 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttenuation-Aware Weighted Optical Flow with Medium Transmission Map for Learning-based Visual Odometry in Underwater terrain
Jul 18, 2024



This paper addresses the challenge of improving learning-based monocular visual odometry (VO) in underwater environments by integrating principles of underwater optical imaging to manipulate optical flow estimation. Leveraging the inherent properties of underwater imaging, the novel wflow-TartanVO is introduced, enhancing the accuracy of VO systems for autonomous underwater vehicles (AUVs). The proposed method utilizes a normalized medium transmission map as a weight map to adjust the estimated optical flow for emphasizing regions with lower degradation and suppressing uncertain regions affected by underwater light scattering and absorption. wflow-TartanVO does not require fine-tuning of pre-trained VO models, thus promoting its adaptability to different environments and camera models. Evaluation of different real-world underwater datasets demonstrates the outperformance of wflow-TartanVO over baseline VO methods, as evidenced by the considerably reduced Absolute Trajectory Error (ATE). The implementation code is available at: https://github.com/bachzz/wflow-TartanVO
Spatiotemporal Pyramidal CNN with Depth-Wise Separable Convolution for Eye Blinking Detection in the Wild
Jun 20, 2023



Eye blinking detection in the wild plays an essential role in deception detection, driving fatigue detection, etc. Despite the fact that numerous attempts have already been made, the majority of them have encountered difficulties, such as the derived eye images having different resolutions as the distance between the face and the camera changes; or the requirement of a lightweight detection model to obtain a short inference time in order to perform in real-time. In this research, two problems are addressed: how the eye blinking detection model can learn efficiently from different resolutions of eye pictures in diverse conditions; and how to reduce the size of the detection model for faster inference time. We propose to utilize upsampling and downsampling the input eye images to the same resolution as one potential solution for the first problem, then find out which interpolation method can result in the highest performance of the detection model. For the second problem, although a recent spatiotemporal convolutional neural network used for eye blinking detection has a strong capacity to extract both spatial and temporal characteristics, it remains having a high number of network parameters, leading to high inference time. Therefore, using Depth-wise Separable Convolution rather than conventional convolution layers inside each branch is considered in this paper as a feasible solution.
Novel projection schemes for graph-based Light Field coding
Jun 09, 2022
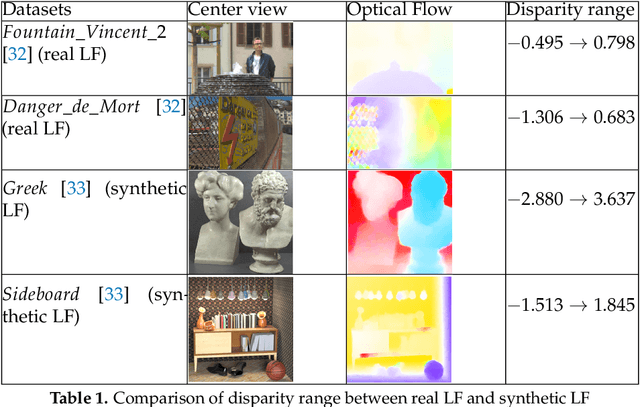


In Light Field compression, graph-based coding is powerful to exploit signal redundancy along irregular shapes and obtains good energy compaction. However, apart from high time complexity to process high dimensional graphs, their graph construction method is highly sensitive to the accuracy of disparity information between viewpoints. In real world Light Field or synthetic Light Field generated by computer software, the use of disparity information for super-rays projection might suffer from inaccuracy due to vignetting effect and large disparity between views in the two types of Light Fields respectively. This paper introduces two novel projection schemes resulting in less error in disparity information, in which one projection scheme can also significantly reduce time computation for both encoder and decoder. Experimental results show projection quality of super-pixels across views can be considerably enhanced using the proposals, along with rate-distortion performance when compared against original projection scheme and HEVC-based or JPEG Pleno-based coding approaches.