Vision Foundation Models (AVFMs) have remained unexplored. We introduce CanViT, the first task- and policy-agnostic AVFM. CanViT uses scene-relative RoPE to bind a retinotopic Vision Transformer backbone and a spatiotopic scene-wide latent workspace, the canvas. Efficient interaction with this high-capacity working memory is supported by Canvas Attention, a novel asymmetric cross-attention mechanism. We decouple thinking (backbone-level) and memory (canvas-level), eliminating canvas-side self-attention and fully-connected layers to achieve low-latency sequential inference and scalability to large scenes. We propose a label-free active vision pretraining scheme, policy-agnostic passive-to-active dense latent distillation: reconstructing scene-wide DINOv3 embeddings from sequences of low-resolution glimpses with randomized locations, zoom levels, and lengths. We pretrain CanViT-B from a random initialization on 13.2 million ImageNet-21k scenes -- an order of magnitude more than previous active models -- and 1 billion random glimpses, in 166 hours on a single H100. On ADE20K segmentation, a frozen CanViT-B achieves 38.5% mIoU in a single low-resolution glimpse, outperforming the best active model's 27.6% with 19.5x fewer inference FLOPs and no fine-tuning, as well as its FLOP- or input-matched DINOv3 teacher. Given additional glimpses, CanViT-B reaches 45.9% ADE20K mIoU. On ImageNet-1k classification, CanViT-B reaches 81.2% top-1 accuracy with frozen teacher probes. CanViT generalizes to longer rollouts, larger scenes, and new policies. Our work closes the wide gap between passive and active vision on semantic segmentation and demonstrates the potential of AVFMs as a new research axis.
Signal from Structure: Exploiting Submodular Upper Bounds in Generative Flow Networks
Jan 28, 2026Generative Flow Networks (GFlowNets; GFNs) are a class of generative models that learn to sample compositional objects proportionally to their a priori unknown value, their reward. We focus on the case where the reward has a specified, actionable structure, namely that it is submodular. We show submodularity can be harnessed to retrieve upper bounds on the reward of compositional objects that have not yet been observed. We provide in-depth analyses of the probability of such bounds occurring, as well as how many unobserved compositional objects can be covered by a bound. Following the Optimism in the Face of Uncertainty principle, we then introduce SUBo-GFN, which uses the submodular upper bounds to train a GFN. We show that SUBo-GFN generates orders of magnitude more training data than classical GFNs for the same number of queries to the reward function. We demonstrate the effectiveness of SUBo-GFN in terms of distribution matching and high-quality candidate generation on synthetic and real-world submodular tasks.
LLM-as-a-Judge: Toward World Models for Slate Recommendation Systems
Nov 06, 2025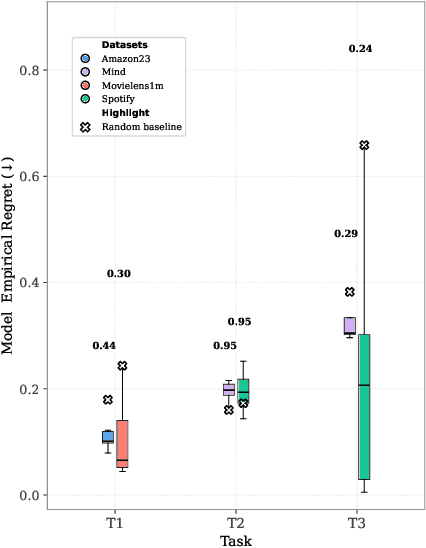
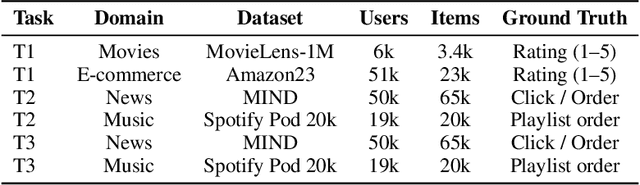
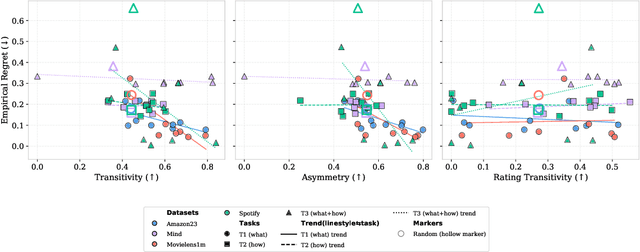
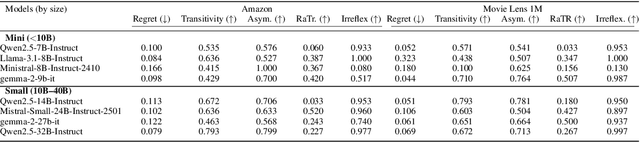
Modeling user preferences across domains remains a key challenge in slate recommendation (i.e. recommending an ordered sequence of items) research. We investigate how Large Language Models (LLM) can effectively act as world models of user preferences through pairwise reasoning over slates. We conduct an empirical study involving several LLMs on three tasks spanning different datasets. Our results reveal relationships between task performance and properties of the preference function captured by LLMs, hinting towards areas for improvement and highlighting the potential of LLMs as world models in recommender systems.
Nested-ReFT: Efficient Reinforcement Learning for Large Language Model Fine-Tuning via Off-Policy Rollouts
Aug 13, 2025Advanced reasoning in LLMs on challenging domains like mathematical reasoning can be tackled using verifiable rewards based reinforced fine-tuning (ReFT). In standard ReFT frameworks, a behavior model generates multiple completions with answers per problem, for the answer to be then scored by a reward function. While such RL post-training methods demonstrate significant performance improvements across challenging reasoning domains, the computational cost of generating completions during training with multiple inference steps makes the training cost non-trivial. To address this, we draw inspiration from off-policy RL, and speculative decoding to introduce a novel ReFT framework, dubbed Nested-ReFT, where a subset of layers of the target model acts as the behavior model to generate off-policy completions during training. The behavior model configured with dynamic layer skipping per batch during training decreases the inference cost compared to the standard ReFT frameworks. Our theoretical analysis shows that Nested-ReFT yields unbiased gradient estimates with controlled variance. Our empirical analysis demonstrates improved computational efficiency measured as tokens/sec across multiple math reasoning benchmarks and model sizes. Additionally, we explore three variants of bias mitigation to minimize the off-policyness in the gradient updates that allows for maintaining performance that matches the baseline ReFT performance.
WAPTS: A Weighted Allocation Probability Adjusted Thompson Sampling Algorithm for High-Dimensional and Sparse Experiment Settings
Jan 07, 2025Aiming for more effective experiment design, such as in video content advertising where different content options compete for user engagement, these scenarios can be modeled as multi-arm bandit problems. In cases where limited interactions are available due to external factors, such as the cost of conducting experiments, recommenders often face constraints due to the small number of user interactions. In addition, there is a trade-off between selecting the best treatment and the ability to personalize and contextualize based on individual factors. A popular solution to this dilemma is the Contextual Bandit framework. It aims to maximize outcomes while incorporating personalization (contextual) factors, customizing treatments such as a user's profile to individual preferences. Despite their advantages, Contextual Bandit algorithms face challenges like measurement bias and the 'curse of dimensionality.' These issues complicate the management of numerous interventions and often lead to data sparsity through participant segmentation. To address these problems, we introduce the Weighted Allocation Probability Adjusted Thompson Sampling (WAPTS) algorithm. WAPTS builds on the contextual Thompson Sampling method by using a dynamic weighting parameter. This improves the allocation process for interventions and enables rapid optimization in data-sparse environments. We demonstrate the performance of our approach on different numbers of arms and effect sizes.
On shallow planning under partial observability
Jul 22, 2024Formulating a real-world problem under the Reinforcement Learning framework involves non-trivial design choices, such as selecting a discount factor for the learning objective (discounted cumulative rewards), which articulates the planning horizon of the agent. This work investigates the impact of the discount factor on the biasvariance trade-off given structural parameters of the underlying Markov Decision Process. Our results support the idea that a shorter planning horizon might be beneficial, especially under partial observability.
Neural Active Learning Meets the Partial Monitoring Framework
May 14, 2024



We focus on the online-based active learning (OAL) setting where an agent operates over a stream of observations and trades-off between the costly acquisition of information (labelled observations) and the cost of prediction errors. We propose a novel foundation for OAL tasks based on partial monitoring, a theoretical framework specialized in online learning from partially informative actions. We show that previously studied binary and multi-class OAL tasks are instances of partial monitoring. We expand the real-world potential of OAL by introducing a new class of cost-sensitive OAL tasks. We propose NeuralCBP, the first PM strategy that accounts for predictive uncertainty with deep neural networks. Our extensive empirical evaluation on open source datasets shows that NeuralCBP has favorable performance against state-of-the-art baselines on multiple binary, multi-class and cost-sensitive OAL tasks.
Randomized Confidence Bounds for Stochastic Partial Monitoring
Feb 07, 2024



The partial monitoring (PM) framework provides a theoretical formulation of sequential learning problems with incomplete feedback. On each round, a learning agent plays an action while the environment simultaneously chooses an outcome. The agent then observes a feedback signal that is only partially informative about the (unobserved) outcome. The agent leverages the received feedback signals to select actions that minimize the (unobserved) cumulative loss. In contextual PM, the outcomes depend on some side information that is observable by the agent before selecting the action on each round. In this paper, we consider the contextual and non-contextual PM settings with stochastic outcomes. We introduce a new class of strategies based on the randomization of deterministic confidence bounds, that extend regret guarantees to settings where existing stochastic strategies are not applicable. Our experiments show that the proposed RandCBP and RandCBPside* strategies improve state-of-the-art baselines in PM games. To encourage the adoption of the PM framework, we design a use case on the real-world problem of monitoring the error rate of any deployed classification system.
Association Rules Mining with Auto-Encoders
Apr 26, 2023



Association rule mining is one of the most studied research fields of data mining, with applications ranging from grocery basket problems to explainable classification systems. Classical association rule mining algorithms have several limitations, especially with regards to their high execution times and number of rules produced. Over the past decade, neural network solutions have been used to solve various optimization problems, such as classification, regression or clustering. However there are still no efficient way association rules using neural networks. In this paper, we present an auto-encoder solution to mine association rule called ARM-AE. We compare our algorithm to FP-Growth and NSGAII on three categorical datasets, and show that our algorithm discovers high support and confidence rule set and has a better execution time than classical methods while preserving the quality of the rule set produced.
Interpret Your Care: Predicting the Evolution of Symptoms for Cancer Patients
Feb 19, 2023



Cancer treatment is an arduous process for patients and causes many side-effects during and post-treatment. The treatment can affect almost all body systems and result in pain, fatigue, sleep disturbances, cognitive impairments, etc. These conditions are often under-diagnosed or under-treated. In this paper, we use patient data to predict the evolution of their symptoms such that treatment-related impairments can be prevented or effects meaningfully ameliorated. The focus of this study is on predicting the pain and tiredness level of a patient post their diagnosis. We implement an interpretable decision tree based model called LightGBM on real-world patient data consisting of 20163 patients. There exists a class imbalance problem in the dataset which we resolve using the oversampling technique of SMOTE. Our empirical results show that the value of the previous level of a symptom is a key indicator for prediction and the weighted average deviation in prediction of pain level is 3.52 and of tiredness level is 2.27.