 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Revisiting Graph Meaning Representations through Decoupling Contextual Representation Learning and Structural Information Propagation
Oct 15, 2023
In the field of natural language understanding, the intersection of neural models and graph meaning representations (GMRs) remains a compelling area of research. Despite the growing interest, a critical gap persists in understanding the exact influence of GMRs, particularly concerning relation extraction tasks. Addressing this, we introduce DAGNN-plus, a simple and parameter-efficient neural architecture designed to decouple contextual representation learning from structural information propagation. Coupled with various sequence encoders and GMRs, this architecture provides a foundation for systematic experimentation on two English and two Chinese datasets. Our empirical analysis utilizes four different graph formalisms and nine parsers. The results yield a nuanced understanding of GMRs, showing improvements in three out of the four datasets, particularly favoring English over Chinese due to highly accurate parsers. Interestingly, GMRs appear less effective in literary-domain datasets compared to general-domain datasets. These findings lay the groundwork for better-informed design of GMRs and parsers to improve relation classification, which is expected to tangibly impact the future trajectory of natural language understanding research.
Natural Disaster Analysis using Satellite Imagery and Social-Media Data for Emergency Response Situations
Nov 16, 2023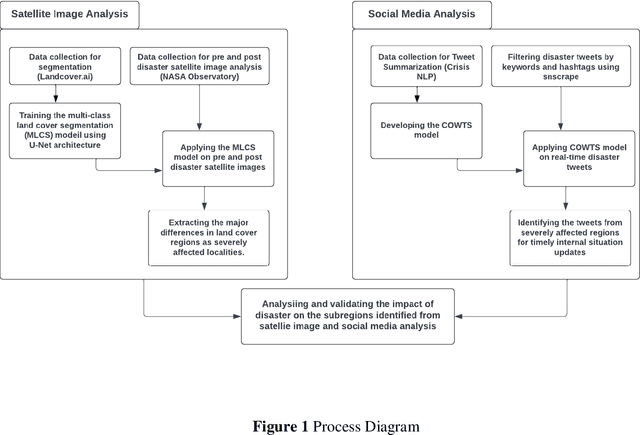


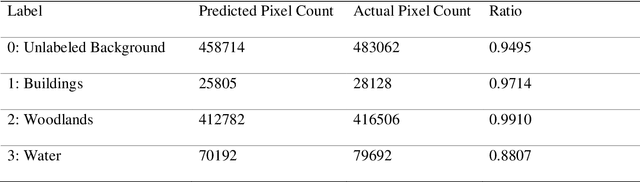
Disaster Management is one of the most promising research areas because of its significant economic, environmental and social repercussions. This research focuses on analyzing different types of data (pre and post satellite images and twitter data) related to disaster management for in-depth analysis of location-wise emergency requirements. This research has been divided into two stages, namely, satellite image analysis and twitter data analysis followed by integration using location. The first stage involves pre and post disaster satellite image analysis of the location using multi-class land cover segmentation technique based on U-Net architecture. The second stage focuses on mapping the region with essential information about the disaster situation and immediate requirements for relief operations. The severely affected regions are demarcated and twitter data is extracted using keywords respective to that location. The extraction of situational information from a large corpus of raw tweets adopts Content Word based Tweet Summarization (COWTS) technique. An integration of these modules using real-time location-based mapping and frequency analysis technique gathers multi-dimensional information in the advent of disaster occurrence such as the Kerala and Mississippi floods that were analyzed and validated as test cases. The novelty of this research lies in the application of segmented satellite images for disaster relief using highlighted land cover changes and integration of twitter data by mapping these region-specific filters for obtaining a complete overview of the disaster.
Utilizing dataset affinity prediction in object detection to assess training data
Nov 16, 2023Data pooling offers various advantages, such as increasing the sample size, improving generalization, reducing sampling bias, and addressing data sparsity and quality, but it is not straightforward and may even be counterproductive. Assessing the effectiveness of pooling datasets in a principled manner is challenging due to the difficulty in estimating the overall information content of individual datasets. Towards this end, we propose incorporating a data source prediction module into standard object detection pipelines. The module runs with minimal overhead during inference time, providing additional information about the data source assigned to individual detections. We show the benefits of the so-called dataset affinity score by automatically selecting samples from a heterogeneous pool of vehicle datasets. The results show that object detectors can be trained on a significantly sparser set of training samples without losing detection accuracy.
AKConv: Convolutional Kernel with Arbitrary Sampled Shapes and Arbitrary Number of Parameters
Nov 26, 2023Neural networks based on convolutional operations have achieved remarkable results in the field of deep learning, but there are two inherent flaws in standard convolutional operations. On the one hand, the convolution operation be confined to a local window and cannot capture information from other locations, and its sampled shapes is fixed. On the other hand, the size of the convolutional kernel is fixed to k $\times$ k, which is a fixed square shape, and the number of parameters tends to grow squarely with size. It is obvious that the shape and size of targets are various in different datasets and at different locations. Convolutional kernels with fixed sample shapes and squares do not adapt well to changing targets. In response to the above questions, the Alterable Kernel Convolution (AKConv) is explored in this work, which gives the convolution kernel an arbitrary number of parameters and arbitrary sampled shapes to provide richer options for the trade-off between network overhead and performance. In AKConv, we define initial positions for convolutional kernels of arbitrary size by means of a new coordinate generation algorithm. To adapt to changes for targets, we introduce offsets to adjust the shape of the samples at each position. Moreover, we explore the effect of the neural network by using the AKConv with the same size and different initial sampled shapes. AKConv completes the process of efficient feature extraction by irregular convolutional operations and brings more exploration options for convolutional sampling shapes. Object detection experiments on representative datasets COCO2017, VOC 7+12 and VisDrone-DET2021 fully demonstrate the advantages of AKConv. AKConv can be used as a plug-and-play convolutional operation to replace convolutional operations to improve network performance. The code for the relevant tasks can be found at https://github.com/CV-ZhangXin/AKConv.
Asking More Informative Questions for Grounded Retrieval
Nov 14, 2023When a model is trying to gather information in an interactive setting, it benefits from asking informative questions. However, in the case of a grounded multi-turn image identification task, previous studies have been constrained to polar yes/no questions, limiting how much information the model can gain in a single turn. We present an approach that formulates more informative, open-ended questions. In doing so, we discover that off-the-shelf visual question answering (VQA) models often make presupposition errors, which standard information gain question selection methods fail to account for. To address this issue, we propose a method that can incorporate presupposition handling into both question selection and belief updates. Specifically, we use a two-stage process, where the model first filters out images which are irrelevant to a given question, then updates its beliefs about which image the user intends. Through self-play and human evaluations, we show that our method is successful in asking informative open-ended questions, increasing accuracy over the past state-of-the-art by 14%, while resulting in 48% more efficient games in human evaluations.
Carpe Diem: On the Evaluation of World Knowledge in Lifelong Language Models
Nov 14, 2023In an ever-evolving world, the dynamic nature of knowledge presents challenges for language models that are trained on static data, leading to outdated encoded information. However, real-world scenarios require models not only to acquire new knowledge but also to overwrite outdated information into updated ones. To address this under-explored issue, we introduce the temporally evolving question answering benchmark, EvolvingQA - a novel benchmark designed for training and evaluating LMs on an evolving Wikipedia database, where the construction of our benchmark is automated with our pipeline using large language models. Our benchmark incorporates question-answering as a downstream task to emulate real-world applications. Through EvolvingQA, we uncover that existing continual learning baselines have difficulty in updating and forgetting outdated knowledge. Our findings suggest that the models fail to learn updated knowledge due to the small weight gradient. Furthermore, we elucidate that the models struggle mostly on providing numerical or temporal answers to questions asking for updated knowledge. Our work aims to model the dynamic nature of real-world information, offering a robust measure for the evolution-adaptability of language models.
Surprisal Driven $k$-NN for Robust and Interpretable Nonparametric Learning
Nov 17, 2023Nonparametric learning is a fundamental concept in machine learning that aims to capture complex patterns and relationships in data without making strong assumptions about the underlying data distribution. Owing to simplicity and familiarity, one of the most well-known algorithms under this paradigm is the $k$-nearest neighbors ($k$-NN) algorithm. Driven by the usage of machine learning in safety-critical applications, in this work, we shed new light on the traditional nearest neighbors algorithm from the perspective of information theory and propose a robust and interpretable framework for tasks such as classification, regression, and anomaly detection using a single model. Instead of using a traditional distance measure which needs to be scaled and contextualized, we use a novel formulation of \textit{surprisal} (amount of information required to explain the difference between the observed and expected result). Finally, we demonstrate this architecture's capability to perform at-par or above the state-of-the-art on classification, regression, and anomaly detection tasks using a single model with enhanced interpretability by providing novel concepts for characterizing data and predictions.
Leveraging Generative AI for Clinical Evidence Summarization Needs to Achieve Trustworthiness
Nov 19, 2023Evidence-based medicine aims to improve the quality of healthcare by empowering medical decisions and practices with the best available evidence. The rapid growth of medical evidence, which can be obtained from various sources, poses a challenge in collecting, appraising, and synthesizing the evidential information. Recent advancements in generative AI, exemplified by large language models, hold promise in facilitating the arduous task. However, developing accountable, fair, and inclusive models remains a complicated undertaking. In this perspective, we discuss the trustworthiness of generative AI in the context of automated summarization of medical evidence.
High-resolution Image-based Malware Classification using Multiple Instance Learning
Nov 21, 2023This paper proposes a novel method of classifying malware into families using high-resolution greyscale images and multiple instance learning to overcome adversarial binary enlargement. Current methods of visualisation-based malware classification largely rely on lossy transformations of inputs such as resizing to handle the large, variable-sized images. Through empirical analysis and experimentation, it is shown that these approaches cause crucial information loss that can be exploited. The proposed solution divides the images into patches and uses embedding-based multiple instance learning with a convolutional neural network and an attention aggregation function for classification. The implementation is evaluated on the Microsoft Malware Classification dataset and achieves accuracies of up to $96.6\%$ on adversarially enlarged samples compared to the baseline of $22.8\%$. The Python code is available online at https://github.com/timppeters/MIL-Malware-Images .
MAIRA-1: A specialised large multimodal model for radiology report generation
Nov 22, 2023We present a radiology-specific multimodal model for the task for generating radiological reports from chest X-rays (CXRs). Our work builds on the idea that large language model(s) can be equipped with multimodal capabilities through alignment with pre-trained vision encoders. On natural images, this has been shown to allow multimodal models to gain image understanding and description capabilities. Our proposed model (MAIRA-1) leverages a CXR-specific image encoder in conjunction with a fine-tuned large language model based on Vicuna-7B, and text-based data augmentation, to produce reports with state-of-the-art quality. In particular, MAIRA-1 significantly improves on the radiologist-aligned RadCliQ metric and across all lexical metrics considered. Manual review of model outputs demonstrates promising fluency and accuracy of generated reports while uncovering failure modes not captured by existing evaluation practices. More information and resources can be found on the project website: https://aka.ms/maira.