 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOff-Policy Evaluation for Missingness-Aware Policies in MDPs with Rewards Missing Not at Random
Jun 18, 2026In offline Reinforcement Learning, immediate rewards in logged batch data are often unobserved due to sparse or irregular record-keeping, or censored beyond certain reward values. This issue arises in practical settings, including health care and marketing. We investigate off-policy evaluation (OPE) in finite-horizon Markov decision processes when rewards are missing not at random (MNAR), which breaks ignorability and induces selection bias even after conditioning on states and actions. To address this, we formalize a reward-dependent propensity model and use future states as shadow variables to identify the full-data conditional mean reward. We further introduce a bridge function that recovers the conditional mean reward without explicitly modeling the MNAR mechanism, and estimate it via a min-max procedure to avoid double sampling. Building upon these identification results, we propose an Fitted-Q-Evaluation-style estimator that propagates the recovered rewards while allowing target policies to depend on past missingness indicators. Finally, we establish consistency and finite-sample error bounds for our OPE estimator, and show through experiments the strong performance of our method compared to existing methods on simulated and MIMIC-III Sepsis data.
Dynamic Topic Modeling with a Higher-Order Hypergraphical Representation
May 27, 2026Dynamic topic modeling is widely used to analyze evolving trends in scientific literature, medical records, and social media. Traditional topic models represent each topic through a single probability vector on the multinomial simplex and implicitly couple word occurrence and repetition within one probabilistic mechanism. However, this formulation restricts the dependence structure among words and overlooks informative higher-order interactions, particularly in dynamic corpora with overlapping semantics. To address these limitations, we introduce a hypergraph representation of text where each document is modeled as a hyperedge connecting all co-occurring words, with repetition intensities encoded as node weights. This representation naturally separates word occurrence from repetition and induces a novel hypergraph-based multinomial distribution with a nonlinear normalization depending on the observed word set of each document. Building on this likelihood, we develop a dynamic topic modeling framework via structured low-rank factorizations with explicit temporal regularization on topic-word profiles. Moreover, we establish local convergence guarantees and derive non-asymptotic error bounds despite the intrinsic nonconvexity induced by bilinear factorization and document-specific nonlinear normalization. Numerical experiments on synthetic data and an application to the International Conference on Learning Representations (ICLR) corpus demonstrate consistent improvements over existing multinomial-based topic models.
TOPPO: Rethinking PPO for Multi-Task Reinforcement Learning with Critic Balancing
May 12, 2026Soft Actor-Critic (SAC) and its variants dominate Multi-Task Reinforcement Learning (MTRL) due to their off-policy sample efficiency, while on-policy methods such as Proximal Policy Optimization (PPO) remain underexplored. We diagnose that PPO in MTRL suffers from a previously overlooked issue: critic-side gradient ill-conditioning, which may cause tail tasks to stall while easy tasks dominate the value function's updates. To address this, we propose TOPPO (Tail-Optimized PPO), a reformulation of PPO via Critic Balancing -- a set of modules that improve gradient conditioning and balance learning dynamics across tasks. Unlike prior approaches that rely on modular architectures or large models, TOPPO targets the optimization bottleneck within PPO itself. Empirically, TOPPO achieves stronger mean and tail-task performance than published SAC-family and ARS-family baselines while using substantially fewer parameters and environment steps on Meta-World+ benchmark. Notably, TOPPO matches or surpasses strong SAC baselines early in training and maintains superior performance at full budget. Ablations confirm the effectiveness of each module in TOPPO and provide insights into their interactions. Our results demonstrate that, with proper optimization, on-policy methods can rival or exceed off-policy approaches in MTRL, challenging the prevailing reliance on SAC and highlighting critic-side gradient conditioning as the central bottleneck.
Distributional Treatment Effect Estimation across Heterogeneous Sites via Optimal Transport
Nov 12, 2025



We propose a novel framework for synthesizing counterfactual treatment group data in a target site by integrating full treatment and control group data from a source site with control group data from the target. Departing from conventional average treatment effect estimation, our approach adopts a distributional causal inference perspective by modeling treatment and control as distinct probability measures on the source and target sites. We formalize the cross-site heterogeneity (effect modification) as a push-forward transformation that maps the joint feature-outcome distribution from the source to the target site. This transformation is learned by aligning the control group distributions between sites using an Optimal Transport-based procedure, and subsequently applied to the source treatment group to generate the synthetic target treatment distribution. Under general regularity conditions, we establish theoretical guarantees for the consistency and asymptotic convergence of the synthetic treatment group data to the true target distribution. Simulation studies across multiple data-generating scenarios and a real-world application to patient-derived xenograft data demonstrate that our framework robustly recovers the full distributional properties of treatment effects.
Meta Fusion: A Unified Framework For Multimodality Fusion with Mutual Learning
Jul 27, 2025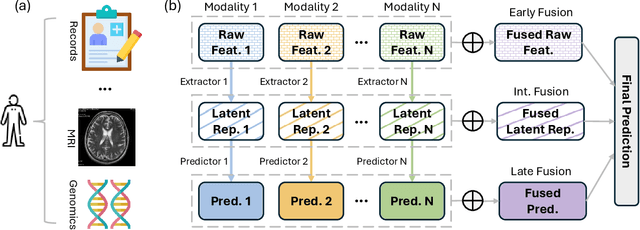
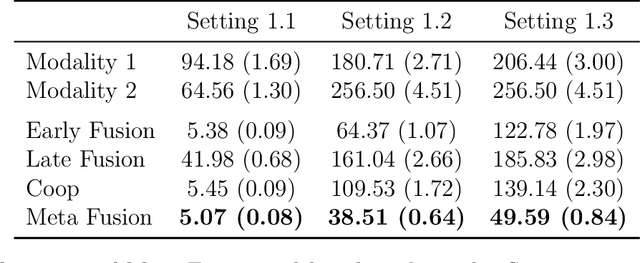
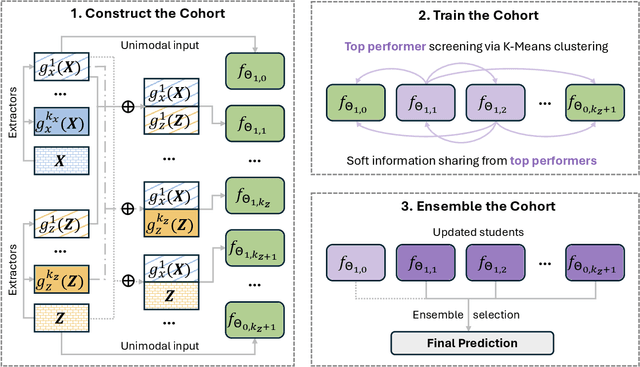
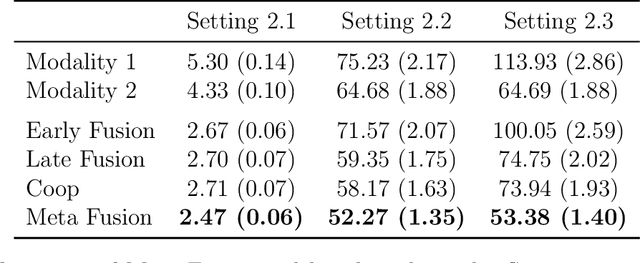
Developing effective multimodal data fusion strategies has become increasingly essential for improving the predictive power of statistical machine learning methods across a wide range of applications, from autonomous driving to medical diagnosis. Traditional fusion methods, including early, intermediate, and late fusion, integrate data at different stages, each offering distinct advantages and limitations. In this paper, we introduce Meta Fusion, a flexible and principled framework that unifies these existing strategies as special cases. Motivated by deep mutual learning and ensemble learning, Meta Fusion constructs a cohort of models based on various combinations of latent representations across modalities, and further boosts predictive performance through soft information sharing within the cohort. Our approach is model-agnostic in learning the latent representations, allowing it to flexibly adapt to the unique characteristics of each modality. Theoretically, our soft information sharing mechanism reduces the generalization error. Empirically, Meta Fusion consistently outperforms conventional fusion strategies in extensive simulation studies. We further validate our approach on real-world applications, including Alzheimer's disease detection and neural decoding.
Multi-task Learning for Heterogeneous Multi-source Block-Wise Missing Data
May 30, 2025Multi-task learning (MTL) has emerged as an imperative machine learning tool to solve multiple learning tasks simultaneously and has been successfully applied to healthcare, marketing, and biomedical fields. However, in order to borrow information across different tasks effectively, it is essential to utilize both homogeneous and heterogeneous information. Among the extensive literature on MTL, various forms of heterogeneity are presented in MTL problems, such as block-wise, distribution, and posterior heterogeneity. Existing methods, however, struggle to tackle these forms of heterogeneity simultaneously in a unified framework. In this paper, we propose a two-step learning strategy for MTL which addresses the aforementioned heterogeneity. First, we impute the missing blocks using shared representations extracted from homogeneous source across different tasks. Next, we disentangle the mappings between input features and responses into a shared component and a task-specific component, respectively, thereby enabling information borrowing through the shared component. Our numerical experiments and real-data analysis from the ADNI database demonstrate the superior MTL performance of the proposed method compared to other competing methods.
Multi-task Learning for Heterogeneous Data via Integrating Shared and Task-Specific Encodings
May 30, 2025Multi-task learning (MTL) has become an essential machine learning tool for addressing multiple learning tasks simultaneously and has been effectively applied across fields such as healthcare, marketing, and biomedical research. However, to enable efficient information sharing across tasks, it is crucial to leverage both shared and heterogeneous information. Despite extensive research on MTL, various forms of heterogeneity, including distribution and posterior heterogeneity, present significant challenges. Existing methods often fail to address these forms of heterogeneity within a unified framework. In this paper, we propose a dual-encoder framework to construct a heterogeneous latent factor space for each task, incorporating a task-shared encoder to capture common information across tasks and a task-specific encoder to preserve unique task characteristics. Additionally, we explore the intrinsic similarity structure of the coefficients corresponding to learned latent factors, allowing for adaptive integration across tasks to manage posterior heterogeneity. We introduce a unified algorithm that alternately learns the task-specific and task-shared encoders and coefficients. In theory, we investigate the excess risk bound for the proposed MTL method using local Rademacher complexity and apply it to a new but related task. Through simulation studies, we demonstrate that the proposed method outperforms existing data integration methods across various settings. Furthermore, the proposed method achieves superior predictive performance for time to tumor doubling across five distinct cancer types in PDX data.
Reinforcement Learning for Individual Optimal Policy from Heterogeneous Data
May 14, 2025Offline reinforcement learning (RL) aims to find optimal policies in dynamic environments in order to maximize the expected total rewards by leveraging pre-collected data. Learning from heterogeneous data is one of the fundamental challenges in offline RL. Traditional methods focus on learning an optimal policy for all individuals with pre-collected data from a single episode or homogeneous batch episodes, and thus, may result in a suboptimal policy for a heterogeneous population. In this paper, we propose an individualized offline policy optimization framework for heterogeneous time-stationary Markov decision processes (MDPs). The proposed heterogeneous model with individual latent variables enables us to efficiently estimate the individual Q-functions, and our Penalized Pessimistic Personalized Policy Learning (P4L) algorithm guarantees a fast rate on the average regret under a weak partial coverage assumption on behavior policies. In addition, our simulation studies and a real data application demonstrate the superior numerical performance of the proposed method compared with existing methods.
Representation Retrieval Learning for Heterogeneous Data Integration
Mar 13, 2025



In the era of big data, large-scale, multi-modal datasets are increasingly ubiquitous, offering unprecedented opportunities for predictive modeling and scientific discovery. However, these datasets often exhibit complex heterogeneity, such as covariate shift, posterior drift, and missing modalities, that can hinder the accuracy of existing prediction algorithms. To address these challenges, we propose a novel Representation Retrieval ($R^2$) framework, which integrates a representation learning module (the representer) with a sparsity-induced machine learning model (the learner). Moreover, we introduce the notion of "integrativeness" for representers, characterized by the effective data sources used in learning representers, and propose a Selective Integration Penalty (SIP) to explicitly improve the property. Theoretically, we demonstrate that the $R^2$ framework relaxes the conventional full-sharing assumption in multi-task learning, allowing for partially shared structures, and that SIP can improve the convergence rate of the excess risk bound. Extensive simulation studies validate the empirical performance of our framework, and applications to two real-world datasets further confirm its superiority over existing approaches.
Optimal Transport for Latent Integration with An Application to Heterogeneous Neuronal Activity Data
Jun 27, 2024



Detecting dynamic patterns of task-specific responses shared across heterogeneous datasets is an essential and challenging problem in many scientific applications in medical science and neuroscience. In our motivating example of rodent electrophysiological data, identifying the dynamical patterns in neuronal activity associated with ongoing cognitive demands and behavior is key to uncovering the neural mechanisms of memory. One of the greatest challenges in investigating a cross-subject biological process is that the systematic heterogeneity across individuals could significantly undermine the power of existing machine learning methods to identify the underlying biological dynamics. In addition, many technically challenging neurobiological experiments are conducted on only a handful of subjects where rich longitudinal data are available for each subject. The low sample sizes of such experiments could further reduce the power to detect common dynamic patterns among subjects. In this paper, we propose a novel heterogeneous data integration framework based on optimal transport to extract shared patterns in complex biological processes. The key advantages of the proposed method are that it can increase discriminating power in identifying common patterns by reducing heterogeneity unrelated to the signal by aligning the extracted latent spatiotemporal information across subjects. Our approach is effective even with a small number of subjects, and does not require auxiliary matching information for the alignment. In particular, our method can align longitudinal data across heterogeneous subjects in a common latent space to capture the dynamics of shared patterns while utilizing temporal dependency within subjects.