 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Task and Behavior: A Two-Stage Reward Curriculum in Reinforcement Learning for Robotics
Mar 05, 2026Deep Reinforcement Learning is a promising tool for robotic control, yet practical application is often hindered by the difficulty of designing effective reward functions. Real-world tasks typically require optimizing multiple objectives simultaneously, necessitating precise tuning of their weights to learn a policy with the desired characteristics. To address this, we propose a two-stage reward curriculum where we decouple task-specific objectives from behavioral terms. In our method, we first train the agent on a simplified task-only reward function to ensure effective exploration before introducing the full reward that includes auxiliary behavior-related terms such as energy efficiency. Further, we analyze various transition strategies and demonstrate that reusing samples between phases is critical for training stability. We validate our approach on the DeepMind Control Suite, ManiSkill3, and a mobile robot environment, modified to include auxiliary behavioral objectives. Our method proves to be simple yet effective, substantially outperforming baselines trained directly on the full reward while exhibiting higher robustness to specific reward weightings.
AFABench: A Generic Framework for Benchmarking Active Feature Acquisition
Aug 20, 2025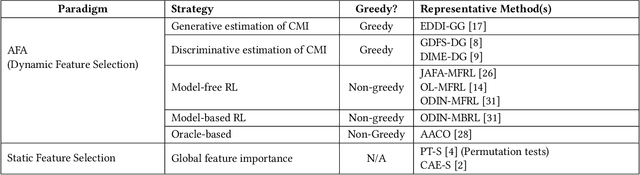
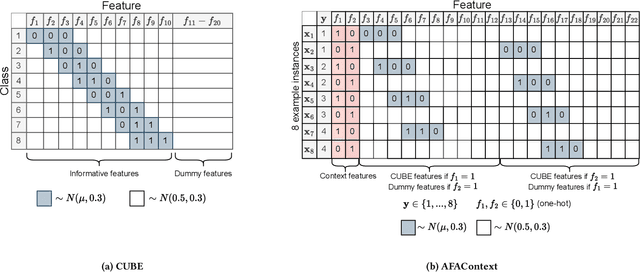
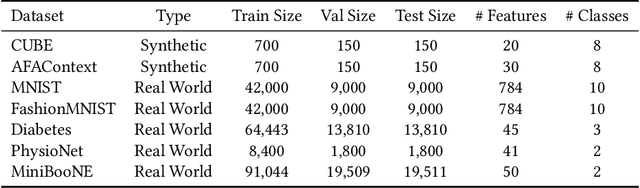
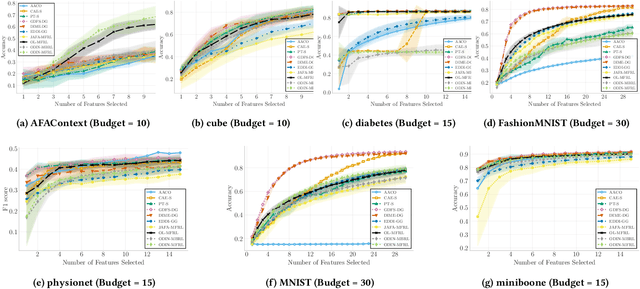
In many real-world scenarios, acquiring all features of a data instance can be expensive or impractical due to monetary cost, latency, or privacy concerns. Active Feature Acquisition (AFA) addresses this challenge by dynamically selecting a subset of informative features for each data instance, trading predictive performance against acquisition cost. While numerous methods have been proposed for AFA, ranging from greedy information-theoretic strategies to non-myopic reinforcement learning approaches, fair and systematic evaluation of these methods has been hindered by the lack of standardized benchmarks. In this paper, we introduce AFABench, the first benchmark framework for AFA. Our benchmark includes a diverse set of synthetic and real-world datasets, supports a wide range of acquisition policies, and provides a modular design that enables easy integration of new methods and tasks. We implement and evaluate representative algorithms from all major categories, including static, greedy, and reinforcement learning-based approaches. To test the lookahead capabilities of AFA policies, we introduce a novel synthetic dataset, AFAContext, designed to expose the limitations of greedy selection. Our results highlight key trade-offs between different AFA strategies and provide actionable insights for future research. The benchmark code is available at: https://github.com/Linusaronsson/AFA-Benchmark.
A Benchmark Dataset for Graph Regression with Homogeneous and Multi-Relational Variants
May 29, 2025



Graph-level regression underpins many real-world applications, yet public benchmarks remain heavily skewed toward molecular graphs and citation networks. This limited diversity hinders progress on models that must generalize across both homogeneous and heterogeneous graph structures. We introduce RelSC, a new graph-regression dataset built from program graphs that combine syntactic and semantic information extracted from source code. Each graph is labelled with the execution-time cost of the corresponding program, providing a continuous target variable that differs markedly from those found in existing benchmarks. RelSC is released in two complementary variants. RelSC-H supplies rich node features under a single (homogeneous) edge type, while RelSC-M preserves the original multi-relational structure, connecting nodes through multiple edge types that encode distinct semantic relationships. Together, these variants let researchers probe how representation choice influences model behaviour. We evaluate a diverse set of graph neural network architectures on both variants of RelSC. The results reveal consistent performance differences between the homogeneous and multi-relational settings, emphasising the importance of structural representation. These findings demonstrate RelSC's value as a challenging and versatile benchmark for advancing graph regression methods.
An Efficient Local Search Approach for Polarized Community Discovery in Signed Networks
Feb 04, 2025Signed networks, where edges are labeled as positive or negative to indicate friendly or antagonistic interactions, offer a natural framework for studying polarization, trust, and conflict in social systems. Detecting meaningful group structures in these networks is crucial for understanding online discourse, political division, and trust dynamics. A key challenge is to identify groups that are cohesive internally yet antagonistic externally, while allowing for neutral or unaligned vertices. In this paper, we address this problem by identifying $k$ polarized communities that are large, dense, and balanced in size. We develop an approach based on Frank-Wolfe optimization, leading to a local search procedure with provable convergence guarantees. Our method is both scalable and efficient, outperforming state-of-the-art baselines in solution quality while remaining competitive in terms of computational efficiency.
Efficient Prior Selection in Gaussian Process Bandits with Thompson Sampling
Feb 03, 2025



Gaussian process (GP) bandits provide a powerful framework for solving blackbox optimization of unknown functions. The characteristics of the unknown function depends heavily on the assumed GP prior. Most work in the literature assume that this prior is known but in practice this seldom holds. Instead, practitioners often rely on maximum likelihood estimation to select the hyperparameters of the prior - which lacks theoretical guarantees. In this work, we propose two algorithms for joint prior selection and regret minimization in GP bandits based on GP Thompson sampling (GP-TS): Prior-Elimination GP-TS (PE-GP-TS) and HyperPrior GP-TS (HP-GP-TS). We theoretically analyze the algorithms and establish upper bounds for their respective regret. In addition, we demonstrate the effectiveness of our algorithms compared to the alternatives through experiments with synthetic and real-world data.
Sample-Efficient Curriculum Reinforcement Learning for Complex Reward Functions
Oct 22, 2024



Reinforcement learning (RL) shows promise in control problems, but its practical application is often hindered by the complexity arising from intricate reward functions with constraints. While the reward hypothesis suggests these competing demands can be encapsulated in a single scalar reward function, designing such functions remains challenging. Building on existing work, we start by formulating preferences over trajectories to derive a realistic reward function that balances goal achievement with constraint satisfaction in the application of mobile robotics with dynamic obstacles. To mitigate reward exploitation in such complex settings, we propose a novel two-stage reward curriculum combined with a flexible replay buffer that adaptively samples experiences. Our approach first learns on a subset of rewards before transitioning to the full reward, allowing the agent to learn trade-offs between objectives and constraints. After transitioning to a new stage, our method continues to make use of past experiences by updating their rewards for sample-efficient learning. We investigate the efficacy of our approach in robot navigation tasks and demonstrate superior performance compared to baselines in terms of true reward achievement and task completion, underlining its effectiveness.
Diversity-Aware Reinforcement Learning for de novo Drug Design
Oct 14, 2024



Fine-tuning a pre-trained generative model has demonstrated good performance in generating promising drug molecules. The fine-tuning task is often formulated as a reinforcement learning problem, where previous methods efficiently learn to optimize a reward function to generate potential drug molecules. Nevertheless, in the absence of an adaptive update mechanism for the reward function, the optimization process can become stuck in local optima. The efficacy of the optimal molecule in a local optimization may not translate to usefulness in the subsequent drug optimization process or as a potential standalone clinical candidate. Therefore, it is important to generate a diverse set of promising molecules. Prior work has modified the reward function by penalizing structurally similar molecules, primarily focusing on finding molecules with higher rewards. To date, no study has comprehensively examined how different adaptive update mechanisms for the reward function influence the diversity of generated molecules. In this work, we investigate a wide range of intrinsic motivation methods and strategies to penalize the extrinsic reward, and how they affect the diversity of the set of generated molecules. Our experiments reveal that combining structure- and prediction-based methods generally yields better results in terms of molecular diversity.
A GREAT Architecture for Edge-Based Graph Problems Like TSP
Aug 29, 2024



In the last years, many neural network-based approaches have been proposed to tackle combinatorial optimization problems such as routing problems. Many of these approaches are based on graph neural networks (GNNs) or related transformers, operating on the Euclidean coordinates representing the routing problems. However, GNNs are inherently not well suited to operate on dense graphs, such as in routing problems. Furthermore, models operating on Euclidean coordinates cannot be applied to non-Euclidean versions of routing problems that are often found in real-world settings. To overcome these limitations, we propose a novel GNN-related edge-based neural model called Graph Edge Attention Network (GREAT). We evaluate the performance of GREAT in the edge-classification task to predict optimal edges in the Traveling Salesman Problem (TSP). We can use such a trained GREAT model to produce sparse TSP graph instances, keeping only the edges GREAT finds promising. Compared to other, non-learning-based methods to sparsify TSP graphs, GREAT can produce very sparse graphs while keeping most of the optimal edges. Furthermore, we build a reinforcement learning-based GREAT framework which we apply to Euclidean and non-Euclidean asymmetric TSP. This framework achieves state-of-the-art results.
Analysing the Behaviour of Tree-Based Neural Networks in Regression Tasks
Jun 17, 2024



The landscape of deep learning has vastly expanded the frontiers of source code analysis, particularly through the utilization of structural representations such as Abstract Syntax Trees (ASTs). While these methodologies have demonstrated effectiveness in classification tasks, their efficacy in regression applications, such as execution time prediction from source code, remains underexplored. This paper endeavours to decode the behaviour of tree-based neural network models in the context of such regression challenges. We extend the application of established models--tree-based Convolutional Neural Networks (CNNs), Code2Vec, and Transformer-based methods--to predict the execution time of source code by parsing it to an AST. Our comparative analysis reveals that while these models are benchmarks in code representation, they exhibit limitations when tasked with regression. To address these deficiencies, we propose a novel dual-transformer approach that operates on both source code tokens and AST representations, employing cross-attention mechanisms to enhance interpretability between the two domains. Furthermore, we explore the adaptation of Graph Neural Networks (GNNs) to this tree-based problem, theorizing the inherent compatibility due to the graphical nature of ASTs. Empirical evaluations on real-world datasets showcase that our dual-transformer model outperforms all other tree-based neural networks and the GNN-based models. Moreover, our proposed dual transformer demonstrates remarkable adaptability and robust performance across diverse datasets.
Less Is More -- On the Importance of Sparsification for Transformers and Graph Neural Networks for TSP
Mar 25, 2024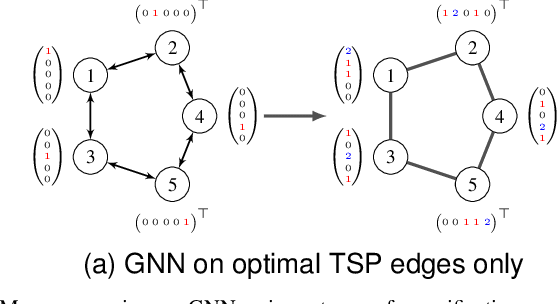
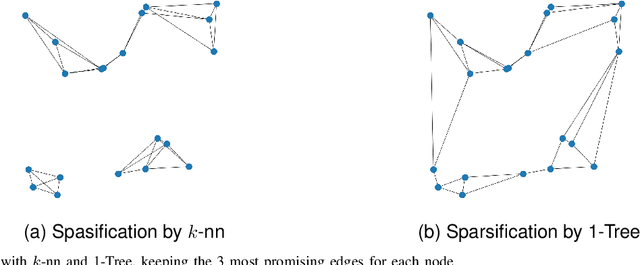


Most of the recent studies tackling routing problems like the Traveling Salesman Problem (TSP) with machine learning use a transformer or Graph Neural Network (GNN) based encoder architecture. However, many of them apply these encoders naively by allowing them to aggregate information over the whole TSP instances. We, on the other hand, propose a data preprocessing method that allows the encoders to focus on the most relevant parts of the TSP instances only. In particular, we propose graph sparsification for TSP graph representations passed to GNNs and attention masking for TSP instances passed to transformers where the masks correspond to the adjacency matrices of the sparse TSP graph representations. Furthermore, we propose ensembles of different sparsification levels allowing models to focus on the most promising parts while also allowing information flow between all nodes of a TSP instance. In the experimental studies, we show that for GNNs appropriate sparsification and ensembles of different sparsification levels lead to substantial performance increases of the overall architecture. We also design a new, state-of-the-art transformer encoder with ensembles of attention masking. These transformers increase model performance from a gap of $0.16\%$ to $0.10\%$ for TSP instances of size 100 and from $0.02\%$ to $0.00\%$ for TSP instances of size 50.