 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Tale of Two Learning Algorithms: Multiple Stream Random Walk and Asynchronous Gossip
Apr 14, 2025



Although gossip and random walk-based learning algorithms are widely known for decentralized learning, there has been limited theoretical and experimental analysis to understand their relative performance for different graph topologies and data heterogeneity. We first design and analyze a random walk-based learning algorithm with multiple streams (walks), which we name asynchronous "Multi-Walk (MW)". We provide a convergence analysis for MW w.r.t iteration (computation), wall-clock time, and communication. We also present a convergence analysis for "Asynchronous Gossip", noting the lack of a comprehensive analysis of its convergence, along with the computation and communication overhead, in the literature. Our results show that MW has better convergence in terms of iterations as compared to Asynchronous Gossip in graphs with large diameters (e.g., cycles), while its relative performance, as compared to Asynchronous Gossip, depends on the number of walks and the data heterogeneity in graphs with small diameters (e.g., complete graphs). In wall-clock time analysis, we observe a linear speed-up with the number of walks and nodes in MW and Asynchronous Gossip, respectively. Finally, we show that MW outperforms Asynchronous Gossip in communication overhead, except in small-diameter topologies with extreme data heterogeneity. These results highlight the effectiveness of each algorithm in different graph topologies and data heterogeneity. Our codes are available for reproducibility.
Priority-Aware Model-Distributed Inference at Edge Networks
Dec 16, 2024Distributed inference techniques can be broadly classified into data-distributed and model-distributed schemes. In data-distributed inference (DDI), each worker carries the entire Machine Learning (ML) model but processes only a subset of the data. However, feeding the data to workers results in high communication costs, especially when the data is large. An emerging paradigm is model-distributed inference (MDI), where each worker carries only a subset of ML layers. In MDI, a source device that has data processes a few layers of ML model and sends the output to a neighboring device, i.e., offloads the rest of the layers. This process ends when all layers are processed in a distributed manner. In this paper, we investigate the design and development of MDI when multiple data sources co-exist. We consider that each data source has a different importance and, hence, a priority. We formulate and solve a priority-aware model allocation optimization problem. Based on the structure of the optimal solution, we design a practical Priority-Aware Model- Distributed Inference (PA-MDI) algorithm that determines model allocation and distribution over devices by taking into account the priorities of different sources. Experiments were conducted on a real-life testbed of NVIDIA Jetson Xavier and Nano edge devices as well as in the Colosseum testbed with ResNet-50, ResNet- 56, and GPT-2 models. The experimental results show that PA-MDI performs priority-aware model allocation successfully while reducing the inference time as compared to baselines.
Early-Exit meets Model-Distributed Inference at Edge Networks
Aug 08, 2024Distributed inference techniques can be broadly classified into data-distributed and model-distributed schemes. In data-distributed inference (DDI), each worker carries the entire deep neural network (DNN) model but processes only a subset of the data. However, feeding the data to workers results in high communication costs, especially when the data is large. An emerging paradigm is model-distributed inference (MDI), where each worker carries only a subset of DNN layers. In MDI, a source device that has data processes a few layers of DNN and sends the output to a neighboring device, i.e., offloads the rest of the layers. This process ends when all layers are processed in a distributed manner. In this paper, we investigate the design and development of MDI with early-exit, which advocates that there is no need to process all the layers of a model for some data to reach the desired accuracy, i.e., we can exit the model without processing all the layers if target accuracy is reached. We design a framework MDI-Exit that adaptively determines early-exit and offloading policies as well as data admission at the source. Experimental results on a real-life testbed of NVIDIA Nano edge devices show that MDI-Exit processes more data when accuracy is fixed and results in higher accuracy for the fixed data rate.
Privacy-Preserving Model-Distributed Inference at the Edge
Jul 25, 2024This paper focuses on designing a privacy-preserving Machine Learning (ML) inference protocol for a hierarchical setup, where clients own/generate data, model owners (cloud servers) have a pre-trained ML model, and edge servers perform ML inference on clients' data using the cloud server's ML model. Our goal is to speed up ML inference while providing privacy to both data and the ML model. Our approach (i) uses model-distributed inference (model parallelization) at the edge servers and (ii) reduces the amount of communication to/from the cloud server. Our privacy-preserving hierarchical model-distributed inference, privateMDI design uses additive secret sharing and linearly homomorphic encryption to handle linear calculations in the ML inference, and garbled circuit and a novel three-party oblivious transfer are used to handle non-linear functions. privateMDI consists of offline and online phases. We designed these phases in a way that most of the data exchange is done in the offline phase while the communication overhead of the online phase is reduced. In particular, there is no communication to/from the cloud server in the online phase, and the amount of communication between the client and edge servers is minimized. The experimental results demonstrate that privateMDI significantly reduces the ML inference time as compared to the baselines.
Improved Generalization Bounds for Communication Efficient Federated Learning
Apr 17, 2024



This paper focuses on reducing the communication cost of federated learning by exploring generalization bounds and representation learning. We first characterize a tighter generalization bound for one-round federated learning based on local clients' generalizations and heterogeneity of data distribution (non-iid scenario). We also characterize a generalization bound in R-round federated learning and its relation to the number of local updates (local stochastic gradient descents (SGDs)). Then, based on our generalization bound analysis and our representation learning interpretation of this analysis, we show for the first time that less frequent aggregations, hence more local updates, for the representation extractor (usually corresponds to initial layers) leads to the creation of more generalizable models, particularly for non-iid scenarios. We design a novel Federated Learning with Adaptive Local Steps (FedALS) algorithm based on our generalization bound and representation learning analysis. FedALS employs varying aggregation frequencies for different parts of the model, so reduces the communication cost. The paper is followed with experimental results showing the effectiveness of FedALS.
DIGEST: Fast and Communication Efficient Decentralized Learning with Local Updates
Jul 14, 2023



Two widely considered decentralized learning algorithms are Gossip and random walk-based learning. Gossip algorithms (both synchronous and asynchronous versions) suffer from high communication cost, while random-walk based learning experiences increased convergence time. In this paper, we design a fast and communication-efficient asynchronous decentralized learning mechanism DIGEST by taking advantage of both Gossip and random-walk ideas, and focusing on stochastic gradient descent (SGD). DIGEST is an asynchronous decentralized algorithm building on local-SGD algorithms, which are originally designed for communication efficient centralized learning. We design both single-stream and multi-stream DIGEST, where the communication overhead may increase when the number of streams increases, and there is a convergence and communication overhead trade-off which can be leveraged. We analyze the convergence of single- and multi-stream DIGEST, and prove that both algorithms approach to the optimal solution asymptotically for both iid and non-iid data distributions. We evaluate the performance of single- and multi-stream DIGEST for logistic regression and a deep neural network ResNet20. The simulation results confirm that multi-stream DIGEST has nice convergence properties; i.e., its convergence time is better than or comparable to the baselines in iid setting, and outperforms the baselines in non-iid setting.
Robust and Computationally-Efficient Anomaly Detection using Powers-of-Two Networks
Oct 30, 2019
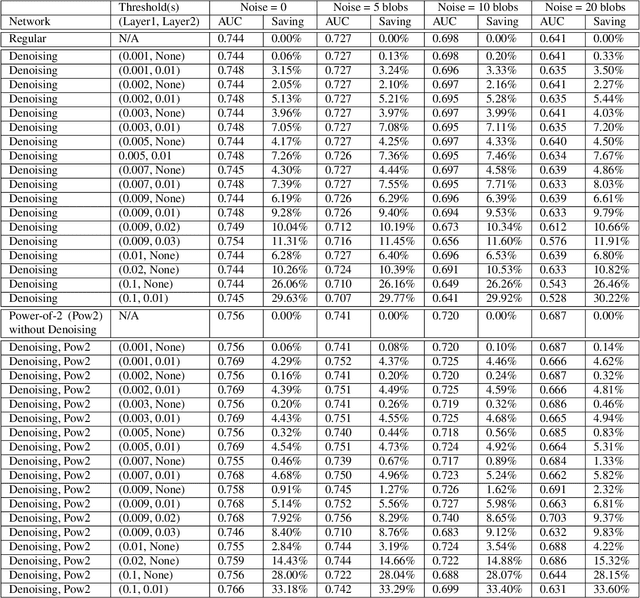
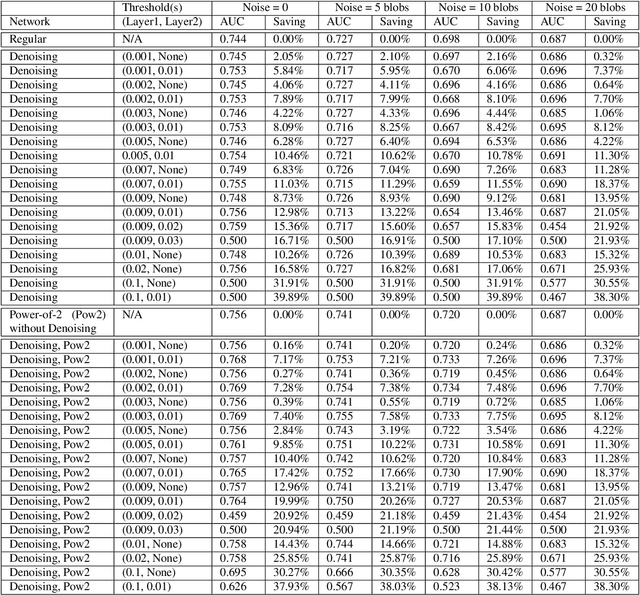
Robust and computationally efficient anomaly detection in videos is a problem in video surveillance systems. We propose a technique to increase robustness and reduce computational complexity in a Convolutional Neural Network (CNN) based anomaly detector that utilizes the optical flow information of video data. We reduce the complexity of the network by denoising the intermediate layer outputs of the CNN and by using powers-of-two weights, which replaces the computationally expensive multiplication operations with bit-shift operations. Denoising operation during inference forces small valued intermediate layer outputs to zero. The number of zeros in the network significantly increases as a result of denoising, we can implement the CNN about 10% faster than a comparable network while detecting all the anomalies in the testing set. It turns out that denoising operation also provides robustness because the contribution of small intermediate values to the final result is negligible. During training we also generate motion vector images by a Generative Adversarial Network (GAN) to improve the robustness of the overall system. We experimentally observe that the resulting system is robust to background motion.