 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Transmitter Side Beyond-Diagonal Reconfigurable Intelligent Surface for Massive MIMO Networks
Jul 19, 2023
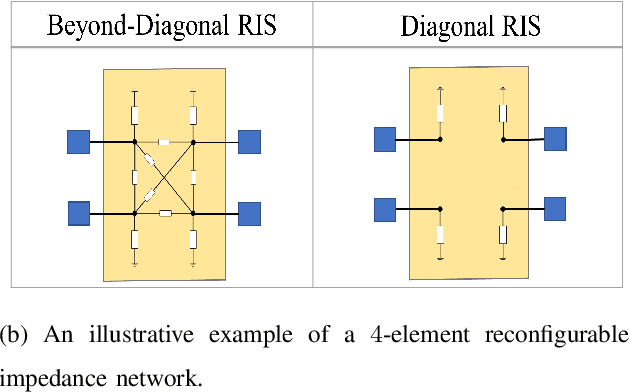
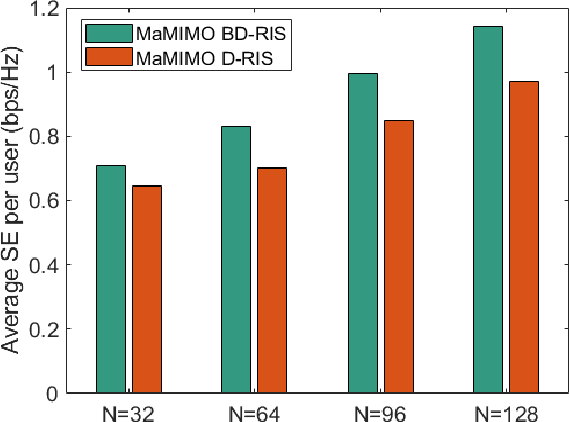
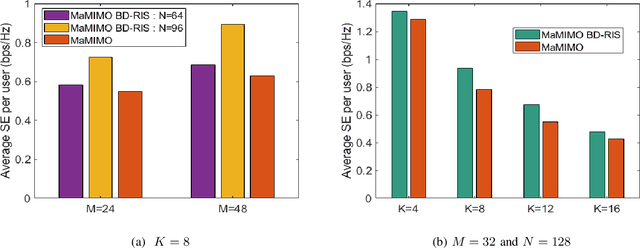

This letter focuses on a transmitter or base station (BS) side beyond-diagonal reflecting intelligent surface (BD-RIS) deployment strategy to enhance the spectral efficiency (SE) of a time-division-duplex massive multiple-input multiple-output (MaMIMO) network. In this strategy, the active antenna array utilizes a BD-RIS at the BS to serve multiple users in the downlink. Based on the knowledge of statistical channel state information (CSI), the BD-RIS coefficients matrix is optimized by employing a novel manifold algorithm, and the power control coefficients are then optimized with the objective of maximizing the minimum SE. Through numerical results we illustrate the SE performance of the proposed transmission framework and compare it with that of a conventional MaMIMO transmission for different network settings.
DIGEST: Fast and Communication Efficient Decentralized Learning with Local Updates
Jul 14, 2023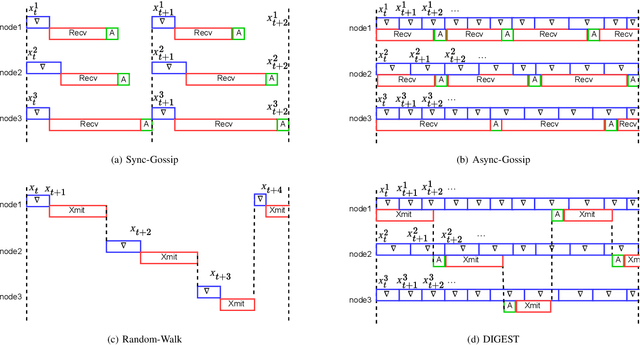


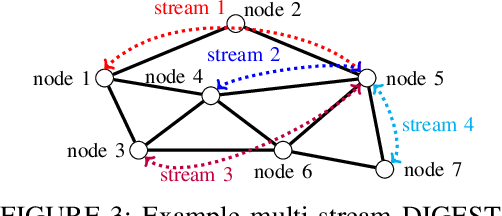
Two widely considered decentralized learning algorithms are Gossip and random walk-based learning. Gossip algorithms (both synchronous and asynchronous versions) suffer from high communication cost, while random-walk based learning experiences increased convergence time. In this paper, we design a fast and communication-efficient asynchronous decentralized learning mechanism DIGEST by taking advantage of both Gossip and random-walk ideas, and focusing on stochastic gradient descent (SGD). DIGEST is an asynchronous decentralized algorithm building on local-SGD algorithms, which are originally designed for communication efficient centralized learning. We design both single-stream and multi-stream DIGEST, where the communication overhead may increase when the number of streams increases, and there is a convergence and communication overhead trade-off which can be leveraged. We analyze the convergence of single- and multi-stream DIGEST, and prove that both algorithms approach to the optimal solution asymptotically for both iid and non-iid data distributions. We evaluate the performance of single- and multi-stream DIGEST for logistic regression and a deep neural network ResNet20. The simulation results confirm that multi-stream DIGEST has nice convergence properties; i.e., its convergence time is better than or comparable to the baselines in iid setting, and outperforms the baselines in non-iid setting.
CoTracker: It is Better to Track Together
Jul 14, 2023
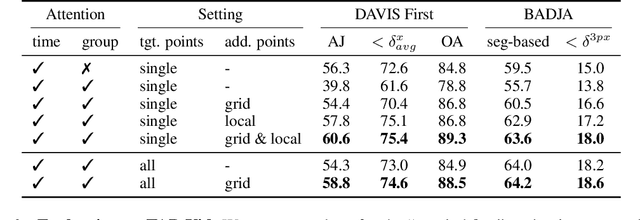
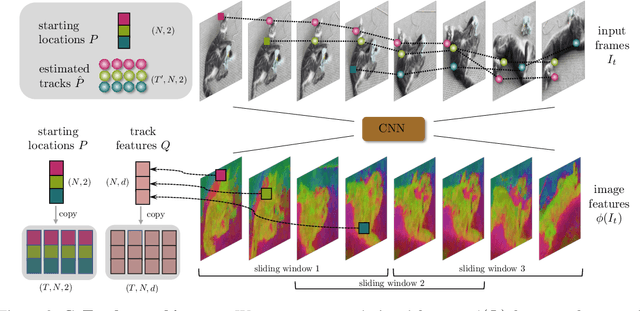
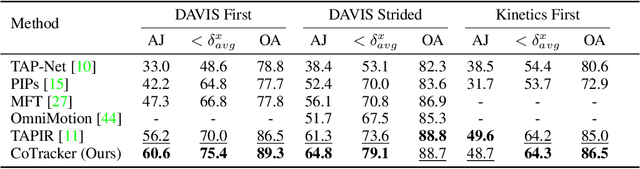
Methods for video motion prediction either estimate jointly the instantaneous motion of all points in a given video frame using optical flow or independently track the motion of individual points throughout the video. The latter is true even for powerful deep-learning methods that can track points through occlusions. Tracking points individually ignores the strong correlation that can exist between the points, for instance, because they belong to the same physical object, potentially harming performance. In this paper, we thus propose CoTracker, an architecture that jointly tracks multiple points throughout an entire video. This architecture combines several ideas from the optical flow and tracking literature in a new, flexible and powerful design. It is based on a transformer network that models the correlation of different points in time via specialised attention layers. The transformer iteratively updates an estimate of several trajectories. It can be applied in a sliding-window manner to very long videos, for which we engineer an unrolled training loop. It can track from one to several points jointly and supports adding new points to track at any time. The result is a flexible and powerful tracking algorithm that outperforms state-of-the-art methods in almost all benchmarks.
Train/Test-Time Adaptation with Retrieval
Mar 25, 2023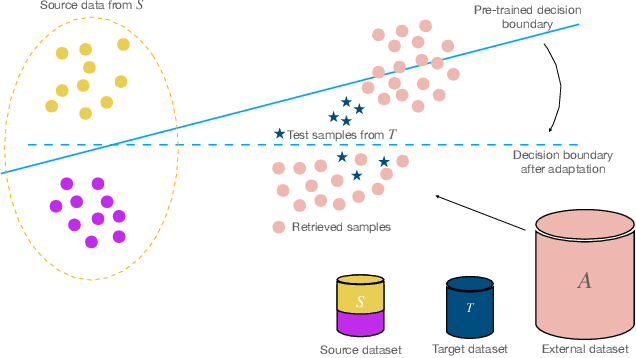
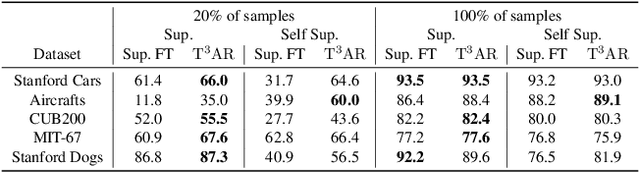
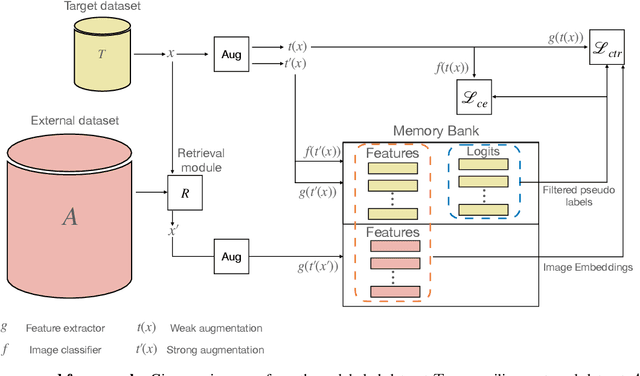
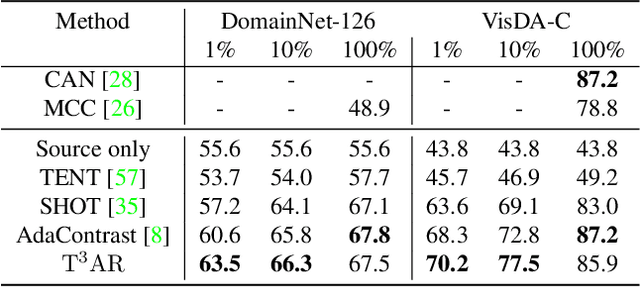
We introduce Train/Test-Time Adaptation with Retrieval (${\rm T^3AR}$), a method to adapt models both at train and test time by means of a retrieval module and a searchable pool of external samples. Before inference, ${\rm T^3AR}$ adapts a given model to the downstream task using refined pseudo-labels and a self-supervised contrastive objective function whose noise distribution leverages retrieved real samples to improve feature adaptation on the target data manifold. The retrieval of real images is key to ${\rm T^3AR}$ since it does not rely solely on synthetic data augmentations to compensate for the lack of adaptation data, as typically done by other adaptation algorithms. Furthermore, thanks to the retrieval module, our method gives the user or service provider the possibility to improve model adaptation on the downstream task by incorporating further relevant data or to fully remove samples that may no longer be available due to changes in user preference after deployment. First, we show that ${\rm T^3AR}$ can be used at training time to improve downstream fine-grained classification over standard fine-tuning baselines, and the fewer the adaptation data the higher the relative improvement (up to 13%). Second, we apply ${\rm T^3AR}$ for test-time adaptation and show that exploiting a pool of external images at test-time leads to more robust representations over existing methods on DomainNet-126 and VISDA-C, especially when few adaptation data are available (up to 8%).
FF-LINS: A Consistent Frame-to-Frame Solid-State-LiDAR-Inertial State Estimator
Jul 13, 2023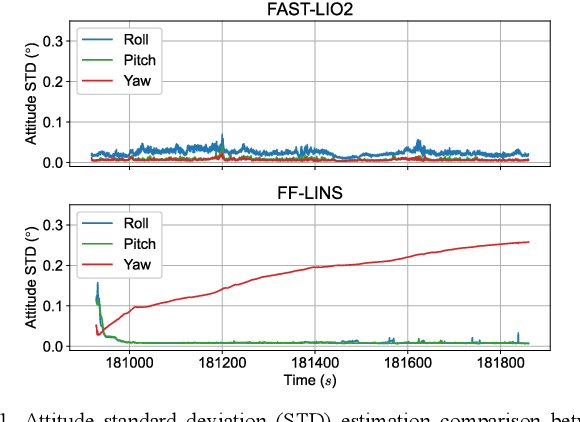
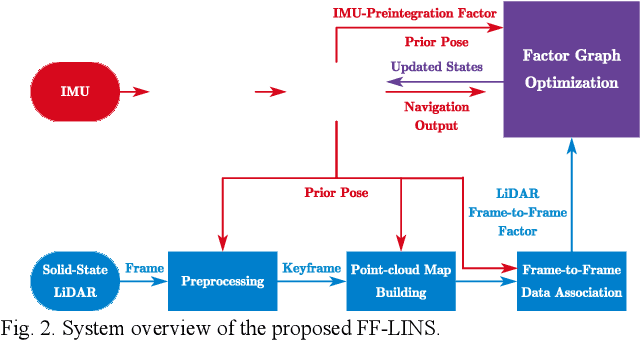
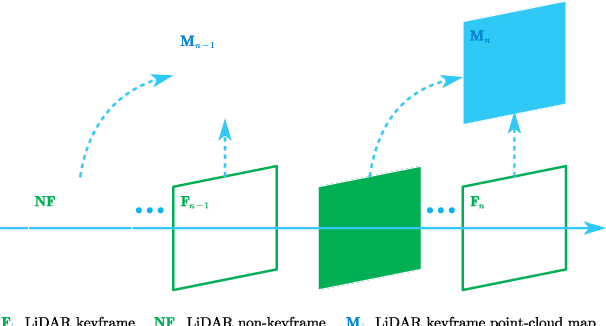
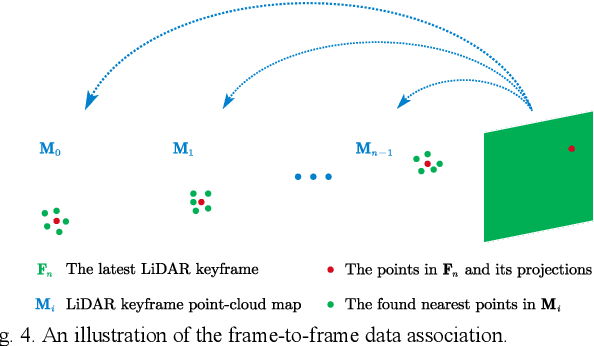
Most of the existing LiDAR-inertial navigation systems are based on frame-to-map registrations, leading to inconsistency in state estimation. The newest solid-state LiDAR with a non-repetitive scanning pattern makes it possible to achieve a consistent LiDAR-inertial estimator by employing a frame-to-frame data association. In this letter, we propose a robust and consistent frame-to-frame LiDAR-inertial navigation system (FF-LINS) for solid-state LiDARs. With the INS-centric LiDAR frame processing, the keyframe point-cloud map is built using the accumulated point clouds to construct the frame-to-frame data association. The LiDAR frame-to-frame and the inertial measurement unit (IMU) preintegration measurements are tightly integrated using the factor graph optimization, with online calibration of the LiDAR-IMU extrinsic and time-delay parameters. The experiments on the public and private datasets demonstrate that the proposed FF-LINS achieves superior accuracy and robustness than the state-of-the-art systems. Besides, the LiDAR-IMU extrinsic and time-delay parameters are estimated effectively, and the online calibration notably improves the pose accuracy. The proposed FF-LINS and the employed datasets are open-sourced on GitHub (https://github.com/i2Nav-WHU/FF-LINS).
HyperDreamBooth: HyperNetworks for Fast Personalization of Text-to-Image Models
Jul 13, 2023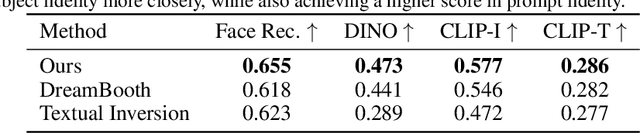
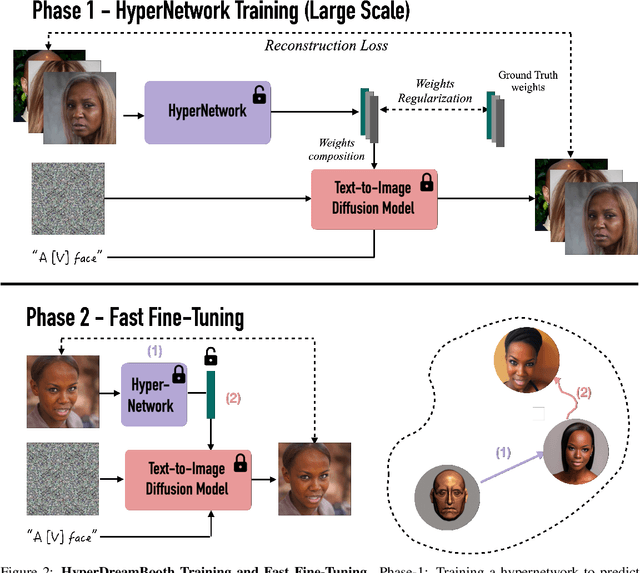
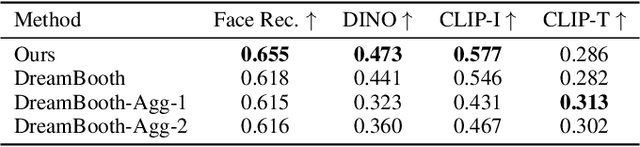
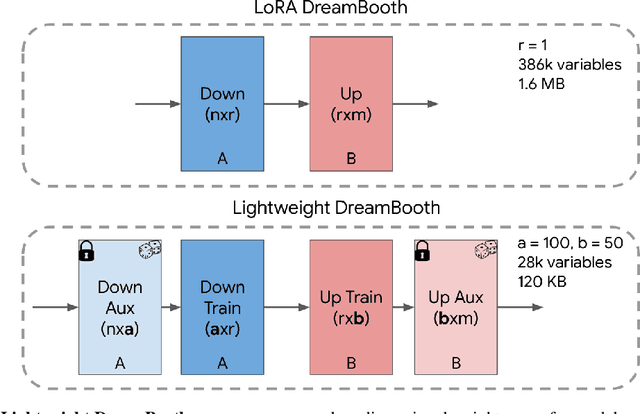
Personalization has emerged as a prominent aspect within the field of generative AI, enabling the synthesis of individuals in diverse contexts and styles, while retaining high-fidelity to their identities. However, the process of personalization presents inherent challenges in terms of time and memory requirements. Fine-tuning each personalized model needs considerable GPU time investment, and storing a personalized model per subject can be demanding in terms of storage capacity. To overcome these challenges, we propose HyperDreamBooth-a hypernetwork capable of efficiently generating a small set of personalized weights from a single image of a person. By composing these weights into the diffusion model, coupled with fast finetuning, HyperDreamBooth can generate a person's face in various contexts and styles, with high subject details while also preserving the model's crucial knowledge of diverse styles and semantic modifications. Our method achieves personalization on faces in roughly 20 seconds, 25x faster than DreamBooth and 125x faster than Textual Inversion, using as few as one reference image, with the same quality and style diversity as DreamBooth. Also our method yields a model that is 10000x smaller than a normal DreamBooth model. Project page: https://hyperdreambooth.github.io
An Evidential Real-Time Multi-Mode Fault Diagnosis Approach Based on Broad Learning System
Apr 29, 2023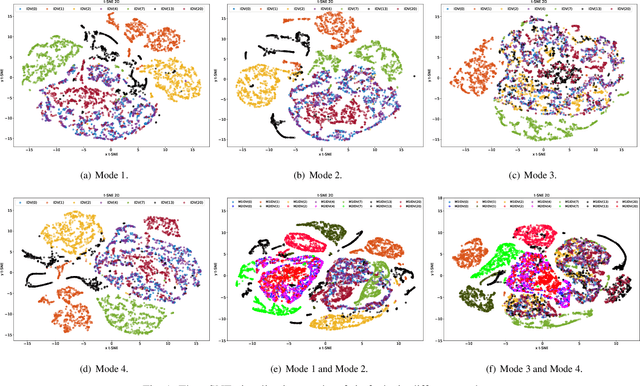
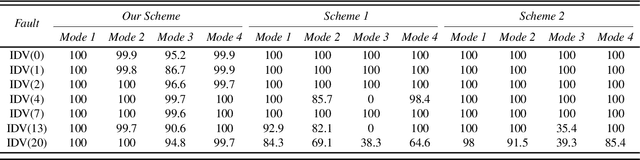
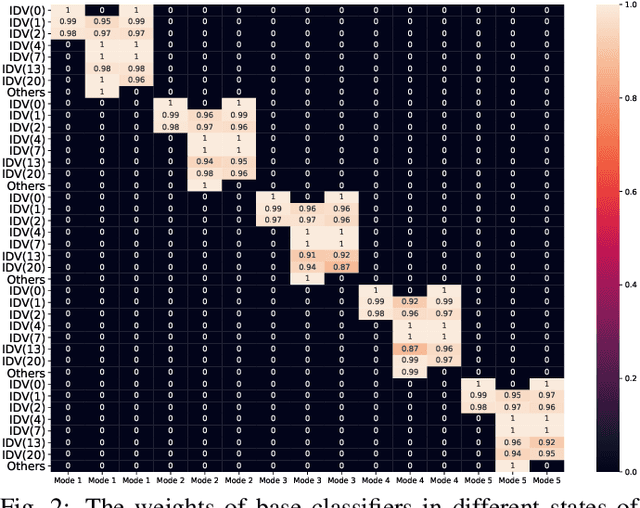
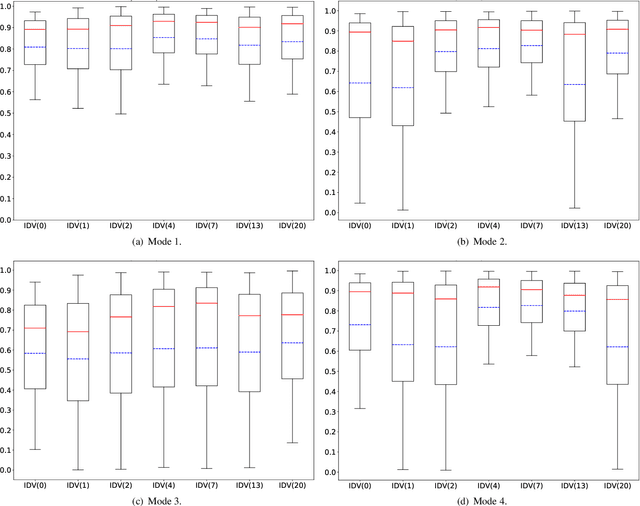
Fault diagnosis is a crucial area of research in the industry due to diverse operating conditions that exhibit non-Gaussian, multi-mode, and center-drift characteristics. Currently, data-driven approaches are the main focus in the field, but they pose challenges for continuous fault classification and parameter updates of fault classifiers, particularly in multiple operating modes and real-time settings. Therefore, a pressing issue is to achieve real-time multi-mode fault diagnosis for industrial systems. To address this problem, this paper proposes a novel approach that utilizes an evidence reasoning (ER) algorithm to fuse information and merge outputs from different base classifiers. These base classifiers are developed using a broad learning system (BLS) to improve good fault diagnosis performance. Moreover, in this approach, the pseudo-label learning method is employed to update model parameters in real-time. To demonstrate the effectiveness of the proposed approach, we perform experiments using the multi-mode Tennessee Eastman process dataset.
Building RadiologyNET: Unsupervised annotation of a large-scale multimodal medical database
Jul 27, 2023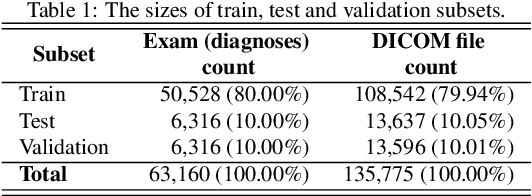
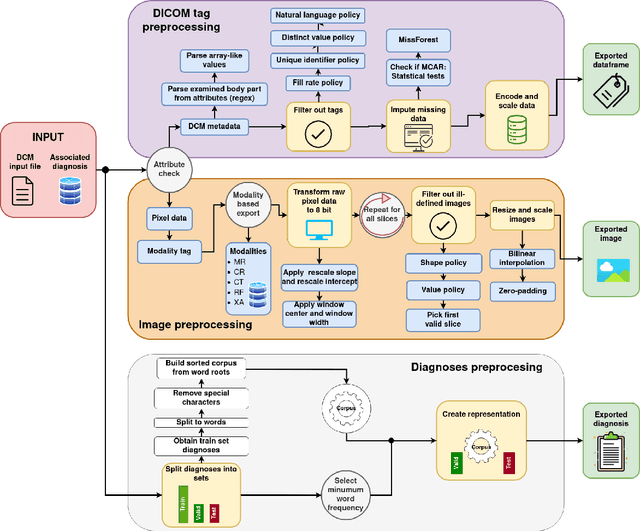
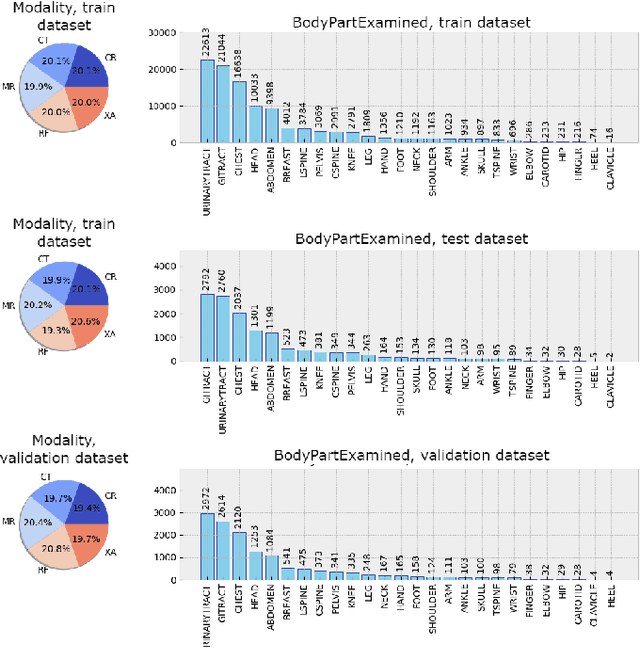
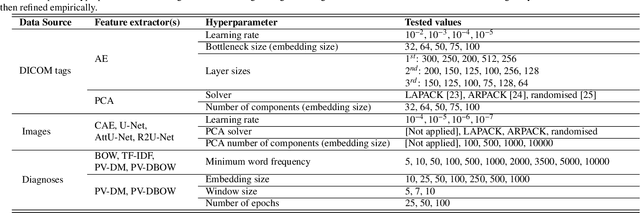
Background and objective: The usage of machine learning in medical diagnosis and treatment has witnessed significant growth in recent years through the development of computer-aided diagnosis systems that are often relying on annotated medical radiology images. However, the availability of large annotated image datasets remains a major obstacle since the process of annotation is time-consuming and costly. This paper explores how to automatically annotate a database of medical radiology images with regard to their semantic similarity. Material and methods: An automated, unsupervised approach is used to construct a large annotated dataset of medical radiology images originating from Clinical Hospital Centre Rijeka, Croatia, utilising multimodal sources, including images, DICOM metadata, and narrative diagnoses. Several appropriate feature extractors are tested for each of the data sources, and their utility is evaluated using k-means and k-medoids clustering on a representative data subset. Results: The optimal feature extractors are then integrated into a multimodal representation, which is then clustered to create an automated pipeline for labelling a precursor dataset of 1,337,926 medical images into 50 clusters of visually similar images. The quality of the clusters is assessed by examining their homogeneity and mutual information, taking into account the anatomical region and modality representation. Conclusion: The results suggest that fusing the embeddings of all three data sources together works best for the task of unsupervised clustering of large-scale medical data, resulting in the most concise clusters. Hence, this work is the first step towards building a much larger and more fine-grained annotated dataset of medical radiology images.
Distributed 3D-Beam Reforming for Hovering-Tolerant UAVs Communication over Coexistence: A Deep-Q Learning for Intelligent Space-Air-Ground Integrated Networks
Jul 18, 2023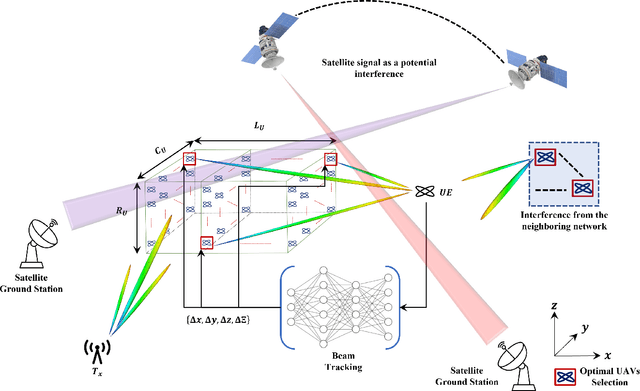
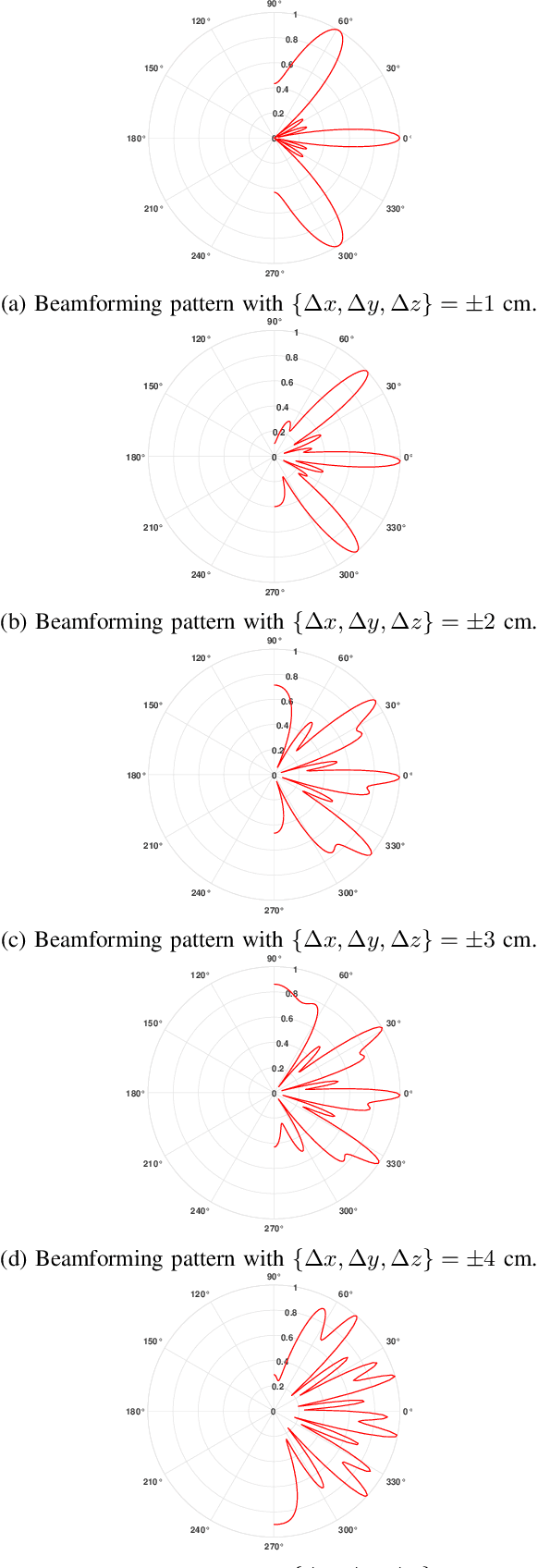
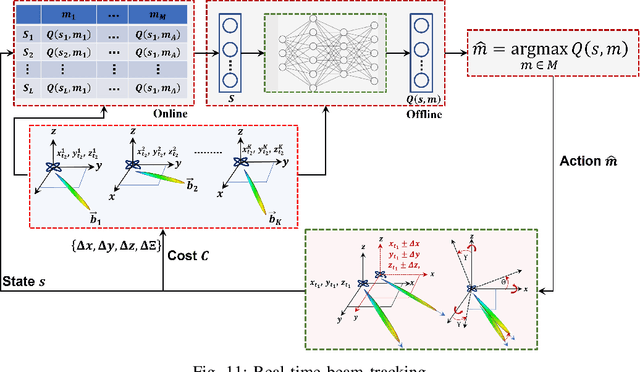
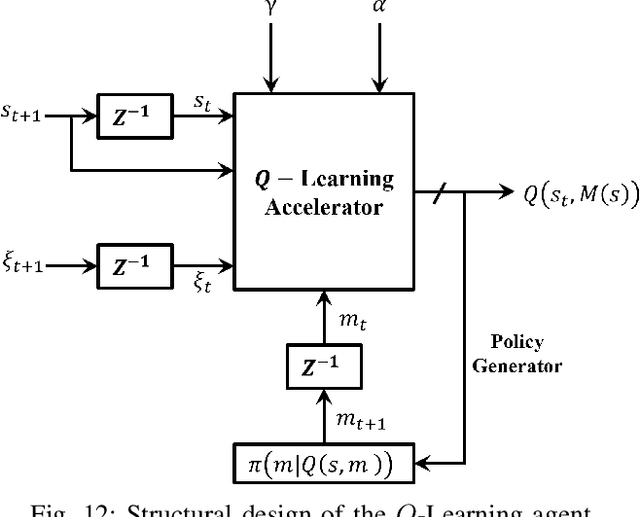
In this paper, we present a novel distributed UAVs beam reforming approach to dynamically form and reform a space-selective beam path in addressing the coexistence with satellite and terrestrial communications. Despite the unique advantage to support wider coverage in UAV-enabled cellular communications, the challenges reside in the array responses' sensitivity to random rotational motion and the hovering nature of the UAVs. A model-free reinforcement learning (RL) based unified UAV beam selection and tracking approach is presented to effectively realize the dynamic distributed and collaborative beamforming. The combined impact of the UAVs' hovering and rotational motions is considered while addressing the impairment due to the interference from the orbiting satellites and neighboring networks. The main objectives of this work are two-fold: first, to acquire the channel awareness to uncover its impairments; second, to overcome the beam distortion to meet the quality of service (QoS) requirements. To overcome the impact of the interference and to maximize the beamforming gain, we define and apply a new optimal UAV selection algorithm based on the brute force criteria. Results demonstrate that the detrimental effects of the channel fading and the interference from the orbiting satellites and neighboring networks can be overcome using the proposed approach. Subsequently, an RL algorithm based on Deep Q-Network (DQN) is developed for real-time beam tracking. By augmenting the system with the impairments due to hovering and rotational motion, we show that the proposed DQN algorithm can reform the beam in real-time with negligible error. It is demonstrated that the proposed DQN algorithm attains an exceptional performance improvement. We show that it requires a few iterations only for fine-tuning its parameters without observing any plateaus irrespective of the hovering tolerance.
Identifying Stochasticity in Time-Series with Autoencoder-Based Content-aware 2D Representation: Application to Black Hole Data
Apr 23, 2023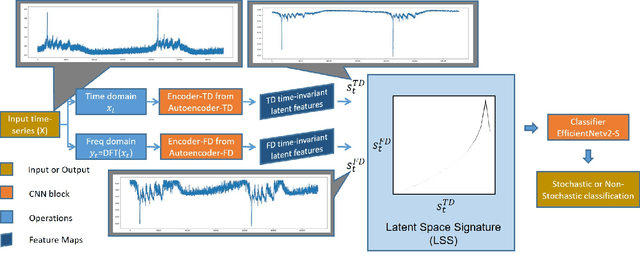
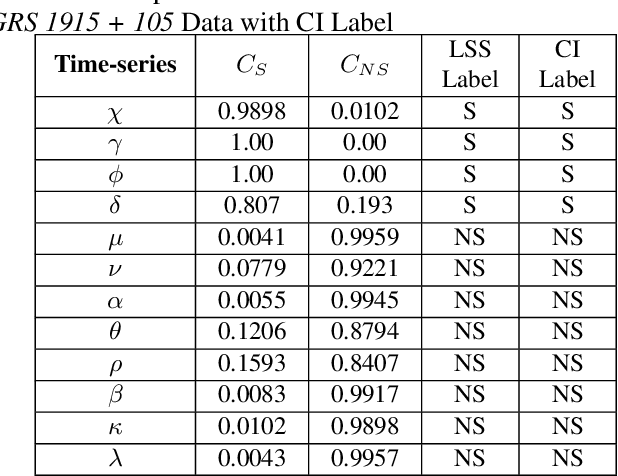
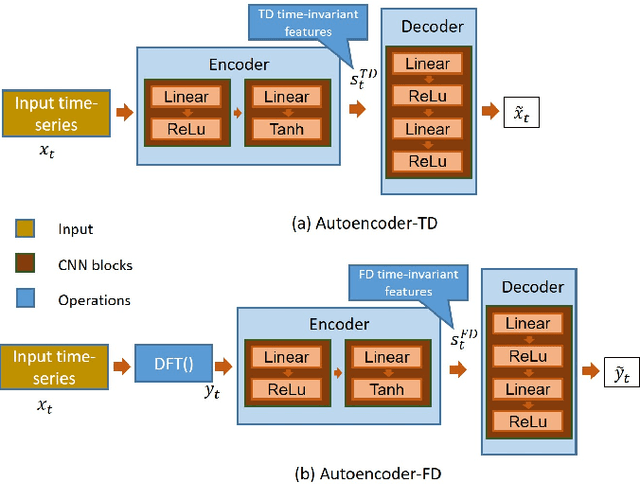
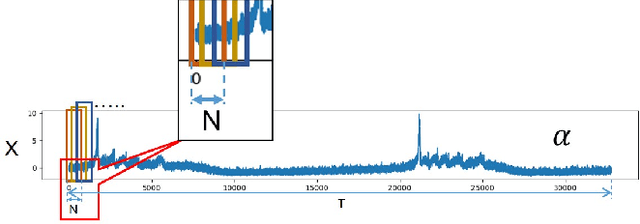
In this work, we report an autoencoder-based 2D representation to classify a time-series as stochastic or non-stochastic, to understand the underlying physical process. Content-aware conversion of 1D time-series to 2D representation, that simultaneously utilizes time- and frequency-domain characteristics, is proposed. An autoencoder is trained with a loss function to learn latent space (using both time- and frequency domains) representation, that is designed to be, time-invariant. Every element of the time-series is represented as a tuple with two components, one each, from latent space representation in time- and frequency-domains, forming a binary image. In this binary image, those tuples that represent the points in the time-series, together form the ``Latent Space Signature" (LSS) of the input time-series. The obtained binary LSS images are fed to a classification network. The EfficientNetv2-S classifier is trained using 421 synthetic time-series, with fair representation from both categories. The proposed methodology is evaluated on publicly available astronomical data which are 12 distinct temporal classes of time-series pertaining to the black hole GRS 1915 + 105, obtained from RXTE satellite. Results obtained using the proposed methodology are compared with existing techniques. Concurrence in labels obtained across the classes, illustrates the efficacy of the proposed 2D representation using the latent space co-ordinates. The proposed methodology also outputs the confidence in the classification label.