 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Discovering Symbolic Laws Directly from Trajectories with Hamiltonian Graph Neural Networks
Jul 11, 2023
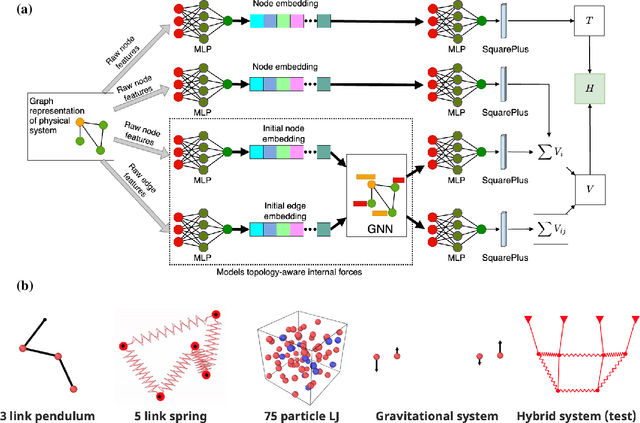

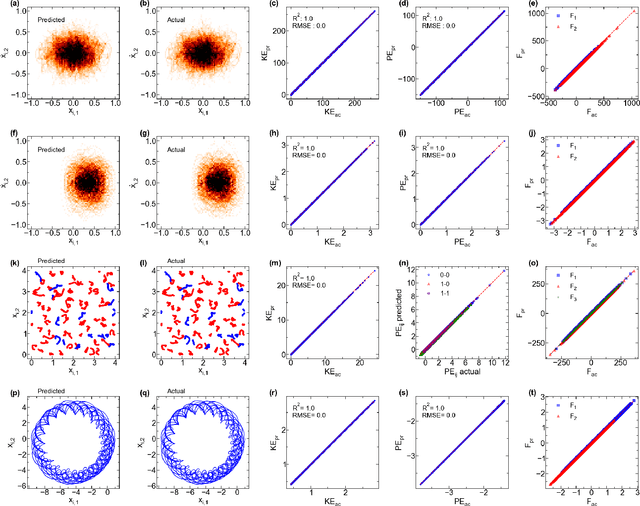
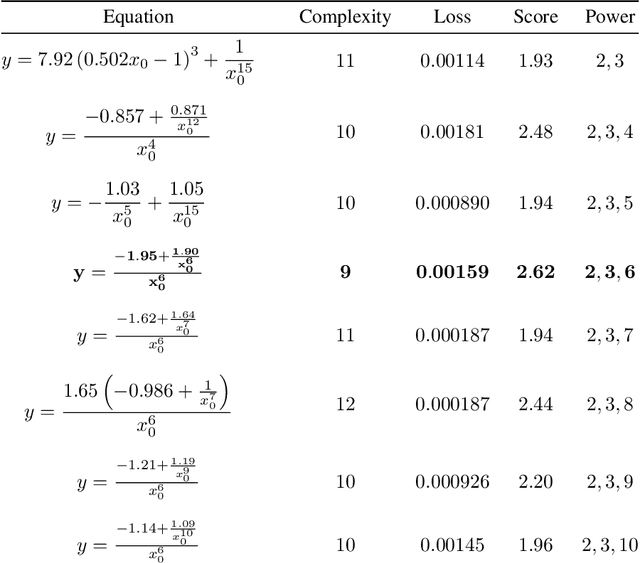
The time evolution of physical systems is described by differential equations, which depend on abstract quantities like energy and force. Traditionally, these quantities are derived as functionals based on observables such as positions and velocities. Discovering these governing symbolic laws is the key to comprehending the interactions in nature. Here, we present a Hamiltonian graph neural network (HGNN), a physics-enforced GNN that learns the dynamics of systems directly from their trajectory. We demonstrate the performance of HGNN on n-springs, n-pendulums, gravitational systems, and binary Lennard Jones systems; HGNN learns the dynamics in excellent agreement with the ground truth from small amounts of data. We also evaluate the ability of HGNN to generalize to larger system sizes, and to hybrid spring-pendulum system that is a combination of two original systems (spring and pendulum) on which the models are trained independently. Finally, employing symbolic regression on the learned HGNN, we infer the underlying equations relating the energy functionals, even for complex systems such as the binary Lennard-Jones liquid. Our framework facilitates the interpretable discovery of interaction laws directly from physical system trajectories. Furthermore, this approach can be extended to other systems with topology-dependent dynamics, such as cells, polydisperse gels, or deformable bodies.
ZJU ReLER Submission for EPIC-KITCHEN Challenge 2023: Semi-Supervised Video Object Segmentation
Jul 05, 2023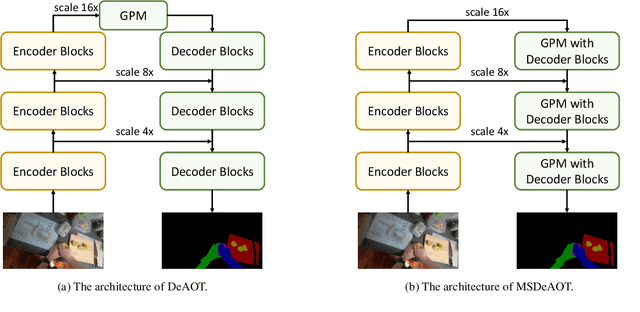

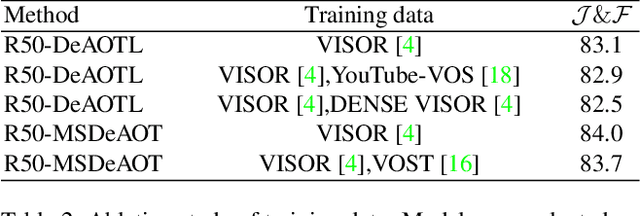

The Associating Objects with Transformers (AOT) framework has exhibited exceptional performance in a wide range of complex scenarios for video object segmentation. In this study, we introduce MSDeAOT, a variant of the AOT series that incorporates transformers at multiple feature scales. Leveraging the hierarchical Gated Propagation Module (GPM), MSDeAOT efficiently propagates object masks from previous frames to the current frame using a feature scale with a stride of 16. Additionally, we employ GPM in a more refined feature scale with a stride of 8, leading to improved accuracy in detecting and tracking small objects. Through the implementation of test-time augmentations and model ensemble techniques, we achieve the top-ranking position in the EPIC-KITCHEN VISOR Semi-supervised Video Object Segmentation Challenge.
Time-frequency Network for Robust Speaker Recognition
Mar 07, 2023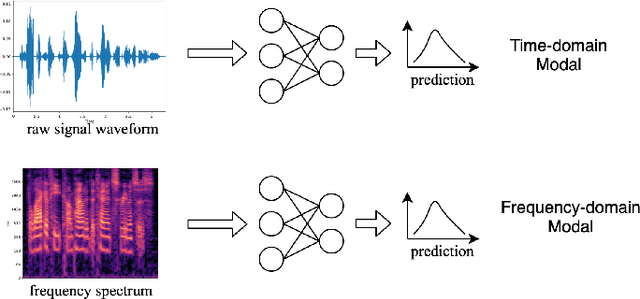
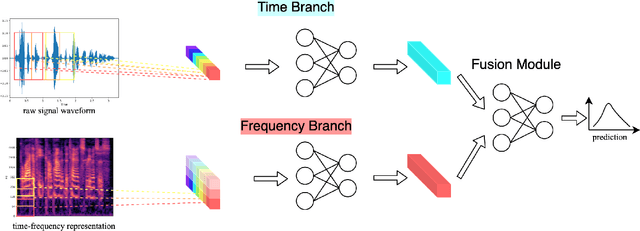
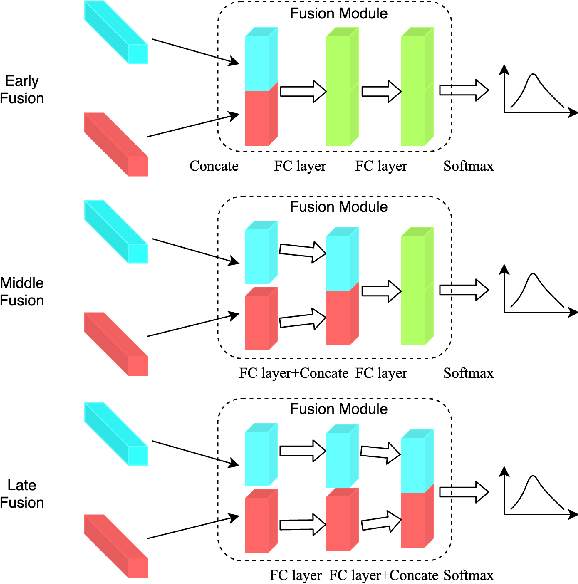
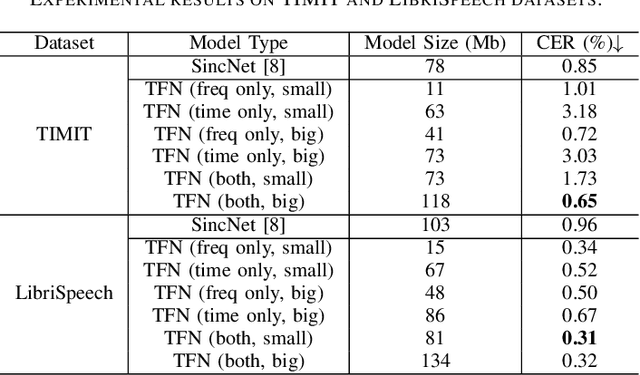
The wide deployment of speech-based biometric systems usually demands high-performance speaker recognition algorithms. However, most of the prior works for speaker recognition either process the speech in the frequency domain or time domain, which may produce suboptimal results because both time and frequency domains are important for speaker recognition. In this paper, we attempt to analyze the speech signal in both time and frequency domains and propose the time-frequency network~(TFN) for speaker recognition by extracting and fusing the features in the two domains. Based on the recent advance of deep neural networks, we propose a convolution neural network to encode the raw speech waveform and the frequency spectrum into domain-specific features, which are then fused and transformed into a classification feature space for speaker recognition. Experimental results on the publicly available datasets TIMIT and LibriSpeech show that our framework is effective to combine the information in the two domains and performs better than the state-of-the-art methods for speaker recognition.
Prediction of Time and Distance of Trips Using Explainable Attention-based LSTMs
Mar 27, 2023
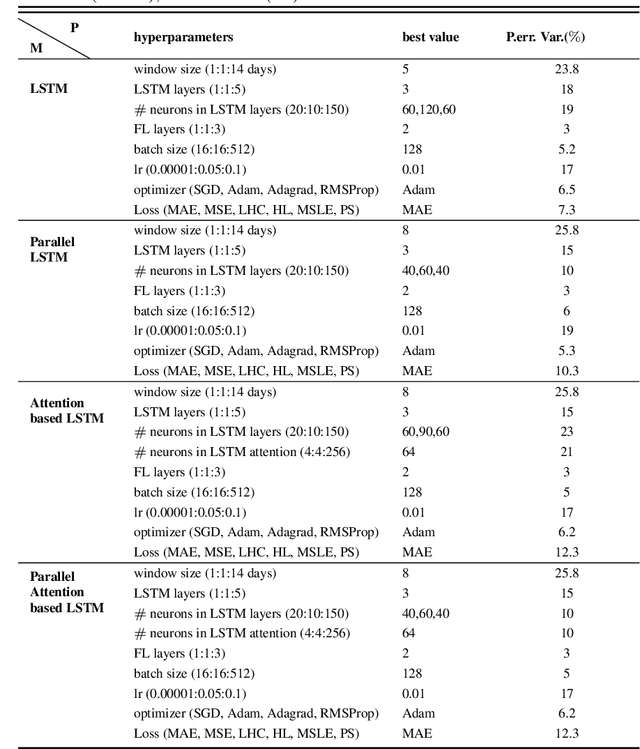
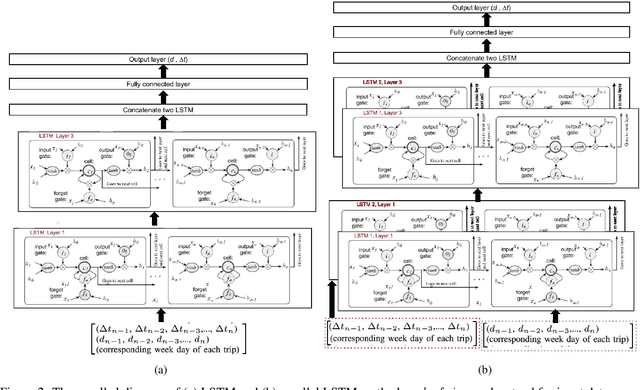
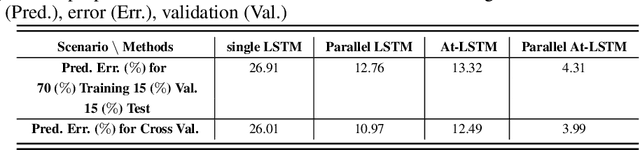
In this paper, we propose machine learning solutions to predict the time of future trips and the possible distance the vehicle will travel. For this prediction task, we develop and investigate four methods. In the first method, we use long short-term memory (LSTM)-based structures specifically designed to handle multi-dimensional historical data of trip time and distances simultaneously. Using it, we predict the future trip time and forecast the distance a vehicle will travel by concatenating the outputs of LSTM networks through fully connected layers. The second method uses attention-based LSTM networks (At-LSTM) to perform the same tasks. The third method utilizes two LSTM networks in parallel, one for forecasting the time of the trip and the other for predicting the distance. The output of each LSTM is then concatenated through fully connected layers. Finally, the last model is based on two parallel At-LSTMs, where similarly, each At-LSTM predicts time and distance separately through fully connected layers. Among the proposed methods, the most advanced one, i.e., parallel At-LSTM, predicts the next trip's distance and time with 3.99% error margin where it is 23.89% better than LSTM, the first method. We also propose TimeSHAP as an explainability method for understanding how the networks perform learning and model the sequence of information.
Feature Engineering Methods on Multivariate Time-Series Data for Financial Data Science Competitions
Apr 18, 2023
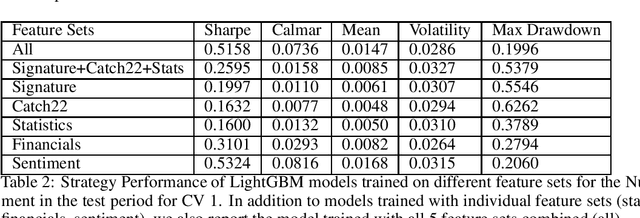
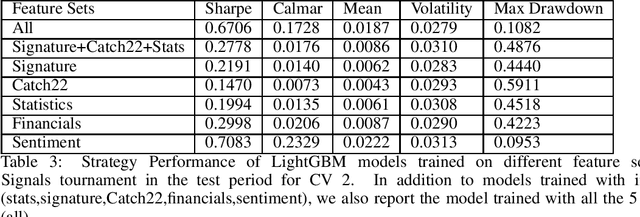
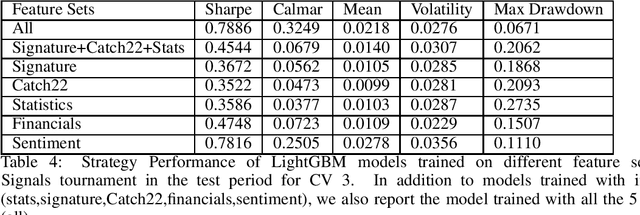
This paper is a work in progress. We are looking for collaborators to provide us financial datasets in Equity/Futures market to conduct more bench-marking studies. The authors have papers employing similar methods applied on the Numerai dataset, which is freely available but obfuscated. We apply different feature engineering methods for time-series to US market price data. The predictive power of models are tested against Numerai-Signals targets.
TTA-COPE: Test-Time Adaptation for Category-Level Object Pose Estimation
Mar 29, 2023
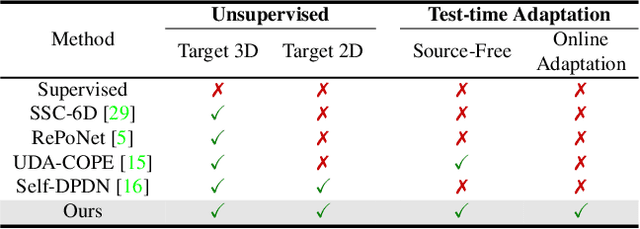
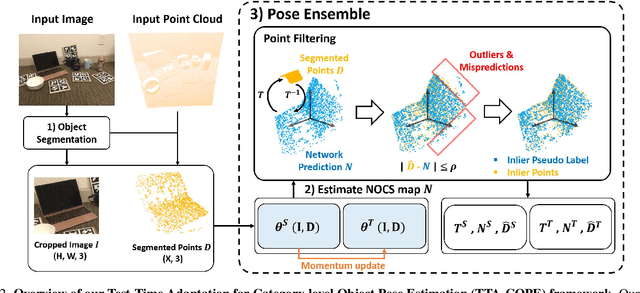
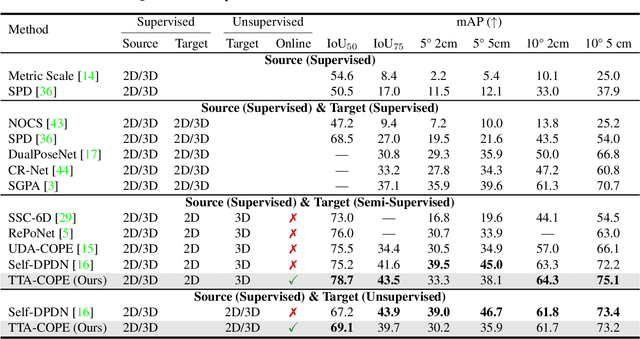
Test-time adaptation methods have been gaining attention recently as a practical solution for addressing source-to-target domain gaps by gradually updating the model without requiring labels on the target data. In this paper, we propose a method of test-time adaptation for category-level object pose estimation called TTA-COPE. We design a pose ensemble approach with a self-training loss using pose-aware confidence. Unlike previous unsupervised domain adaptation methods for category-level object pose estimation, our approach processes the test data in a sequential, online manner, and it does not require access to the source domain at runtime. Extensive experimental results demonstrate that the proposed pose ensemble and the self-training loss improve category-level object pose performance during test time under both semi-supervised and unsupervised settings. Project page: https://taeyeop.com/ttacope
Spatiotemporal Pyramidal CNN with Depth-Wise Separable Convolution for Eye Blinking Detection in the Wild
Jun 20, 2023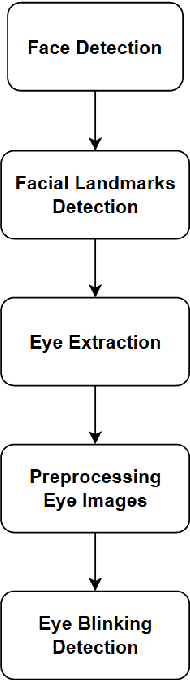
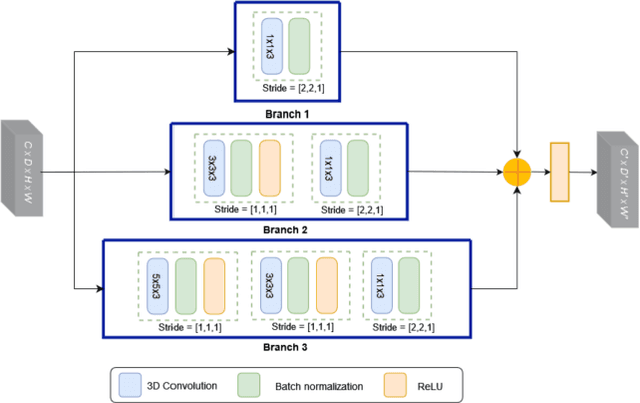
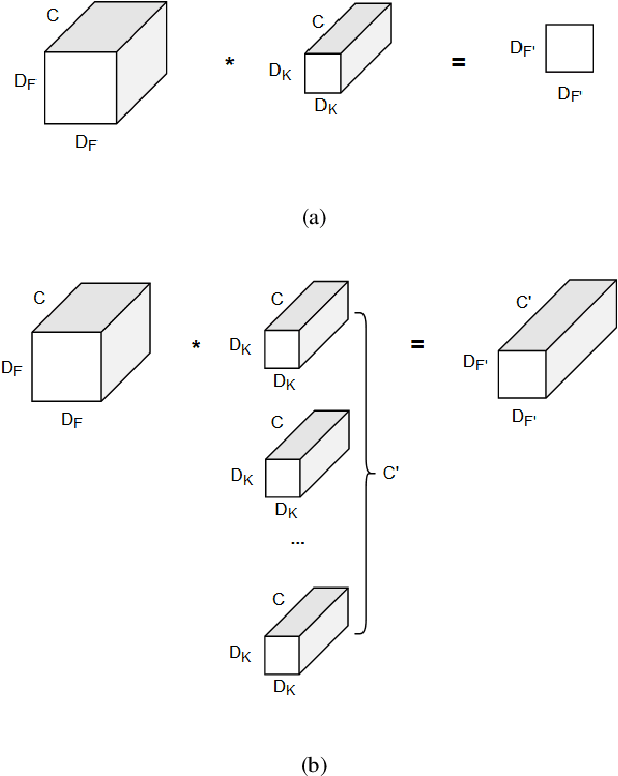
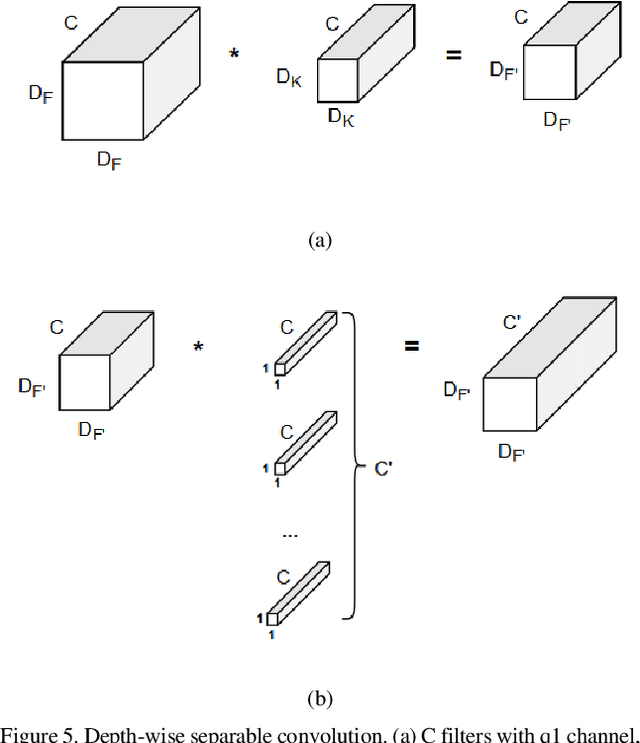
Eye blinking detection in the wild plays an essential role in deception detection, driving fatigue detection, etc. Despite the fact that numerous attempts have already been made, the majority of them have encountered difficulties, such as the derived eye images having different resolutions as the distance between the face and the camera changes; or the requirement of a lightweight detection model to obtain a short inference time in order to perform in real-time. In this research, two problems are addressed: how the eye blinking detection model can learn efficiently from different resolutions of eye pictures in diverse conditions; and how to reduce the size of the detection model for faster inference time. We propose to utilize upsampling and downsampling the input eye images to the same resolution as one potential solution for the first problem, then find out which interpolation method can result in the highest performance of the detection model. For the second problem, although a recent spatiotemporal convolutional neural network used for eye blinking detection has a strong capacity to extract both spatial and temporal characteristics, it remains having a high number of network parameters, leading to high inference time. Therefore, using Depth-wise Separable Convolution rather than conventional convolution layers inside each branch is considered in this paper as a feasible solution.
LMBot: Distilling Graph Knowledge into Language Model for Graph-less Deployment in Twitter Bot Detection
Jul 03, 2023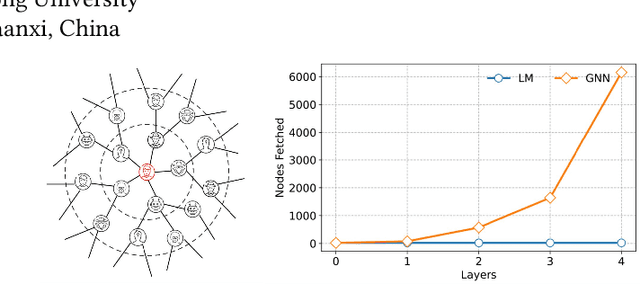
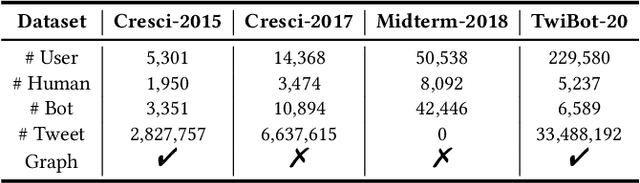
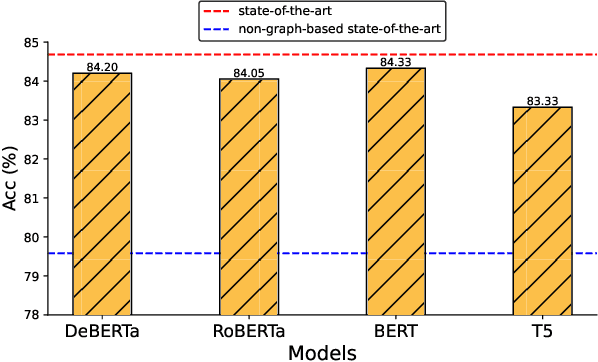
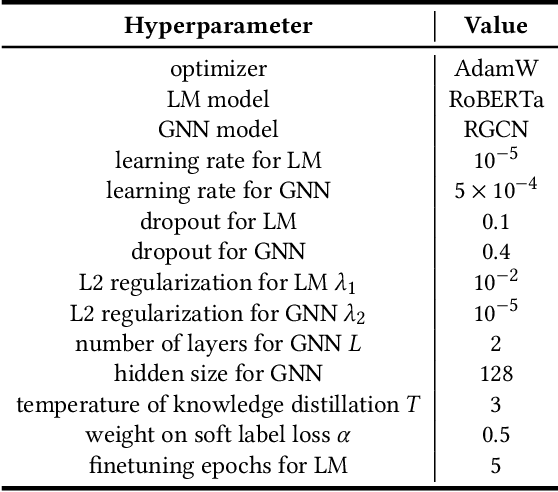
As malicious actors employ increasingly advanced and widespread bots to disseminate misinformation and manipulate public opinion, the detection of Twitter bots has become a crucial task. Though graph-based Twitter bot detection methods achieve state-of-the-art performance, we find that their inference depends on the neighbor users multi-hop away from the targets, and fetching neighbors is time-consuming and may introduce bias. At the same time, we find that after finetuning on Twitter bot detection, pretrained language models achieve competitive performance and do not require a graph structure during deployment. Inspired by this finding, we propose a novel bot detection framework LMBot that distills the knowledge of graph neural networks (GNNs) into language models (LMs) for graph-less deployment in Twitter bot detection to combat the challenge of data dependency. Moreover, LMBot is compatible with graph-based and graph-less datasets. Specifically, we first represent each user as a textual sequence and feed them into the LM for domain adaptation. For graph-based datasets, the output of LMs provides input features for the GNN, enabling it to optimize for bot detection and distill knowledge back to the LM in an iterative, mutually enhancing process. Armed with the LM, we can perform graph-less inference, which resolves the graph data dependency and sampling bias issues. For datasets without graph structure, we simply replace the GNN with an MLP, which has also shown strong performance. Our experiments demonstrate that LMBot achieves state-of-the-art performance on four Twitter bot detection benchmarks. Extensive studies also show that LMBot is more robust, versatile, and efficient compared to graph-based Twitter bot detection methods.
Adaptive Region Selection for Active Learning in Whole Slide Image Semantic Segmentation
Jul 14, 2023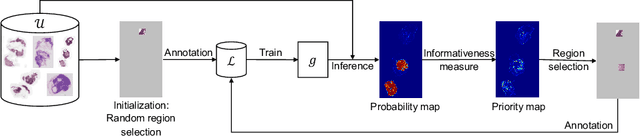
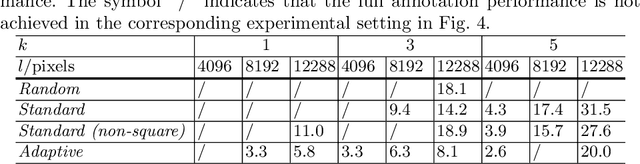
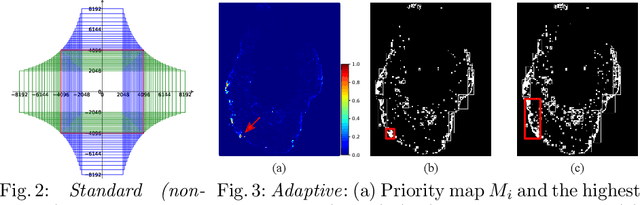
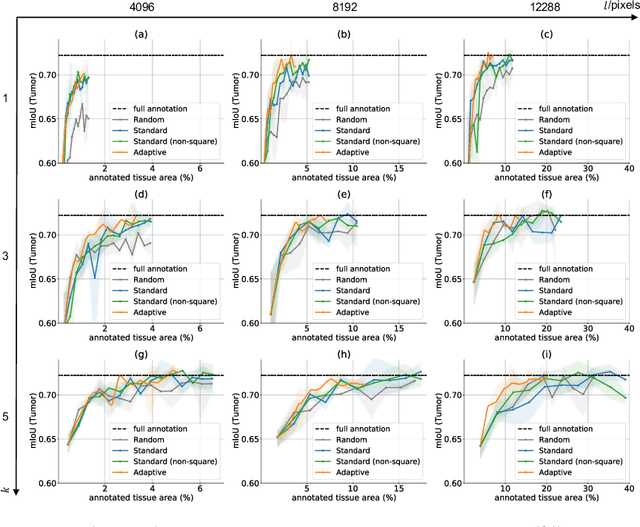
The process of annotating histological gigapixel-sized whole slide images (WSIs) at the pixel level for the purpose of training a supervised segmentation model is time-consuming. Region-based active learning (AL) involves training the model on a limited number of annotated image regions instead of requesting annotations of the entire images. These annotation regions are iteratively selected, with the goal of optimizing model performance while minimizing the annotated area. The standard method for region selection evaluates the informativeness of all square regions of a specified size and then selects a specific quantity of the most informative regions. We find that the efficiency of this method highly depends on the choice of AL step size (i.e., the combination of region size and the number of selected regions per WSI), and a suboptimal AL step size can result in redundant annotation requests or inflated computation costs. This paper introduces a novel technique for selecting annotation regions adaptively, mitigating the reliance on this AL hyperparameter. Specifically, we dynamically determine each region by first identifying an informative area and then detecting its optimal bounding box, as opposed to selecting regions of a uniform predefined shape and size as in the standard method. We evaluate our method using the task of breast cancer metastases segmentation on the public CAMELYON16 dataset and show that it consistently achieves higher sampling efficiency than the standard method across various AL step sizes. With only 2.6\% of tissue area annotated, we achieve full annotation performance and thereby substantially reduce the costs of annotating a WSI dataset. The source code is available at https://github.com/DeepMicroscopy/AdaptiveRegionSelection.
Improving Speech Translation Accuracy and Time Efficiency with Fine-tuned wav2vec 2.0-based Speech Segmentation
Apr 25, 2023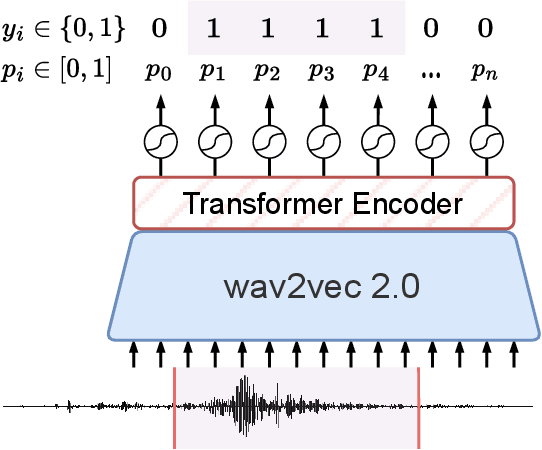
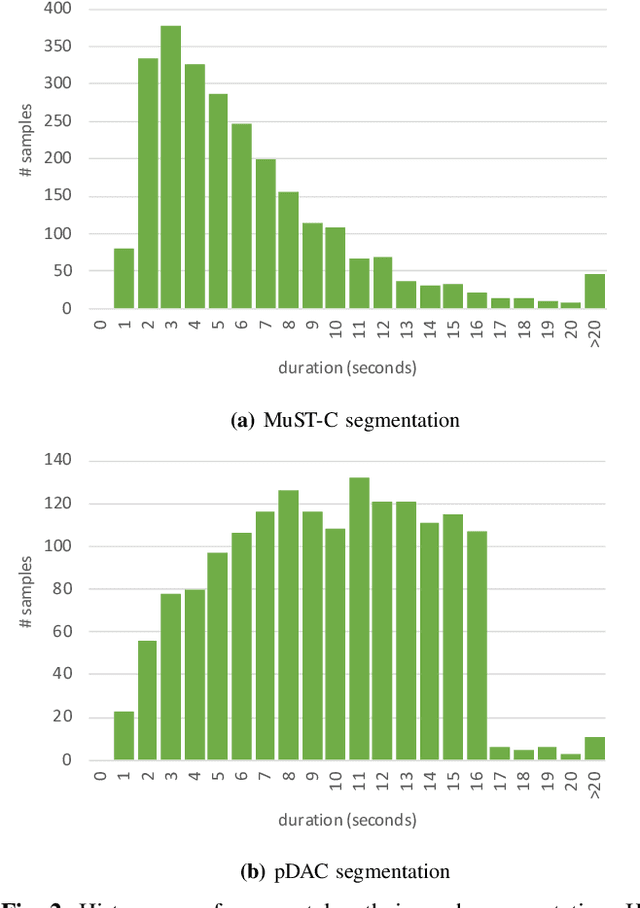
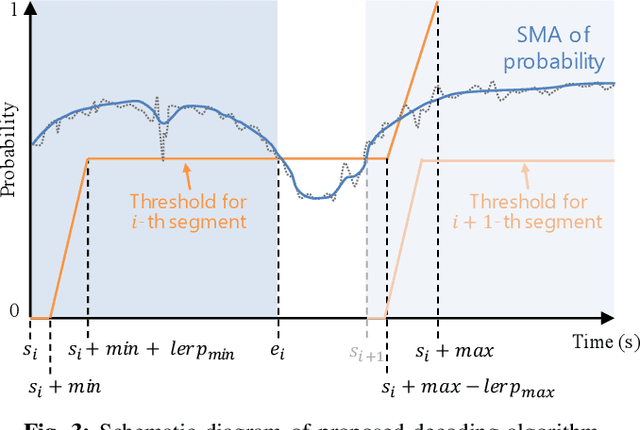
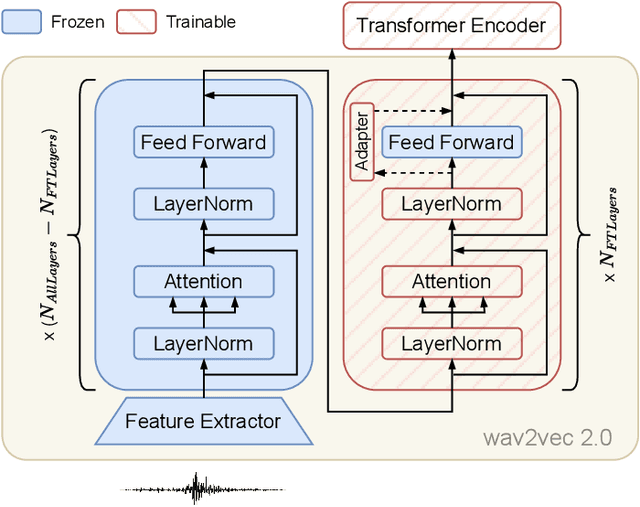
Speech translation (ST) automatically converts utterances in a source language into text in another language. Splitting continuous speech into shorter segments, known as speech segmentation, plays an important role in ST. Recent segmentation methods trained to mimic the segmentation of ST corpora have surpassed traditional approaches. Tsiamas et al. proposed a segmentation frame classifier (SFC) based on a pre-trained speech encoder called wav2vec 2.0. Their method, named SHAS, retains 95-98% of the BLEU score for ST corpus segmentation. However, the segments generated by SHAS are very different from ST corpus segmentation and tend to be longer with multiple combined utterances. This is due to SHAS's reliance on length heuristics, i.e., it splits speech into segments of easily translatable length without fully considering the potential for ST improvement by splitting them into even shorter segments. Longer segments often degrade translation quality and ST's time efficiency. In this study, we extended SHAS to improve ST translation accuracy and efficiency by splitting speech into shorter segments that correspond to sentences. We introduced a simple segmentation algorithm using the moving average of SFC predictions without relying on length heuristics and explored wav2vec 2.0 fine-tuning for improved speech segmentation prediction. Our experimental results reveal that our speech segmentation method significantly improved the quality and the time efficiency of speech translation compared to SHAS.