 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Distance Correlation-Based Approach to Characterize the Effectiveness of Recurrent Neural Networks for Time Series Forecasting
Jul 28, 2023
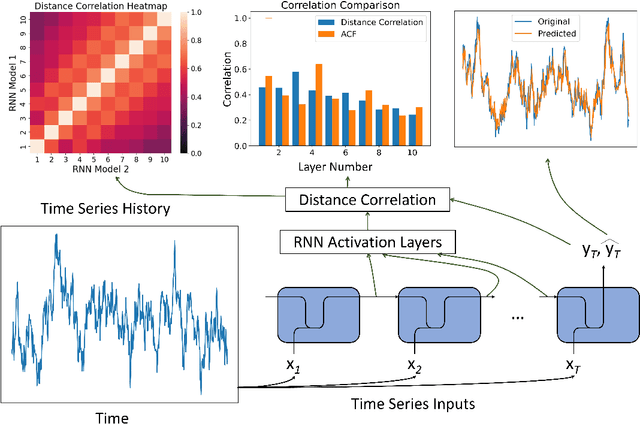
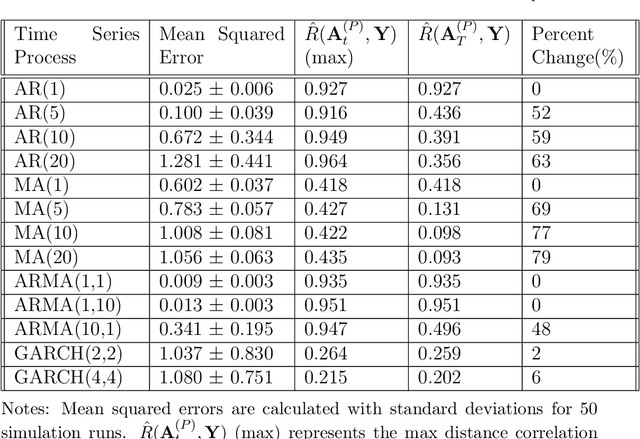
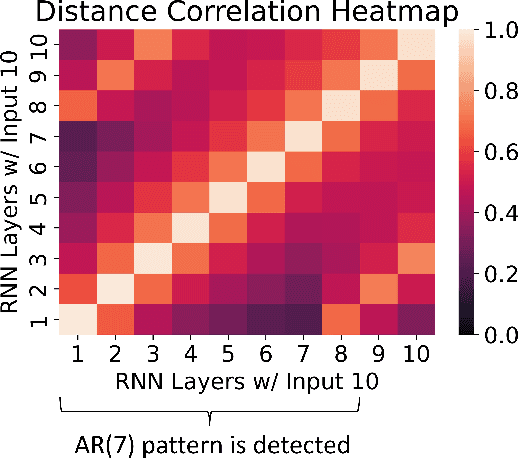
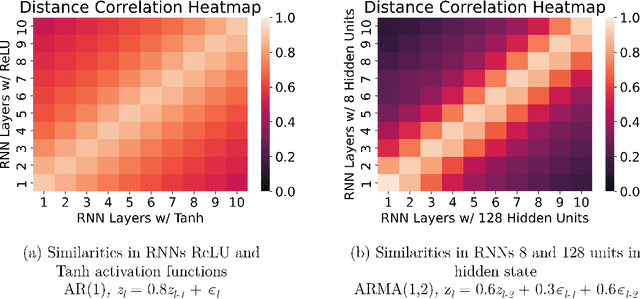
Time series forecasting has received a lot of attention with recurrent neural networks (RNNs) being one of the widely used models due to their ability to handle sequential data. Prior studies of RNNs for time series forecasting yield inconsistent results with limited insights as to why the performance varies for different datasets. In this paper, we provide an approach to link the characteristics of time series with the components of RNNs via the versatile metric of distance correlation. This metric allows us to examine the information flow through the RNN activation layers to be able to interpret and explain their performance. We empirically show that the RNN activation layers learn the lag structures of time series well. However, they gradually lose this information over a span of a few consecutive layers, thereby worsening the forecast quality for series with large lag structures. We also show that the activation layers cannot adequately model moving average and heteroskedastic time series processes. Last, we generate heatmaps for visual comparisons of the activation layers for different choices of the network hyperparameters to identify which of them affect the forecast performance. Our findings can, therefore, aid practitioners in assessing the effectiveness of RNNs for given time series data without actually training and evaluating the networks.
Energy-efficient Integrated Sensing and Communication System and DNLFM Waveform
Sep 18, 2023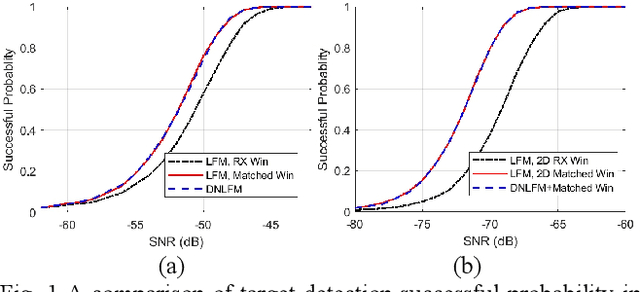
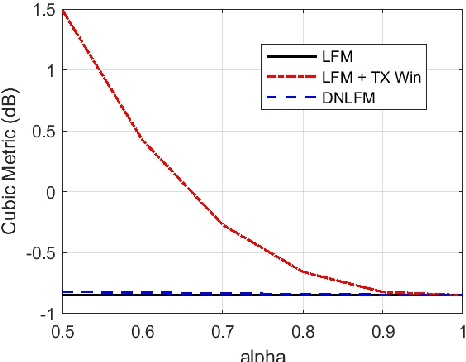
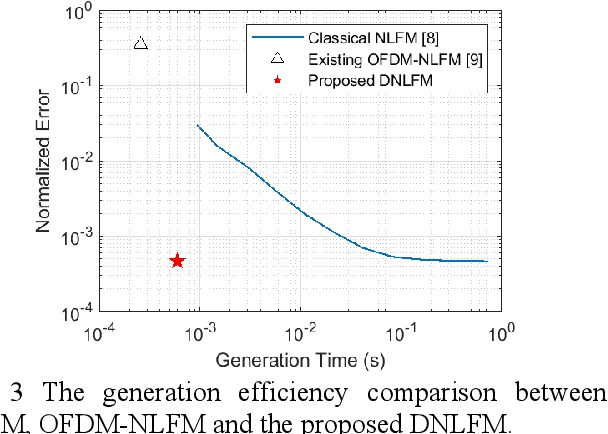
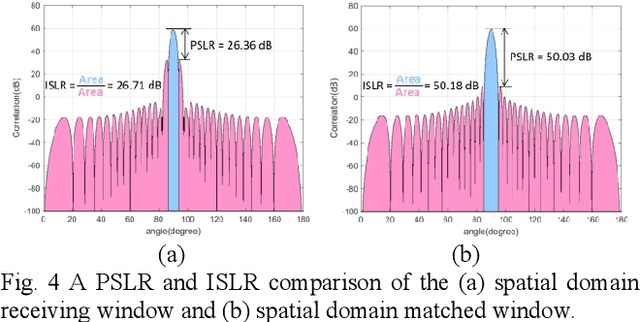
Integrated sensing and communication (ISAC) is a key enabler of 6G. Unlike communication radio links, the sensing signal requires to experience round trips from many scatters. Therefore, sensing is more power-sensitive and faces a severer multi-target interference. In this paper, the ISAC system employs dedicated sensing signals, which can be reused as the communication reference signal. This paper proposes to add time-frequency matched windows at both the transmitting and receiving sides, which avoids mismatch loss and increases energy efficiency. Discrete non-linear frequency modulation (DNLFM) is further proposed to achieve both time-domain constant modulus and frequency-domain arbitrary windowing weights. DNLFM uses very few Newton iterations and a simple geometrically-equivalent method to generate, which greatly reduces the complex numerical integral in the conventional method. Moreover, the spatial-domain matched window is proposed to achieve low sidelobes. The simulation results show that the proposed methods gain a higher energy efficiency than conventional methods.
Training dynamic models using early exits for automatic speech recognition on resource-constrained devices
Sep 18, 2023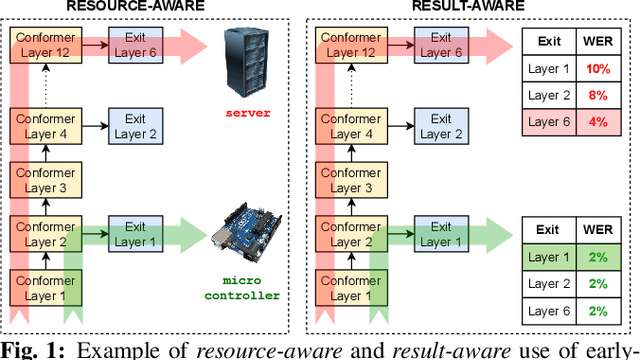
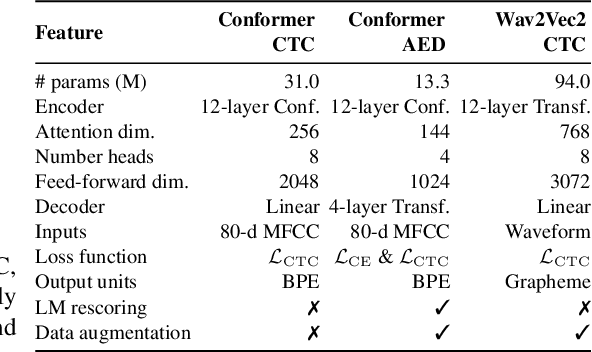
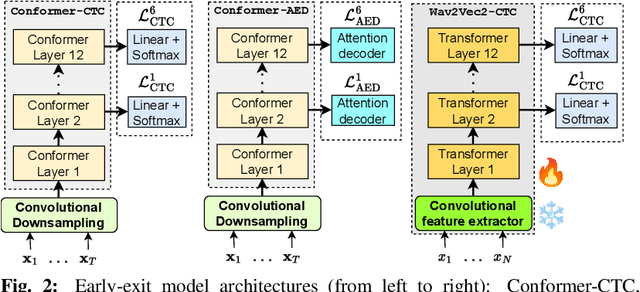
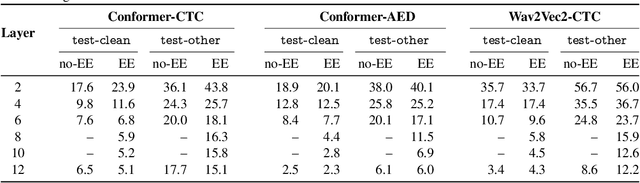
The possibility of dynamically modifying the computational load of neural models at inference time is crucial for on-device processing, where computational power is limited and time-varying. Established approaches for neural model compression exist, but they provide architecturally static models. In this paper, we investigate the use of early-exit architectures, that rely on intermediate exit branches, applied to large-vocabulary speech recognition. This allows for the development of dynamic models that adjust their computational cost to the available resources and recognition performance. Unlike previous works, besides using pre-trained backbones we also train the model from scratch with an early-exit architecture. Experiments on public datasets show that early-exit architectures from scratch not only preserve performance levels when using fewer encoder layers, but also improve task accuracy as compared to using single-exit models or using pre-trained models. Additionally, we investigate an exit selection strategy based on posterior probabilities as an alternative to frame-based entropy.
CRIMED: Lower and Upper Bounds on Regret for Bandits with Unbounded Stochastic Corruption
Sep 28, 2023We investigate the regret-minimisation problem in a multi-armed bandit setting with arbitrary corruptions. Similar to the classical setup, the agent receives rewards generated independently from the distribution of the arm chosen at each time. However, these rewards are not directly observed. Instead, with a fixed $\varepsilon\in (0,\frac{1}{2})$, the agent observes a sample from the chosen arm's distribution with probability $1-\varepsilon$, or from an arbitrary corruption distribution with probability $\varepsilon$. Importantly, we impose no assumptions on these corruption distributions, which can be unbounded. In this setting, accommodating potentially unbounded corruptions, we establish a problem-dependent lower bound on regret for a given family of arm distributions. We introduce CRIMED, an asymptotically-optimal algorithm that achieves the exact lower bound on regret for bandits with Gaussian distributions with known variance. Additionally, we provide a finite-sample analysis of CRIMED's regret performance. Notably, CRIMED can effectively handle corruptions with $\varepsilon$ values as high as $\frac{1}{2}$. Furthermore, we develop a tight concentration result for medians in the presence of arbitrary corruptions, even with $\varepsilon$ values up to $\frac{1}{2}$, which may be of independent interest. We also discuss an extension of the algorithm for handling misspecification in Gaussian model.
Leveraging Untrustworthy Commands for Multi-Robot Coordination in Unpredictable Environments: A Bandit Submodular Maximization Approach
Sep 28, 2023We study the problem of multi-agent coordination in unpredictable and partially-observable environments with untrustworthy external commands. The commands are actions suggested to the robots, and are untrustworthy in that their performance guarantees, if any, are unknown. Such commands may be generated by human operators or machine learning algorithms and, although untrustworthy, can often increase the robots' performance in complex multi-robot tasks. We are motivated by complex multi-robot tasks such as target tracking, environmental mapping, and area monitoring. Such tasks are often modeled as submodular maximization problems due to the information overlap among the robots. We provide an algorithm, Meta Bandit Sequential Greedy (MetaBSG), which enjoys performance guarantees even when the external commands are arbitrarily bad. MetaBSG leverages a meta-algorithm to learn whether the robots should follow the commands or a recently developed submodular coordination algorithm, Bandit Sequential Greedy (BSG) [1], which has performance guarantees even in unpredictable and partially-observable environments. Particularly, MetaBSG asymptotically can achieve the better performance out of the commands and the BSG algorithm, quantifying its suboptimality against the optimal time-varying multi-robot actions in hindsight. Thus, MetaBSG can be interpreted as robustifying the untrustworthy commands. We validate our algorithm in simulated scenarios of multi-target tracking.
Deep Geometrized Cartoon Line Inbetweening
Sep 28, 2023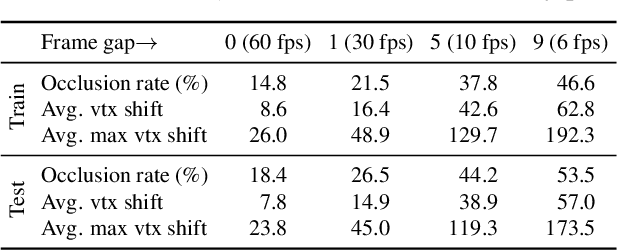
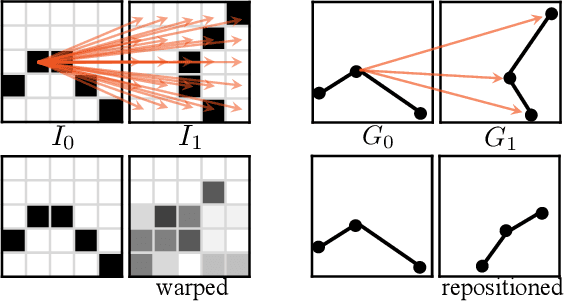
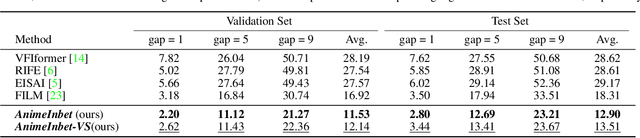
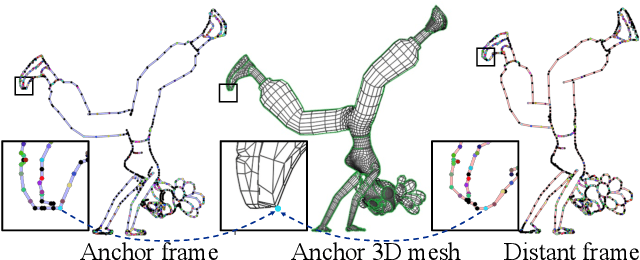
We aim to address a significant but understudied problem in the anime industry, namely the inbetweening of cartoon line drawings. Inbetweening involves generating intermediate frames between two black-and-white line drawings and is a time-consuming and expensive process that can benefit from automation. However, existing frame interpolation methods that rely on matching and warping whole raster images are unsuitable for line inbetweening and often produce blurring artifacts that damage the intricate line structures. To preserve the precision and detail of the line drawings, we propose a new approach, AnimeInbet, which geometrizes raster line drawings into graphs of endpoints and reframes the inbetweening task as a graph fusion problem with vertex repositioning. Our method can effectively capture the sparsity and unique structure of line drawings while preserving the details during inbetweening. This is made possible via our novel modules, i.e., vertex geometric embedding, a vertex correspondence Transformer, an effective mechanism for vertex repositioning and a visibility predictor. To train our method, we introduce MixamoLine240, a new dataset of line drawings with ground truth vectorization and matching labels. Our experiments demonstrate that AnimeInbet synthesizes high-quality, clean, and complete intermediate line drawings, outperforming existing methods quantitatively and qualitatively, especially in cases with large motions. Data and code are available at https://github.com/lisiyao21/AnimeInbet.
MASK4D: Mask Transformer for 4D Panoptic Segmentation
Sep 28, 2023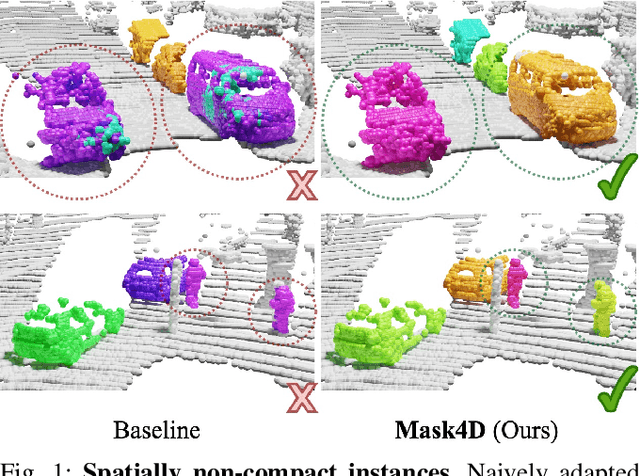
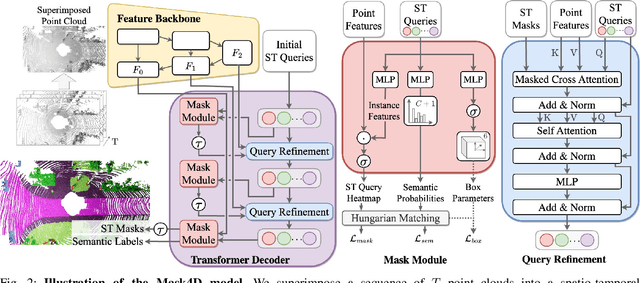
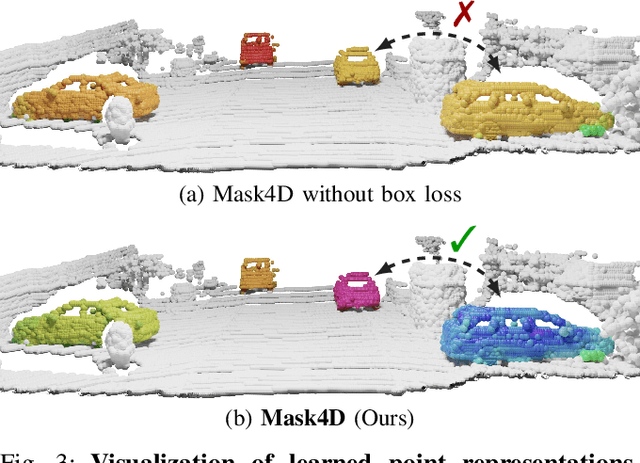

Accurately perceiving and tracking instances over time is essential for the decision-making processes of autonomous agents interacting safely in dynamic environments. With this intention, we propose Mask4D for the challenging task of 4D panoptic segmentation of LiDAR point clouds. Mask4D is the first transformer-based approach unifying semantic instance segmentation and tracking of sparse and irregular sequences of 3D point clouds into a single joint model. Our model directly predicts semantic instances and their temporal associations without relying on any hand-crafted non-learned association strategies such as probabilistic clustering or voting-based center prediction. Instead, Mask4D introduces spatio-temporal instance queries which encode the semantic and geometric properties of each semantic tracklet in the sequence. In an in-depth study, we find that it is critical to promote spatially compact instance predictions as spatio-temporal instance queries tend to merge multiple semantically similar instances, even if they are spatially distant. To this end, we regress 6-DOF bounding box parameters from spatio-temporal instance queries, which is used as an auxiliary task to foster spatially compact predictions. Mask4D achieves a new state-of-the-art on the SemanticKITTI test set with a score of 68.4 LSTQ, improving upon published top-performing methods by at least +4.5%.
TrTr: A Versatile Pre-Trained Large Traffic Model based on Transformer for Capturing Trajectory Diversity in Vehicle Population
Sep 22, 2023Understanding trajectory diversity is a fundamental aspect of addressing practical traffic tasks. However, capturing the diversity of trajectories presents challenges, particularly with traditional machine learning and recurrent neural networks due to the requirement of large-scale parameters. The emerging Transformer technology, renowned for its parallel computation capabilities enabling the utilization of models with hundreds of millions of parameters, offers a promising solution. In this study, we apply the Transformer architecture to traffic tasks, aiming to learn the diversity of trajectories within vehicle populations. We analyze the Transformer's attention mechanism and its adaptability to the goals of traffic tasks, and subsequently, design specific pre-training tasks. To achieve this, we create a data structure tailored to the attention mechanism and introduce a set of noises that correspond to spatio-temporal demands, which are incorporated into the structured data during the pre-training process. The designed pre-training model demonstrates excellent performance in capturing the spatial distribution of the vehicle population, with no instances of vehicle overlap and an RMSE of 0.6059 when compared to the ground truth values. In the context of time series prediction, approximately 95% of the predicted trajectories' speeds closely align with the true speeds, within a deviation of 7.5144m/s. Furthermore, in the stability test, the model exhibits robustness by continuously predicting a time series ten times longer than the input sequence, delivering smooth trajectories and showcasing diverse driving behaviors. The pre-trained model also provides a good basis for downstream fine-tuning tasks. The number of parameters of our model is over 50 million.
U-shaped Transformer: Retain High Frequency Context in Time Series Analysis
Jul 18, 2023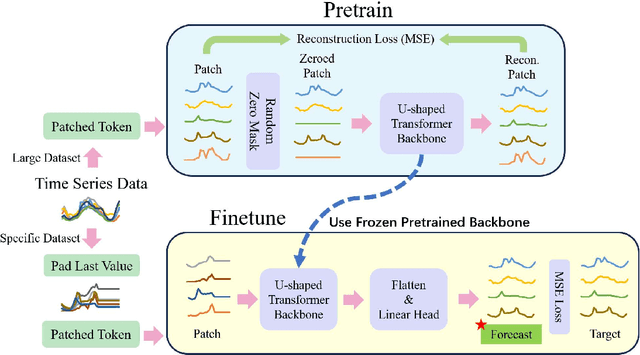
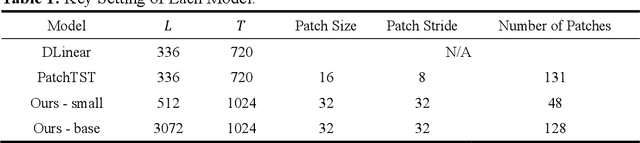

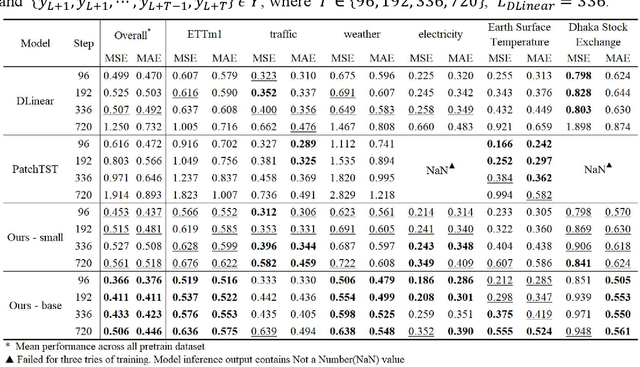
Time series prediction plays a crucial role in various industrial fields. In recent years, neural networks with a transformer backbone have achieved remarkable success in many domains, including computer vision and NLP. In time series analysis domain, some studies have suggested that even the simplest MLP networks outperform advanced transformer-based networks on time series forecast tasks. However, we believe these findings indicate there to be low-rank properties in time series sequences. In this paper, we consider the low-pass characteristics of transformers and try to incorporate the advantages of MLP. We adopt skip-layer connections inspired by Unet into traditional transformer backbone, thus preserving high-frequency context from input to output, namely U-shaped Transformer. We introduce patch merge and split operation to extract features with different scales and use larger datasets to fully make use of the transformer backbone. Our experiments demonstrate that the model performs at an advanced level across multiple datasets with relatively low cost.
Gold-YOLO: Efficient Object Detector via Gather-and-Distribute Mechanism
Sep 20, 2023In the past years, YOLO-series models have emerged as the leading approaches in the area of real-time object detection. Many studies pushed up the baseline to a higher level by modifying the architecture, augmenting data and designing new losses. However, we find previous models still suffer from information fusion problem, although Feature Pyramid Network (FPN) and Path Aggregation Network (PANet) have alleviated this. Therefore, this study provides an advanced Gatherand-Distribute mechanism (GD) mechanism, which is realized with convolution and self-attention operations. This new designed model named as Gold-YOLO, which boosts the multi-scale feature fusion capabilities and achieves an ideal balance between latency and accuracy across all model scales. Additionally, we implement MAE-style pretraining in the YOLO-series for the first time, allowing YOLOseries models could be to benefit from unsupervised pretraining. Gold-YOLO-N attains an outstanding 39.9% AP on the COCO val2017 datasets and 1030 FPS on a T4 GPU, which outperforms the previous SOTA model YOLOv6-3.0-N with similar FPS by +2.4%. The PyTorch code is available at https://github.com/huaweinoah/Efficient-Computing/Detection/Gold-YOLO, and the MindSpore code is available at https://gitee.com/mindspore/models/tree/master/research/cv/Gold_YOLO.