 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
KTRL+F: Knowledge-Augmented In-Document Search
Nov 16, 2023
We introduce a new problem KTRL+F, a knowledge-augmented in-document search task that necessitates real-time identification of all semantic targets within a document with the awareness of external sources through a single natural query. This task addresses following unique challenges for in-document search: 1) utilizing knowledge outside the document for extended use of additional information about targets to bridge the semantic gap between the query and the targets, and 2) balancing between real-time applicability with the performance. We analyze various baselines in KTRL+F and find there are limitations of existing models, such as hallucinations, low latency, or difficulties in leveraging external knowledge. Therefore we propose a Knowledge-Augmented Phrase Retrieval model that shows a promising balance between speed and performance by simply augmenting external knowledge embedding in phrase embedding. Additionally, we conduct a user study to verify whether solving KTRL+F can enhance search experience of users. It demonstrates that even with our simple model users can reduce the time for searching with less queries and reduced extra visits to other sources for collecting evidence. We encourage the research community to work on KTRL+F to enhance more efficient in-document information access.
Few-shot Message-Enhanced Contrastive Learning for Graph Anomaly Detection
Nov 17, 2023Graph anomaly detection plays a crucial role in identifying exceptional instances in graph data that deviate significantly from the majority. It has gained substantial attention in various domains of information security, including network intrusion, financial fraud, and malicious comments, et al. Existing methods are primarily developed in an unsupervised manner due to the challenge in obtaining labeled data. For lack of guidance from prior knowledge in unsupervised manner, the identified anomalies may prove to be data noise or individual data instances. In real-world scenarios, a limited batch of labeled anomalies can be captured, making it crucial to investigate the few-shot problem in graph anomaly detection. Taking advantage of this potential, we propose a novel few-shot Graph Anomaly Detection model called FMGAD (Few-shot Message-Enhanced Contrastive-based Graph Anomaly Detector). FMGAD leverages a self-supervised contrastive learning strategy within and across views to capture intrinsic and transferable structural representations. Furthermore, we propose the Deep-GNN message-enhanced reconstruction module, which extensively exploits the few-shot label information and enables long-range propagation to disseminate supervision signals to deeper unlabeled nodes. This module in turn assists in the training of self-supervised contrastive learning. Comprehensive experimental results on six real-world datasets demonstrate that FMGAD can achieve better performance than other state-of-the-art methods, regardless of artificially injected anomalies or domain-organic anomalies.
Joint Sensing and Communication Optimization in Target-Mounted STARS-Assisted Vehicular Networks: A MADRL Approach
Nov 17, 2023The utilization of integrated sensing and communication (ISAC) technology has the potential to enhance the communication performance of road side units (RSUs) through the active sensing of target vehicles. Furthermore, installing a simultaneous transmitting and reflecting surface (STARS) on the target vehicle can provide an extra boost to the reflection of the echo signal, thereby improving the communication quality for in-vehicle users. However, the design of this target-mounted STARS system exhibits significant challenges, such as limited information sharing and distributed STARS control. In this paper, we propose an end-to-end multi-agent deep reinforcement learning (MADRL) framework to tackle the challenges of joint sensing and communication optimization in the considered target-mounted STARS assisted vehicle networks. By deploying agents on both RSU and vehicle, the MADRL framework enables RSU and vehicle to perform beam prediction and STARS pre-configuration using their respective local information. To ensure efficient and stable learning for continuous decision-making, we employ the multi-agent soft actor critic (MASAC) algorithm and the multi-agent proximal policy optimization (MAPPO) algorithm on the proposed MADRL framework. Extensive experimental results confirm the effectiveness of our proposed MADRL framework in improving both sensing and communication performance through the utilization of target-mounted STARS. Finally, we conduct a comparative analysis and comparison of the two proposed algorithms under various environmental conditions.
Deep Group Interest Modeling of Full Lifelong User Behaviors for CTR Prediction
Nov 15, 2023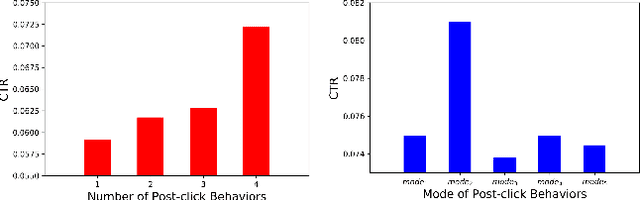

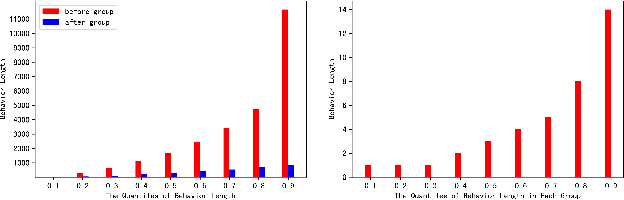
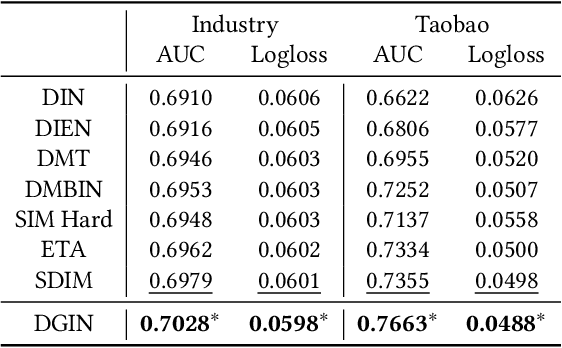
Extracting users' interests from their lifelong behavior sequence is crucial for predicting Click-Through Rate (CTR). Most current methods employ a two-stage process for efficiency: they first select historical behaviors related to the candidate item and then deduce the user's interest from this narrowed-down behavior sub-sequence. This two-stage paradigm, though effective, leads to information loss. Solely using users' lifelong click behaviors doesn't provide a complete picture of their interests, leading to suboptimal performance. In our research, we introduce the Deep Group Interest Network (DGIN), an end-to-end method to model the user's entire behavior history. This includes all post-registration actions, such as clicks, cart additions, purchases, and more, providing a nuanced user understanding. We start by grouping the full range of behaviors using a relevant key (like item_id) to enhance efficiency. This process reduces the behavior length significantly, from O(10^4) to O(10^2). To mitigate the potential loss of information due to grouping, we incorporate two categories of group attributes. Within each group, we calculate statistical information on various heterogeneous behaviors (like behavior counts) and employ self-attention mechanisms to highlight unique behavior characteristics (like behavior type). Based on this reorganized behavior data, the user's interests are derived using the Transformer technique. Additionally, we identify a subset of behaviors that share the same item_id with the candidate item from the lifelong behavior sequence. The insights from this subset reveal the user's decision-making process related to the candidate item, improving prediction accuracy. Our comprehensive evaluation, both on industrial and public datasets, validates DGIN's efficacy and efficiency.
Survey on Near-Space Information Networks: Channel Modeling, Networking, and Transmission Perspectives
Oct 13, 2023Near-space information networks (NSIN) composed of high-altitude platforms (HAPs), high- and low-altitude unmanned aerial vehicles (UAVs) are a new regime for providing quickly, robustly, and cost-efficiently sensing and communication services. Precipitated by innovations and breakthroughs in manufacturing, materials, communications, electronics, and control technologies, NSIN have emerged as an essential component of the emerging sixth-generation of mobile communication systems. This article aims at providing and discussing the latest advances in NSIN in the research areas of channel modeling, networking, and transmission from a forward-looking, comparative, and technological evolutionary perspective. In this article, we highlight the characteristics of NSIN and present the promising use-cases of NSIN. The impact of airborne platforms' unstable movements on the phase delays of onboard antenna arrays with diverse structures is mathematically analyzed. The recent advancements in HAP channel modeling are elaborated on, along with the significant differences between HAP and UAV channel modeling. A comprehensive review of the networking technologies of NSIN in network deployment, handoff management, and network management aspects is provided. Besides, the promising technologies and communication protocols of the physical layer, medium access control (MAC) layer, network layer, and transport layer of NSIN for achieving efficient transmission over NSIN are overviewed. Finally, we outline some open issues and promising directions of NSIN deserved for future study and discuss the corresponding challenges.
Differentiable Visual Computing for Inverse Problems and Machine Learning
Nov 21, 2023Originally designed for applications in computer graphics, visual computing (VC) methods synthesize information about physical and virtual worlds, using prescribed algorithms optimized for spatial computing. VC is used to analyze geometry, physically simulate solids, fluids, and other media, and render the world via optical techniques. These fine-tuned computations that operate explicitly on a given input solve so-called forward problems, VC excels at. By contrast, deep learning (DL) allows for the construction of general algorithmic models, side stepping the need for a purely first principles-based approach to problem solving. DL is powered by highly parameterized neural network architectures -- universal function approximators -- and gradient-based search algorithms which can efficiently search that large parameter space for optimal models. This approach is predicated by neural network differentiability, the requirement that analytic derivatives of a given problem's task metric can be computed with respect to neural network's parameters. Neural networks excel when an explicit model is not known, and neural network training solves an inverse problem in which a model is computed from data.
Neural Network Pruning by Gradient Descent
Nov 21, 2023The rapid increase in the parameters of deep learning models has led to significant costs, challenging computational efficiency and model interpretability. In this paper, we introduce a novel and straightforward neural network pruning framework that incorporates the Gumbel-Softmax technique. This framework enables the simultaneous optimization of a network's weights and topology in an end-to-end process using stochastic gradient descent. Empirical results demonstrate its exceptional compression capability, maintaining high accuracy on the MNIST dataset with only 0.15\% of the original network parameters. Moreover, our framework enhances neural network interpretability, not only by allowing easy extraction of feature importance directly from the pruned network but also by enabling visualization of feature symmetry and the pathways of information propagation from features to outcomes. Although the pruning strategy is learned through deep learning, it is surprisingly intuitive and understandable, focusing on selecting key representative features and exploiting data patterns to achieve extreme sparse pruning. We believe our method opens a promising new avenue for deep learning pruning and the creation of interpretable machine learning systems.
Individualized Dynamic Latent Factor Model with Application to Mobile Health Data
Nov 21, 2023Mobile health has emerged as a major success in tracking individual health status, due to the popularity and power of smartphones and wearable devices. This has also brought great challenges in handling heterogeneous, multi-resolution data which arise ubiquitously in mobile health due to irregular multivariate measurements collected from individuals. In this paper, we propose an individualized dynamic latent factor model for irregular multi-resolution time series data to interpolate unsampled measurements of time series with low resolution. One major advantage of the proposed method is the capability to integrate multiple irregular time series and multiple subjects by mapping the multi-resolution data to the latent space. In addition, the proposed individualized dynamic latent factor model is applicable to capturing heterogeneous longitudinal information through individualized dynamic latent factors. In theory, we provide the integrated interpolation error bound of the proposed estimator and derive the convergence rate with B-spline approximation methods. Both the simulation studies and the application to smartwatch data demonstrate the superior performance of the proposed method compared to existing methods.
Infinite forecast combinations based on Dirichlet process
Nov 21, 2023Forecast combination integrates information from various sources by consolidating multiple forecast results from the target time series. Instead of the need to select a single optimal forecasting model, this paper introduces a deep learning ensemble forecasting model based on the Dirichlet process. Initially, the learning rate is sampled with three basis distributions as hyperparameters to convert the infinite mixture into a finite one. All checkpoints are collected to establish a deep learning sub-model pool, and weight adjustment and diversity strategies are developed during the combination process. The main advantage of this method is its ability to generate the required base learners through a single training process, utilizing the decaying strategy to tackle the challenge posed by the stochastic nature of gradient descent in determining the optimal learning rate. To ensure the method's generalizability and competitiveness, this paper conducts an empirical analysis using the weekly dataset from the M4 competition and explores sensitivity to the number of models to be combined. The results demonstrate that the ensemble model proposed offers substantial improvements in prediction accuracy and stability compared to a single benchmark model.
Image-Based Soil Organic Carbon Remote Sensing from Satellite Images with Fourier Neural Operator and Structural Similarity
Nov 21, 2023Soil organic carbon (SOC) sequestration is the transfer and storage of atmospheric carbon dioxide in soils, which plays an important role in climate change mitigation. SOC concentration can be improved by proper land use, thus it is beneficial if SOC can be estimated at a regional or global scale. As multispectral satellite data can provide SOC-related information such as vegetation and soil properties at a global scale, estimation of SOC through satellite data has been explored as an alternative to manual soil sampling. Although existing studies show promising results, they are mainly based on pixel-based approaches with traditional machine learning methods, and convolutional neural networks (CNNs) are uncommon. To study the use of CNNs on SOC remote sensing, here we propose the FNO-DenseNet based on the Fourier neural operator (FNO). By combining the advantages of the FNO and DenseNet, the FNO-DenseNet outperformed the FNO in our experiments with hundreds of times fewer parameters. The FNO-DenseNet also outperformed a pixel-based random forest by 18% in the mean absolute percentage error.