 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Equivalence of Regression and Classification
Nov 06, 2025A formal link between regression and classification has been tenuous. Even though the margin maximization term $\|w\|$ is used in support vector regression, it has at best been justified as a regularizer. We show that a regression problem with $M$ samples lying on a hyperplane has a one-to-one equivalence with a linearly separable classification task with $2M$ samples. We show that margin maximization on the equivalent classification task leads to a different regression formulation than traditionally used. Using the equivalence, we demonstrate a ``regressability'' measure, that can be used to estimate the difficulty of regressing a dataset, without needing to first learn a model for it. We use the equivalence to train neural networks to learn a linearizing map, that transforms input variables into a space where a linear regressor is adequate.
GraphFLEx: Structure Learning Framework for Large Expanding Graphs
May 18, 2025Graph structure learning is a core problem in graph-based machine learning, essential for uncovering latent relationships and ensuring model interpretability. However, most existing approaches are ill-suited for large-scale and dynamically evolving graphs, as they often require complete re-learning of the structure upon the arrival of new nodes and incur substantial computational and memory costs. In this work, we propose GraphFLEx: a unified and scalable framework for Graph Structure Learning in Large and Expanding Graphs. GraphFLEx mitigates the scalability bottlenecks by restricting edge formation to structurally relevant subsets of nodes identified through a combination of clustering and coarsening techniques. This dramatically reduces the search space and enables efficient, incremental graph updates. The framework supports 48 flexible configurations by integrating diverse choices of learning paradigms, coarsening strategies, and clustering methods, making it adaptable to a wide range of graph settings and learning objectives. Extensive experiments across 26 diverse datasets and Graph Neural Network architectures demonstrate that GraphFLEx achieves state-of-the-art performance with significantly improved scalability.
No prejudice! Fair Federated Graph Neural Networks for Personalized Recommendation
Dec 20, 2023



Ensuring fairness in Recommendation Systems (RSs) across demographic groups is critical due to the increased integration of RSs in applications such as personalized healthcare, finance, and e-commerce. Graph-based RSs play a crucial role in capturing intricate higher-order interactions among entities. However, integrating these graph models into the Federated Learning (FL) paradigm with fairness constraints poses formidable challenges as this requires access to the entire interaction graph and sensitive user information (such as gender, age, etc.) at the central server. This paper addresses the pervasive issue of inherent bias within RSs for different demographic groups without compromising the privacy of sensitive user attributes in FL environment with the graph-based model. To address the group bias, we propose F2PGNN (Fair Federated Personalized Graph Neural Network), a novel framework that leverages the power of Personalized Graph Neural Network (GNN) coupled with fairness considerations. Additionally, we use differential privacy techniques to fortify privacy protection. Experimental evaluation on three publicly available datasets showcases the efficacy of F2PGNN in mitigating group unfairness by 47% - 99% compared to the state-of-the-art while preserving privacy and maintaining the utility. The results validate the significance of our framework in achieving equitable and personalized recommendations using GNN within the FL landscape.
MaScQA: A Question Answering Dataset for Investigating Materials Science Knowledge of Large Language Models
Aug 17, 2023



Information extraction and textual comprehension from materials literature are vital for developing an exhaustive knowledge base that enables accelerated materials discovery. Language models have demonstrated their capability to answer domain-specific questions and retrieve information from knowledge bases. However, there are no benchmark datasets in the materials domain that can evaluate the understanding of the key concepts by these language models. In this work, we curate a dataset of 650 challenging questions from the materials domain that require the knowledge and skills of a materials student who has cleared their undergraduate degree. We classify these questions based on their structure and the materials science domain-based subcategories. Further, we evaluate the performance of GPT-3.5 and GPT-4 models on solving these questions via zero-shot and chain of thought prompting. It is observed that GPT-4 gives the best performance (~62% accuracy) as compared to GPT-3.5. Interestingly, in contrast to the general observation, no significant improvement in accuracy is observed with the chain of thought prompting. To evaluate the limitations, we performed an error analysis, which revealed conceptual errors (~64%) as the major contributor compared to computational errors (~36%) towards the reduced performance of LLMs. We hope that the dataset and analysis performed in this work will promote further research in developing better materials science domain-specific LLMs and strategies for information extraction.
Discovering Symbolic Laws Directly from Trajectories with Hamiltonian Graph Neural Networks
Jul 11, 2023



The time evolution of physical systems is described by differential equations, which depend on abstract quantities like energy and force. Traditionally, these quantities are derived as functionals based on observables such as positions and velocities. Discovering these governing symbolic laws is the key to comprehending the interactions in nature. Here, we present a Hamiltonian graph neural network (HGNN), a physics-enforced GNN that learns the dynamics of systems directly from their trajectory. We demonstrate the performance of HGNN on n-springs, n-pendulums, gravitational systems, and binary Lennard Jones systems; HGNN learns the dynamics in excellent agreement with the ground truth from small amounts of data. We also evaluate the ability of HGNN to generalize to larger system sizes, and to hybrid spring-pendulum system that is a combination of two original systems (spring and pendulum) on which the models are trained independently. Finally, employing symbolic regression on the learned HGNN, we infer the underlying equations relating the energy functionals, even for complex systems such as the binary Lennard-Jones liquid. Our framework facilitates the interpretable discovery of interaction laws directly from physical system trajectories. Furthermore, this approach can be extended to other systems with topology-dependent dynamics, such as cells, polydisperse gels, or deformable bodies.
Graph Neural Stochastic Differential Equations for Learning Brownian Dynamics
Jun 20, 2023



Neural networks (NNs) that exploit strong inductive biases based on physical laws and symmetries have shown remarkable success in learning the dynamics of physical systems directly from their trajectory. However, these works focus only on the systems that follow deterministic dynamics, for instance, Newtonian or Hamiltonian dynamics. Here, we propose a framework, namely Brownian graph neural networks (BROGNET), combining stochastic differential equations (SDEs) and GNNs to learn Brownian dynamics directly from the trajectory. We theoretically show that BROGNET conserves the linear momentum of the system, which in turn, provides superior performance on learning dynamics as revealed empirically. We demonstrate this approach on several systems, namely, linear spring, linear spring with binary particle types, and non-linear spring systems, all following Brownian dynamics at finite temperatures. We show that BROGNET significantly outperforms proposed baselines across all the benchmarked Brownian systems. In addition, we demonstrate zero-shot generalizability of BROGNET to simulate unseen system sizes that are two orders of magnitude larger and to different temperatures than those used during training. Altogether, our study contributes to advancing the understanding of the intricate dynamics of Brownian motion and demonstrates the effectiveness of graph neural networks in modeling such complex systems.
Cementron: Machine Learning the Constituent Phases in Cement Clinker from Optical Images
Nov 06, 2022



Cement is the most used construction material. The performance of cement hydrate depends on the constituent phases, viz. alite, belite, aluminate, and ferrites present in the cement clinker, both qualitatively and quantitatively. Traditionally, clinker phases are analyzed from optical images relying on a domain expert and simple image processing techniques. However, the non-uniformity of the images, variations in the geometry and size of the phases, and variabilities in the experimental approaches and imaging methods make it challenging to obtain the phases. Here, we present a machine learning (ML) approach to detect clinker microstructure phases automatically. To this extent, we create the first annotated dataset of cement clinker by segmenting alite and belite particles. Further, we use supervised ML methods to train models for identifying alite and belite regions. Specifically, we finetune the image detection and segmentation model Detectron-2 on the cement microstructure to develop a model for detecting the cement phases, namely, Cementron. We demonstrate that Cementron, trained only on literature data, works remarkably well on new images obtained from our experiments, demonstrating its generalizability. We make Cementron available for public use.
Predicting Oxide Glass Properties with Low Complexity Neural Network and Physical and Chemical Descriptors
Oct 19, 2022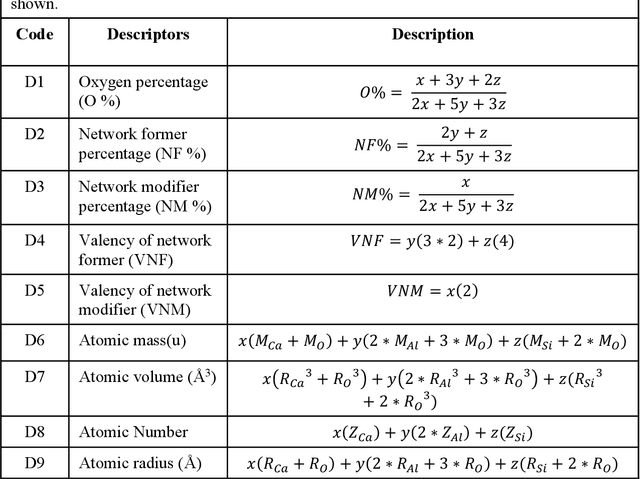
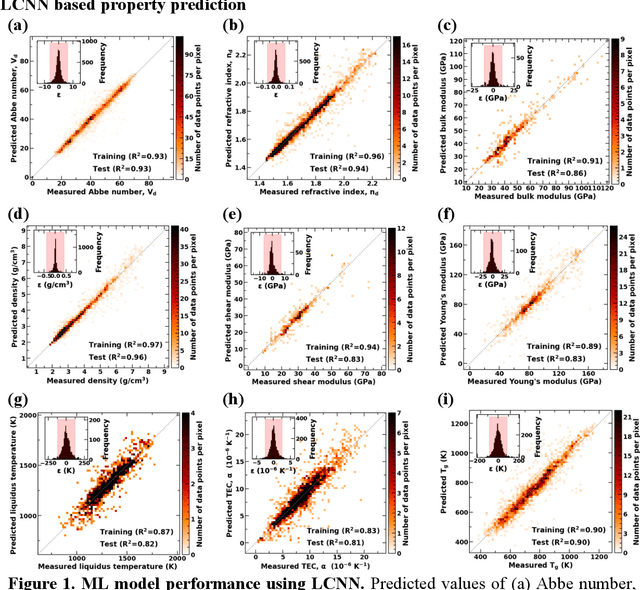
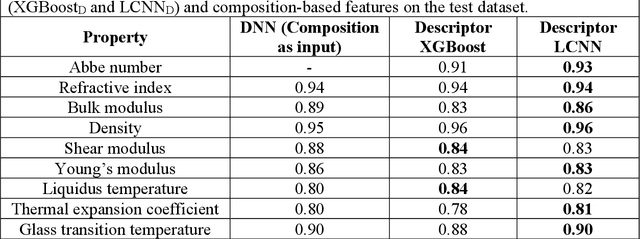
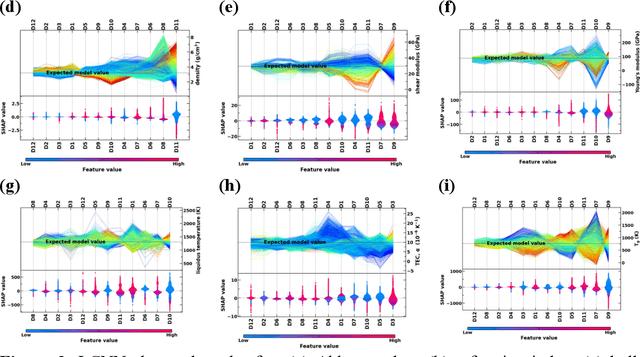
Due to their disordered structure, glasses present a unique challenge in predicting the composition-property relationships. Recently, several attempts have been made to predict the glass properties using machine learning techniques. However, these techniques have the limitations, namely, (i) predictions are limited to the components that are present in the original dataset, and (ii) predictions towards the extreme values of the properties, important regions for new materials discovery, are not very reliable due to the sparse datapoints in this region. To address these challenges, here we present a low complexity neural network (LCNN) that provides improved performance in predicting the properties of oxide glasses. In addition, we combine the LCNN with physical and chemical descriptors that allow the development of universal models that can provide predictions for components beyond the training set. By training on a large dataset (~50000) of glass components, we show the LCNN outperforms state-of-the-art algorithms such as XGBoost. In addition, we interpret the LCNN models using Shapely additive explanations to gain insights into the role played by the descriptors in governing the property. Finally, we demonstrate the universality of the LCNN models by predicting the properties for glasses with new components that were not present in the original training set. Altogether, the present approach provides a promising direction towards accelerated discovery of novel glass compositions.
A Novel Meta-predictor based Algorithm for Testing VLSI Circuits
Jul 22, 2022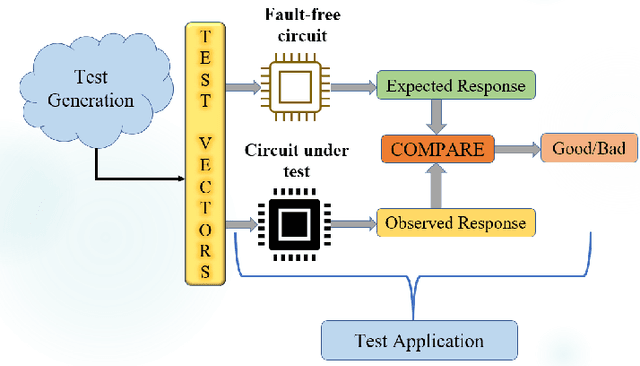
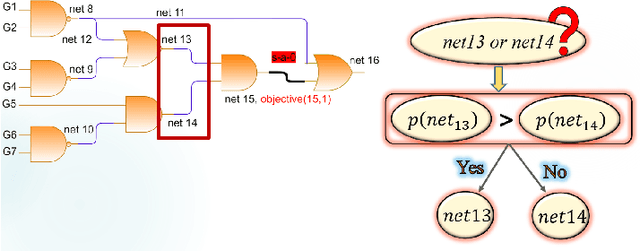
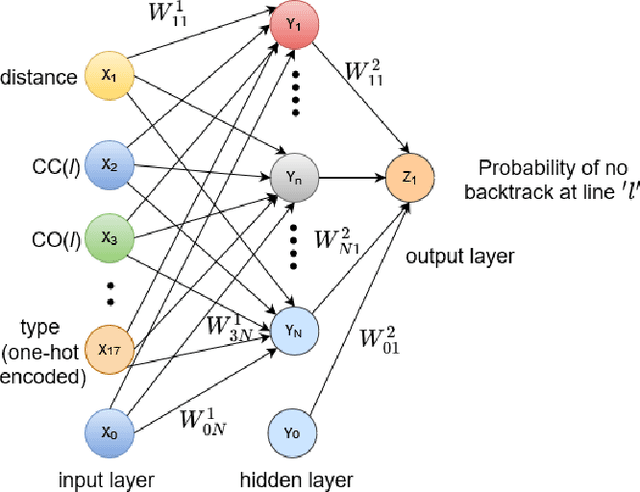
Testing of integrated circuits (IC) is a highly expensive process but also the most important one in determining the defect level of an IC. Manufacturing defects in the IC are modeled using stuck-at-fault models. Stuck-at-fault models cover most of the physical faults that occur during the manufacturing process. With decreasing feature sizes due to the advancement of semiconductor technology, the defects are also getting smaller in size. Tests for these hard-to-detect defects are generated using deterministic test generation (DTG) algorithms. Our work aims at reducing the cost of Path Oriented Decision Making: PODEM (a DTG algorithm) without compromising the test quality. We trained a meta predictor to choose the best model given the circuit and the target net. This ensemble chooses the best probability prediction model with a 95% accuracy. This leads to a reduced number of backtracking decisions and much better performance of PODEM in terms of its CPU time. We show that our ML- guided PODEM algorithm with a meta predictor outperforms the baseline PODEM by 34% and other state-of-the-art ML-guided algorithms by at least 15% for ISCAS85 benchmark circuits.
Twin Augmented Architectures for Robust Classification of COVID-19 Chest X-Ray Images
Feb 16, 2021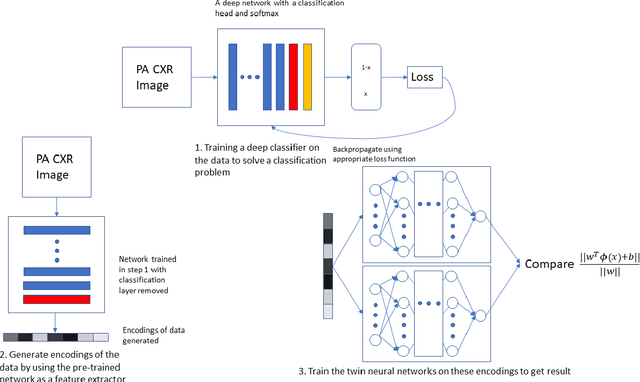
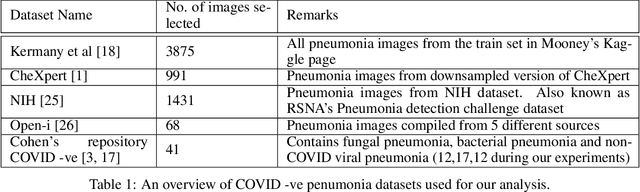
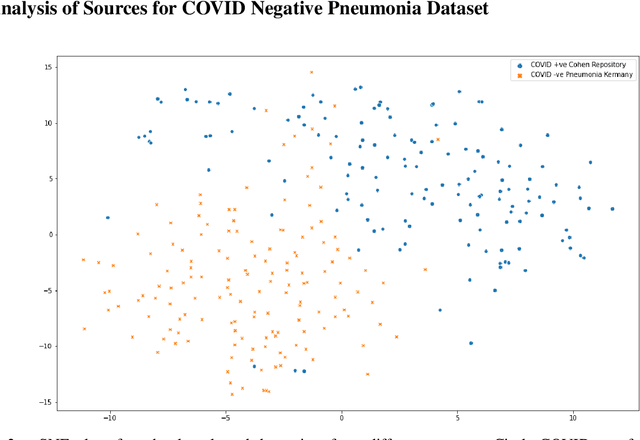
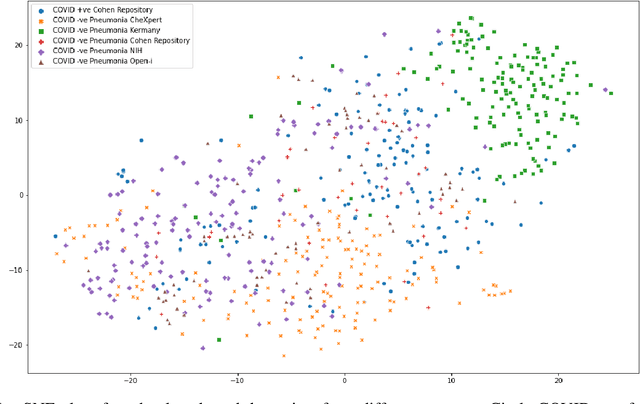
The gold standard for COVID-19 is RT-PCR, testing facilities for which are limited and not always optimally distributed. Test results are delayed, which impacts treatment. Expert radiologists, one of whom is a co-author, are able to diagnose COVID-19 positivity from Chest X-Rays (CXR) and CT scans, that can facilitate timely treatment. Such diagnosis is particularly valuable in locations lacking radiologists with sufficient expertise and familiarity with COVID-19 patients. This paper has two contributions. One, we analyse literature on CXR based COVID-19 diagnosis. We show that popular choices of dataset selection suffer from data homogeneity, leading to misleading results. We compile and analyse a viable benchmark dataset from multiple existing heterogeneous sources. Such a benchmark is important for realistically testing models. Our second contribution relates to learning from imbalanced data. Datasets for COVID X-Ray classification face severe class imbalance, since most subjects are COVID -ve. Twin Support Vector Machines (Twin SVM) and Twin Neural Networks (Twin NN) have, in recent years, emerged as effective ways of handling skewed data. We introduce a state-of-the-art technique, termed as Twin Augmentation, for modifying popular pre-trained deep learning models. Twin Augmentation boosts the performance of a pre-trained deep neural network without requiring re-training. Experiments show, that across a multitude of classifiers, Twin Augmentation is very effective in boosting the performance of given pre-trained model for classification in imbalanced settings.